【论文阅读】Multi-Class Cell Detection Using Spatial Context Representation

代码地址:https://github. com/TopoXLab/MCSpatNet
摘要
在数字病理学中,细胞的检测与分类对于自动化的诊断和预后任务都至关重要。将细胞划分为不同亚型(如肿瘤细胞、淋巴细胞或基质细胞)尤其具有挑战性。现有方法多侧重于单个细胞的形态特征,而在实际操作中,病理学家常常依赖细胞的空间上下文来推断其类别。本文提出了一种新颖的方法,能够同时实现细胞的检测与分类,并明确引入空间上下文信息。我们采用空间统计函数,从多类别和多尺度的角度描述局部密度。通过表征学习与深度聚类技术,我们获得了融合形态特征与空间上下文的高级细胞表示。在多个基准数据集上,我们的方法在性能上优于现有的先进方法,尤其在细胞分类任务中表现更为出色。
引言
我们提出了首个联合细胞检测与分类的方法,该方法首次显式学习了细胞的空间上下文感知表示。我们证明,引入空间上下文可以显著提升性能,尤其是在细胞分类任务中。
在数字病理学中,从全片组织切片图像中识别各种类型的细胞(如肿瘤细胞、淋巴细胞和基质细胞)是实现自动诊断和预后的关键步骤。不同类型细胞的空间分布模式能够全面表征肿瘤与免疫细胞间的相互作用,并与临床结果密切相关 [29, 48, 23]。一个典型的例子是肿瘤浸润性淋巴细胞(TILs)的检测与量化,即分布在侵袭性肿瘤边缘内部的淋巴细胞 [36]。研究表明,TILs 的丰富程度与更好的临床结果相关 [37, 38, 41]。除了淋巴细胞之外,在侵袭性肿瘤前沿出现的孤立或小簇肿瘤细胞(称为肿瘤芽生)也是一种预后生物标志物,与结直肠癌及其他实体瘤中淋巴结转移风险增加有关 [28]。其他示例还包括对淋巴血管侵犯和神经周围侵犯的评估 [27],以及在乳糜泻诊断中对上皮内淋巴细胞的识别与量化 [34]。所有这些研究都需要一种高效算法,来准确识别不同类型的细胞。
