6月14日day53打卡
对抗生成网络
知识点回顾:
- 对抗生成网络的思想:关注损失从何而来
- 生成器、判别器
- nn.sequential容器:适合于按顺序运算的情况,简化前向传播写法
- leakyReLU介绍:避免relu的神经元失活现象
ps;如果你学有余力,对于gan的损失函数的理解,建议去找找视频看看,如果只是用,没必要学
作业:对于心脏病数据集,对于病人这个不平衡的样本用GAN来学习并生成病人样本,观察不用GAN和用GAN的F1分数差异。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, classification_report, confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统常用黑体字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
data = pd.read_csv('D:\桌面\研究项目\打卡文件\python60-days-challenge-master\heart.csv') #读取数据# 设置随机种子以确保结果可复现
torch.manual_seed(42)
np.random.seed(42)# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# ---------------------------
# 1. 加载并预处理心脏病数据集
# ---------------------------def load_heart_disease_data():"""加载心脏病数据集并进行预处理"""try:# 读取CSV文件df = pd.read_csv("D:\桌面\研究项目\打卡文件\python60-days-challenge-master\heart.csv")print(f"成功加载heart.csv,数据形状: {df.shape}")# 显示数据基本信息print("\n数据基本信息:")df.info()# 显示数据集行数和列数rows, columns = df.shape# 数据可视化 - 目标变量分布plt.figure(figsize=(6, 4))sns.countplot(x='target', data=df)plt.title('心脏病患者分布')plt.xlabel('是否患病')plt.ylabel('样本数')plt.xticks([0, 1], ['健康', '患病'])plt.show()# 重命名列以便更好理解df.columns = ['age', 'sex', 'chest_pain_type', 'resting_blood_pressure', 'cholesterol', 'fasting_blood_sugar', 'rest_ecg', 'max_heart_rate_achieved', 'exercise_induced_angina', 'st_depression', 'st_slope', 'num_major_vessels', 'thalassemia', 'target']# 转换分类特征categorical_features = ['sex', 'chest_pain_type', 'fasting_blood_sugar', 'rest_ecg', 'exercise_induced_angina', 'st_slope', 'num_major_vessels', 'thalassemia']for feature in categorical_features:df[feature] = df[feature].astype('object')# 独热编码df = pd.get_dummies(df, drop_first=True)# 划分特征和目标变量X = df.drop(columns='target').valuesy = df['target'].values# 打印类别分布class_counts = pd.Series(y).value_counts()print(f"\n类别分布: \n{class_counts}")print(f"不平衡比例: {class_counts[0]/class_counts[1]:.2f}:1")return X, yexcept FileNotFoundError:print("错误:未找到heart.csv文件,请检查文件路径")return None, Noneexcept Exception as e:print(f"数据加载错误: {str(e)}")return None, None# 加载数据
X, y = load_heart_disease_data()
