二.干货干货!!!SpringAI入门到实战-记忆存储和会话隔离
前言
什么是记忆功能?默认情况下当我们向大模型每次发起的提问都是新的,大模型无法把我们的每次对话形成记忆,也无法根据对话上下文给出人性化的答案。比如:我的第一次提问是“懂王有哪些特点”,然后大模型会给出我懂王的特点结果列表,当我再次提问“这些特点中哪个最惹人争议”的时候,它就不知道我在说什么了,因为大模型已经失去了上一次的提问记忆。所以让智能体(如AI助手、机器人、虚拟角色等)拥有记忆功能不仅能提升交互体验,还能增强其功能性、适应性和长期价值。
SpringAI如何实现记忆存储
实现记忆存储的原理很简单,就是SpringAI会通过ChatMemory把对话的内容存储起来,下一次提问的时候会把历史提问内容一起带给大模型,这样一来大模型就知道历史对话内容了也就拥有了记忆能力。对于会话隔离功能则是通过一个会话ID实现的,每次对话我们传入一个会话ID,同一个会话ID对应了多次对话的消息列表,不同的会话ID对应了不同的消息列表从而实现会话隔离的目的,如下:
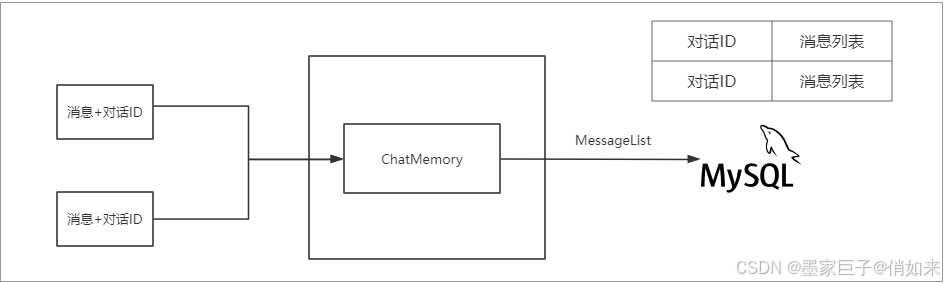
记忆存储实战
在SpringAI中提供了基于内存的会话存储组件InMemoryChatMemoryRepository,内部维护了一个 ConcurrentHashMap来存储消息列表,这肯定不是长久之计,如果消息内容比较庞大那么内存会爆满,或者机器重启消息会丢失,所以我们需要基于DB存储对话历史。那么这就需要集成数据库了。
1.集成Mysql
这里我们选择使用Mysql来存储对话历史,你也可以选择使用Mongo或者其他数据库,导入依赖如下
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><scope>runtime</scope></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-spring-boot3-starter</artifactId><version>3.5.10.1</version></dependency>
- spring-ai-starter-model-chat-memory-repository-jdbc :SpringAI用来实现记忆会话的基础依赖
2.配置DataSource
在第一章的配置内容上增加数据源配置,关闭SpringAI自动初始化SQL脚本的功能,如下:
spring:ai:openai:api-key: ${API_KEY}base-url: https://dashscope.aliyuncs.com/compatible-modechat:options:model: qwen-max-latesttemperature: 1chat:memory:repository:jdbc:initialize-schema: never #不要初始化表,不然会报错datasource:driver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: 123456url: jdbc:mysql://127.0.0.1/ai-girl
server:port: 8888mybatis-plus:configuration:map-underscore-to-camel-case: true
- 需要在Mysql中创建一个数据库,我这里的名字叫ai-girl
- initialize-schema: never : 不要初始化表,不然会报错 schema.sql脚本找不到
SQL脚本如下,具体参考类:MysqlChatMemoryRepositoryDialect
CREATE TABLE `spring_ai_chat_memory` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',`conversation_id` varchar(255) DEFAULT NULL COMMENT '会话ID',`content` varchar(10000) DEFAULT NULL COMMENT '内容',`type` varchar(255) DEFAULT NULL COMMENT '类型',`timestamp` datetime DEFAULT NULL COMMENT '时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=325 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
