信息检索4
接上一节——信息检索3
第四章 布尔模型与倒排索引
一、信息检索模型
DDocument
Q:关键词或是布尔表达式或是自然语言,查询集合
DQ一样:基于内容的查询;否则多模态查询
R排序函数
F框架,包括QD,匹配函数(QD的关系)(检索系统的理论框架包括预处理、中间处理)
基于内容的信息检索模型
集合论模型:布尔模型、模糊集合模型、扩展布尔模型
代数模型:向量空间模型,神经网络模型,广义向量空间模型,潜在语义标引模型
概率模型:经典概率模型,推理网络模型
深度学习模型(召回+精排)
经典信息检索模型:布尔模型,向量空间模型,经典概率模型
二、布尔检索模型
简单的检索模型,在集合论和布尔代数基础上
基本规则:每个索引词在一篇文档中只有两种状态:出现或不出现(0或1);每篇文档是索引词(0或1)的集合
词袋模型bag of words
假定:对于一个文本,忽略次序和语法句法(只看做词的集合或是词的组合);每个词都相互独立,不依赖其他词是否出现(任意一个位置选择一个词汇都不受到前面句子的影响)
ComputerVision中Bag of word可用来表示图像的特征描述
矩阵的某一列,就是一个词袋
布尔代数
布尔表达式:多个布尔变量之间通过布尔操作组成的表达式;蕴含P -> Q
布尔操作:and or not
文档表示:关键词的集合
查询表示:查询式为关键词的不二组合
相关度计算:文档满足布尔查询式才被检索,二值匹配01
形式化表示