多类别细胞识别任务既包含细胞检测,也包含细胞分类。过去几十年,细胞检测已经得到了广泛研究 [40, 21, 45]。现有方法主要分为两类:一类是借用计算机视觉中的目标检测算法 [20, 47],另一类是将其视为实例分割问题,对细胞核逐个分割 [18, 19, 32, 25, 30]。尽管分割方法能提供详细的细胞核形态,但训练这些方法需要高度精细的细胞核掩膜标注,耗时耗力。为了解决这一瓶颈问题,研究者提出了弱监督方法 [31, 46, 43, 11],仅依赖于点注释(即标注在细胞核中心的点)来进行分割。点注释是一种更具成本效益的大规模训练标注形式。
尽管在细胞检测方面取得了显著进展,细胞分类的研究进展却相对缓慢。实际上,即便对于人类专家而言,细胞分类仍是一项颇具挑战的任务。不同类型的细胞可能具有相似的外观特征;而同类型细胞在肿瘤或炎症区域中可能在形态和纹理上存在很大差异。要在如此复杂的背景下实现准确分类,病理学家不仅依赖细胞外观,还依赖于其周围细胞的上下文信息、空间关系和组织结构。例如,退变或凋亡细胞往往聚集在形成腺体的肿瘤的腔隙中,即便它们呈现多种不同的形态特征,也能在这种空间结构中被识别;类似地,当反应性基质细胞与肿瘤细胞的形态和染色质模式难以区分时,组织结构模式也可辅助其鉴别。
因此,设计理想的分类算法,关键在于模仿病理学家的诊断逻辑,将空间上下文纳入决策过程。与仅隐式学习上下文的方法不同 [19, 40],我们提出了一种新型算法,明确利用空间上下文进行学习。为建模空间上下文,我们引入了经典的空间统计学函数——Ripley 的 K 函数 [15]。K 函数能够以多类别、多尺度的方式编码细胞之间的空间关系,被证明是刻画细胞结构的有力工具 [48, 7]。但现有研究大多仅将 K 函数用于下游分析,而非用于提升细胞识别性能。
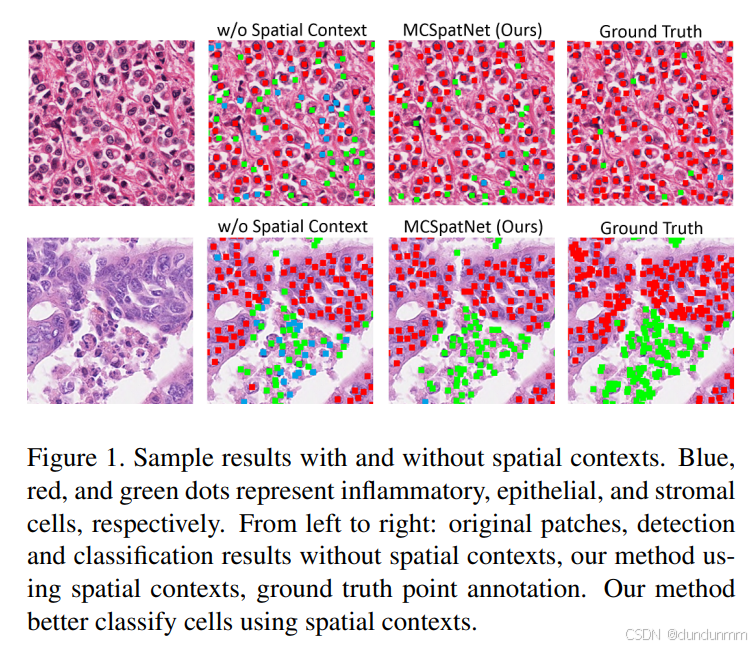
本研究的一个核心挑战在于:空间上下文在推理阶段是不可直接获得的——因为在未识别出细胞及其类别之前,无法计算 K 函数。为此,我们假设深度神经网络具有足够的学习能力,并提出通过多任务学习框架来学习空间上下文感知的表示。我们训练一个深度神经网络,联合完成细胞检测、细胞分类和空间上下文预测(即预测 K 函数)。在训练过程中,网络能够学习融合了外观特征与空间上下文的细胞表示。在推理阶段,仅使用检测与分类模块即可获得优异表现,得益于训练时学到的空间感知能力。图1展示了该过程的示意。
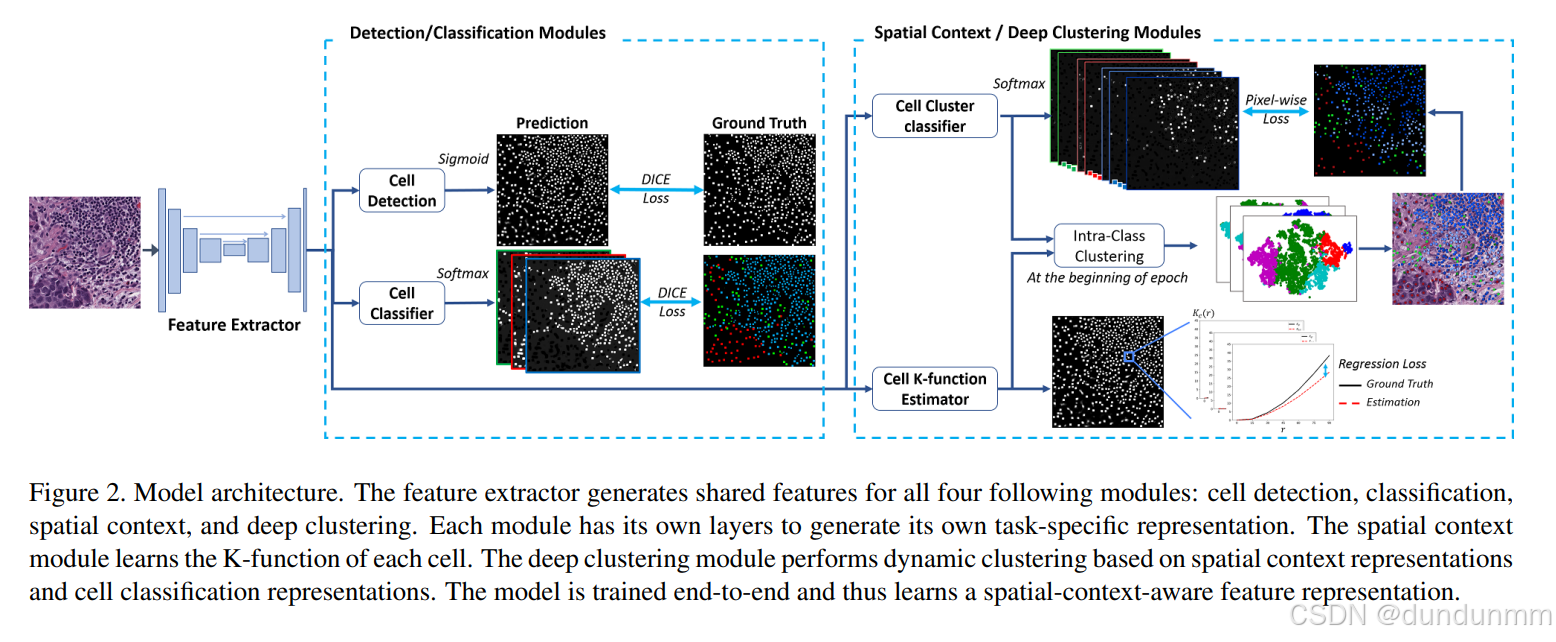
