【论文阅读】Qwen2.5-VL Technical Report
Arxiv:https://arxiv.org/abs/2502.13923
Source code:https://github.com/QwenLM/Qwen2.5-VL
Author’s Institution:Alibaba
背景
多模态大模型
多模态大模型MultiModal Large Language Models (MM-LLMs) 的发展可以通过一篇综述了解:MM-LLMs: Recent Advances in MultiModal Large Language Models.
现在先以一个小白的视角看一下所谓的多模态大模型是什么样的,包括模型的输入、输出能够解决什么问题等等。从上面提到的综述上看,多模态大模型的模型结构一般如下:
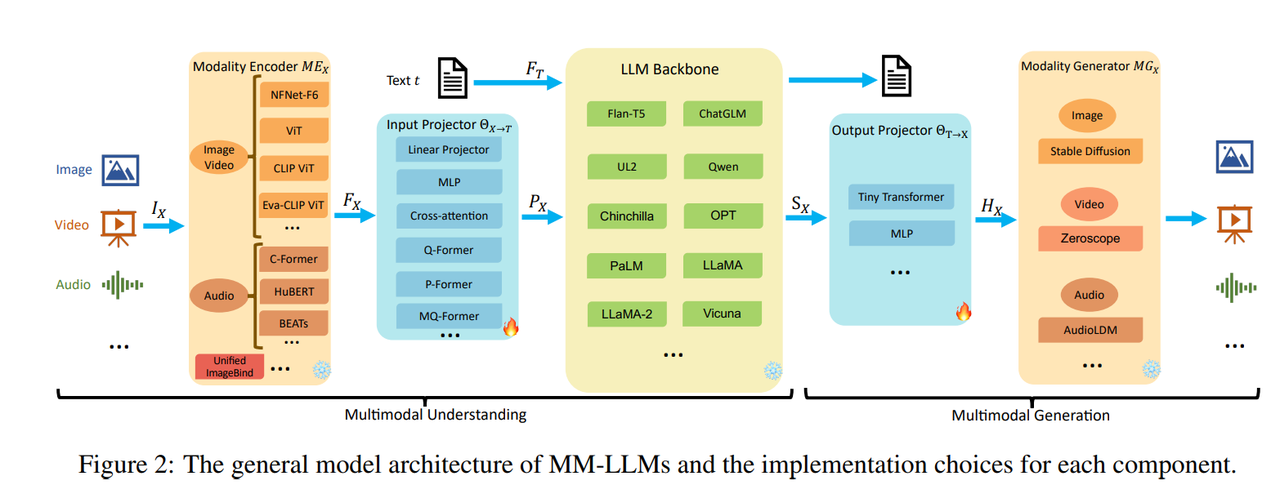
