Ubuntu 安装并使用 Elasticsearch
启动并运行 Elasticsearch | Elasticsearch 中文文档
Elasticsearch 不允许以特权用户(root)身份直接运行,您需要创建一个非 root 用户来运行 Elasticsearch。
创建新用户并设置密码:
我将创建一个名为 esuser 的新用户。您可以根据需要更改用户名。
sudo adduser esuser && echo "esuser:nihao123" | sudo chpasswd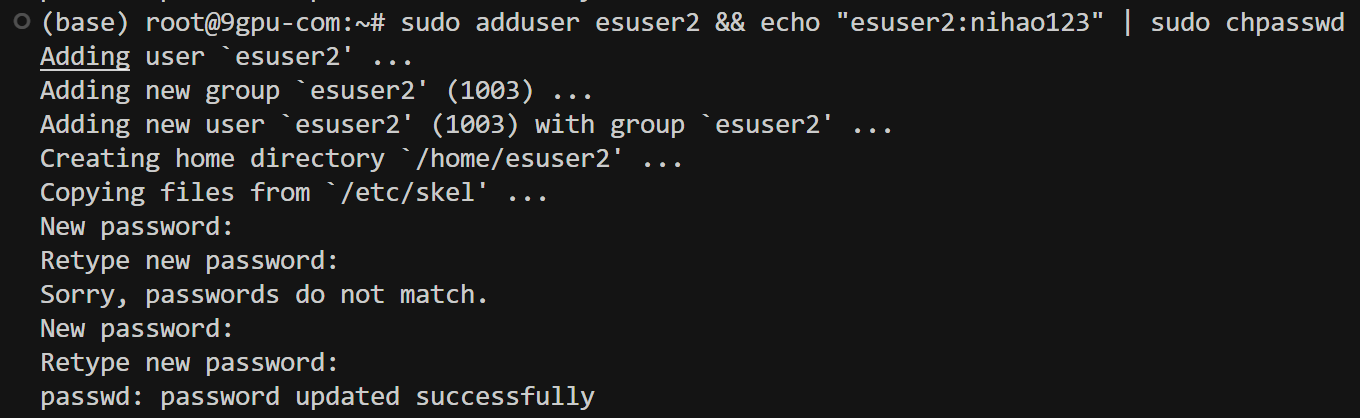
nihao123
如果输入密码持续报错:
请在终端中运行以下命令来重新设置 esuser 的密码:
sudo passwd esusernihao123
请运行以下命令,将 /root/elasticsearch-7.11.1 目录及其所有内容的拥有者更改为 esuser。
sudo chown -R esuser:esuser /root/elasticsearch-7.11.1切换到 esuser 用户:
su - esuser下载 Elasticsearch 压缩包
curl -L -O https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.11.1-linux-x86_64.tar.gz解压文件:
tar -xvf elasticsearch-7.11.1-linux-x86_64.tar.gz 从 bin 目录中启动 Elasticsearch:
cd elasticsearch-7.11.1/bin
./elasticsearch
现在你就运行起了一个单节点 Elasticsearch 集群!