在多任务框架下进行学习具有一定挑战性,因为这些任务本质上差异较大。细胞检测与分类模块输出的是类别标签,而空间上下文预测模块则需输出高维连续值向量(K 函数)。为更好地融合这些任务,我们引入了一个深度聚类模块,灵感来自无监督和弱监督学习的相关研究 [10, 13]。该模块中,我们对深度表示进行聚类,生成伪标签,这些伪标签在细胞类别标签与 K 函数之间建立了连接,促进了各模块的协同与外观信息与空间信息的融合。图2展示了我们模型的整体结构。
我们将所提出的方法命名为 MCSpatNet,并应用于细胞联合检测与分类任务。我们在三个多类别点注释基准数据集(乳腺癌、结直肠癌和肺癌)上对该方法进行了评估。结果表明,我们的方法在性能上超越了多种现有先进方法,验证了空间上下文感知表示的有效性。
综上所述,我们的主要贡献如下:
-
提出了一种新颖的细胞检测与分类方法,首次通过多任务学习显式学习细胞的空间上下文感知表示;
-
引入空间统计函数(K 函数)作为细胞空间上下文的有效描述方式;
-
引入空间上下文预测模块与深度聚类模块,促进空间与外观特征的融合学习。
模型
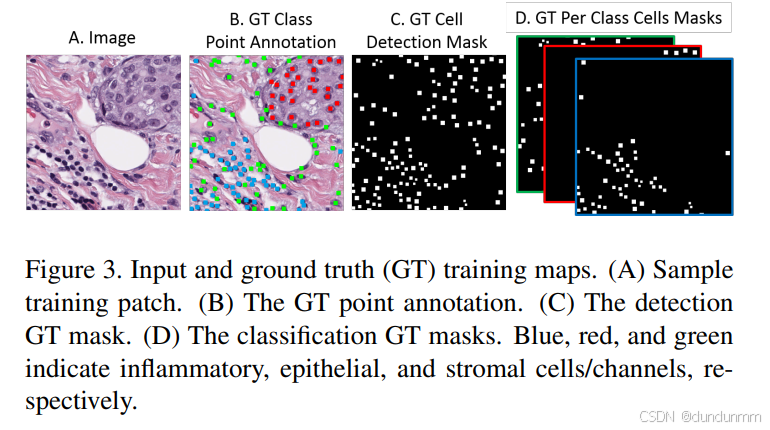
我们提出了一种用于 H&E 染色图像中细胞联合检测与分类 的方法。模型的预测结果和真实标注都是多类别的点标注形式:每个点位于细胞核的近似中心位置,并附带细胞的类别标签,包括 炎性细胞(inflammatory)、上皮细胞(epithelial) 和 基质细胞(stromal)。如图3所示提供了示意。
我们模型由多个执行不同任务的模块组成。这些模块共享相同的输入和特征提取器,但各自拥有独立的卷积层块,用于完成其特定的预测任务。通过这种方式,各模块可以在共享表示的基础上协同学习而不会互相干扰。
模型架构如图2所示。除了细胞检测与分类模块外,我们的方法还引入了两个额外模块:
-
空间分布预测模块(Spatial Distribution Prediction Module):该模块学习预测细胞相关的空间统计函数,从而具备了汇聚描述空间上下文信息的能力。
-
基于细胞级别的深度聚类模块(Cell-level Deep Clustering Module):该模块根据细胞的特征表示进行迭代聚类,并预测聚类结果,融合了细胞的外观特征和空间上下文,以获取更优的特征表达。
