DBSCAN(Density-Based Spatial Clustering of Applications with Noise)基于密度的聚类方法介绍
前言
聚类算法是无监督学习中最经典的问题之一,虽然 K-Means 用得广泛,但它有明显的局限性:
- 无法识别任意形状的簇
- 需要提前指定簇的个数 K
- 对噪声和离群点非常敏感
上一篇介绍了K-Means算法,本文将介绍一下DBSCAN(Density-Based Spatial Clustering of Applications with Noise)基于密度的噪声应用空间聚类,可以不用担心这些局限!
DBSCAN简介
DBSCAN 是一种基于密度的聚类算法,核心思想是:
“密度高的区域形成簇,密度低的区域是噪声或边界”。
与 K-Means 不同,DBSCAN 不要求指定簇的个数,而是通过“密度”定义簇。
DBSCAN 的核心概念
1. 邻域(ε邻域)
对于任意一点 p p p,其ε邻域是以 p p p 为圆心、半径为 ε 的圆(或球)内的点。
2. 密度可达(density reachable)
如果点 q q q 在点 p p p 的 ε 邻域内,且 p p p 是“核心点”,那么 q q q 被称为从 p p p 密度可达。
3. 核心点(core point)
如果某点的 ε 邻域内的点的个数 ≥ MinPts(最小点数),则它是核心点。
4. 边界点(border point)
在核心点的 ε 邻域内,但自身邻域不足 MinPts,不是核心点。
5. 噪声点(noise point)
既不是核心点,也不属于任何核心点邻域。
算法流程
输入:
- 数据集 D
- 参数 ε(邻域半径)
- 参数 MinPts(邻域最小点数)
主要步骤:
- 遍历所有点,为每个未访问点执行以下操作:
- 如果该点的 ε 邻域内有 ≥ MinPts 点 → 标记为“核心点”,开始新簇;
- 递归扩展:把它邻域中的所有密度可达的点加入该簇;
- 如果邻域点数不足 MinPts → 标记为“噪声”或“边界点”;
- 重复直到所有点被处理。
用一句话总结:
从任意一个核心点出发,将其“邻居的邻居的邻居…”全都拉入簇中,直到遇到边界或稀疏区域。
DBSCAN vs K-Means
| 特性 | K-Means | DBSCAN |
|---|---|---|
| 是否需要指定簇数 K? | ✅ 是 | ❌ 不需要 |
| 是否能处理异常值? | ❌ 敏感 | ✅ 能自动识别为噪声点 |
| 是否支持任意形状簇? | ❌ 仅支持球状 | ✅ 支持任意形状 |
| 是否稳定? | ❌ 对初始点敏感 | ✅ 参数敏感但更鲁棒 |
Python 实战代码
我们使用 sklearn 中的 DBSCAN:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.cluster import DBSCAN# 生成非球形数据
X, _ = make_moons(n_samples=300, noise=0.05, random_state=0)# 运行 DBSCAN,后续会介绍如何确定这两个参数eps和minsamples
#eps:ε 邻域的半径
#minsamples:最小密度点数 MinPts(含自身)
dbscan = DBSCAN(eps=0.2, min_samples=5)
labels = dbscan.fit_predict(X)# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='rainbow', s=30)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("DBSCAN 聚类结果")
plt.show()
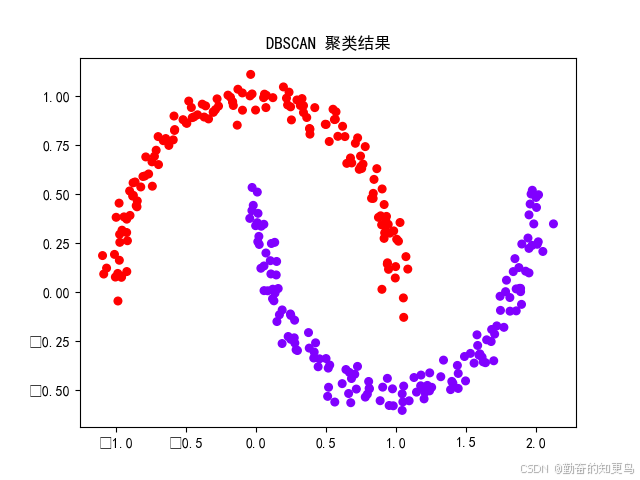
从图可以看到:
- 弯月形状的两个簇成功分开;
- 中间稀疏的点自动识别为噪声(label = -1);
- 无需手动指定“2个簇”。
eps 和 MinPts参数
这是 DBSCAN 唯一的难点。
一个实用技巧是,使用 K-距离图
- 对每个点,计算其到第 MinPts 个最近邻的距离;
- 将这些距离排序并绘图;
- 找“拐点”(突变处),即为合适的 ε。
from sklearn.neighbors import NearestNeighborsneighbors = NearestNeighbors(n_neighbors=5)
neighbors_fit = neighbors.fit(X)
distances, _ = neighbors_fit.kneighbors(X)
distances = np.sort(distances[:, 4]) # 第5个最近邻
plt.plot(distances)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("K-距离图")
plt.show()
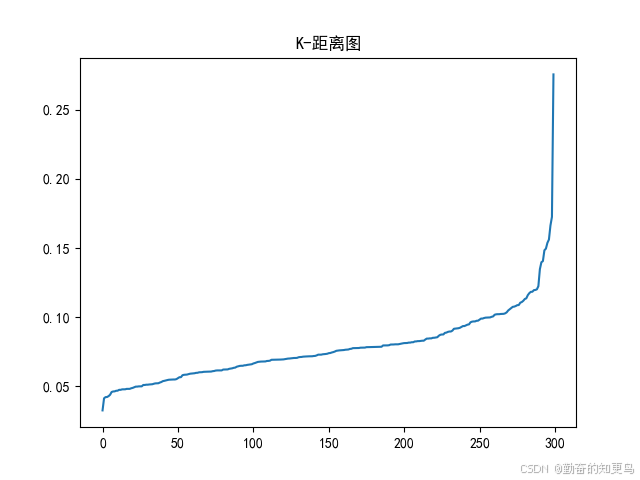
DBSCAN 的优缺点总结
优点:
- 自动识别簇数;
- 可检测任意形状簇;
- 能发现异常点;
- 不敏感于初始点。
缺点:
- 对参数 eps & MinPts 较敏感;
- 在不同密度数据上表现不佳;
- 高维空间中“密度”概念变得模糊,也叫维度灾难。
应用场景
- 地理空间数据聚类,如用户聚集区;
- 社交网络关系发现;
- 图像去噪;
- 异常检测,如金融欺诈、网络攻击等;
总结
DBSCAN 是一款“智能划圈工具”:自动围出密集人群,忽略稀疏路人。
在你不想手动选 K、希望识别复杂形状簇、同时处理异常点时,DBSCAN 是你的好帮手!