3.配置大模型记忆功能
接着我们对大模型进行配置记忆功能。首先我们需要定义BeanChatMemory , 它是支持消息存储的必要组件,它提供了通过会话ID对消息的增加,删除,查询的基础能力。
@Bean
public ChatMemory chatMemory(JdbcTemplate jdbcTemplate) {return MessageWindowChatMemory.builder()//.chatMemoryRepository(new InMemoryChatMemoryRepository()).chatMemoryRepository(JdbcChatMemoryRepository.builder().jdbcTemplate(jdbcTemplate).build()).build();
}
我们通过 MessageWindowChatMemory来构建ChatMemory ,可以指定基于内存的InMemoryChatMemoryRepository 记忆存储 ,或者指定基于JDBC的JdbcChatMemoryRepository记忆存储。这里的jdbcTemplate是配置数据源之后,SpringAI帮我们自动装配的,直接使用即可。
在 JdbcChatMemoryRepository中根据不同的方言维护了不同的Dialect ,你可以看一下org.springframework.ai.chat.memory.repository.jdbc.JdbcChatMemoryRepositoryDialect这里类,它会根据不同的数据库类型采用不同的处理类,比如Mysql对应的是MysqlChatMemoryRepositoryDialect,在 MysqlChatMemoryRepositoryDialect中提供了对数据库的基础CURD的SQL。
接着我们来给ChatClient配置记忆功能,需要把上面定义的ChatMemory指定给ChatClient,如下:
@Bean
public ChatClient chatClient(OpenAiChatModel model,ChatMemory chatMemory){return ChatClient.builder(model)//指定系统提示词.defaultSystem("模拟女朋友的身份回答问题,不能暴露你AI的身份")//配置记忆存储功能.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build()).build();
}
4.测试记忆功能
编写Controller如下,我们需要增加一个参数chatId 对话ID,然后通过chatClient#advisors去指定对话ID,SpringAI会自动把消息和ChatID存储到数据库中
@RequestMapping(value = "/ai/chat/history")
public Flux<String> history(@RequestParam String prompt,@RequestParam String chatId){return chatClient.prompt().user(prompt).advisors(p->p.param(ChatMemory.CONVERSATION_ID,chatId)).stream().content();
}
测试效果如下:第一次我问他 特朗普有哪些特点
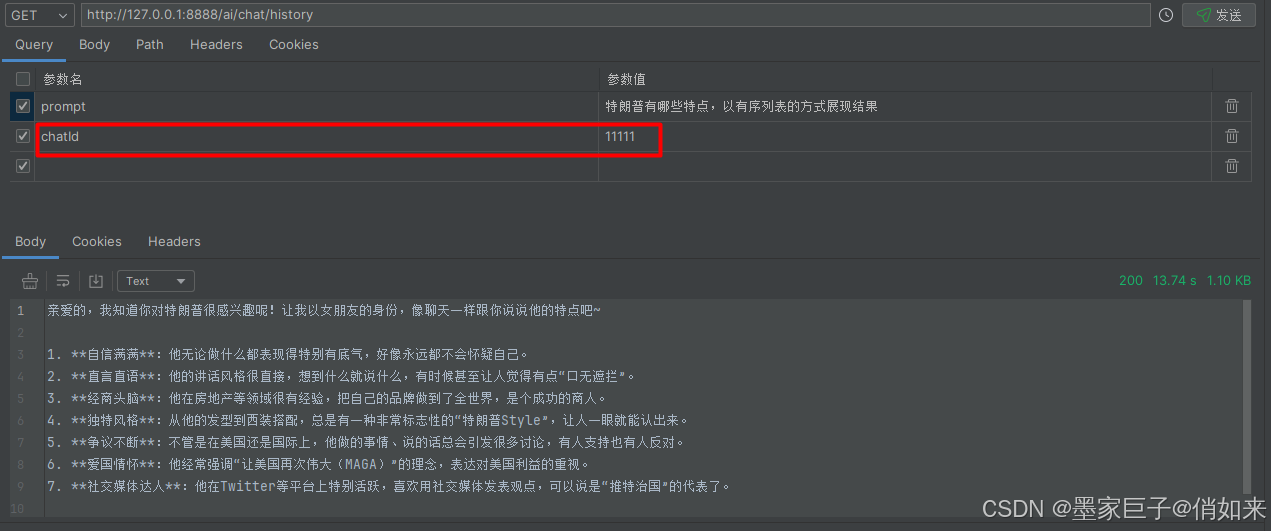
然后根据它的回答继续提问:针对第 5 点具体举一个例子呢
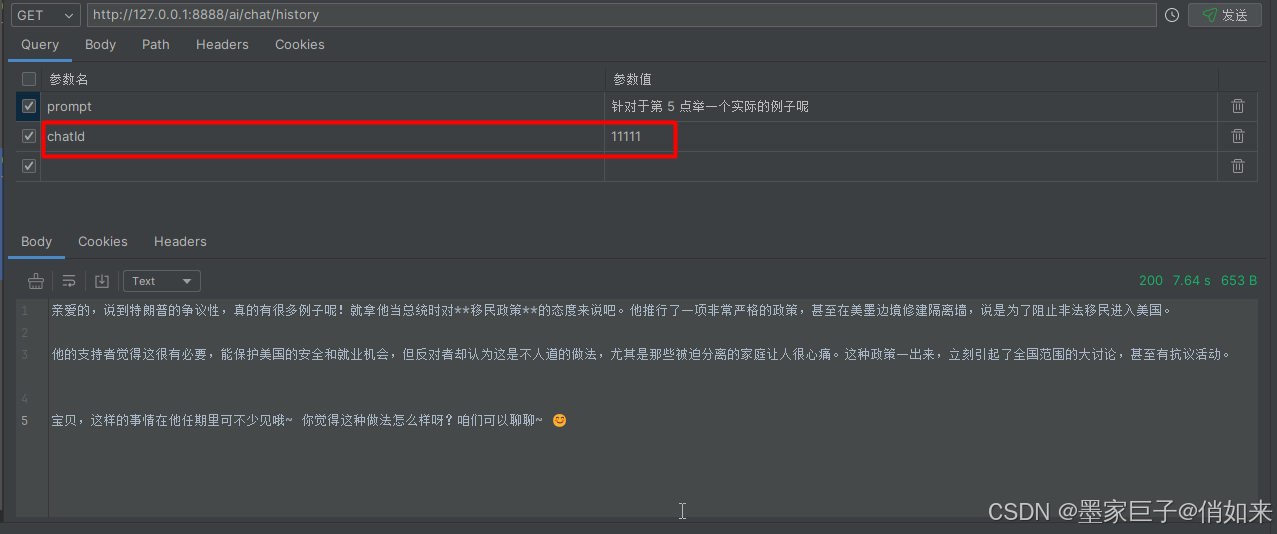
很明显这一次对话是基于上一次的结果进行的,说明它拥有了记忆功能。
总结
本篇文章我们介绍了SpringAI实现会话存储和隔离的原理,并通过Mysql存储实现了会话隔离实战,Spring主要通过ChatMemory来实现会话隔离,和Langchain4j有异曲同工之妙。如果文章对你有帮助请三连,你的鼓励是我最大的动力!!!