注:我们的图像块选自癌变区域,因此上皮细胞均为肿瘤细胞。
2.1 细胞的空间上下文建模(Cellular Spatial Context)
我们将一个细胞的空间上下文定义为其邻域中不同类别细胞的分布情况。为此,我们引入了 Ripley 的 K 函数 ——一种描述点模式的空间统计函数 [15, 5]。
对于一个被关注的细胞(称为“源点”),我们可以统计其一定距离 r 范围内的邻居细胞数(称为“目标点”)。将所有观测点汇总后,K函数就成为一个累计分布函数,表示源点在不断增大的距离 ri 内所预期的邻居数。如图4所示。

形式上,给定一个大小为 n 的二维点集 X,K函数定义如下:
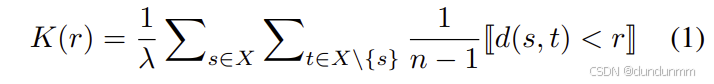
其中:
-
d(s,t)是源点 s 与目标点 t的欧氏距离;
-
⟦⋅⟧是 Iverson 括号,条件为真时值为 1,否则为 0;
-
λ是归一化的强度函数,用于调整源点密度的影响。
根据建模假设,λ 可以是常数(即 \frac{\text{Area}}{n},均质情形),也可以依赖于位置(非均质情形)。
我们可以将计算出的 K 函数与基线进行比较,例如与泊松随机点过程(Poisson Point Process)对应的 K 函数比较:
-
当目标 K 函数高于基线时,表示邻域中的目标点比随机分布中期望的更多,说明 存在聚类;
-
当目标 K 函数低于基线时,说明邻域中目标点比随机期望的更少,表现为 离散。
对于多类别点集,我们将 K 函数扩展为支持源点和目标点来自不同类别的情况,此时该函数被称为 K-交叉函数(K-cross function)。
特异性细胞的 K 函数及其向量化
在细胞检测与分类任务中,我们关注的是单个细胞,而非整个细胞群体的空间关系。对于给定的源细胞s,我们限制在其周围的一个固定大小区域内进行空间上下文分析,仅考虑落在该局部区域(patch)内的目标细胞。我们对不同类别的目标细胞逐一计算其空间关系。对于类别 c,记 Xsc为以 s 为中心的局部区域内所有类别为 c 的细胞集合。类别 c 的 K 函数定义如下:
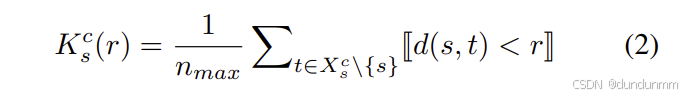
其中,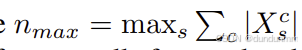 表示所有局部区域内目标细胞的最大数量,用于归一化处理。
