DAY49 超大力王爱学Python
知识点回顾:
- 通道注意力模块复习
- 空间注意力模块
- CBAM的定义
最近临近毕业,事情有点多。如果有之前的基础的话,今天的难度相对较低。
后面说完几种模块提取特征的组合方式后,会提供整理的开源模块的文件。
现在大家已近可以去读这类文章了,应该已经可以无压力看懂三四区的很多这类文章。
作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)
torch.backends.cudnn.deterministic = True# 定义CBAM模块
class ChannelAttention(nn.Module):def __init__(self, in_channels, reduction_ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc = nn.Sequential(nn.Conv2d(in_channels, in_channels // reduction_ratio, 1, bias=False),nn.ReLU(),nn.Conv2d(in_channels // reduction_ratio, in_channels, 1, bias=False))def forward(self, x):avg_out = self.fc(self.avg_pool(x))max_out = self.fc(self.max_pool(x))out = avg_out + max_outreturn torch.sigmoid(out)class SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super(SpatialAttention, self).__init__()self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.conv(out)return torch.sigmoid(out)class CBAM(nn.Module):def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):super(CBAM, self).__init__()self.channel_att = ChannelAttention(in_channels, reduction_ratio)self.spatial_att = SpatialAttention(kernel_size)def forward(self, x):x = x * self.channel_att(x)x = x * self.spatial_att(x)return x# 定义带有CBAM的CNN模型
class CBAM_CNN(nn.Module):def __init__(self, num_classes=10):super(CBAM_CNN, self).__init__()# ---------------------- 第一个卷积块(带CBAM) ----------------------self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)self.bn1 = nn.BatchNorm2d(32) # 批归一化self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(kernel_size=2)self.cbam1 = CBAM(in_channels=32) # 在第一个卷积块后添加CBAM# ---------------------- 第二个卷积块(带CBAM) ----------------------self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2)self.cbam2 = CBAM(in_channels=64) # 在第二个卷积块后添加CBAM# ---------------------- 第三个卷积块(带CBAM) ----------------------self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(kernel_size=2)self.cbam3 = CBAM(in_channels=128) # 在第三个卷积块后添加CBAM# ---------------------- 全连接层 ----------------------self.fc1 = nn.Linear(128 * 4 * 4, 512)self.dropout = nn.Dropout(p=0.5)self.fc2 = nn.Linear(512, num_classes)def forward(self, x):# 第一个卷积块x = self.conv1(x)x = self.bn1(x)x = self.relu1(x)x = self.pool1(x)x = self.cbam1(x) # 应用CBAM# 第二个卷积块x = self.conv2(x)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x)x = self.cbam2(x) # 应用CBAM# 第三个卷积块x = self.conv3(x)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x)x = self.cbam3(x) # 应用CBAM# 全连接层x = x.view(-1, 128 * 4 * 4)x = self.fc1(x)x = self.relu3(x)x = self.dropout(x)x = self.fc2(x)return x# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)# CIFAR-10的类别名称
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 创建TensorBoard的SummaryWriter
log_dir = 'runs/cifar10_mlp_experiment'
# 自动生成唯一目录(避免覆盖)
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"# 创建日志目录并验证
os.makedirs(log_dir, exist_ok=True)
print(f"TensorBoard日志将保存在: {log_dir}")# 检查目录是否创建成功
if not os.path.exists(log_dir):raise FileNotFoundError(f"无法创建日志目录: {log_dir}")writer = SummaryWriter(log_dir)# 模型保存路径
model_save_dir = 'saved_models'
os.makedirs(model_save_dir, exist_ok=True)
best_model_path = os.path.join(model_save_dir, 'best_model.pth')
final_model_path = os.path.join(model_save_dir, 'final_model.pth')# 初始化模型并移至设备
model = CBAM_CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', patience=3, factor=0.5)# 5. 训练模型(优化TensorBoard日志写入)
# 训练函数
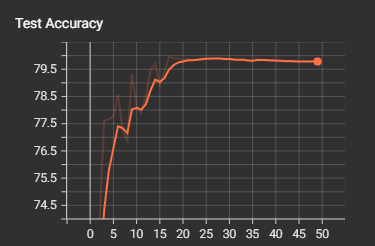
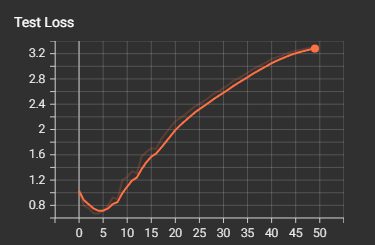
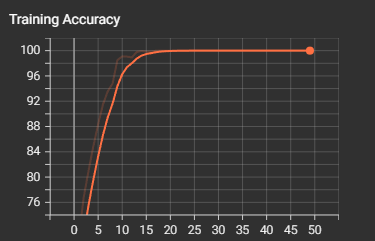
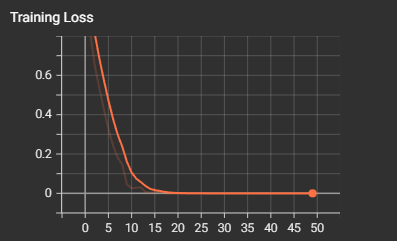
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer, best_model_path):model.train()all_iter_losses = []iter_indices = []train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []best_accuracy = 0.0for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 记录训练指标到TensorBoardwriter.add_scalar('Training Loss', epoch_train_loss, epoch)writer.add_scalar('Training Accuracy', epoch_train_acc, epoch)# 测试阶段model.eval()test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 记录测试指标到TensorBoardwriter.add_scalar('Test Loss', epoch_test_loss, epoch)writer.add_scalar('Test Accuracy', epoch_test_acc, epoch)# 学习率调整scheduler.step(epoch_test_loss)# 保存最佳模型if epoch_test_acc > best_accuracy:best_accuracy = epoch_test_acctorch.save(model.state_dict(), best_model_path)print(f'在Epoch {epoch+1} 保存了最佳模型,准确率: {best_accuracy:.2f}%')print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)# 保存最终模型torch.save(model.state_dict(), final_model_path)print(f'保存了最终模型到 {final_model_path}')# 刷新并关闭TensorBoard写入器writer.flush()writer.close()return best_accuracy# 绘图函数
