篇章六 论坛系统——业务开发——实现业务功能
1.主要的包和目录及其主要功能

2.注册
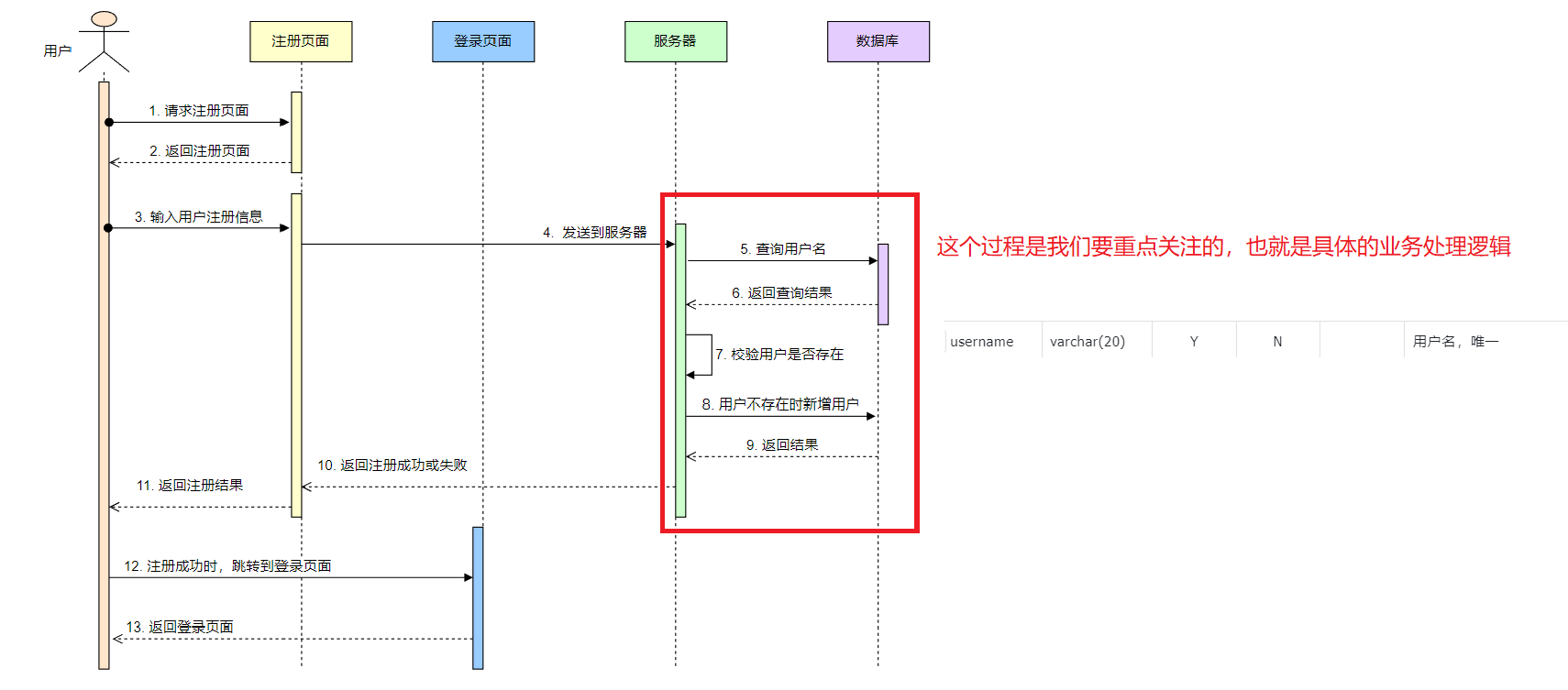
2.1 顺序图
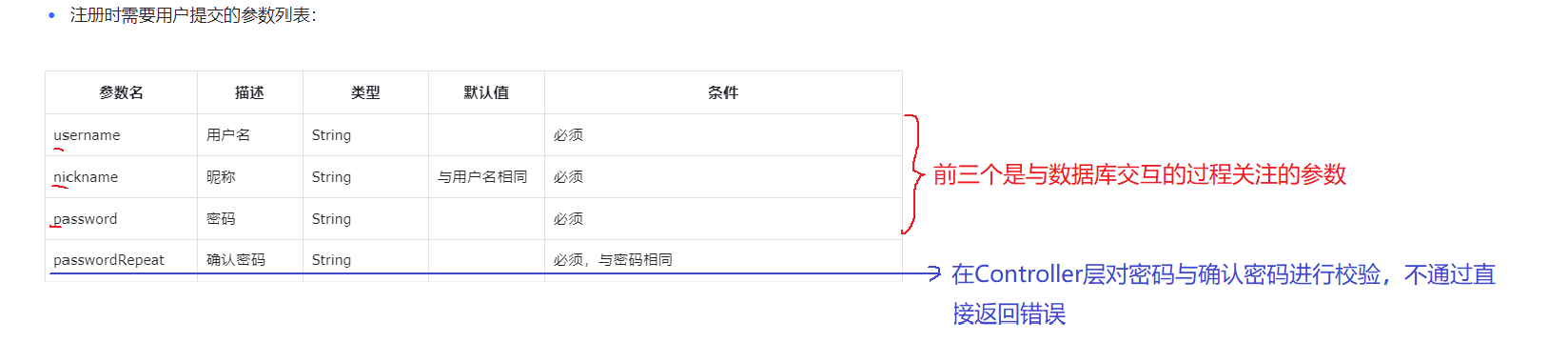
2.2 参数要求
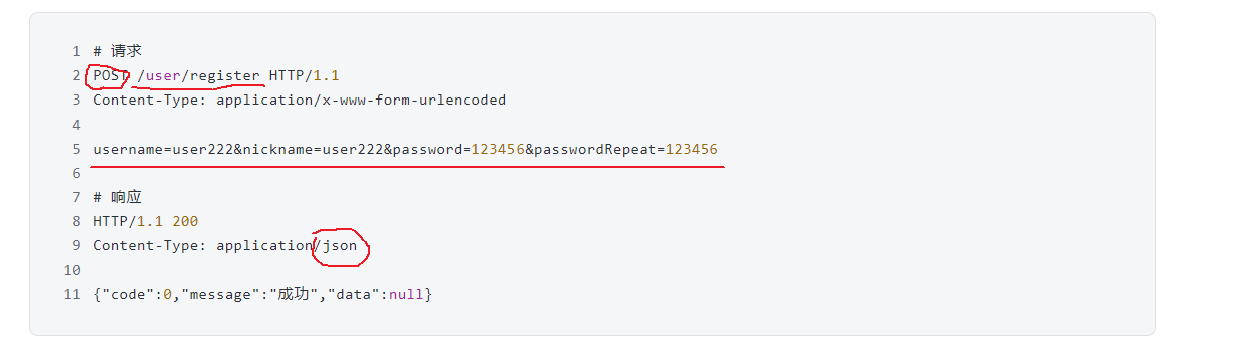
2.3 接口规范
2.4 实现步骤


1.定义SQL
按用户名查询用户信息
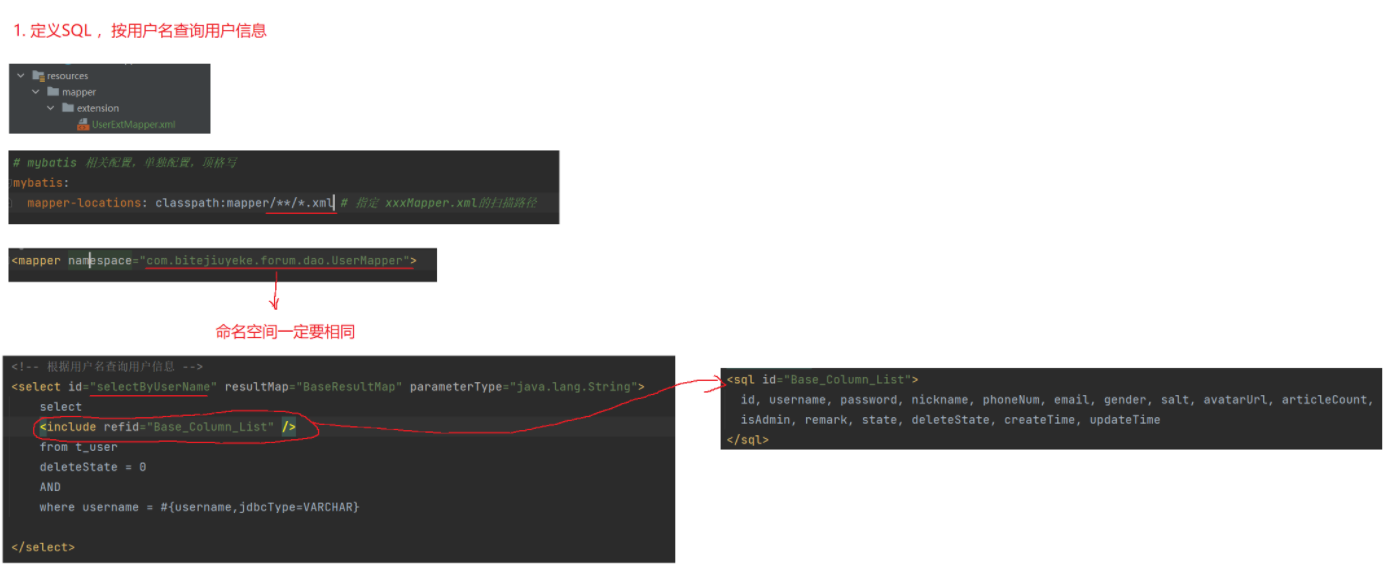
<!--1.注意namespace表示命名空间,指定要与UserMapper.xml中的namespace相同2.统一用com.example.forum.dao.UserMapper,也就是UserMapper的完全限定名(包名+类名)3.不同的映射文件指定了相同的namespace后,定义的所有用id或name标识的结果集映射都可以在不同的文件中共享--><select id="selectByUserName" resultMap="BaseResultMap" parameterType="java.lang.String">select<include refid="Base_Column_List"/>from t_userwhere deleteState = 0<!--1. #{} 占位符允许你在 SQL 查询中动态插入参数值。这些参数值可以在执行查询时从 Java 方法的参数中获取2. 防止 SQL 注入使用 #{} 占位符可以有效防止 SQL 注入攻击。MyBatis 会将参数值作为预处理语句(PreparedStatement)的参数,而不是直接拼接到 SQL 字符串中。这样可以避免恶意输入被当作 SQL 代码执行。3. 为什么需要 jdbcType1)类型安全:指定 jdbcType可以确保 MyBatis 在处理参数时不会出现类型不匹配的问题。2)指定 jdbcType 可以帮助数据库优化器更好地理解参数类型,从而提高查询性能-->AND username = #{username, jdbcType=VARCHAR}1.1 Mapper中resultMap的作用
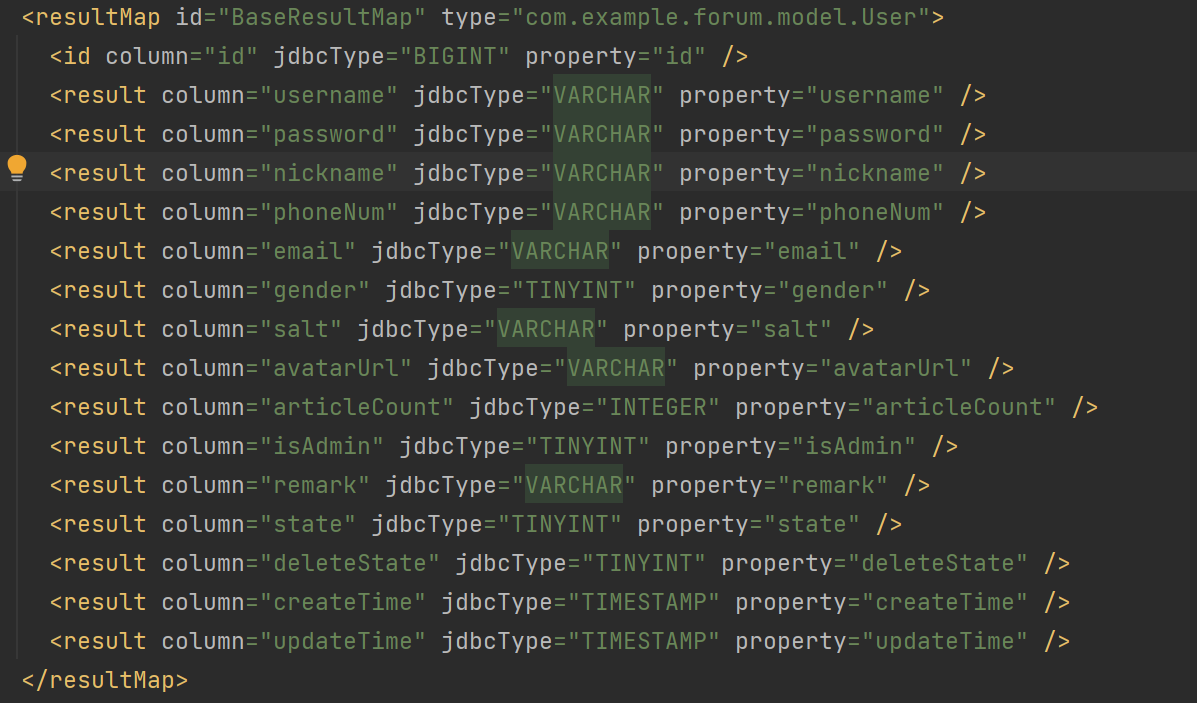
1.作用
1.1 字段映射:明确指定数据库表中的字段如何映射到实体类的属性上,尤其是当字段名和属性名不一致时。
1.2 复杂类型处理:支持嵌套结果映射,例如关联对象或集合的映射。
1.3 提高灵活性:允许更精细地控制数据的处理方式,比如处理数据库中的 null 值或默认值。
即使你不定义
<resultMap>,MyBatis 也可以通过简单的自动映射(autoMapping)来处理字段和属性的映射关系。但是,自动映射有一些限制:
它要求数据库字段名和实体类属性名完全一致。
对于复杂的数据结构(如关联对象或嵌套集合),自动映射可能无法正确处理。
因此,如果你的项目中字段名和属性名完全一致,并且没有复杂的关联关系,那么不定义
<resultMap>也可以正常使用。但如果存在字段名不一致或复杂的数据结构,定义
<resultMap>是更稳妥的选择。
2.复杂的数据结构处理
MyBatis中的复杂类型处理主要通过<resultMap>实现嵌套结果映射
1.1 关联对象(一对一)
示例场景:商品(Product)与商品详情(ProductDetail)的一对一关系
<resultMap id="productWithDetailMap" type="Product"><id property="id" column="product_id"/><result property="name" column="product_name"/><!-- 嵌套关联对象 --><association property="detail" javaType="ProductDetail" fetchType="eager"><id property="id" column="detail_id"/><result property="description" column="product_desc"/></association>