if X is None or y is None:exit()# 数据缩放
scaler = MinMaxScaler(feature_range=(-1, 1))
X_scaled = scaler.fit_transform(X)# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)# 提取少数类样本 (心脏病患者)
X_minority = X_train[y_train == 1]
y_minority = y_train[y_train == 1]print(f"训练集中少数类样本数量: {len(X_minority)}")# ---------------------------
# 2. 定义条件GAN模型
# ---------------------------class ConditionalGenerator(nn.Module):def __init__(self, input_dim, output_dim, label_dim):super(ConditionalGenerator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim + label_dim, 64),nn.LeakyReLU(0.2),nn.BatchNorm1d(64),nn.Linear(64, 128),nn.LeakyReLU(0.2),nn.BatchNorm1d(128),nn.Linear(128, output_dim),nn.Tanh() # 输出范围为[-1, 1],与数据缩放范围一致)def forward(self, z, labels):# 合并噪声和标签input_tensor = torch.cat([z, labels], dim=1)return self.model(input_tensor)class ConditionalDiscriminator(nn.Module):def __init__(self, input_dim, label_dim):super(ConditionalDiscriminator, self).__init__()self.model = nn.Sequential(nn.Linear(input_dim + label_dim, 128),nn.LeakyReLU(0.2),nn.Dropout(0.3),nn.Linear(128, 64),nn.LeakyReLU(0.2),nn.Dropout(0.3),nn.Linear(64, 1),nn.Sigmoid() # 输出概率值)def forward(self, x, labels):# 合并输入特征和标签input_tensor = torch.cat([x, labels], dim=1)return self.model(input_tensor)# ---------------------------
# 3. 训练CGAN模型
# ---------------------------# 模型参数
LATENT_DIM = 10
INPUT_DIM = X_train.shape[1]
LABEL_DIM = 1 # 二分类问题
EPOCHS = 1000
BATCH_SIZE = 32
LR = 0.0002
BETA1 = 0.5# 创建数据加载器
minority_dataset = TensorDataset(torch.FloatTensor(X_minority), torch.FloatTensor(y_minority).view(-1, 1)
)
