2022年SCI1区TOP:K-means聚类算法KO,深度解析+性能实测
目录
- 1.摘要
- 2.k -means聚类算法
- 3.算法原理
- 4.结果展示
- 5.参考文献
- 6.代码获取

1.摘要
本文提出了一种K-means聚类算法KO,用于解决从数值函数到实际设计挑战的广泛优化问题。KO算法在每次迭代中使用K-means算法建立聚类区域的质心向量,随后KO提出了两种移动策略,以在开发和探索之间实现平衡。每次迭代中选择探索或开发的移动策略取决于一个参数,该参数用于判断每个搜索个体是否在已访问区域停留过久且未实现自我改进。
PS:有点套娃,KO并非K-means(无监督学习)而是用K-means(无监督学习)机制构建的K-means算法(元启发式算法)🤣🤣🤣
2.k -means聚类算法
K-means算法将一组数据划分为
K
K
K个簇,这些簇是离散的、不重叠的子组,每个数据点都被分配到一个独立的簇。K-means通过最小化数据点与簇的质心(即簇内所有数据点的算术平均值)之间的平方距离和,来为每个数据点分配簇。为了找到K个质心,K-means的核心问题是最小化一个目标函数,该目标函数基于数据点集
X
=
{
x
1
,
x
2
,
…
,
x
n
}
X=\{x_{1},x_{2},\ldots,x_{n}\}
X={x1,x2,…,xn}以及质心集
C
=
{
c
1
,
c
2
,
…
,
c
K
}
C=\{c_1,c_2,\ldots,c_K\}
C={c1,c2,…,cK}:
f
o
b
j
(
X
,
C
)
=
∑
n
min
{
∥
x
i
−
c
l
∥
2
,
l
=
(
1
,
2
,
…
,
K
)
}
f_{obj}\left(X,C\right)=\sum^n\min\left\{\left\|x_i-c_l\right\|^2,l=(1,2,\ldots,K)\right\}
fobj(X,C)=∑nmin{∥xi−cl∥2,l=(1,2,…,K)}
3.算法原理
初始化构建潜力矩阵
P
‾
\overline{P}
P:
P
‾
=
[
p
1
,
1
‾
p
1
,
2
‾
⋯
⋯
p
1
,
D
‾
F
i
t
n
e
s
s
1
‾
p
2
,
1
‾
p
2
,
1
‾
⋯
⋯
p
2
,
D
‾
F
i
t
n
e
s
s
2
‾
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
p
N
,
1
‾
p
N
,
2
‾
⋯
⋯
p
N
,
D
‾
F
i
t
n
e
s
s
N
‾
]
N
×
D
\overline{P}= \begin{bmatrix} \overline{p_{1,1}} & \overline{p_{1,2}} & \cdots & \cdots & \overline{p_{1,D}} & \overline{Fitness_{1}} \\ \overline{p_{2,1}} & \overline{p_{2,1}} & \cdots & \cdots & \overline{p_{2,D}} & \overline{Fitness_{2}} \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ \overline{p_{N,1}} & \overline{p_{N,2}} & \cdots & \cdots & \overline{p_{N,D}} & \overline{Fitness_{N}} \end{bmatrix}^{N\times D}
P=
p1,1p2,1⋮⋮pN,1p1,2p2,1⋮⋮pN,2⋯⋯⋮⋮⋯⋯⋯⋮⋮⋯p1,Dp2,D⋮⋮pN,DFitness1Fitness2⋮⋮FitnessN
N×D
其中,
F
i
t
n
e
s
s
1
‾
≤
F
i
t
n
e
s
s
2
‾
≤
F
i
t
n
e
s
s
3
‾
≤
⋯
≤
F
i
t
n
e
s
s
N
‾
\overline{Fitness_{1}}\leq\overline{Fitness_{2}}\leq\overline{Fitness_{3}}\leq\cdots\leq\overline{Fitness_{N}}
Fitness1≤Fitness2≤Fitness3≤⋯≤FitnessN