</resultMap>
通过<association>标签将查询结果中的detail_id等字段映射到Product对象的detail属性
1.2 集合映射(一对多)
示例场景:班级(Class)与学生(Student)的一对多关系
<resultMap id="classWithStudentsMap" type="Class"><id property="id" column="class_id"/><result property="className" column="class_name"/><!-- 嵌套集合映射 --><collection property="students" ofType="Student" fetchType="eager"><id property="id" column="student_id"/><result property="name" column="student_name"/></collection>
</resultMap>
通过<collection>标签将多个学生记录映射到Class对象的students集合属性
3. 实现方式对比
- 嵌套结果:单次SQL查询通过表连接获取所有数据,通过resultMap拆解映射
- 嵌套查询:分多次SQL查询,通过column属性传递参数
3.1 嵌套结果映射 的应用场景与组件
1.核心实现位置
- 在
<resultMap>中使用<association>(一对一)或<collection>(一对多)标签 - 通过单条SQL的
JOIN语句关联多表查询
<resultMap id="orderWithUserMap" type="Order"><id property="id" column="order_id"/><!-- 嵌套结果映射:通过JOIN查询直接映射关联对象 --><association property="user" javaType="User" fetchType="eager"><id property="id" column="user_id"/><result property="name" column="user_name"/></association>
</resultMap>
1.此配置通过
LEFT JOIN user ON order.user_id=user.id一次性获取订单及关联用户数据2. 加上
fetchType="eager":表示在加载主实体时,立即加载其关联的集合数据。
默认情况下,MyBatis 使用延迟加载(
fetchType="lazy"),即在访问关联数据时才加载。通过设置
fetchType="eager",可以一次性加载主实体及其关联的集合数据,避免“N+1 查询问题”。
3.2 嵌套查询 的应用场景与组件
1.核心实现位置
- 在
<resultMap>中使用<association>或<collection>的select属性指定子查询 - 通过
column属性传递主查询字段值给子查询
<resultMap id="orderWithUserQueryMap" type="Order"><id property="id" column="order_id"/><!-- 嵌套查询:通过column传递参数执行子查询 --><association property="user" column="user_id" select="com.example.mapper.UserMapper.selectById"/>
</resultMap>
此配置会先执行订单查询,再根据user_id逐个调用UserMapper.selectById加载用户数据。
3.3 关键差异对比
| 组件/行为 | 嵌套结果映射 | 嵌套查询 |
|---|---|---|
| SQL生成方式 | 单条含JOIN的复杂SQL | 主查询+多条子SQL |
| 参数传递机制 | 无(直接映射结果集) | 通过column传递参数 |