多模态大模型的输入、输出可以是图片、视频、语音等。结构上主要分为两个模块:多模态理解、多模态生成。
多模态理解主要有以下模块:
- Modality Encoder(模态编码器):提取多模态的特征为embedding,模态编码器通常是单独针对对应模态的数据进行了预训练。
- Input Projector(输入投影):将模态编码器的输出映射到LLM的输入特征空间的适配层,即不同模型数据空间信息模态对齐(将其他模态数据对齐到文本域空间)。
- LLM Backbone(LLM主干网络):这里的输入通常有text模态数据(人们发布指令或者希望大模型做什么事情还是通过文本描述的形式以让大模型给出预期结果)和其他对齐到text模型空间的模态数据。LLM是经过预训练的语言模型,用来理解输入的模态数据。
多模态生成主要有以下模块: - Output Projector( 输出投影):LLM主干网络根据自身对输入数据的理解输出一系列数据。该模块则是将LLM输出的数据映射成Modality Generator可理解的特征空间。
- Modality Generator(模态生成器):根据输出投影的结果生成最后的结果。
QwenVL
Qwen-VL模型则是一系列视觉+文本多模态理解模型Large vision-language models ( LVLMs ),主要处理文本和视觉特征,即"Text、Image、Video" in,“Text” out。 系列模型也在不断更新,先后发布了:Qwen-VL、Qwen2-VL、Qwen2.5-VL(2025年2月更新)。
截止目前,现有的视觉大语言模型主要遇到的问题或者瓶颈:计算复杂性、有限的上下文理解、较差的细粒度视觉感知以及不同序列长度的不一致性能等问题。Qwen2.5-VL在不断迭代和优化中解决了一些问题。
方法论
模型结构
Qwen2.5VL的模型结构如下:
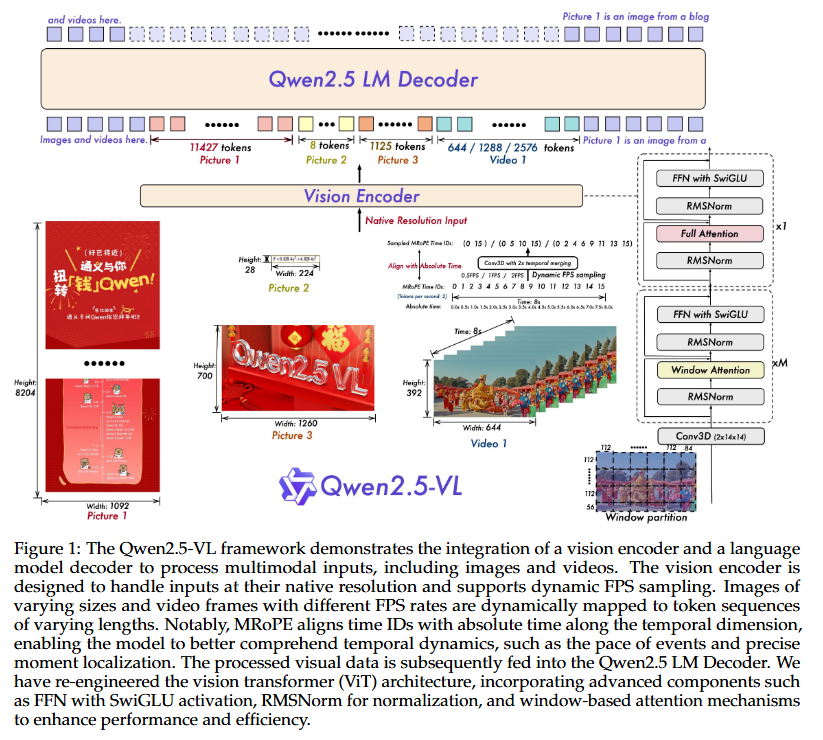