minority_dataloader = DataLoader(minority_dataset, batch_size=BATCH_SIZE, shuffle=True)# 实例化模型
generator = ConditionalGenerator(LATENT_DIM, INPUT_DIM, LABEL_DIM).to(device)
discriminator = ConditionalDiscriminator(INPUT_DIM, LABEL_DIM).to(device)# 定义损失函数和优化器
criterion = nn.BCELoss()
g_optimizer = optim.Adam(generator.parameters(), lr=LR, betas=(BETA1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LR, betas=(BETA1, 0.999))# 训练循环
g_losses, d_losses = [], []for epoch in range(EPOCHS):epoch_g_loss, epoch_d_loss = 0, 0batches_per_epoch = 0for i, (real_data, real_labels) in enumerate(minority_dataloader):real_data = real_data.to(device)real_labels = real_labels.to(device)batch_size = real_data.size(0)batches_per_epoch += 1# 创建真实和虚假标签real_targets = torch.ones(batch_size, 1).to(device)fake_targets = torch.zeros(batch_size, 1).to(device)# ---------------------# 训练判别器# ---------------------d_optimizer.zero_grad()# 用真实数据训练real_validity = discriminator(real_data, real_labels)d_real_loss = criterion(real_validity, real_targets)# 生成假数据z = torch.randn(batch_size, LATENT_DIM).to(device)fake_labels = real_labels # 生成与真实样本相同类别的数据fake_data = generator(z, fake_labels)# 用假数据训练fake_validity = discriminator(fake_data.detach(), fake_labels)d_fake_loss = criterion(fake_validity, fake_targets)# 总判别器损失d_loss = (d_real_loss + d_fake_loss) / 2d_loss.backward()d_optimizer.step()epoch_d_loss += d_loss.item()# ---------------------# 训练生成器# ---------------------g_optimizer.zero_grad()# 生成假数据fake_data = generator(z, fake_labels)fake_validity = discriminator(fake_data, fake_labels)# 生成器损失g_loss = criterion(fake_validity, real_targets)g_loss.backward()g_optimizer.step()epoch_g_loss += g_loss.item()# 计算平均损失avg_g_loss = epoch_g_loss / batches_per_epochavg_d_loss = epoch_d_loss / batches_per_epochg_losses.append(avg_g_loss)d_losses.append(avg_d_loss)# 每100个epoch打印一次损失if (epoch + 1) % 100 == 0:print(f"Epoch [{epoch+1}/{EPOCHS}], D_loss: {avg_d_loss:.4f}, G_loss: {avg_g_loss:.4f}")print("CGAN训练完成!")# 绘制训练损失曲线