| 性能影响点 | 1.可能因多表连接导致结果集膨胀(笛卡尔积问题) | 1.多次简单查询,避免复杂连接,但可能因 N+1 问题拖慢性能(尤其数据量大时)2.多次查询可能导致弱一致性(高并发时) |
| 标签配置重点 | 联合查询结果拆解 | select+column联动 |
3.4 配置与灵活性对比
| 特性 | 嵌套结果映射 | 嵌套查询 |
|---|---|---|
| SQL 复杂度 | 需手动编写多表连接 SQL,可读性低 | 主查询和子查询分离,SQL 更简洁 |
| 复用性 | 结果映射可复用(通过 extends 继承) | 子查询语句可复用(如多个实体引用同一查询) |
| 参数传递灵活性 | 无参数传递机制 | 支持多参数传递(column="{prop1=col1, prop2=col2}") |
1.支持多参数传递(column="{prop1=col1, prop2=col2}")
<!-- 单参数传递示例 --> <resultMap id="deptSimpleMap" type="Dept"><id property="id" column="id"/><collection property="users" select="com.mapper.UserMapper.selectByDeptId" column="id" <!-- 只传递部门ID -->/> </resultMap><!-- 多参数传递示例 --> <resultMap id="deptComplexMap" type="Dept"><id property="id" column="id"/><result property="compId" column="comp_id"/><collection property="users" select="com.mapper.UserMapper.selectByDeptAndComp" column="{deptId=id, companyId=comp_id}" <!-- 传递部门ID和公司ID -->/> </resultMap>代码说明:单参数直接写列名,多参数需用{key1=col1,key2=col2}格式,嵌套查询方法需接收Map类型参数。注意列名需与主查询结果集字段对应<!-- 单参数接收查询 --> <select id="selectByDeptId" resultType="User">SELECT * FROM user WHERE dept_id = #{deptId} </select><!-- 多参数接收查询 --> <select id="selectByDeptAndComp" resultType="User">SELECT * FROM user WHERE dept_id = #{deptId} AND company_id = #{companyId} </select>
2.结果映射可复用(通过
extends继承)父类映射定义基础字段,子类映射仅需补充新增字段:
<resultMap id="BaseResultMap" type="User"><id column="id" property="id"/><result column="name" property="name"/> </resultMap><resultMap id="UserViewMap" type="UserView" extends="BaseResultMap"><result column="role_name" property="roleName"/> </resultMap>子类
UserView继承父类User的所有映射配置
3.子查询语句可复用(如多个实体引用同一查询)
1.<sql>片段复用 定义可重用的SQL片段,通过<include>引用12:<sql id="baseColumns">id, name, create_time</sql><select id="selectUser" resultType="User">SELECT <include refid="baseColumns"/> FROM user </select>2.嵌套查询复用 通过<association>/<collection>的select属性引用已定义的查询: <resultMap id="deptMap" type="Dept"><collection property="users" select="selectUserByDept" column="id"/> </resultMap>
