Pytorch 卷积神经网络参数说明一
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、卷积层的定义
- 1.常见的卷积操作
- 2. 感受野
- 3. 如何理解参数量和计算量
- 4.如何减少计算量和参数量
- 二、神经网络结构:有些层前面文章说过,不全讲
- 1. 池化层(下采样)
- 2. 上采样
- 3. 激活层、BN层、FC层
- 1).BatchNorm 层
- 2).FC 全连接层
- 3). dropout 层
- 4). 损失层
- 鸣谢
前言
在前两个实战中,我们只学会了如何搭建神经网络,但是里面有些函数接口不明白怎么回事,在这篇文章中,我们会逐一解答。
一、卷积层的定义
nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding = 0,dilation = 1,groups = 1,bias = True)
- 输入通道
- 输出通道
- 卷积核大小
- 移动步长
- 卷积核膨胀
卷积核的大小一般是 3 x 3,卷积的时候,以该元素为中心形成一个 3 x 3的格子,然后与卷积核做内积。不懂的话去小破站学学,很简单,这里不是重点。输入通道和输出通道不用过多解释,卷积核的数量。padding = 1 我们有时候发现靠边的元素卷积不够,需要进行拓展,这句话就是添加一行和一列,完成边缘元素的卷积。dilation = 1,这个是为了增加卷积核的视野感受范围,3 x 3 的卷积核变成 7 x 7 的卷积核,在分割网络中常用。卷积一个元素之后,stride = 1 移动的步长,如果等于 2 就有些元素没有中心卷积。groups = 1 分组卷积,一个卷积核为一组,可以降低计算量,主要在深度可分离卷积中。bias=True 偏执量,输出的结果经过 y = wx+b wx 可以理解卷积,b就是我们家的偏置量。
1.常见的卷积操作
- 分组卷积
- 空洞卷积
- 深度可分离卷积( 分组卷积 + 1 x 1 卷积)
- 反卷积
- 可变型卷积,卷积核不是固定的。
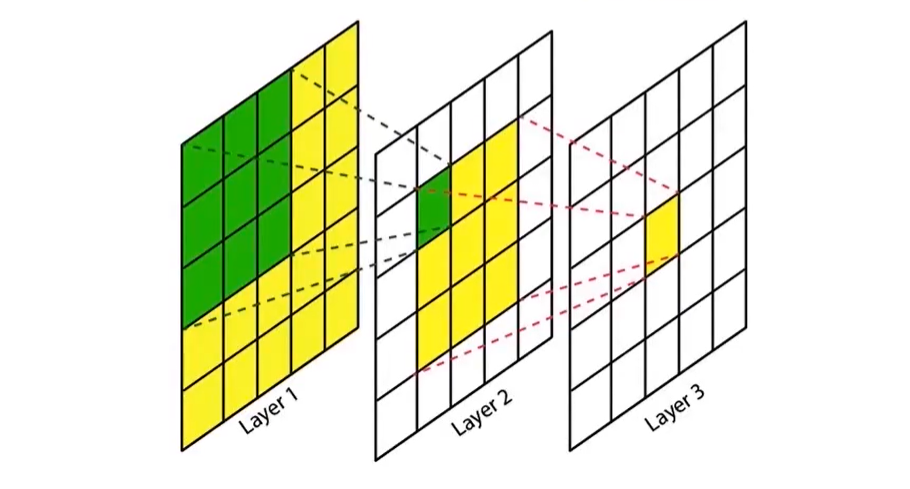
2. 感受野
指的是神经网络中卷积核看到的区域,在神经网络中,feature_map 某个元素的计算受到输入图像上某个区域的影响,这个区域就是该元素的感受野。
3. 如何理解参数量和计算量
- 参数量:参与计算参数的个数,占用内存空间:对于一个卷积核而言参数量: ( C i n ∗ ( K ∗ K ) + 1 ) ∗ C o u t (Cin*(K*K)+1)*Cout (Cin∗(K∗K)+1)∗Cout
- FLOPS:每秒浮点运算次数,可以理解是速度,用来衡量硬件的性能。
- FLOPs:s小写,这个就是计算量,衡量算法模型的复杂度:
( C i n ∗ 2 ∗ K ∗ K ) ∗ H o u t ∗ W o u t ∗ C o u t (Cin * 2 * K* K ) * Hout * Wout * Cout (Cin∗2∗K∗K)∗Hout∗Wout∗Cout- MAC:乘加的次数
C i n ∗ K ∗ K ∗ H o u t ∗ W o u t ∗ C o u t Cin * K* K * Hout * Wout * Cout Cin∗K∗K∗Hout∗Wout∗Cout
FLOPs 把乘加分开算,所以乘以2,MAC 算一次,所以是 1。
4.如何减少计算量和参数量
减少计算量很参数量还是要在卷积层动脑子,在不改变感受野和减少参数量的角度压缩矩阵:
- 采用多个 3 x 3 的卷积核代替大的卷积核。
- 采用深度可分离卷积核,即分组卷积
- 通道 Shuffle
- Pooling 层:快速下采样,可能有信息的损失。一般在前两个卷积核使用。
- Stride = 2:卷积的步长加大
等等
二、神经网络结构:有些层前面文章说过,不全讲
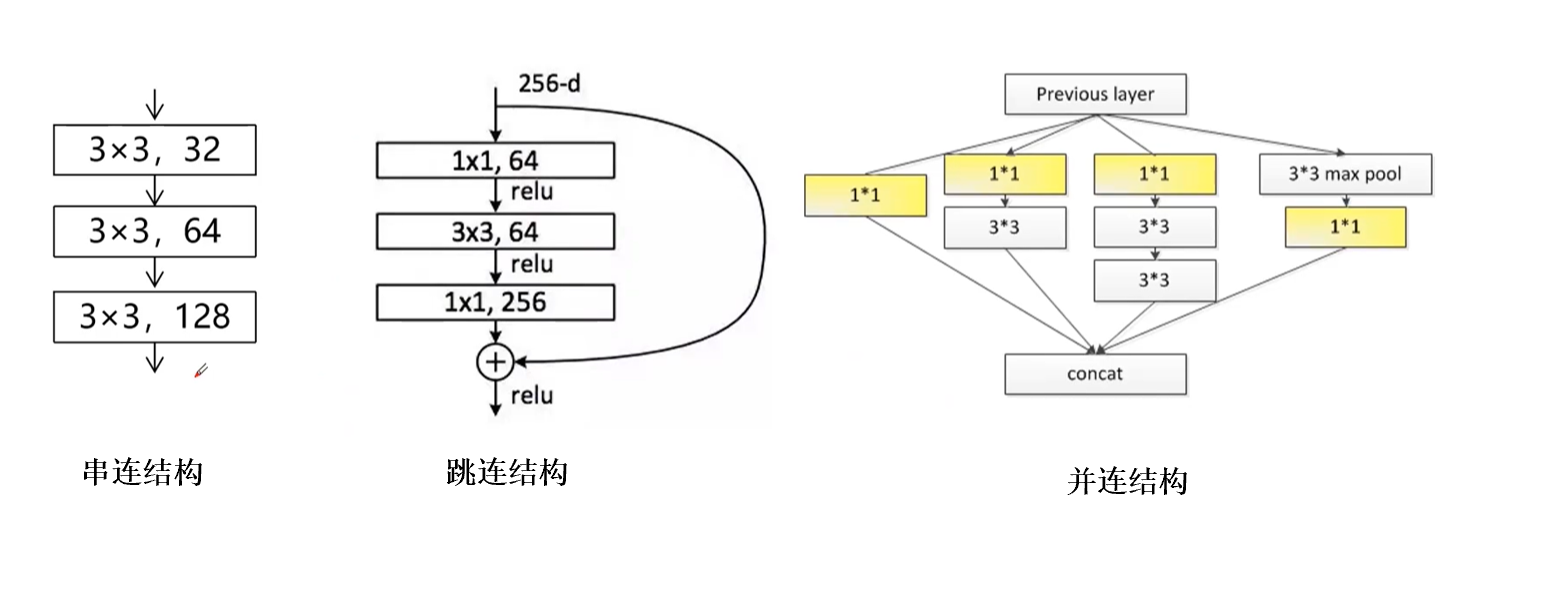
神经网络基本可以分成这三种金典的结构,如图 2 所示。串联结构、跳连结构、并连结构。跳连结构是把部分输出直接作为输出,这样可以大幅度减少计算量。
1. 池化层(下采样)
池化层对输入特征的压缩:
- 一方面使特征图变小,简化网络计算复杂度。
- 一方面进行特征压缩,提取主要特征。
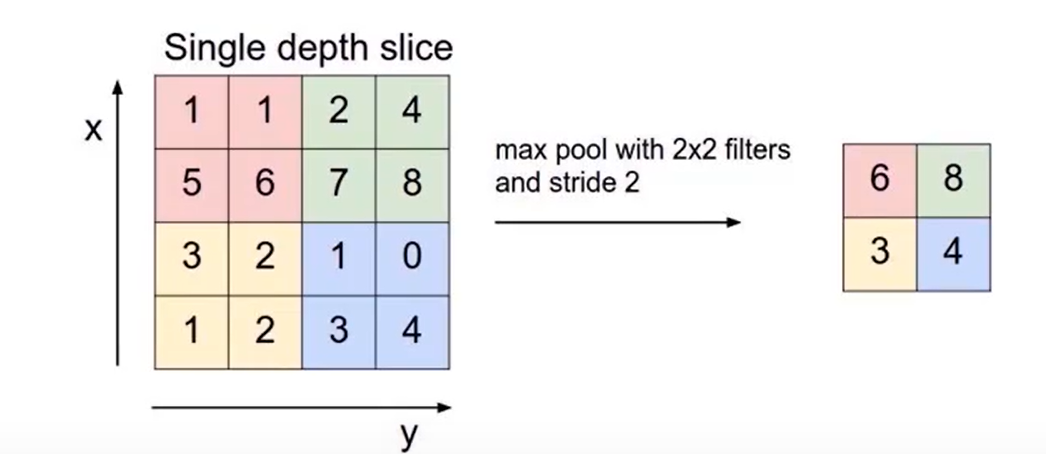
池化层常用两种方法:最大池化(Max Pooling)和平均池化(Average Poling),
nn.MaxPool2d(kernel_size = ,Stride = ,pading =0 ,dilation = 1,return_indeces = False,ceil_mode = False)
前四个参数就不说了,上面有。这个 return_indeces,返回的是最大值的索引,这样当我们恢复原图的时候有很大作用,相似度更近。下面是一张最大池化的图:
2. 上采样
上采样有两种方式:
- Resize,如双线性插值直接放缩,类似于图像放缩。
- 反卷积:Deconvolution,即 Transposed Convolution
代码摘要:
nn.functional.interpolate(input,size = None,scalar_factor = None,model = 'nearest',align_corners = None)nn.ConvTranspose2d(in_channels,out_channels,kernel_size, stride = 1,padding = 0,bias = True)