说明按照适应度排序后重构了种群矩阵,在找到潜力矩阵P之后,为了提高搜索空间的质量并考虑高质量的位置,KO算法使用了线性种群规模缩减(LPSR)方法。KO中的种群规模将随着迭代次数的增加,按照线性函数逐渐减少:
f
(
t
)
=
(
N
−
4
)
t
1
−
T
max
+
N
−
(
N
−
4
)
1
−
T
max
f(t)=\frac{(N-4)t}{1-T_{\max}}+N-\frac{(N-4)}{1-T_{\max}}
f(t)=1−Tmax(N−4)t+N−1−Tmax(N−4)
因此,潜力矩阵P变成:
P
(
t
)
‾
=
[
p
1
,
1
(
t
)
‾
p
1
,
2
(
t
)
‾
⋯
⋯
p
1
,
D
(
t
)
‾
F
i
t
n
e
s
s
1
(
t
)
‾
p
2
,
1
(
t
)
‾
p
2
,
1
(
t
)
‾
⋯
⋯
p
2
,
D
(
t
)
‾
F
i
t
n
e
s
s
2
(
t
)
‾
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
⋮
p
f
(
t
)
,
1
(
t
)
‾
p
f
(
t
)
,
2
(
t
)
‾
⋯
⋯
p
f
(
t
)
,
D
(
t
)
‾
F
i
t
n
e
s
s
f
(
t
)
(
t
)
‾
]
f
(
t
)
×
D
\overline{P(t)}= \begin{bmatrix} \overline{p_{1,1}^{(t)}} & \overline{p_{1,2}^{(t)}} & \cdots & \cdots & \overline{p_{1,D}^{(t)}} & \overline{Fitness_{1}^{(t)}} \\ \overline{p_{2,1}^{(t)}} & \overline{p_{2,1}^{(t)}} & \cdots & \cdots & \overline{p_{2,D}^{(t)}} & \overline{Fitness_{2}^{(t)}} \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ \vdots & \vdots & \vdots & \vdots & \vdots & \vdots \\ \overline{p_{f(t),1}^{(t)}} & \overline{p_{f(t),2}^{(t)}} & \cdots & \cdots & \overline{p_{f(t),D}^{(t)}} & \overline{Fitness_{f(t)}^{(t)}} \end{bmatrix}^{f(t)\times D}
P(t)=
p1,1(t)p2,1(t)⋮⋮pf(t),1(t)p1,2(t)p2,1(t)⋮⋮pf(t),2(t)⋯⋯⋮⋮⋯⋯⋯⋮⋮⋯p1,D(t)p2,D(t)⋮⋮pf(t),D(t)Fitness1(t)Fitness2(t)⋮⋮Fitnessf(t)(t)
f(t)×D
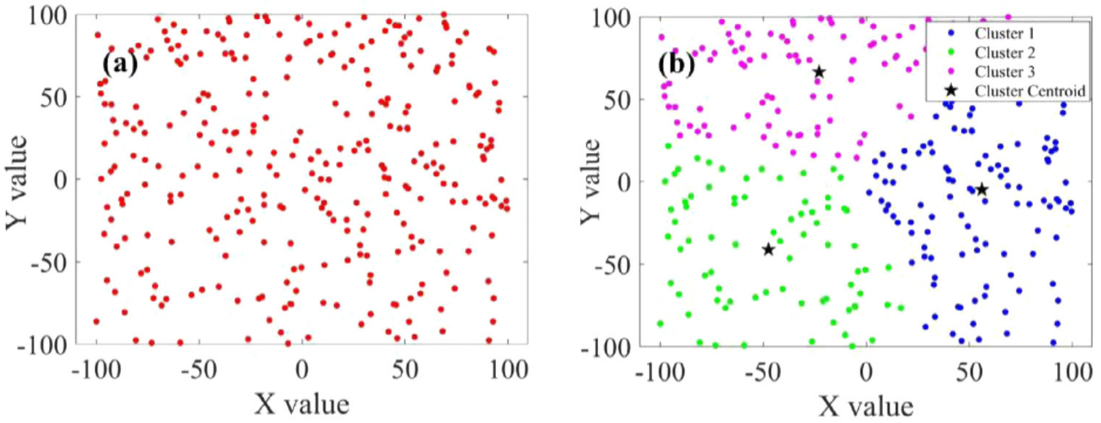
在KO算法中,簇的数量与选定的质心数量相对应,为了达到快速且高质量的搜索空间,选择
K
=
3
K = 3
K=3。如果我们将
P
(
t
)
P(t)
P(t)视为任意迭代中的输入数据集,可以计算得到包含三行和
D
D
D列的质心向量
C
(
t
)
C(t)
C(t):
P
(
t
)
‾
→
K
−
m
e
a
n
s
C
(
t
)
=
{
C
1
(
t
)
C
2
(
t
)
C
3
(
t
)
}
=
[
c
1
,
1
(
t
)
c
1
,
2
(
t
)
⋯
⋯
c
1
,
D
(
t
)
c
2
,
1
(
t
)
c
2
,
2
(
t
)
⋯
⋯
c
2
,
D
(
t
)
c
3
,
1
(
t
)
c
3
,
2
(
t
)
⋯
⋯
c
3
,
D
(
t
)
]
3
×
D