3.5 优化建议
- 嵌套结果映射:通过
JOIN优化 SQL,减少返回字段。 - 嵌套查询:启用懒加载(
lazyLoadingEnabled=true)
(关联数据延迟加载) ,避免 N+1 问题
1.通过
JOIN优化 SQL,减少返回字段
-- 完整优化版本(含索引建议)
CREATE INDEX idx_cover ON users(id, name, status);
CREATE INDEX idx_cover_orders ON orders(user_id, id, order_no);EXPLAIN
SELECT o.id, o.order_no, u.name
FROM orders o FORCE INDEX(idx_cover)
JOIN users u FORCE INDEX(idx_cover_orders) ON o.user_id=u.id
WHERE u.status=1
LIMIT 100;
1.优化前使用SELECT *会返回orders表所有字段
优化后明确指定o.id, o.order_no, u.name三个业务字段2.如果这些字段都在索引中,可以利用覆盖索引避免回表2.1 假设我们有以下索引结构:users表有主键索引(id)和复合索引(id, name, status)
orders表有主键索引(id)和索引(user_id)2.2 当执行优化后的查询时:SELECT o.id, o.order_no, u.name
FROM orders o JOIN users u ON o.user_id=u.id
WHERE u.status=12.3覆盖索引生效的两种情况:
覆盖索引是指查询所需的所有列都包含在索引中,无需回表查询原始数据表,从而提高查询效率对users表的覆盖:
如果存在复合索引(id, name, status)
查询只需访问索引就能获取id、name、status字段
EXPLAIN会显示"Using index"对orders表的覆盖:
如果存在复合索引(user_id, id, order_no)
查询只需访问索引就能获取所需字段
不需要回表查数据页2.4 验证方法:
EXPLAIN
SELECT o.id, o.order_no, u.name
FROM orders o JOIN users u ON o.user_id=u.id
WHERE u.status=1;
在Extra列看到"Using index"就表示使用了覆盖索引。如果没有,则需要创建包含查询字段的复合索引:CREATE INDEX idx_cover ON users(id, name, status);
CREATE INDEX idx_cover_orders ON orders(user_id, id, order_no);2.5 FORCE INDEX:强制使用指定的索引,确保查询优化器按照指定的索引进行查询。JOIN策略优化的实践:
3.用INNER JOIN替代了WHERE IN子查询(嵌套查询)4.users表作为被驱动表,其id字段应该建立索引SELECT a.col1, b.col2
FROM tableA a
JOIN tableB b ON a.id = b.id;
tableA 是驱动表。
tableB 是被驱动表。如果驱动表较小,查询可能更快,因为只需要扫描较少的行。
如果驱动表的连接条件过滤性很好(即能快速缩小匹配范围),查询效率也会更高。假设users表过滤后结果集较小,符合"小表驱动大表"原则
“小表驱动大表” 的核心在于减少驱动表的行数,从而降低查询的总体开销,包括减少扫描行数、减少内存和缓存的使用、减少 I/O 操作等。这种优化策略特别适用于 JOIN 查询,尤其是当其中一个表经过过滤后结果集显著减少时。执行计划优化要点:
5.优化后查询应显示"Using index"(如果name在索引中)