plt.figure(figsize=(10, 5))
plt.plot(g_losses, label='生成器损失')
plt.plot(d_losses, label='判别器损失')
plt.title('训练损失曲线')
plt.xlabel('Epoch')
plt.ylabel('损失')
plt.legend()
plt.show()# ---------------------------
# 4. 生成合成样本
# ---------------------------# 设置为评估模式
generator.eval()# 生成与少数类样本数量相同的合成数据
num_samples_to_generate = len(X_minority)
z = torch.randn(num_samples_to_generate, LATENT_DIM).to(device)
labels = torch.ones(num_samples_to_generate, 1).to(device) # 标签为1,表示心脏病患者with torch.no_grad():synthetic_data = generator(z, labels).cpu().numpy()# 逆缩放合成数据
synthetic_data = scaler.inverse_transform(synthetic_data)# 为合成数据创建标签
synthetic_labels = np.ones(num_samples_to_generate)# 逆缩放原始训练数据用于可视化
X_train_original = scaler.inverse_transform(X_train)# ---------------------------
# 5. 可视化原始数据和合成数据
# ---------------------------# 可视化特征分布对比
plt.figure(figsize=(14, 10))
feature_names = ['年龄', '血压', '胆固醇', '最大心率']
feature_indices = [0, 3, 4, 7] # 对应数据集中的特征索引for i, idx in enumerate(feature_indices):plt.subplot(2, 2, i+1)# 绘制原始少数类样本的特征分布sns.kdeplot(X_train_original[y_train == 1, idx], label='原始数据', color='blue')# 绘制合成样本的特征分布sns.kdeplot(synthetic_data[:, idx], label='合成数据', color='orange')plt.title(f'{feature_names[i]}分布对比')plt.xlabel('特征值')plt.ylabel('密度')plt.legend()plt.tight_layout()
plt.show()# ---------------------------
# 6. 比较模型性能
# ---------------------------# 6.1 使用原始数据训练的模型
model_original = RandomForestClassifier(random_state=42)
model_original.fit(X_train, y_train)
y_pred_original = model_original.predict(X_test)
y_pred_prob_original = model_original.predict_proba(X_test)[:, 1]# 6.2 使用增强数据训练的模型
# 将合成数据添加到训练集中
X_train_augmented = np.vstack([X_train, scaler.transform(synthetic_data)])