表示所有局部区域内目标细胞的最大数量,用于归一化处理。
在实际操作中,我们设定局部 patch 的大小为 180 × 180 像素,并在一组有限的半径值上对 K 函数进行均匀采样,半径值为:15, 30, 45, ..., 90 像素。由于我们处理三类细胞,每类采样 6 个半径,共得到一个 18 维的向量。我们将其称为细胞 sss 的 K 函数向量(K-function vector)。通过学习预测这个 K 函数向量,模型能够学习细胞的空间表示能力。
K 函数与细胞的空间行为
我们通过真实示例进一步说明 K 函数如何帮助细化细胞的空间表示。在图 5 中,我们可视化了不同类别细胞及其对应的 K 函数表现。由于 K 函数是高维数据,无法直接可视化其数值,因此我们将每类细胞按照其 K 函数向量进行聚类,并使用不同颜色对不同子类细胞进行可视化(炎性细胞为深蓝到浅蓝,间质细胞为深绿到浅绿,上皮细胞为深红到浅红/粉红)。
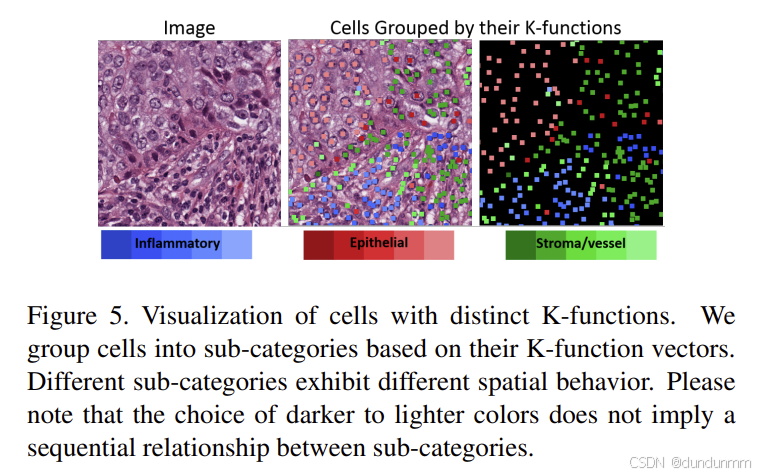
我们观察到,不同子类细胞呈现出明显不同的空间行为特征。例如,上皮细胞中聚集于肿瘤巢中的细胞通常属于粉红子类,而那些较分散且靠近间质细胞的细胞属于红色子类。间质细胞中,浅绿色子类通常靠近其他类别细胞(如炎性或上皮细胞),而深绿色子类则往往远离其他细胞。炎性细胞也表现出类似趋势:浅蓝子类较为聚集,深蓝子类较为分散。
此外,图 6 显示了不同类别细胞对之间的平均 K 函数结果,明显表明不同类别对的空间行为各不相同。
这些发现表明,K 函数可以有效地将细胞划分为具有不同空间行为的子类,从而进一步推动我们通过 K 函数来学习细胞的空间表示能力。
2.2 空间上下文感知表示的多任务学习
我们提出的模型包含四个用于不同任务的模块:细胞检测、细胞分类、深度聚类和空间上下文预测。这四个模块共享一个特征提取器,该提取器学习通用的特征表示。其中,深度聚类模块和空间上下文预测模块仅在训练阶段使用,其目的是学习一个具备空间上下文感知能力的表示,从而提升细胞检测和分类的性能。请参见图2了解模型架构。
特征提取器
特征提取器是一个U-Net变体,其编码器采用VGG-16结构。提取器输出96通道的特征图,空间分辨率与输入图像相同。这一特征表示被四个任务模块共享。