EXPLAIN会显示使用索引连接而非全表扫描WHERE u.status=1:在连接之前,先过滤出 status=1 的用户记录。
6.确保连接算法是BNLJ而非性能更差的Simple Nested Loop JoinBlock Nested Loop Join(块嵌套循环连接)是一种在数据库系统中实现表连接操作的算法。它属于嵌套循环连接的一种优化版本,通过一次性处理多个元组(形成一个 "块")来减少 I/O 次数和提高缓存利用率。块嵌套循环连接算法将外部表(通常是较小的表)分成多个块,每次将一个块加载到内存中。然后,它逐行扫描内部表,并将每一行与内存中的所有元组进行比较,以找出匹配的记录。与简单的嵌套循环连接相比,块嵌套循环连接的主要改进在于:减少 I/O 次数:通过批量处理元组,减少了对外部表的读取次数。提高缓存利用率:利用内存块的局部性原理,减少了缓存失效假设我们有两个表:Employees(员工)和Departments(部门),需要通过department_id字段进行连接。分块:将Employees表(外部表)分成多个块,每个块包含 1000 行。加载:每次加载一个块到内存中。扫描:逐行扫描Departments表(内部表),并与内存中的每个员工记录进行比较。匹配输出:如果某个员工的department_id与当前部门记录的id匹配,则输出连接结果。优化建议选择合适的块大小:块大小应根据可用内存和缓存特性进行调整。将较小的表作为外部表:减少需要加载的块数。结合索引:如果内部表在连接键上有索引,可以加速匹配过程。块嵌套循环连接是数据库查询执行中的一种基础算法,理解它有助于深入掌握数据库系统的查询优化原理7.结果集处理改进:
虽然示例没展示LIMIT,但实际可添加LIMIT 100限制行数
这种简单JOIN比嵌套子查询更易维护和优化
2.N+1问题
1.1 典型案例
以“博客系统”为例
第 1 次查询:获取所有博客帖子(主对象)
SELECT * FROM posts; -- 返回 N 条记录(例如 100 条)
第 2 到 N+1 次查询:遍历每条帖子,查询其关联的作者信息(关联对象)
SELECT * FROM authors WHERE id = 1; -- 帖子 1 的作者
SELECT * FROM authors WHERE id = 2; -- 帖子 2 的作者
...
SELECT * FROM authors WHERE id = 100; -- 帖子 100 的作者
总查询次数 = 1(主查询) + N(关联查询) = 101 次
1.2 性能危害
| 问题类型 | 具体影响 |
|---|---|
| 数据库压力 | 大量小查询消耗连接池资源,导致数据库 CPU/IO 飙升,尤其在并发场景下可能引发雪崩 |
| 网络延迟累积 | 每次查询需经历网络传输,N 较大时总延迟显著增加(例如 100 次 10ms 查询 = 1秒延迟) |
| 应用响应变慢 | 前端页面等待时间延长,用户体验下降(如商品列表加载卡顿) |
本质矛盾:ORM 的“对象思维”(逐对象加载关联数据)与数据库“批量查询”的高效性冲突
1.3 解决方案
1.3.1 预加载(Eager Loading)—— 嵌套结果映射
一次性通过 JOIN 或子查询获取主对象及关联对象,仅需 1 次查询:
SELECT posts.*, authors.name
FROM posts
LEFT JOIN authors ON posts.author_id = authors.id; -- 1 次查询解决
1.
SELECT posts.*, authors.name
posts.*:表示选择posts表中的所有列。
authors.name:表示选择authors表中的name列。这部分定义了查询结果中要返回的字段。
2.
FROM posts
指定主表为
posts,即查询的起点是posts表。3.
LEFT JOIN authors
LEFT JOIN是一种连接操作,用于将posts表与authors表进行连接。
LEFT JOIN的特点是:即使右边的表(authors)中没有匹配的行,左边的表(posts)中的行仍然会出现在结果中,未匹配的列会显示为NULL。4.