y_train_augmented = np.hstack([y_train, synthetic_labels])model_augmented = RandomForestClassifier(random_state=42)
model_augmented.fit(X_train_augmented, y_train_augmented)
y_pred_augmented = model_augmented.predict(X_test)
y_pred_prob_augmented = model_augmented.predict_proba(X_test)[:, 1]# 6.3 比较F1分数
f1_original = f1_score(y_test, y_pred_original)
f1_augmented = f1_score(y_test, y_pred_augmented)print("\n模型性能比较:")
print(f"原始数据训练的模型 F1 分数: {f1_original:.4f}")
print(f"增强数据训练的模型 F1 分数: {f1_augmented:.4f}")# 打印详细分类报告
print("\n原始数据训练的模型分类报告:")
print(classification_report(y_test, y_pred_original))print("\n增强数据训练的模型分类报告:")
print(classification_report(y_test, y_pred_augmented))# 计算混淆矩阵
cm_original = confusion_matrix(y_test, y_pred_original)
cm_augmented = confusion_matrix(y_test, y_pred_augmented)# 计算ROC曲线
fpr_original, tpr_original, _ = roc_curve(y_test, y_pred_prob_original)
fpr_augmented, tpr_augmented, _ = roc_curve(y_test, y_pred_prob_augmented)
roc_auc_original = auc(fpr_original, tpr_original)
roc_auc_augmented = auc(fpr_augmented, tpr_augmented)# ---------------------------
# 7. 可视化评估结果
# ---------------------------# 7.1 混淆矩阵对比
plt.figure(figsize=(12, 5))plt.subplot(1, 2, 1)
sns.heatmap(cm_original, annot=True, fmt='d', cmap='Blues')
plt.title('原始数据模型混淆矩阵')
plt.xlabel('预测类别')
plt.ylabel('真实类别')plt.subplot(1, 2, 2)
sns.heatmap(cm_augmented, annot=True, fmt='d', cmap='Greens')
plt.title('增强数据模型混淆矩阵')
plt.xlabel('预测类别')
plt.ylabel('真实类别')plt.tight_layout()
plt.show()# 7.2 ROC曲线对比
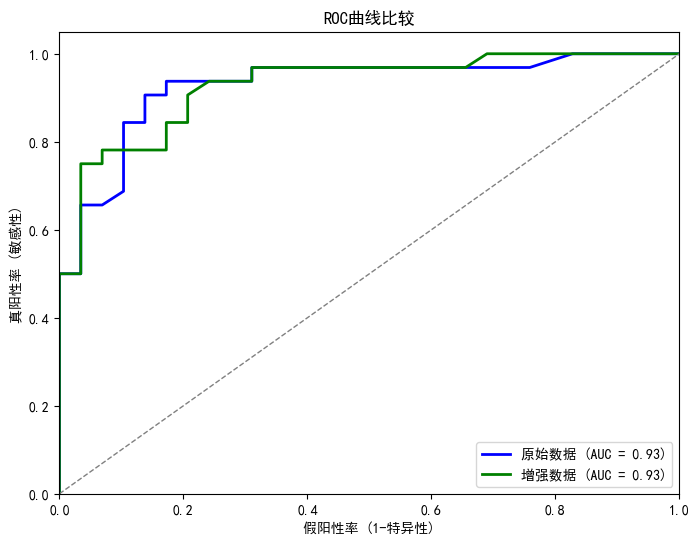
plt.figure(figsize=(8, 6))
plt.plot(fpr_original, tpr_original, color='blue', lw=2, label=f'原始数据 (AUC = {roc_auc_original:.2f})')
plt.plot(fpr_augmented, tpr_augmented, color='green', lw=2, label=f'增强数据 (AUC = {roc_auc_augmented:.2f})')