通常我们采用Resize进行重构,计算量小,反卷积的计算量很大。
3. 激活层、BN层、FC层
在卷积层,其实就是一个线性操作y = wx +b w 和 b 就是卷积核的参数,线性函数并不能很好去拟合数据样本,所以我们提出激活函数来解决这一问题,旨在提高网络的非线性表达。
- 激活函数:为了增加网络的非线性,进而增加网络的表达能力。
- 常用函数:ReLU函数、Leakly ReLU函数、ELU 函数等
- 语句:
torch.nn.ReLU(inplace = True)
1).BatchNorm 层
- 通过一定的规范化手段,把每层神经网络任意神经元的输入值分布强行拉倒j标准正态分布上面,均值 0 ,方差 1.
- BatchNorm 是一种归一化的手段,他会减少图像之间的绝对差异,突出相对差异,加快模型的训练速度。
- 不适合 image to image 和对噪声敏感的任务中
- 语句:
nn.BatchNorm2d(num_features,eps = 1e-05,momentum =0.1,affine = True,track_runing_stats = True )
BatchNorm 层可以理解为工具层,我们在卷积层也可以加入,后面在更一个ReLU层,往往就是这么干的。
2).FC 全连接层
连接所有的特征,把输出值送给分类器(softmax层)。
- 对前层的特征进行一个加权和,(卷积层是将输入数据映射到隐层特征空间) ,将特征空间通过线性变化映射到样本标记空间。
- 也可以通过 1 x 1 卷积 + gloable average pooling 代替。
- 全连接层的参数冗余,一般情况需要 Dropout 限制参数。
- FC 层对图片的大小尺寸非常敏感。
- 语句:
nn.Linear(in_features,out_features,bias)
3). dropout 层
- 在不同的训练中随机扔掉一些神经元。
- 在测试中不实用随机失活,那么所有的神经元都激活。
- 作用:为了防止和减轻过拟合才使用的函数,一般用在全链接层。
- 语句:
nn.dropout
4). 损失层
在网络优化,反向传播时非常重要的一个层,损失函数选择取决于我们要训练的任务。
- 损失层:设置一个损失函数用来比较输出值和目标值,通过最小损失来驱动网络的训练。
- 网络的损失通过前向操作计算,网络的参数相较于损失函数,通过后向操作计算。
- 分类问题损失:
- nn.BCELoss
- nn.CrossEntrophyLoss 等等
- 回归问题损失:
- nn.L1Loss
- nn.MSELoss
- nn.SmoothL1Loss 等等
鸣谢
年龄越大,越不想欠谁。一生活得洒脱,一个人,几个人也快乐。如果本文对大家有帮助,还请大家浏览一下我弟新开的小店,要黄了,哈哈哈。点击这里。