ON posts.author_id = authors.id
ON子句定义了连接条件,即如何将posts表和authors表的行关联起来。这里的条件是:
posts.author_id(文章的作者 ID)等于authors.id(作者的 ID)
ORM 支持:
- JPA:
@EntityGraph(attributePaths = "authors") - Hibernate:
FetchType.EAGER或@Fetch(FetchMode.JOIN) - MyBatis:
<collection>嵌套查询优化(需配置fetchType="eager")
1.3.2 批量延迟加载(Batch Lazy Loading)
同时加上禁用激进懒加载效果更好(aggressiveLazyLoading=false):
- 激进懒加载可能会自动加载所有相关联的数据,即使这些数据在当前查询中并不需要。禁用它意味着更精确地控制加载的数据量,避免不必要的加载,进一步优化性能。
当访问关联对象时,按批次加载(非逐条加载):
-- 首次访问作者时,批量加载所有关联作者(例如 10 条/批)
SELECT * FROM authors WHERE id IN (1, 2, 3, ..., 10);
1. 配置延迟加载(XML映射文件)<resultMap id="PostResultMap" type="Post"><association property="author" column="author_id" select="com.example.mapper.AuthorMapper.selectById"fetchType="lazy"/> </resultMap> 注:selectById 是单条查询方法,用于兼容默认延迟加载机制36。2. 实现批量加载(Java层)// 批量查询接口方法 List<Author> selectAuthorsByIds(@Param("ids") List<Long> ids);// 实现类 public class PostService {@Autowiredprivate AuthorMapper authorMapper;public void loadAuthorsForPosts(List<Post> posts) {Set<Long> authorIds = posts.stream().map(Post::getAuthorId).collect(Collectors.toSet());Map<Long, Author> authorMap = authorMapper.selectAuthorsByIds(new ArrayList<>(authorIds)).stream().collect(Collectors.toMap(Author::getId, a -> a));posts.forEach(post -> post.setAuthor(authorMap.get(post.getAuthorId())));} }3. 批量查询SQL(Mapper XML)<select id="selectAuthorsByIds" resultType="Author">SELECT * FROM authors WHERE id IN<foreach item="id" collection="ids" open="(" separator="," close=")">#{id}</foreach> </select>初始查询 仅获取主表数据(如 SELECT * FROM posts)。批量预加载 主动调用 loadAuthorsForPosts 方法,通过 IN 语句批量查询关联数据。属性注入 将查询结果手动注入到主对象中,后续访问 post.getAuthor() 直接返回缓存对象方案对比
方式 查询次数 适用场景 缺点 原生延迟加载 N+1 关联数据访问分散 性能差 手动批量加载 2 需集中处理关联数据 需额外编码 JOIN查询 1 简单关联且数据量小 可能返回冗余数据4 关键点:通过业务层主动触发批量查询,绕过 MyBatis 延迟加载的单条查询限制
总结
通过这种方式,MyBatis 实现了批量延迟加载:
延迟加载:在首次访问关联对象时才加载数据,避免不必要的查询。
批量加载:通过一次性查询多个关联对象,减少了数据库查询次数,避免了“N+1 查询问题”。
这种策略在处理大量关联数据时非常高效,尤其是在分页查询或批量处理场景中
1.3.3 DTO 投影(Data Transfer Object)
仅查询所需字段,避免加载全量关联对象:
SELECT p.title, a.name AS author_name FROM posts p JOIN authors a ON p.author_id = a.id;减少数据传输量,提升响应速度
典型应用场景
- 移动端列表页:仅返回ID、名称、缩略图等核心字段68
- 微服务API:跨服务调用时过滤敏感字段(如密码哈希)16
- 大数据导出:选择列减少文件体积和传输时间
N+1 问题的本质是多次小查询代替单次批量查询导致的性能劣化,通过预加载、批量加载或 DTO 投影可有效规避。关键在于理解 ORM 机制,根据数据量和访问模式选择最优策略。
3.6 选择建议
1.优先嵌套结果(空间换时间)