plt.plot([0, 1], [0, 1], color='gray', lw=1, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('假阳性率 (1-特异性)')
plt.ylabel('真阳性率 (敏感性)')
plt.title('ROC曲线比较')
plt.legend(loc="lower right")
plt.show()# 7.3 F1分数对比
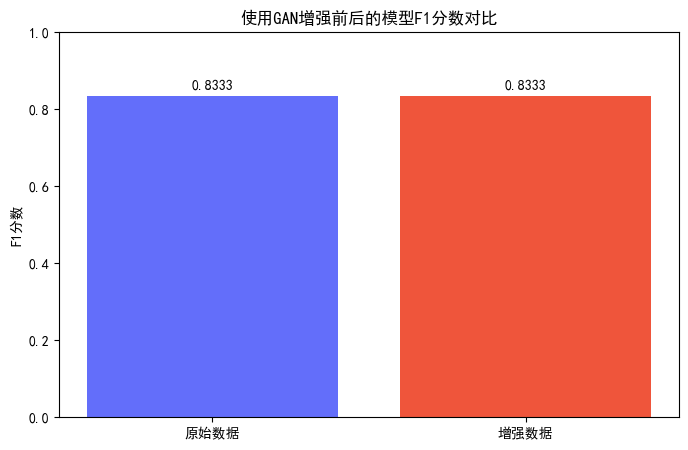
plt.figure(figsize=(8, 5))
plt.bar(['原始数据', '增强数据'], [f1_original, f1_augmented], color=['#636EFA', '#EF553B'])
plt.ylim(0, 1)
plt.title('使用GAN增强前后的模型F1分数对比')
plt.ylabel('F1分数')
for i, v in enumerate([f1_original, f1_augmented]):plt.text(i, v + 0.02, f'{v:.4f}', ha='center')
plt.show() 使用设备: cuda
成功加载heart.csv,数据形状: (303, 14)数据基本信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 age 303 non-null int64 1 sex 303 non-null int64 2 cp 303 non-null int64 3 trestbps 303 non-null int64 4 chol 303 non-null int64 5 fbs 303 non-null int64 6 restecg 303 non-null int64 7 thalach 303 non-null int64 8 exang 303 non-null int64 9 oldpeak 303 non-null float6410 slope 303 non-null int64 11 ca 303 non-null int64 12 thal 303 non-null int64 13 target 303 non-null int64
dtypes: float64(1), int64(13)
memory usage: 33.3 KB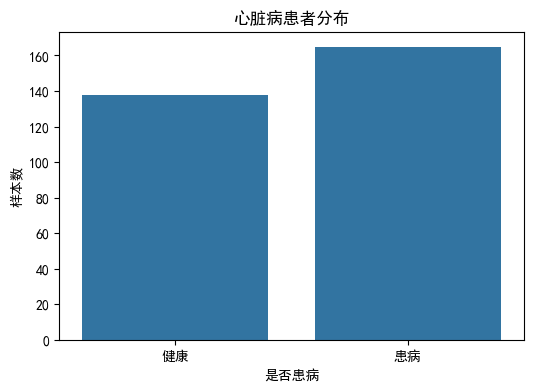
类别分布:
1 165
0 138
Name: count, dtype: int64
不平衡比例: 0.84:1
训练集中少数类样本数量: 133
Epoch [100/1000], D_loss: 0.5933, G_loss: 0.9950
Epoch [200/1000], D_loss: 0.6231, G_loss: 0.9423
Epoch [300/1000], D_loss: 0.5518, G_loss: 1.0263
Epoch [400/1000], D_loss: 0.5745, G_loss: 0.9765
Epoch [500/1000], D_loss: 0.5725, G_loss: 0.8739
Epoch [600/1000], D_loss: 0.6261, G_loss: 0.8975
Epoch [700/1000], D_loss: 0.5993, G_loss: 0.9735
Epoch [800/1000], D_loss: 0.6198, G_loss: 0.9446
Epoch [900/1000], D_loss: 0.5936, G_loss: 0.9563
Epoch [1000/1000], D_loss: 0.6497, G_loss: 0.9020
CGAN训练完成!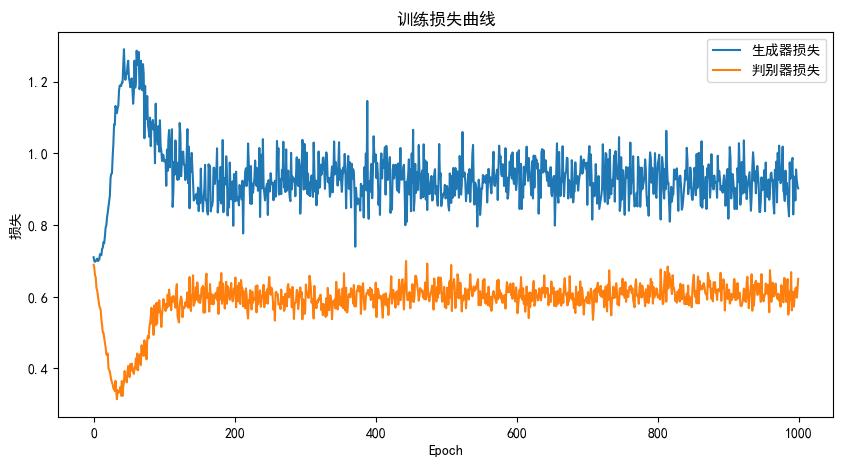
模型性能比较:
原始数据训练的模型 F1 分数: 0.8333
增强数据训练的模型 F1 分数: 0.8333原始数据训练的模型分类报告:precision recall f1-score support0 0.79 0.90 0.84 291 0.89 0.78 0.83 32accuracy 0.84 61macro avg 0.84 0.84 0.84 61