每个任务模块都有其专属的卷积层块。这些块的输入输出分辨率与原图一致,但输出通道数因任务而异。这种设计允许各任务根据自身需求调整特征,不会发生冲突。因为这些任务的性质差异较大,既包括分类任务,也包括回归任务。尤其是深度聚类任务具有很强的动态性,若不使用单独的模块,可能会导致特征提取器不稳定,进而影响其他任务的性能。
接下来,我们介绍每个任务模块的细节。
细胞检测与分类模块
在细胞检测任务中,模型对每个像素预测一个单通道的置信度图,并与二值真值掩膜进行比较。该真值掩膜是对细胞点注释进行适度膨胀得到的。对于靠得较近的细胞,我们使用更小的膨胀半径以避免重叠。掩膜中的每个连通区域对应一个细胞,见图3。该模块的输出是单通道图像,使用Sigmoid激活函数,并采用DICE损失函数进行训练,以更好地保留图像中的小目标。
在分类任务中,我们构建了类似的真值掩膜,但每个连通区域内的像素标记为特定的细胞类别。分类模块的输出具有三个通道,对应三种细胞类别,使用Softmax激活并同样采用DICE损失函数训练。
推理阶段,仅使用检测与分类模块。我们对检测模块的输出进行阈值处理,并提取每个连通区域的质心作为预测的细胞位置。随后,在预测位置上从分类模块的输出中提取类别标签。
空间上下文预测模块
空间上下文预测模块用于预测每个细胞的K函数向量(如公式(2)所定义)。其直觉是:通过预测空间上下文信息,所学习的特征表示能具备空间上下文感知能力,从而辅助检测与分类模块。我们将在实验部分通过消融实验验证这一点。
对于每个细胞,我们预测一个18维的K函数向量。其真值由细胞检测任务生成的真值掩膜得出。对于每个阳性像素(即膨胀区域内的像素),我们计算其K函数向量。该模块的输出具有与输入图像相同的空间分辨率,并包含18个通道,对应K函数向量的18个维度。无需额外激活函数,仅比较阳性像素处的预测与真实向量。
比较两个K函数向量时,可使用Kolmogorov–Smirnov检验(用于比较累积分布函数)。其形式为预测与真实向量之间的最大差值:
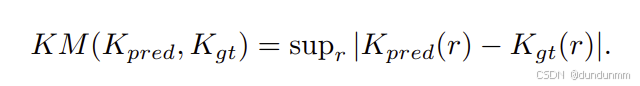
但在实际中,我们发现最大范数效率较低,故改用L1范数作为代理损失。
深度聚类模块