适用:当关联数据量小、需要强一致性时(如订单详情页)
不适用:多层级嵌套或关联表过多导致结果集膨胀时
2.选择嵌套查询(时间换灵活性)
适用:需懒加载或主查询结果集小时(如用户中心页的订单列表)
不适用:对延迟敏感或N值过大(>1000)时
简单关联(如一对一)优先用嵌套结果映射;
复杂嵌套(如一对多+多对一)或大数据量场景用嵌套查询+懒加载
4.注意事项:
- 关联对象使用
javaType指定类型 - 集合映射使用
ofType指定元素类型 - 建议对关联字段使用别名避免列名冲突
5.理解 ORM(Object-Relational Mapping,对象关系映射)机制
是使用 MyBatis 或其他 ORM 框架的基础。ORM 机制的核心是将关系型数据库中的表结构映射到面向对象编程语言中的类和对象,从而简化数据库操作,提高开发效率
2.DAO添加接口

// 1.@Param("username") 为SQL 传入的参数名User selectByUserName(@Param("username") String username);
3.进行Service中业务方法的编写
3.1 创建Service接口
com.example.forum.services包下创建IUserService接口
3.2 实现Service接口
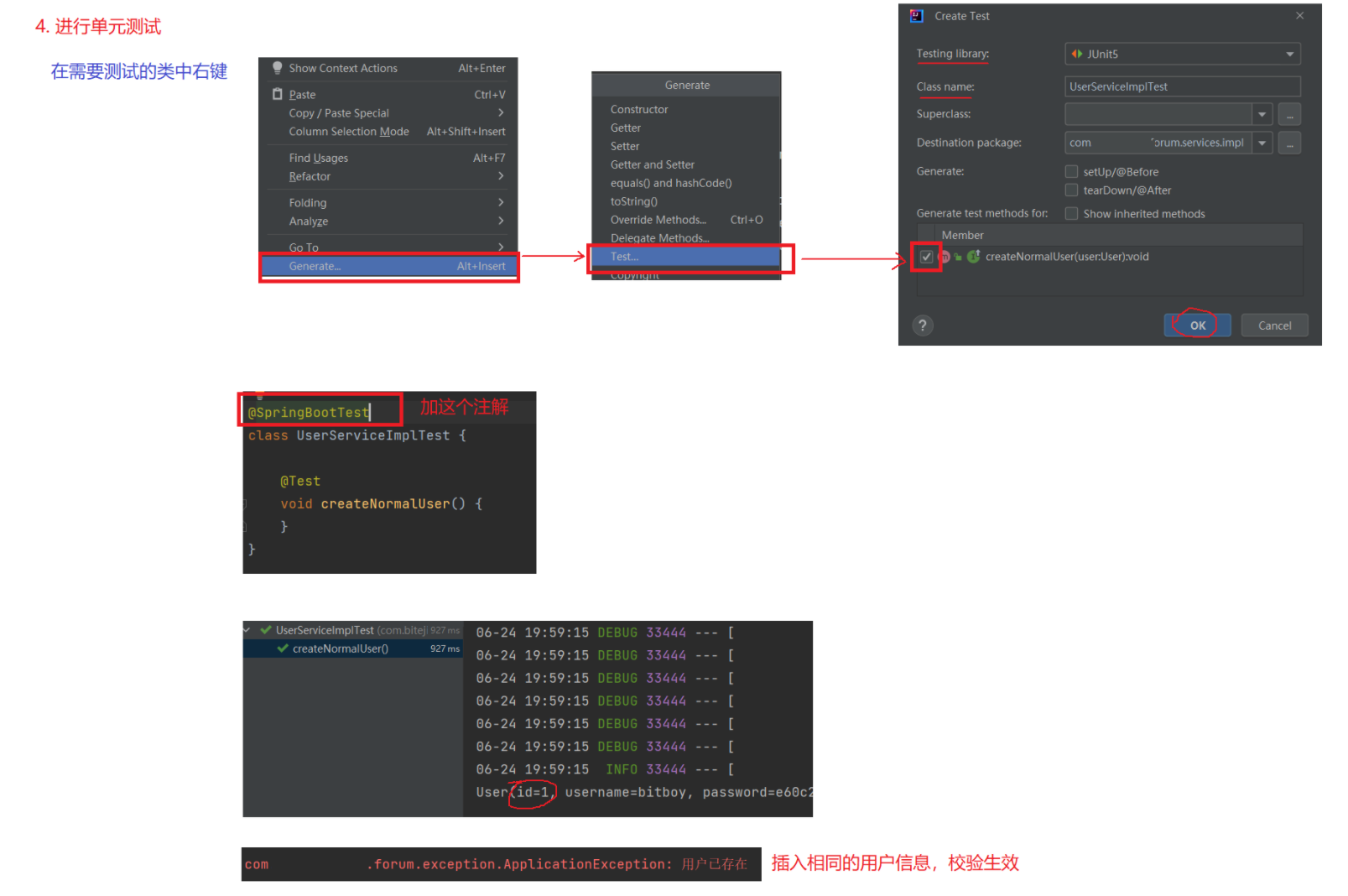
@Resourceprivate UserMapper userMapper;/*** 创建一个普通用户** @param user 用户信息*/@Overridepublic void createNormalUser(User user) {// 1.非空校验if(user == null || StringUtils.isEmpty(user.getUsername())|| StringUtils.isEmpty(user.getPassword()) || StringUtils.isEmpty(user.getNickname())|| StringUtils.isEmpty(user.getSalt()) ) {// 打印日志log.warn(ResultCode.FAILED_PARAMS_VALIDATE.toString());// 抛出异常, 统一抛出 ApplicationExceptionthrow new ApplicationException(AppResult.failed(ResultCode.FAILED_PARAMS_VALIDATE));}// 2.按用户名查询用户信息User existUser = userMapper.selectByUserName(user.getUsername());// 2.1 判断用户是否存在if (existUser != null) {log.info(ResultCode.FAILED_USER_EXISTS.toString());throw new ApplicationException(AppResult.failed(ResultCode.FAILED_USER_EXISTS));}// 3.新增用户流程, 设置默认值user.setGender((byte) 2);user.setArticleCount(0);user.setIsAdmin((byte) 0);user.setState((byte) 0);user.setDeleteState((byte) 0);// 当前日期Date date = new Date();user.setCreateTime(date);user.setUpdateTime(date);// 写入数据库int row = userMapper.insertSelective(user);if(row != 1) {// 打印日志log.warn(ResultCode.FAILED_CREATE.toString());// 抛出异常, 统一抛出 ApplicationExceptionthrow new ApplicationException(AppResult.failed(ResultCode.FAILED_CREATE));}log.info("[UserServiceImpl]:新增用户成功 username = " + user.getUsername() + ". ");}3.3 进行单元测试
package com.example.forum.services.impl;import com.example.forum.model.User;
import com.example.forum.services.IUserService;
import com.example.forum.utils.MD5Util;
import com.example.forum.utils.UUIDUtil;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;import javax.annotation.Resource;/*** Created with IntelliJ IDEA* Description* User: 王杰* Date: 2025-06-14* Time: 13:06*/