Qwen2.5VL系列模型结构主要包含三个模块:
- LLM: 语言模型是多模态大模型非常基础的模块,有类似于“大脑”的功能,使用的语言模型是Qwen2.5 LLM,为了能够更好的理解多模态,作者修改了1D RoPE(Rotary Position Embedding,旋转位置编码)为于绝对时间对齐的多模态旋转位置嵌入。
- 视觉编码器:使用的是重新设计的Vision Transformer(ViT)结构。
- MLP-based的视觉-语言融合器:使用基于多层感知机来将vit输出特征做进一步压缩以及对齐到text域中。
不同参数的模型配置如下:
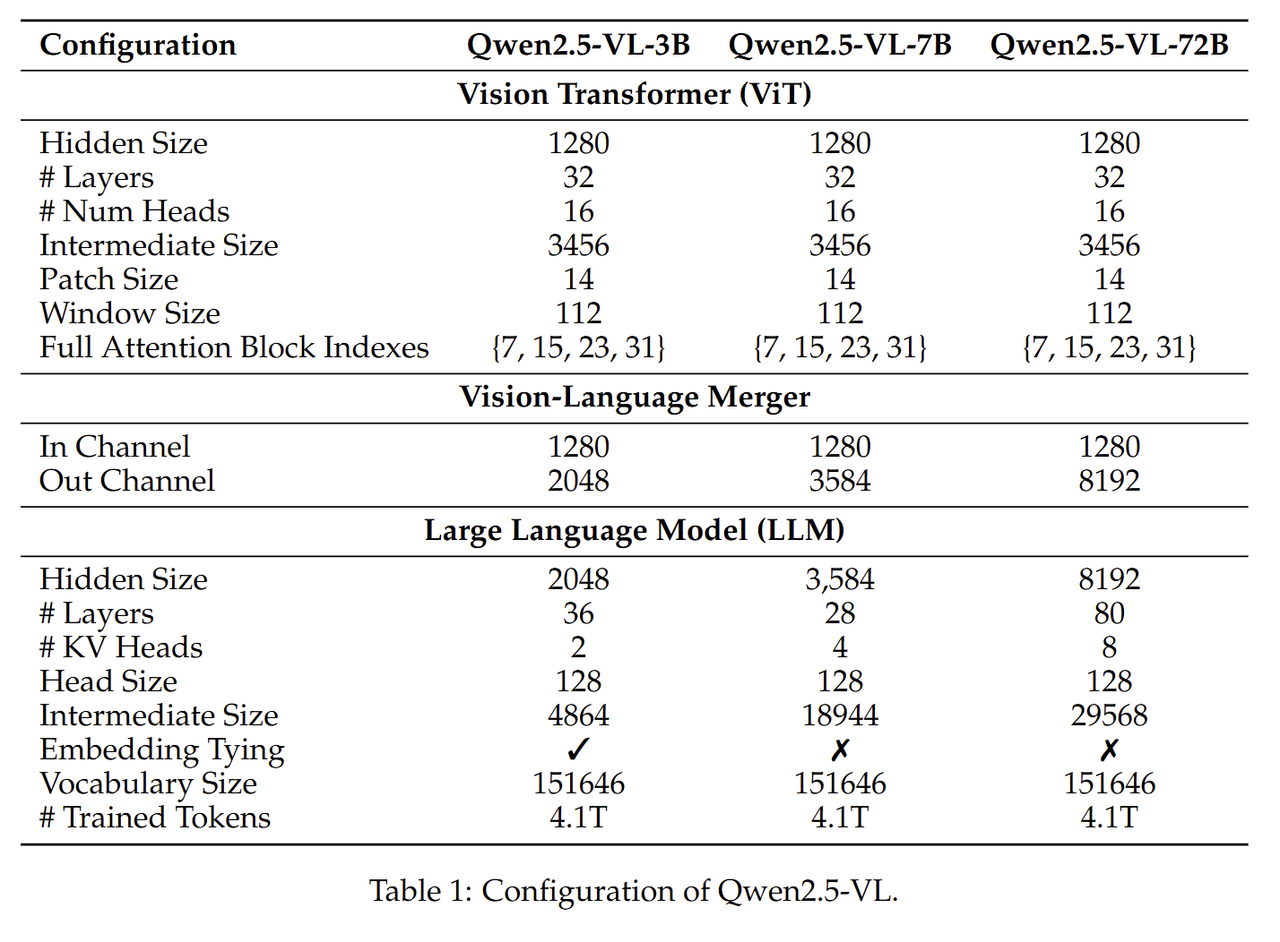
补充:qwen2.5vl-32b的模型也在2025年5月开源。
视觉编码器
在视觉编码器的主要创新点:
- 实施窗口注意力机制:将窗口注意力引入视觉编码器以优化推理效率。