weighted avg 0.84 0.84 0.84 61增强数据训练的模型分类报告:precision recall f1-score support0 0.79 0.90 0.84 291 0.89 0.78 0.83 32accuracy 0.84 61macro avg 0.84 0.84 0.84 61
weighted avg 0.84 0.84 0.84 61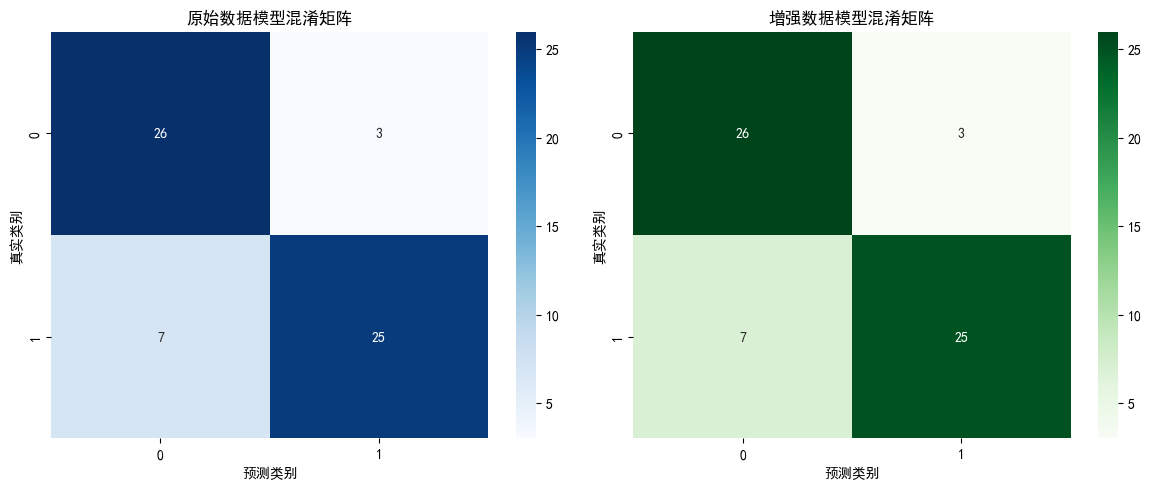
实验总结报告
一、数据分布分析
1. 原始类别分布
- 数据集规模:心脏病数据集共 303 条记录。
- 类别分布:患病(target=1)样本 165 条,健康(target=0)样本 138 条。
- 不平衡程度:不平衡比例约为 0.84:1,属于轻度不平衡数据集。
- 实验动机:因存在轻度不平衡,引入 GAN 进行数据增强,试图补充少数类(健康样本相对患病样本为少数类)数据,优化模型对少数类的识别能力。
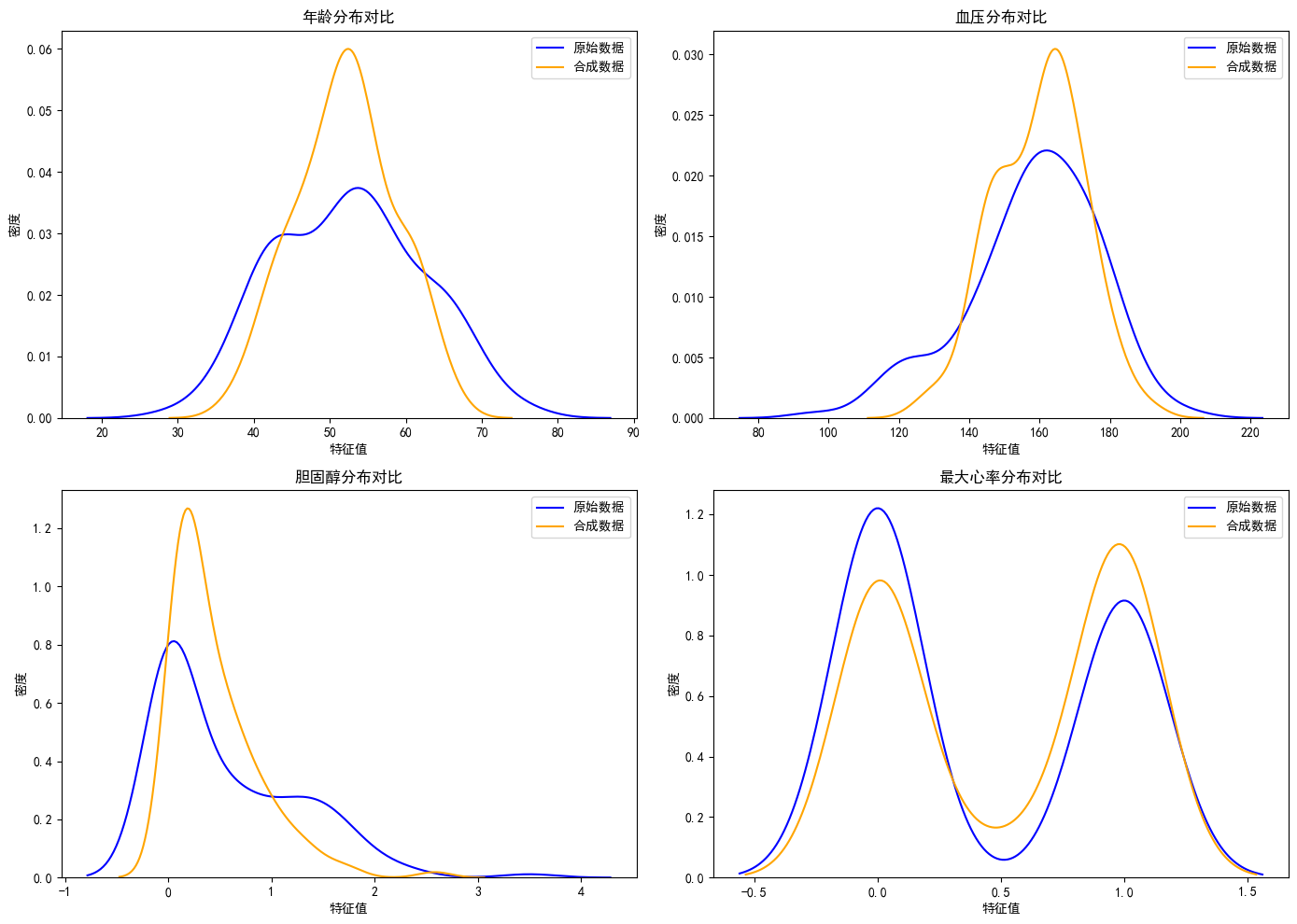
2. 合成数据分布
- 特征分布对比(年龄、血压、胆固醇、最大心率等关键特征):
- 整体趋势:合成数据与原始数据的核密度曲线形态接近,说明 GAN 生成的合成数据能一定程度模拟原始数据的分布模式,具备补充真实数据的潜力。
- 现存差异:部分特征(如胆固醇分布)的曲线形态仍有差异,反映生成数据与真实数据存在一定 gap。
- 优化方向:后续可尝试调整 GAN 网络结构(如增加层数、调整隐层维度)、训练参数(如学习率、迭代次数)以提升生成效果。
二、GAN 训练过程分析
损失曲线特征
- 前期阶段:判别器损失快速下降,生成器损失快速上升,体现判别器对真假数据的辨别能力快速提升,生成器努力学习生成更“逼真”数据。
- 后期阶段:二者损失进入相对稳定的波动状态,模型逐渐达到博弈平衡。
- 现存问题:损失值未趋近于理想低水平(如判别器损失未接近 0.5 附近稳定),可能因训练轮次不足、网络结构未充分拟合数据分布,或数据集特征复杂导致。
- 优化方向:可考虑延长训练周期、改进网络架构(如引入注意力机制、调整激活函数)。
三、模型评估指标分析
1. 混淆矩阵
- 分类格局:原始数据与增强数据训练的随机森林模型,混淆矩阵结构几乎一致。
- 健康样本(target=0):真实为健康的样本中,预测正确 26 例、错误 3 例。
- 患病样本(target=1):真实为患病的样本中,预测正确 25 例、错误 7 例。
- 结论:GAN 增强数据未显著改变模型对不同类别样本的分类正误格局。
- 可能原因:原始数据集不平衡程度较低,少量合成数据补充对模型决策边界影响有限;或生成数据质量不足,未提供足够有价值的新信息。
2. ROC 曲线与 AUC
- 曲线形态:两条 ROC 曲线形态接近,AUC 均为 0.93。
- 结论:模型在原始数据和增强数据上对正负样本的区分能力相当,整体预测性能良好,但增强数据未带来 AUC 提升。
- 可能原因:合成数据质量或数量不足,未有效强化模型区分能力;可尝试生成更多高质量数据或结合其他增强策略(如 SMOTE 结合 GAN)。
3. F1 分数
- 指标结果:原始数据与增强数据训练模型的 F1 分数均为 0.8333。
- 结论:GAN 增强后,模型在平衡精确率(precision)和召回率(recall)方面未体现优势;结合分类报告,两类样本的精确率、召回率无明显变化。
- 可能原因:当前实验设置下,GAN 增强未有效改善模型性能,需从数据生成质量、模型训练策略(如调整分类器参数、尝试其他分类模型)等方面优化。
四、整体结论与优化方向
本次实验中,GAN 虽能一定程度模拟数据分布,但因原始数据集不平衡程度不高、生成数据质量和数量有限等因素,未显著提升分类模型性能。
后续优化方向:
- 优化 GAN 训练:调整网络结构(如增加层数、引入注意力机制)、延长训练周期、优化超参数(如学习率、批次大小)。
- 探索多策略数据增强:结合 SMOTE 等传统方法与 GAN,提升合成数据质量与多样性。
- 改进分类模型:尝试其他分类器(如 XGBoost、LightGBM)或调整随机森林参数,挖掘模型潜力。
@浙大疏锦行