@SpringBootTest
class UserServiceImplTest {@Resourceprivate IUserService userService;@Testvoid createNormalUser() {// 构造User对象User user = new User();user.setUsername("girl");user.setNickname("girl");// 定义一个原始的密码String password = "123456";// 生成盐String salt = UUIDUtil.UUID_32();// 生成密码的密文String ciphertext = MD5Util.md5Salt(password, salt);user.setPassword(ciphertext);// 设置盐user.setSalt(salt);// 调用Service 层的方法userService.createNormalUser(user);// 打印结果System.out.println(user);}
}3.4 编写Controller中的代码
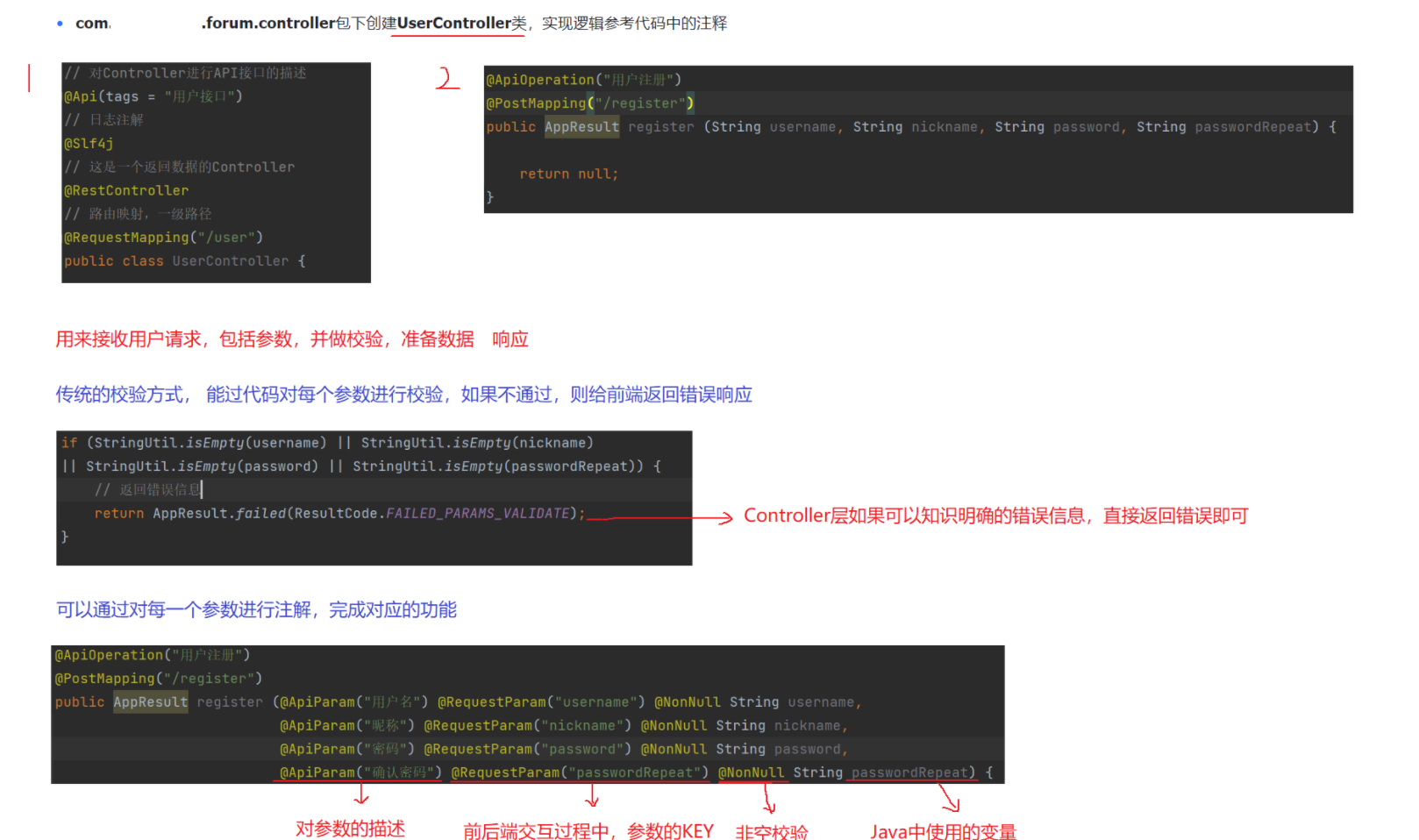
package com.example.forum.controller;import com.example.forum.common.AppResult;
import com.example.forum.common.ResultCode;
import com.example.forum.model.User;
import com.example.forum.services.IUserService;
import com.example.forum.utils.MD5Util;
import com.example.forum.utils.UUIDUtil;
import com.sun.istack.internal.NotNull;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;/*** Created with IntelliJ IDEA* Description* User: 王杰* Date: 2025-06-14* Time: 18:52*/
// 对Controller进行API接口的描述
@Api(tags="用户接口")
// 日志注解
@Slf4j
// 这是一个返回数据的Controller
@RestController
// 路由映射 一级路径
@RequestMapping("/user")
public class UserController {@Resourceprivate IUserService userService;/*** 用户注册* @param username 用户名* @param nickname 用户昵称* @param password 密码* @param passwordRepeat 确认密码* @return*/@ApiOperation("用户注册")@PostMapping("/register")public AppResult register(@ApiParam("用户名") @RequestParam("username") @NotNull String username,@ApiParam("昵称") @RequestParam("nickname") @NotNull String nickname,@ApiParam("密码") @RequestParam("password") @NotNull String password,@ApiParam("确认密码") @RequestParam("passwordRepeat") @NotNull String passwordRepeat) {// 1.校验密码与确认密码是否相同if (!password.equals(passwordRepeat)) {log.warn(ResultCode.FAILED_TWO_PWD_NOT_SAME.toString());// 返回错误信息return AppResult.failed(ResultCode.FAILED_TWO_PWD_NOT_SAME);}// 2.准备数据// 构造User对象User user = new User();user.setUsername(username);user.setNickname(nickname);// 生成盐String salt = UUIDUtil.UUID_32();// 生成密码的密文String encryptPassword = MD5Util.md5Salt(password, salt);user.setPassword(encryptPassword);// 设置盐user.setSalt(salt);// 3.调用Service 层的方法userService.createNormalUser(user);// 4.返回成功return AppResult.success();}
}
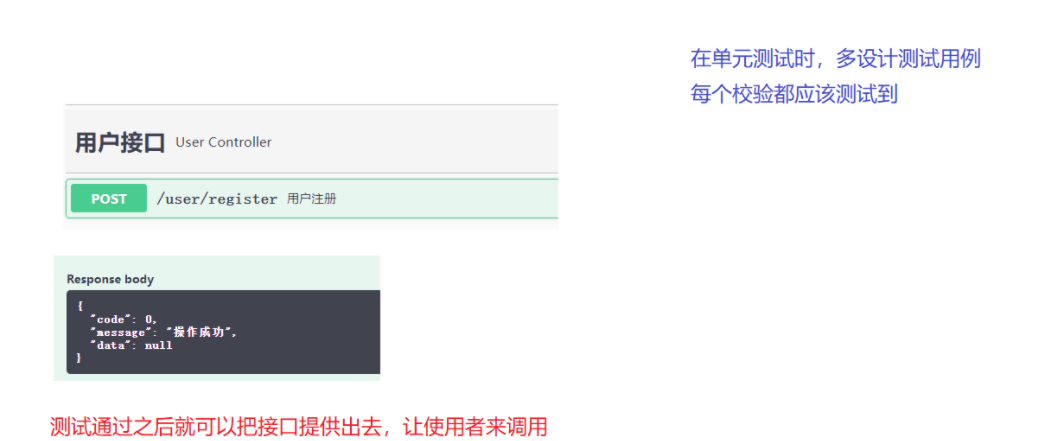
3.5 测试Controller中对外提供的API