\begin{aligned} & \overline{P\left(t\right)}\xrightarrow{K-means}C\left(t\right)= \begin{Bmatrix} C_{1}\left(t\right) \\ C_{2}\left(t\right) \\ C_{3}\left(t\right) \end{Bmatrix} \\ & = \begin{bmatrix} c_{1,1}^{(t)} & c_{1,2}^{(t)} & \cdots & \cdots & c_{1,D}^{(t)} \\ c_{2,1}^{(t)} & c_{2,2}^{(t)} & \cdots & \cdots & c_{2,D}^{(t)} \\ c_{3,1}^{(t)} & c_{3,2}^{(t)} & \cdots & \cdots & c_{3,D}^{(t)} \end{bmatrix}^{3\times D} \end{aligned}
P(t)K−meansC(t)=⎩
⎨
⎧C1(t)C2(t)C3(t)⎭
⎬
⎫=
c1,1(t)c2,1(t)c3,1(t)c1,2(t)c2,2(t)c3,2(t)⋯⋯⋯⋯⋯⋯c1,D(t)c2,D(t)c3,D(t)
3×D
移动策略
KO将计算其当前位置与最佳解决方案之间的相对距离:
D
S
A
i
(
t
)
=
∥
S
A
i
(
t
)
→
−
P
b
e
s
t
(
t
)
→
∥
2
∥
P
w
o
r
s
t
(
t
)
→
−
P
b
e
s
t
(
t
)
→
∥
2
D_{SA_i}\left(t\right)=\frac{\left\|\overrightarrow{SA_i^{(t)}}-\overrightarrow{P_{best}^{(t)}}\right\|_2}{\left\|\overrightarrow{P_{worst}^{(t)}}-\overrightarrow{P_{best}^{(t)}}\right\|_2}
DSAi(t)=
Pworst(t)−Pbest(t)
2
SAi(t)−Pbest(t)
2
开发策略
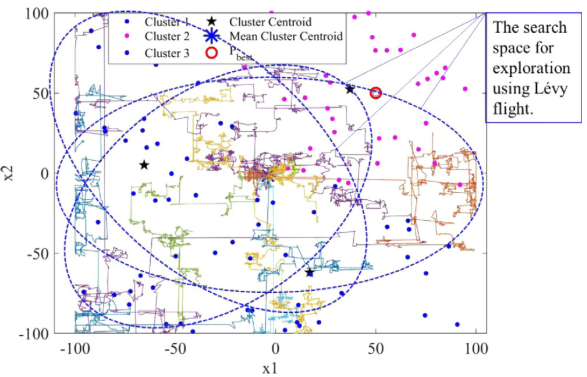
为了使KO的搜索空间多样化,除了每次迭代利用三个质心向量位置外,KO还增加了一个新的搜索区域,称为平均质心向量位置:
C
m
e
a
n
(
t
)
→
=
C
1
(
t
)
→
+
C
2
(
t
)
→
+
C
3
(
t
)
→
3
\overrightarrow{C_{mean}^{(t)}}=\frac{\overrightarrow{C_1^{(t)}}+\overrightarrow{C_2^{(t)}}+\overrightarrow{C_3^{(t)}}}{3}
Cmean(t)=3C1(t)+C2(t)+C3(t)
在KO中,高质量的搜索空间定义:
Ω
∗
=
{
C
1
(
t
)
→
,
C
2
(
t
)
→
,
C
3
(
t
)
→
,
C
m
e
a
n
(
t
)
→
,
P
b
e
s
t
(
t
)
→
}
\Omega^{*}=\left\{\overrightarrow{C_{1}^{(t)}},\overrightarrow{C_{2}^{(t)}},\overrightarrow{C_{3}^{(t)}},\overrightarrow{C_{mean}^{(t)}},\overrightarrow{P_{best}^{(t)}}\right\}
Ω∗={C1(t),C2(t),C3(t),Cmean(t),Pbest(t)}
第一个开发趋势侧重于开发当前每个搜索代理的当前位置
S
A
(
t
)
→
\overrightarrow{SA(t)}
SA(t)、最佳位置
P
(
t
)
b
e
s
t
→
\overrightarrow{P(t)_{best}}
P(t)best和质心位置
C
(
t
)
m
e
a
n
→
\overrightarrow{C(t)_{mean}}
C(t)mean之间建立的搜索空间,:
S
A
i
(
t
+
1
)
→
=
w
11
P
b
e
s
t
(
t
)
→
+
d
1
(
t
)
∣
S
A
i
(
t
)
→
−
w
12
P
b
e
s
t
(
t
)
→
∣
+
d
2
(
t
)
∣
S
A
i
(
t
)
→
−
w
13
C
m
e
a
n
(
t
)
→
∣