- 引入动态FPS采样:将动态分辨率扩展到时域维度,使模型能够全面理解不同采样率下的视频。
- 升级MRoPE:在时域上对齐至绝对时间,从而促进更加复杂的序列学习。
具体如何实现的后续继续研读代码。
预训练
预训练语料大约4T的token。相关数据分别在模型训练阶段使用情况:
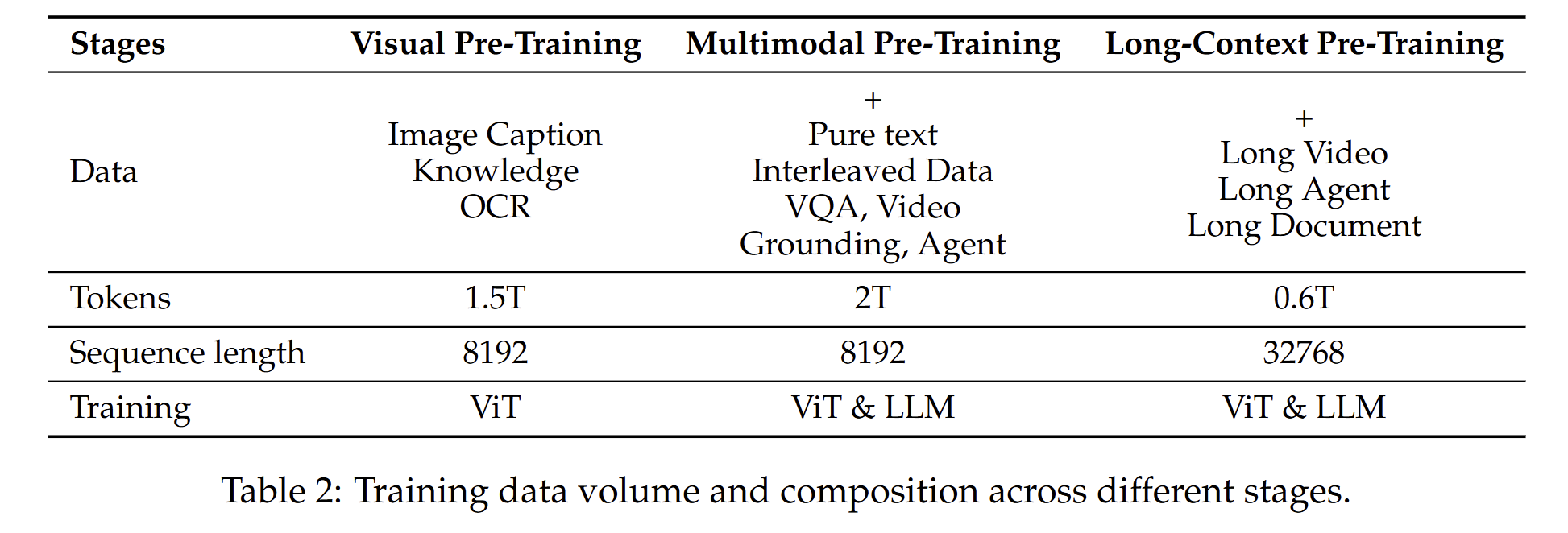
视觉编码器模块的ViT先使用DataComp以及内部的数据进行初始化,使用预训练的qwen2.5语言模型初始化LLM模块。预训练过程分为三个阶段:
- 只训练ViT模块去对齐(alignment)视觉和语言模块,训练过程冻结语言模块,为多模态里面打下基础。
- 视觉模块和语言模型全部参与训练,数据更加复杂。通过该阶段的训练,增加了模型的建立视觉和语言链接的能力以能够进一步应对推理的需求;
- 该阶段通过增加比较长的训练数据,进一步增强模型的推理能力。
可参考qwenvl训练流程:
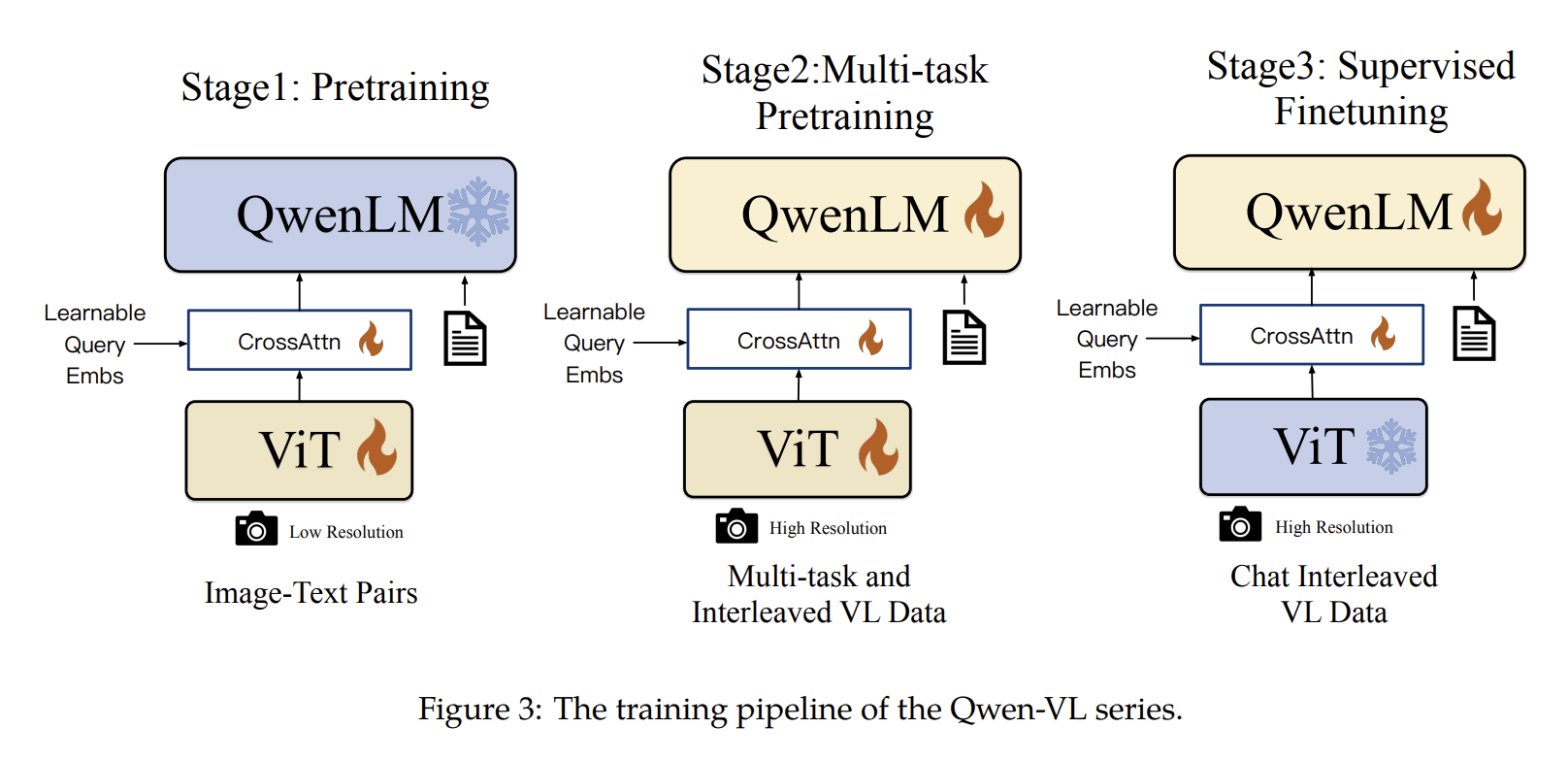
后训练
这部分主要使用SFT(Supervised Fine-Tuning)和DPO(Direct Preference Optimization)方式。SFT监督微调旨在通过目标指令优化弥合预训练表示和下游任务需求之间的差距,本质上来说是进一步提升指令跟随能力。
大量的工作关注于:收集和过滤出高质量的训练数据。例如构建了数据过滤的pipeline,使用了多种策略过滤,例如:基于规则的、基于模型的以及Rejection Sampling(拒绝采样)。
然后使用这些精心收集的数据进行后训练(SFT和DPO),后训练过程中,视觉编码器ViT的参数是被冻结的。
实验
相比于当时的开源、闭源的模型在主要的评测数据集的效果如下:
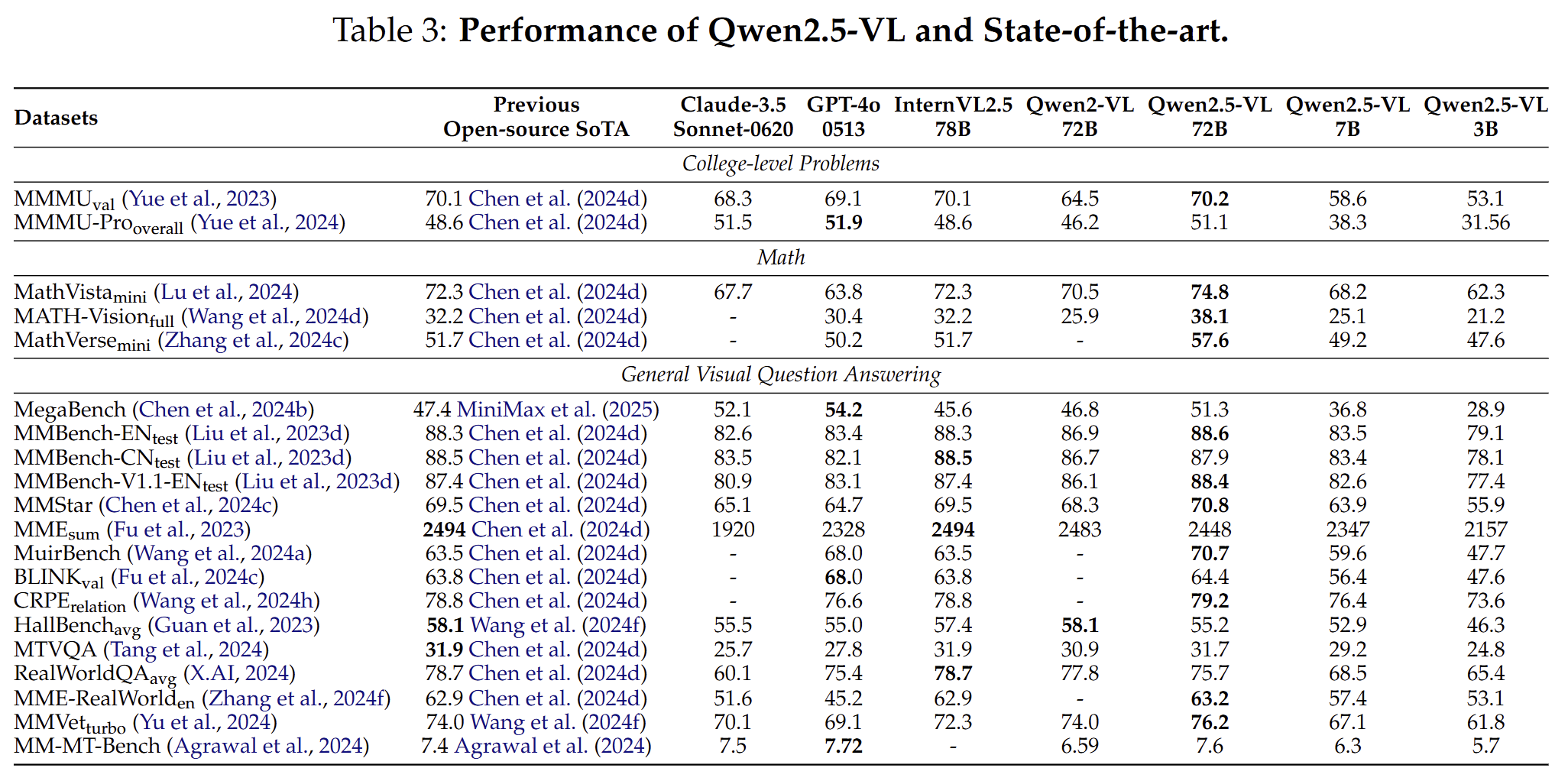