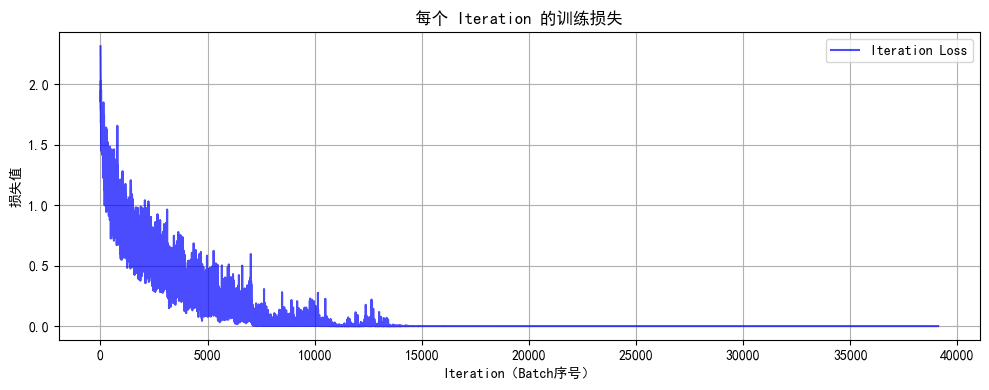
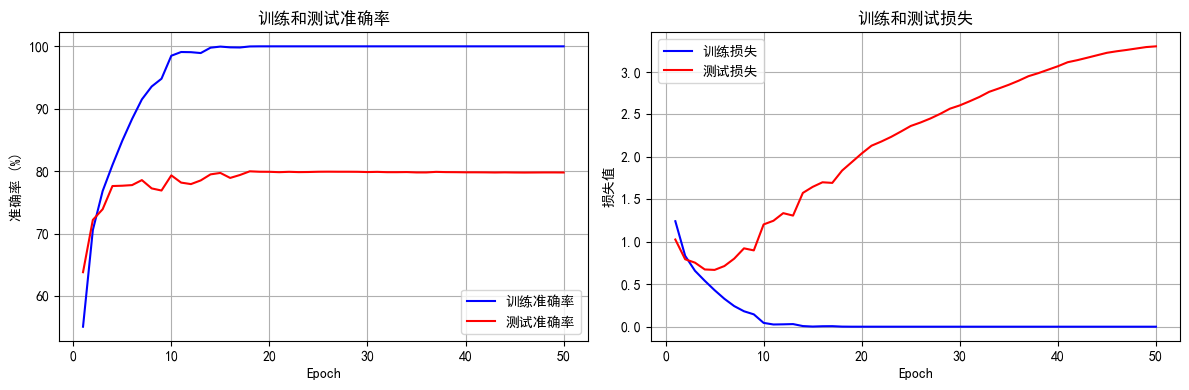
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 执行训练
epochs = 50
print("开始使用带CBAM的CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer, best_model_path)
print(f"训练完成!最佳测试准确率: {final_accuracy:.2f}%")Files already downloaded and verified
使用设备: cuda
TensorBoard日志将保存在: runs/cifar10_mlp_experiment_3
开始使用带CBAM的CNN训练模型... Epoch: 1/50 | Batch: 100/782 | 单Batch损失: 1.5347 | 累计平均损失: 1.7286 Epoch: 1/50 | Batch: 200/782 | 单Batch损失: 1.6409 | 累计平均损失: 1.5906 Epoch: 1/50 | Batch: 300/782 | 单Batch损失: 1.2963 | 累计平均损失: 1.4923 Epoch: 1/50 | Batch: 400/782 | 单Batch损失: 1.2433 | 累计平均损失: 1.4150 Epoch: 1/50 | Batch: 500/782 | 单Batch损失: 0.9714 | 累计平均损失: 1.3561 Epoch: 1/50 | Batch: 600/782 | 单Batch损失: 1.3788 | 累计平均损失: 1.3111 Epoch: 1/50 | Batch: 700/782 | 单Batch损失: 1.1744 | 累计平均损失: 1.2702 在Epoch 1 保存了最佳模型,准确率: 63.80% Epoch 1/50 完成 | 训练准确率: 55.06% | 测试准确率: 63.80% Epoch: 2/50 | Batch: 100/782 | 单Batch损失: 0.8755 | 累计平均损失: 0.9532 Epoch: 2/50 | Batch: 200/782 | 单Batch损失: 0.9961 | 累计平均损失: 0.9275 Epoch: 2/50 | Batch: 300/782 | 单Batch损失: 0.8786 | 累计平均损失: 0.9017 Epoch: 2/50 | Batch: 400/782 | 单Batch损失: 0.8517 | 累计平均损失: 0.8855 Epoch: 2/50 | Batch: 500/782 | 单Batch损失: 0.6945 | 累计平均损失: 0.8724 Epoch: 2/50 | Batch: 600/782 | 单Batch损失: 0.9180 | 累计平均损失: 0.8587 Epoch: 2/50 | Batch: 700/782 | 单Batch损失: 0.7349 | 累计平均损失: 0.8446 在Epoch 2 保存了最佳模型,准确率: 72.18% Epoch 2/50 完成 | 训练准确率: 70.55% | 测试准确率: 72.18% Epoch: 3/50 | Batch: 100/782 | 单Batch损失: 0.8370 | 累计平均损失: 0.6600 Epoch: 3/50 | Batch: 200/782 | 单Batch损失: 0.6755 | 累计平均损失: 0.6713 Epoch: 3/50 | Batch: 300/782 | 单Batch损失: 0.7057 | 累计平均损失: 0.6630
...
Epoch: 50/50 | Batch: 500/782 | 单Batch损失: 0.0000 | 累计平均损失: 0.0000 Epoch: 50/50 | Batch: 600/782 | 单Batch损失: 0.0000 | 累计平均损失: 0.0000 Epoch: 50/50 | Batch: 700/782 | 单Batch损失: 0.0000 | 累计平均损失: 0.0000 Epoch 50/50 完成 | 训练准确率: 100.00% | 测试准确率: 79.78%
@浙大疏锦行