深度理解 CLIP:连接图像与语言的桥梁
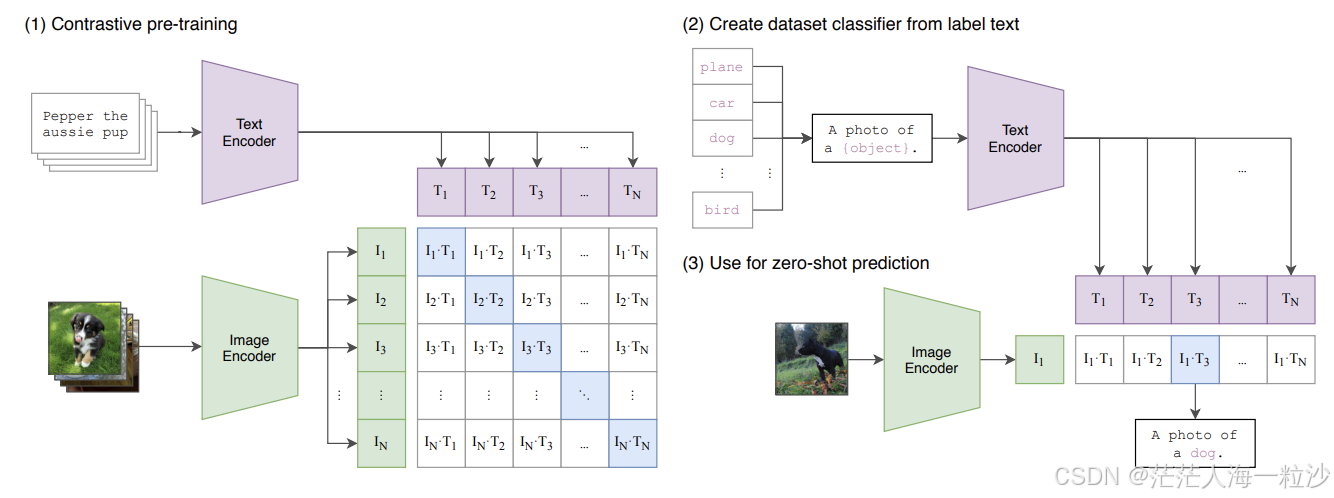
在AI跨模态研究领域,一个名字频繁出现——CLIP(Contrastive Language–Image Pre-training)。这是OpenAI于2021年发布的一项颠覆性研究成果,它能够理解图像与自然语言之间的语义关联,实现真正的图文统一表示学习。本文将带你了解 CLIP 是什么,它如何工作,有哪些独特优势,以及为何它在当今AI技术中如此重要。
什么是 CLIP?
CLIP,全称为 Contrastive Language–Image Pre-training(对比语言-图像预训练),是一种跨模态模型。它的目标是学习一个可以同时理解图像和语言的通用视觉-语言表示空间。
传统图像识别模型需要在每个任务上进行微调(fine-tuning),但 CLIP 只需简单的自然语言提示(prompt),就可以实现 零样本图像分类(zero-shot classification),无需额外训练。
CLIP 的架构
CLIP 包含两个主要部分:
-
图像编码器(Image Encoder)
通常是 ResNet 或 Vision Transformer(ViT),将输入图像转换为向量。 -
文本编码器(Text Encoder)
使用 Transformer(如类似 GPT/BERT 的结构),将文本描述编码为向量。
两者的输出被映射到同一个高维语义空间中。
CLIP 如何训练?
CLIP 使用了一种 对比学习(Contrastive Learning) 方法。其核心思想是:
-
给定一个图像和它的文本描述(如图片是“狗”,文本是“a photo of a dog”),模型要学会将这对图文表示拉近;
-
同时让与之无关的图文对保持距离。
这种学习方式使用了大规模的训练数据,CLIP 是在 4亿对图文数据 上训练出来的,这些数据来自互联网。
训练目标是最大化匹配图文对的相似度,同时最小化不匹配对的相似度。
CLIP 的强大能力
✅ 零样本分类(Zero-shot Classification)
CLIP 不需要针对某个具体任务进行训练。你只需给出自然语言提示(如:"a photo of a cat", "a photo of a dog"...),模型就能自动判断图像最匹配哪个描述。
✅ 图文检索(Text-Image Retrieval)
CLIP 可以:
-
以图搜文(图像找到最匹配的文字描述)
-
以文搜图(文字描述找到最匹配的图像)
这使得 CLIP 成为构建智能搜索系统的理想选择。
✅ 跨模态理解与生成
CLIP 可以作为生成模型(如 DALL·E)中的评分机制,帮助挑选最贴合文本的图像。它也可用于指导图像生成、风格转换、图文匹配等任务。
为什么 CLIP 意义重大?
-
跨模态融合的范式变革:CLIP 不再把图像和文本视为两个孤立世界,而是通过共享语义空间,实现了更自然的人机交互。
-
开放世界识别能力:CLIP 不依赖固定的标签体系,而是支持动态、可组合的自然语言标签。
-
通用性与可扩展性:一次训练,多场景使用。它打破了“一个模型一个任务”的传统限制。
应用场景举例
-
AI辅助内容审核:自动识别违反政策的图像内容。
-
搜索引擎:图文双向检索,提升用户体验。
-
图像生成评分:在文本到图像生成中选择最相关结果。
-
多模态问答系统:辅助机器人更好地理解用户需求。
总结
CLIP 的提出,让图像“读懂”语言,也让语言“看见”图像。它是连接视觉和语言的关键桥梁,是AI通用智能迈出的重要一步。随着越来越多的应用落地,CLIP 为多模态学习、通用表示和开放世界智能奠定了坚实基础。
推荐阅读:
-
OpenAI 官方论文:Learning Transferable Visual Models From Natural Language Supervision
-
OpenAI Blog:CLIP: Connecting Vision and Language