尽管空间上下文预测模块可学习空间上下文表示,但实践中我们发现它与检测和分类模块协同效果较差。我们推测,外观特征与空间特征融合效果不佳,可能是因为它们任务本质差异太大:检测与分类是小类别的像素级分类任务,而空间上下文预测是高维回归问题。
为此,我们引入深度聚类模块,用于重新校准外观与空间特征。该模块本质上是一个具有大量伪类别的像素级分类任务,伪类别由外观和空间信息联合生成。深度聚类在弱监督与无监督任务中已被证实可增强特征表示,符合我们的场景需求:我们没有细胞子类别的金标准,而是动态生成这些子类别,并训练模型去预测它们。
具体而言,我们对中间特征表示进行K-means聚类,得到每类细胞的5个伪子类别。深度聚类模块的结构与分类模块类似,用于预测这些伪标签。聚类所用的特征为深度聚类模块与空间上下文预测模块的特征拼接,确保融合空间与外观信息。
每个训练周期开始时,重新生成聚类与伪标签,且使用前一周期的聚类中心初始化以避免剧烈变化。训练方法与分类任务类似,使用DICE损失。
总体损失函数
模型的总损失是四个模块损失的加权和:
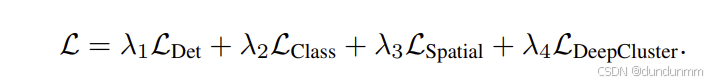
在实践中,我们将所有权重均设为1。
实验
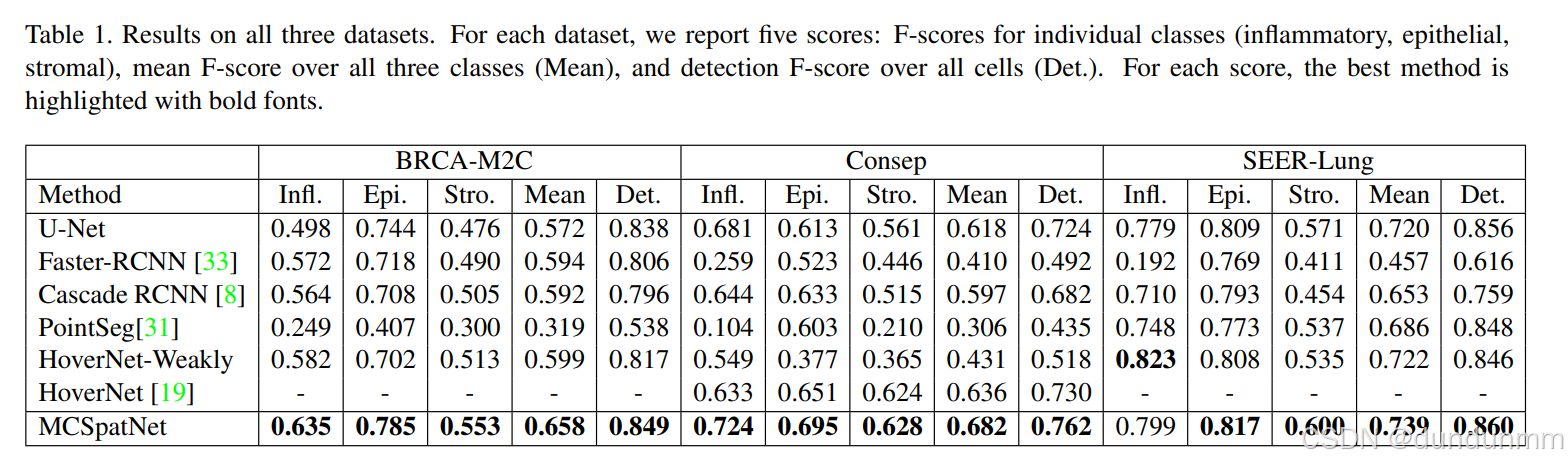
我们在三种不同癌症类型的数据集上评估了我们的方法 MCSpatNet:乳腺癌、肺癌和结直肠癌。
-
乳腺癌数据集(BRCA-M2C) 包含来自 TCGA 数据库 [42] 的 113 位患者的 120 个图像块。
-
肺癌数据集(SEER-Lung) 来自 SEER 队列 [16],包含 57 个图像块。
-
结直肠癌数据集(Consep) 是一个公开可用的数据集 [19],共包含 41 个图像块。
每个图像块均从不同的全切片图像或组织样本中采样,以最大化泛化能力。所有三个数据集中的图像块大小均约为 500×500 像素,在 20 倍放大倍率下获取,足以提供丰富的空间上下文信息。
乳腺癌和肺癌数据集由病理学专家进行注释,给出了细胞近似中心点的真实标签,并标注了所属类别:炎性细胞(inflammatory)、上皮细胞(epithelial) 或 基质细胞(stromal)。需要指出的是,这些图像块中的所有上皮细胞均为肿瘤细胞。
Consep 数据集还额外提供了细胞核轮廓的掩膜信息。
画的图很喜欢,学习