再启动两个 Elasticsearch 实例,你就能看到典型的多节点集群行为。你需要为每个节点指定唯一的数据和日志路径。
./elasticsearch -Epath.data=data2 -Epath.logs=log2
./elasticsearch -Epath.data=data3 -Epath.logs=log3现在 Elasticsearch 已经成功启动了(从日志来看,它已经在 127.0.0.1:9200 上监听)。
以下是使用 Python 将数据批量插入 Elasticsearch 的步骤:
启用新的终端窗口,保持es数据库启动窗口
步骤 1:安装 elasticsearch 库
首先,确保您在 root 用户下,然后运行以下命令安装 Elasticsearch Python 客户端:
安装一个兼容 Elasticsearch 7.x 版本的 elasticsearch 库。我将指定 elasticsearch<8 来确保安装 7.x 系列的最新版本。
pip install "elasticsearch<8"步骤2:运行 es_insert.py 脚本插入数据
from elasticsearch import Elasticsearch, helpers
import json
from tqdm import tqdm
import time
import requests # 导入 requests# Elasticsearch 连接参数
ES_HOST = "127.0.0.1" # 显式使用 IP 地址
ES_PORT = 9200
ES_INDEX = "recipes" # Elasticsearch 索引名称def test_es_connection_with_requests():"""使用 requests 库测试 Elasticsearch 连接"""url = f"http://{ES_HOST}:{ES_PORT}"print(f"正在使用 requests 测试连接到 Elasticsearch: {url}...")try:response = requests.get(url, timeout=5)response.raise_for_status() # 如果状态码不是 2xx,则抛出 HTTPError 异常print(f"requests 成功连接到 Elasticsearch: {response.json()}")return Trueexcept requests.exceptions.RequestException as e:print(f"requests 连接 Elasticsearch 失败!详细错误: {e}")return Falsedef connect_elasticsearch():"""连接到 Elasticsearch"""es = Elasticsearch(f"http://{ES_HOST}:{ES_PORT}")try:if not es.ping():raise ValueError("Elasticsearch ping 失败!服务可能未运行或不可访问。")except Exception as e:raise ValueError(f"连接 Elasticsearch 失败!详细错误: {e}")print(f"成功连接到 Elasticsearch: {ES_HOST}:{ES_PORT}")return esdef create_es_index(es_client, index_name):"""创建 Elasticsearch 索引并定义 Mapping (可选) """if not es_client.indices.exists(index=index_name):# 您可以根据实际需求定义更详细的 mappingmapping = {"properties": {"name": {"type": "text"},"dish": {"type": "keyword"},"description": {"type": "text"},"recipeIngredient": {"type": "text"},"recipeInstructions": {"type": "text"},"author": {"type": "keyword"},"keywords": {"type": "keyword"}}}es_client.indices.create(index=index_name, body={"mappings": mapping})print(f"Elasticsearch 索引 '{index_name}' 创建成功.")else:print(f"Elasticsearch 索引 '{index_name}' 已经存在.")def generate_actions(recipes_list, index_name):"""生成用于批量插入的 action 字典"""for doc in recipes_list:# 确保每个文档都有必要的字段,这里使用 .get() 方法,避免 KeyErroryield {"_index": index_name,"_source": {"name": doc.get("name", ""),"dish": doc.get("dish", ""),"description": doc.get("description", ""),"recipeIngredient": doc.get("recipeIngredient", ""),"recipeInstructions": doc.get("recipeInstructions", ""),"author": doc.get("author", ""),"keywords": doc.get("keywords", "")}}def insert_data_to_es(es_client, data_path, index_name):"""从 JSON 文件批量插入数据到 Elasticsearch"""print("正在读取数据...")valid_recipes = []with open(data_path, 'r', encoding='utf-8', errors='ignore') as f:for line_num, line in enumerate(f):try:valid_recipes.append(json.loads(line))except json.JSONDecodeError as e:print(f"警告: JSON 解析错误在文件 {data_path} 的第 {line_num + 1} 行: {e}. 跳过此行.")print(f"数据读取完成,共 {len(valid_recipes)} 条有效记录.")if not valid_recipes:print("错误: 未能从文件中读取到任何有效的食谱数据。请检查JSON文件格式和内容。")returnactions_generator = generate_actions(valid_recipes, index_name)start_total_time = time.time()success_count = 0for ok, item in tqdm(helpers.streaming_bulk(es_client, actions_generator, chunk_size=1000, request_timeout=60),total=len(valid_recipes), desc="Elasticsearch 插入进度"):if not ok:print(f"插入失败: {item}")else:success_count += 1end_total_time = time.time()print(f"\n总共成功插入 {success_count} 条数据到 Elasticsearch. 总耗时 {end_total_time - start_total_time:.2f} 秒.")if __name__ == "__main__":try:# 首先使用 requests 测试连接if not test_es_connection_with_requests():print("requests 无法连接到 Elasticsearch,停止执行。")else:es = connect_elasticsearch()create_es_index(es, ES_INDEX)insert_data_to_es(es, "/root/recipe_corpus_full.json", ES_INDEX)except Exception as e:print(f"发生错误: {e}")
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.dtcms.com/a/251404.html
如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!