记录lxml中的etree、xpath来定位、爬取元素
有如下一个网页,想要抓取其中内容,主要是IP Address和Port,使用python实现。
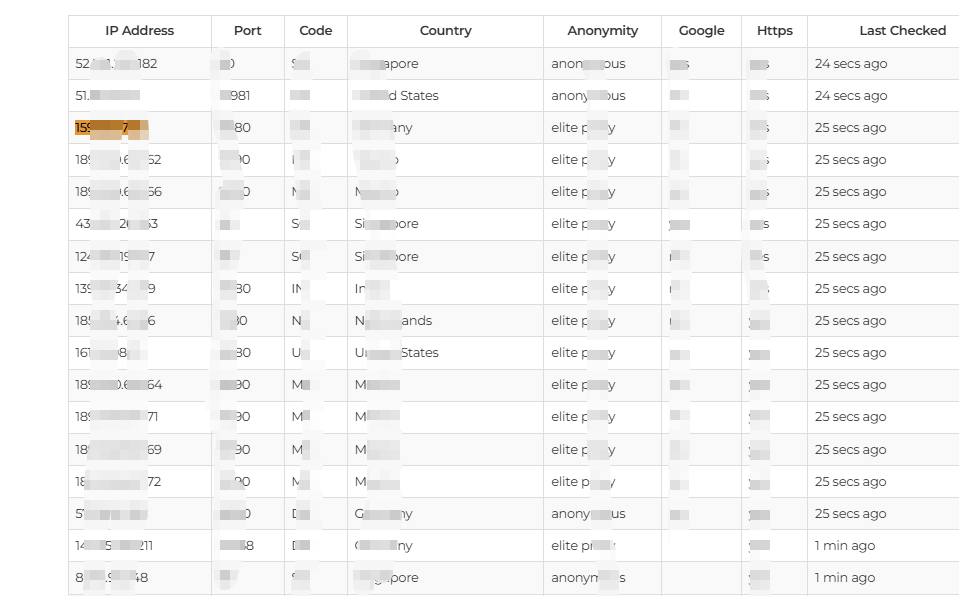
用F12看一下网页源代码,对应上图表格内容的部分如下:
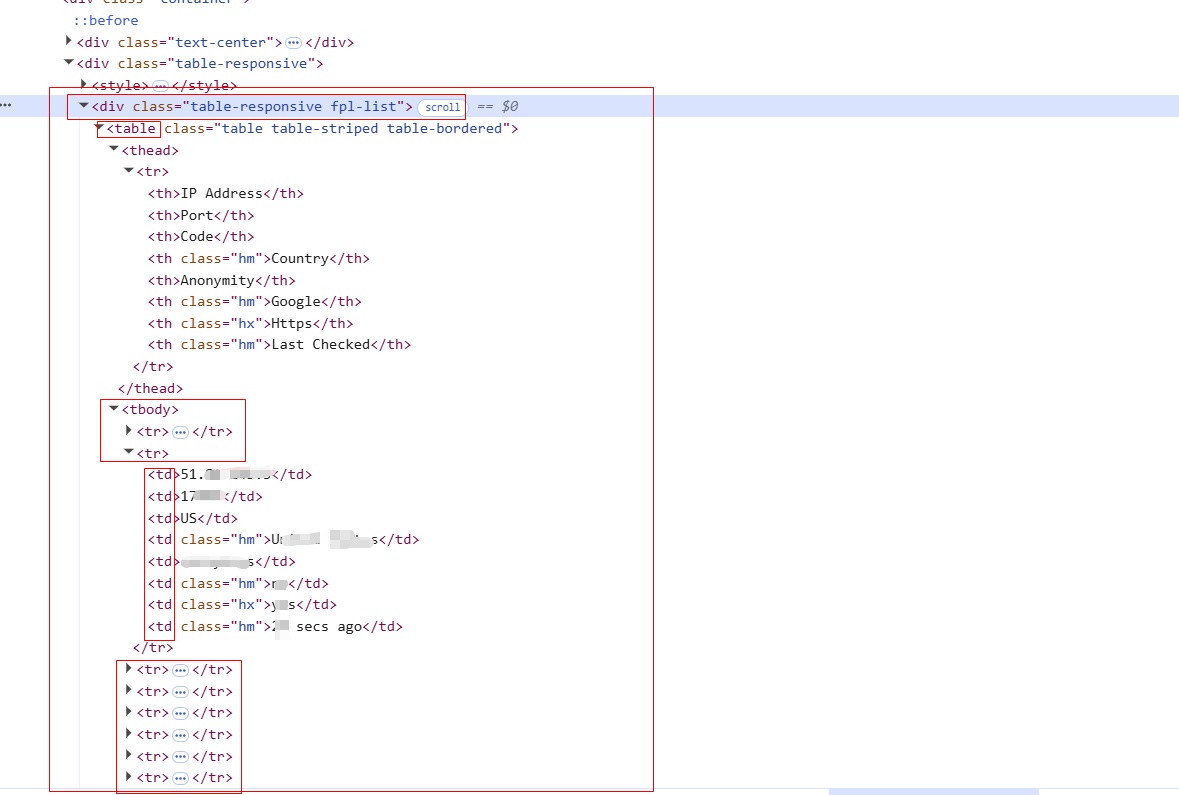
使用python和lxml来定位爬取。
首先要安装lxml,如下命令(可以在pycharm项目的Terminal中运行):
pip3 install lxml
实现代码:
from lxml import etree
import requestsurl = 'https://www.example.com'
r = requests.get(url)
result = r.text
html = etree.HTML(result)rows = html.xpath(".//div[@class='table-responsive fpl-list']/table/tbody/tr[position()>0]")proxy_list = []
for row in rows:td_list1 = row.xpath('./td[1]')td_list2 = row.xpath('./td[2]')ip = td_list1[0].text.replace(' ','').replace('\t','').replace('\n','')port = td_list2[0].text.replace(' ','').replace('\t','').replace('\n','')web_proxy = {'ip': ip, 'port': port, 'types': 0, 'protocol': '0', 'country': '0', 'area': '0', 'speed': 100}proxy_list.append(web_proxy)print(proxy_list说明:
在HTML中,tr、td、th是用于构建表格的核心标签:tr(Table Row)定义表格行,td(Table Data)定义标准数据单元格,th(Table Header)定义表头单元格。
结合上述代码,rows即是获取的表格中的所有行。
然后针对每一行进行操作。从每一行中,定位并获取需要的单元格的文本内容(此行第一列的单元格就是td[1],第二列就是td[2],使用.text获取其文本内容,注意:使用row.xpath获取出的是一个列表,需要加一个[0]来成为单个元素)。