总得来看,qwen2.5vl-72b在很多数据集的效果是sota的。同时作者也验证了,多模态大模型维持了语言模型的性能,如下表:
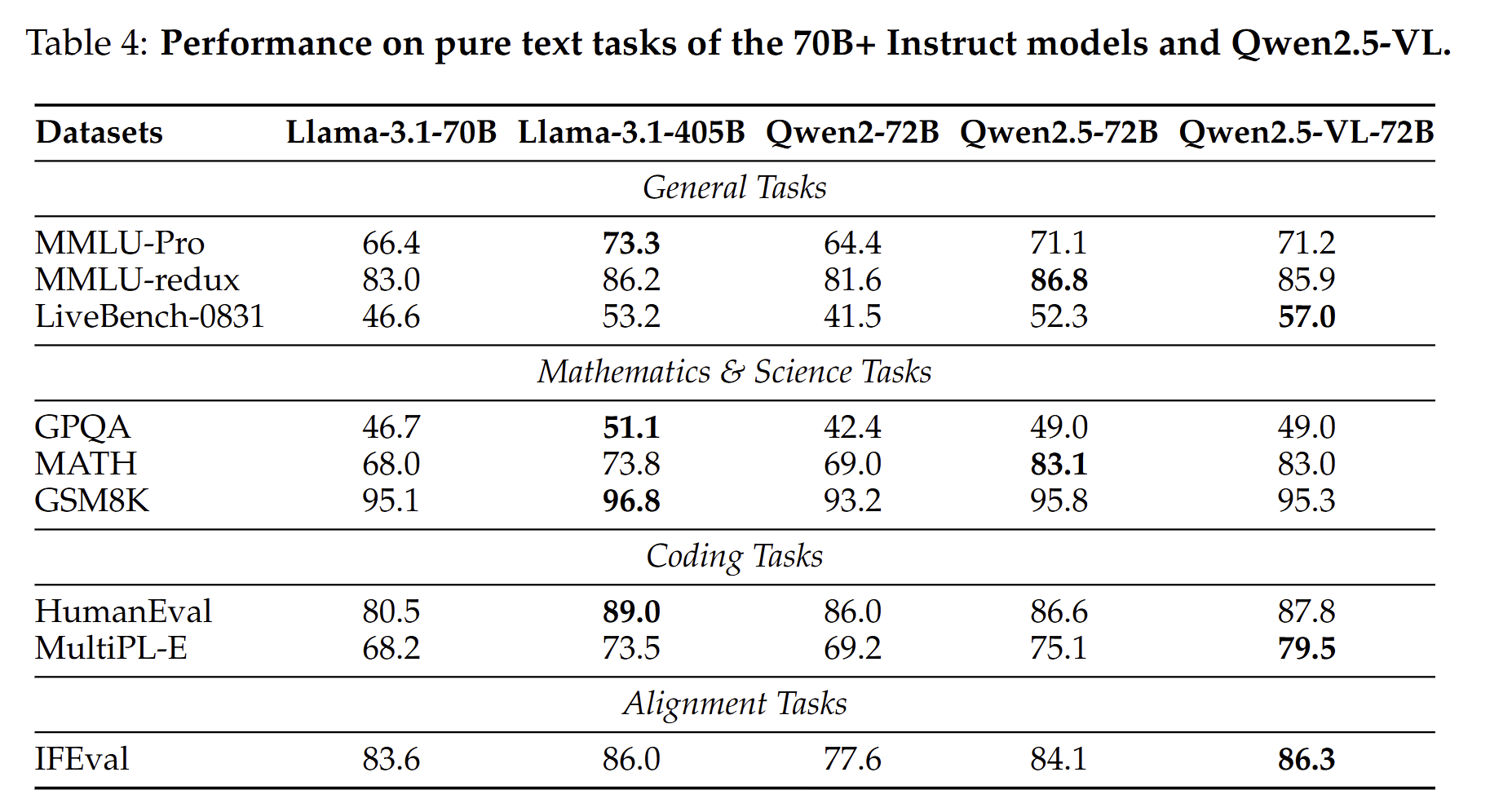
但在我们的实际场景中可能更加关注具体的领域业务,例如文档理解和OCR效果,可以参见下表:
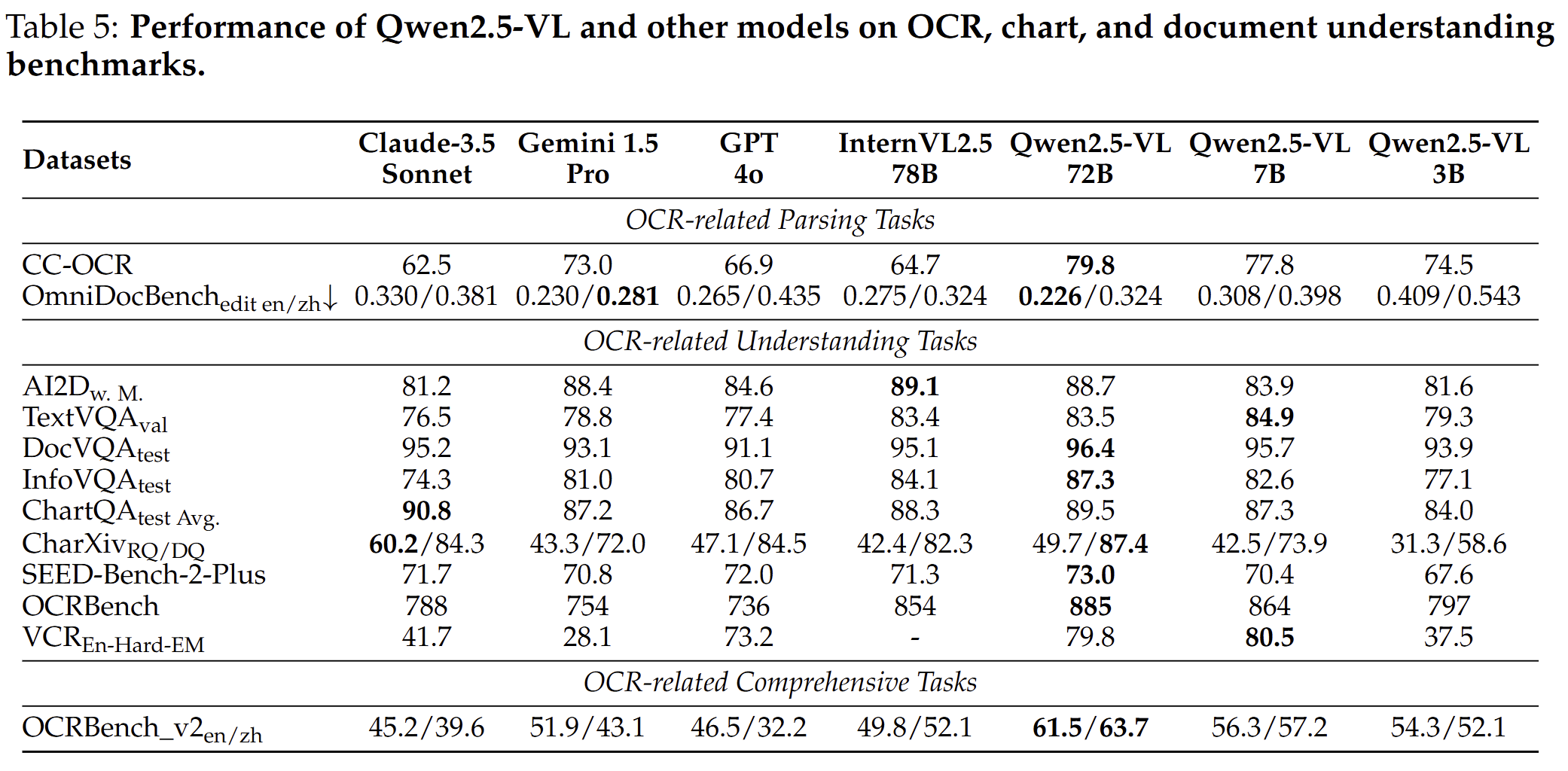
整体来说效果还是不错的,如果在自己的业务数据做进一步的微调的话,应该是可以达到落地标准的。
此外还有视频理解还有Agent的功能,具体可参见原文。
总结
文章优点
本文提出了一种名为Qwen2.5-VL的视觉语言模型系列,该模型在多模态理解和交互方面取得了显著进展。其增强的视觉识别能力、对象定位能力、文档解析能力和长视频理解能力使其在静态和动态任务中表现出色。此外,它具有原生的动态分辨率处理和绝对时间编码功能,可以高效地处理各种输入,并通过减少计算开销而不牺牲分辨率精度来降低计算负担。Qwen2.5-VL适用于从边缘AI到高性能计算的各种应用。旗舰版本Qwen2.5-VL-72B与领先的模型如GPT-4o和Claude3.5 Sonnet相比,在文档和图表理解方面匹配或超过它们,同时保持纯文本任务的良好性能。较小的Qwen2.5-VL-7B和Qwen2.5-VL-3B变体优于相应大小的竞争者,提供效率和灵活性。Qwen2.5-VL为视觉语言模型树立了新的基准,展示了在跨领域的任务执行和一般化方面的卓越表现,为更智能和互动系统的发展铺平了道路,实现了感知和现实世界应用之间的桥梁。
方法创新点
本文的主要贡献在于以下几个方面:
- 实施窗口注意力机制:将窗口注意力引入视觉编码器以优化推理效率。
- 引入动态FPS采样:将动态分辨率扩展到时域维度,使模型能够全面理解不同采样率下的视频。
- 升级MRoPE:在时域上对齐至绝对时间,从而促进更加复杂的序列学习。
- 数据集构建:致力于高质量数据的收集和整理,进一步扩大预训练语料库规模。