\overrightarrow{SA_{i}^{(t+1)}}=w_{11}\overrightarrow{P_{best}^{(t)}}+d_{1}\left(t\right)\left|\overrightarrow{SA_{i}^{(t)}}-w_{12}\overrightarrow{P_{best}^{(t)}}\right|+d_{2}\left(t\right)\left|\overrightarrow{SA_{i}^{(t)}}-w_{13}\overrightarrow{C_{mean}^{(t)}}\right|
SAi(t+1)=w11Pbest(t)+d1(t)
SAi(t)−w12Pbest(t)
+d2(t)
SAi(t)−w13Cmean(t)
第二个开发趋势侧重于高质量的搜索空间:
S
A
i
(
t
+
1
)
→
=
w
21
S
A
i
(
t
)
→
+
w
22
(
P
b
e
s
t
(
t
)
→
−
w
23
S
A
i
(
t
)
→
)
+
∑
k
=
1
3
δ
k
(
C
k
(
t
)
→
−
β
k
S
A
i
(
t
)
→
)
\overrightarrow{SA_i^{(t+1)}}=w_{21}\overrightarrow{SA_i^{(t)}}+w_{22}\left(\overrightarrow{P_{best}^{(t)}}-w_{23}\overrightarrow{SA_i^{(t)}}\right)+\sum_{k=1}^{3}\delta_{k}\left(\overrightarrow{C_k^{(t)}}-\beta_{k}\overrightarrow{SA_i^{(t)}}\right)
SAi(t+1)=w21SAi(t)+w22(Pbest(t)−w23SAi(t))+k=1∑3δk(Ck(t)−βkSAi(t))
第三个开发趋势利用在平均质心向量位置:
S
A
i
(
t
+
1
)
→
=
w
31
C
m
e
a
n
(
t
)
→
+
w
32
(
P
b
e
s
t
(
t
)
→
−
w
33
C
m
e
a
n
(
t
)
→
)
\overrightarrow{SA_i^{(t+1)}}=w_{31}\overrightarrow{C_{mean}^{(t)}}+w_{32}\left(\overrightarrow{P_{best}^{(t)}}-w_{33}\overrightarrow{C_{mean}^{(t)}}\right)
SAi(t+1)=w31Cmean(t)+w32(Pbest(t)−w33Cmean(t))
第一个探索趋势利用Levy飞行:
S
A
i
(
t
+
1
)
→
=
C
m
e
a
n
(
t
)
→
+
s
t
e
p
l
e
n
g
t
h
(
S
)
i
f
r
a
n
d
(
0
,
1
)
>
0.5
\overrightarrow{SA_i^{(t+1)}}=\overrightarrow{C_{mean}^{(t)}}+steplength(S)\quad ifrand(0,1)>0.5
SAi(t+1)=Cmean(t)+steplength(S)ifrand(0,1)>0.5
在某些情况下,全局最优解可能位于一个距离平均质心向量位置较远的区域。为了克服这一限制,搜索空间会进行调整:
S
A
i
(
t
+
1
)
→
=
L
b
+
r
a
n
d
(
0
,
1
)
(
U
b
−
L
b
)
l
F
r
a
n
d
(
0
,
1
)
<
0.5
\overrightarrow{SA_i^{(t+1)}}=L_b+rand\left(0,1\right)\left(U_b-L_b\right)\quad lFrand\left(0,1\right)<0.5
SAi(t+1)=Lb+rand(0,1)(Ub−Lb)lFrand(0,1)<0.5
伪代码

4.结果展示


5.参考文献
[1] Minh H L, Sang-To T, Wahab M A, et al. A new metaheuristic optimization based on K-means clustering algorithm and its application to structural damage identification[J]. Knowledge-Based Systems, 2022, 251: 109189.