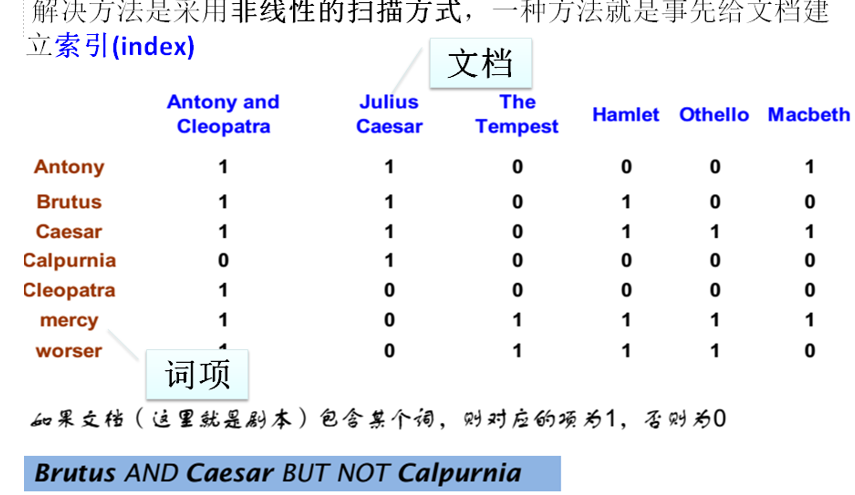

数据结构
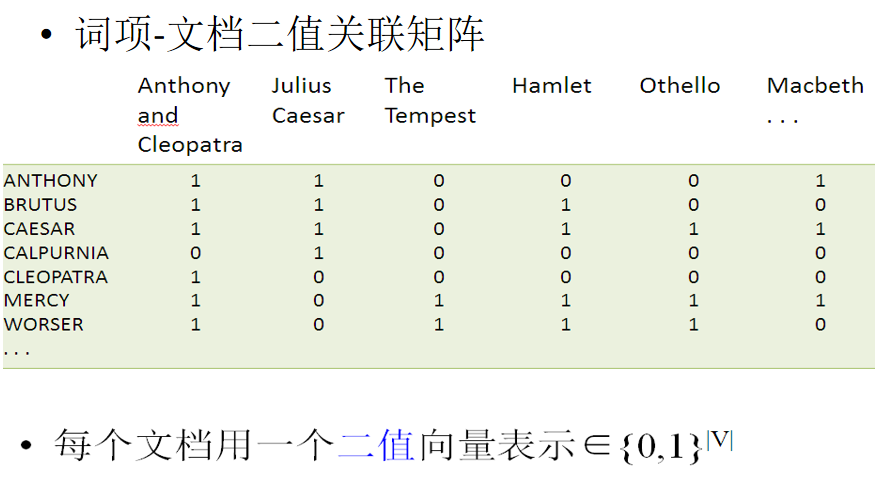
词项文档矩阵
庞大,稀疏
构造相关矩阵:每一列就是完整文本,某一个行是某个词项。非常大,非常稀疏->只记录1的位置
三、倒排索引
搜索引擎的核心数据结构为倒排文件(Inverted Files) 也称倒排索引:词项+倒排记录
词项词典:对于每一个词项,存储所有包含这个词项的文档的一个列表,应当用可变长度的记录列表
倒排记录表:一个文档用一个序列号docID来表示
建立索引的步骤
词条序列token squence,修改过的词条、文档ID对序列->
排序:先按照词条排序,再按照docID排序->
构建词典和倒排表:同一篇文档中多次出现的词被合并;分割成词典和倒排表
词典,每个词条后面跟着可变长的倒排记录表(出现该词项的表),共同构成倒排索引
四、倒排索引的操作
4.1查询处理
单个词查询;多词查询(and/or)
4.2基于跳表(Skip List)的倒排记录表
倒排记录表数据结构的扩展形式;快速合并(跳表指针能够提供捷径来跳过那些不可能出现在检索结果中的记录项);构建索引的同时在倒排记录表上建立跳表


放置跳表指针的一个简单的启发式策略是: 如果倒排表的长度是L,那么在每个根号L处均匀放置跳表指针 该策略没有考虑到查询词项的分布
如果索引相对固定的话,建立有效的跳表指针比较容易,如果索引需要经常的更新,建立跳表指针就相对困难。
注意:跳表指针只对AND类型的查询有用,对OR类型的查询不起作用。
4.3包含位置信息的倒排记录表
(词袋模型:不考虑词在文档中出现的顺序,位置索引考虑)
位置索引:
用于短语查询(查询输入时需要加入双引号表明是一个词)
邻近查询:两个词之间相距k个词

实现方法:
1.二元词索引
相邻的两个词作为一个整体
扩展的二元词索引:考虑词性 删除,将形式为N(名词)*X(虚词,其他词性)N非词项序列看成一个扩展的二元词

2.二元信息索引
每个词项的信息:词项,词项数目,文档1:位置1,位置2


采用位置索引会大大增加倒排记录表的存储空间,采取这种索引方式,用于用户期望的 短语查询 邻近查询
经验:位置索引大概是非位置索引大小的2~4倍 位置索引的大小大约是原始文档的30%~50%
混合索引
处理开销最大的短语查询 它们中的每个词都非常常见, 但是组合起来却相对很少见
二元词索引和位置索引二种策略可以进行有效的合并
选择方法原则:
五、布尔模型的特点
优点:查询简单,容易理解;通过使用复杂的布尔表达式,可方便地控制查询结果
缺点:不能输出部分匹配的情况;无权重设计,无法排序;用户必须用布尔表达式提问,检出的文档太多或太少;很难进行自动的相关反馈
第五章 向量空间模型VSM
一、布尔检索模型的特点
布尔模型的优缺点(在第四章末尾)
排序检索
在排序检索模型中,系统根据文档与query的相关性排序返回文档集合中的文档,而不是简单地返回所有满足query描述的文档集合 希望根据文档对查询者的有用性大小顺序排序:给每个“查询-文档对”进行评分,在[0,1]之间 ,这个评分值衡量文档与query的匹配程度
评分
布尔检索模型:单个词组成的query 如果该词项不出现在文档中,该文档评分为0 该词项在文档中出现,则评分为1 。存在问题:多个词组成的query? 全部满足,则评分为1 其他,评分为0。那么部分满足呢?
计算查询和文档之间的相似度
曼哈顿距离 欧几里得距离 Jaccard相似度 余弦相似度
曼哈顿:标明两个点在标准坐标系上的绝对轴距总和

lucene默认使用TF/IDF模型来计算文档与查询的相关性:
TF(Term Frequency): 词频,即某个词在文档中出现的次数。
IDF(Inverse Document Frequency): 逆文档频率, 用于衡量一个词在所有文档中的普遍重要性。 一个词在越多文档中出现,其IDF值越低,反之则越高。
二、词项频率TF
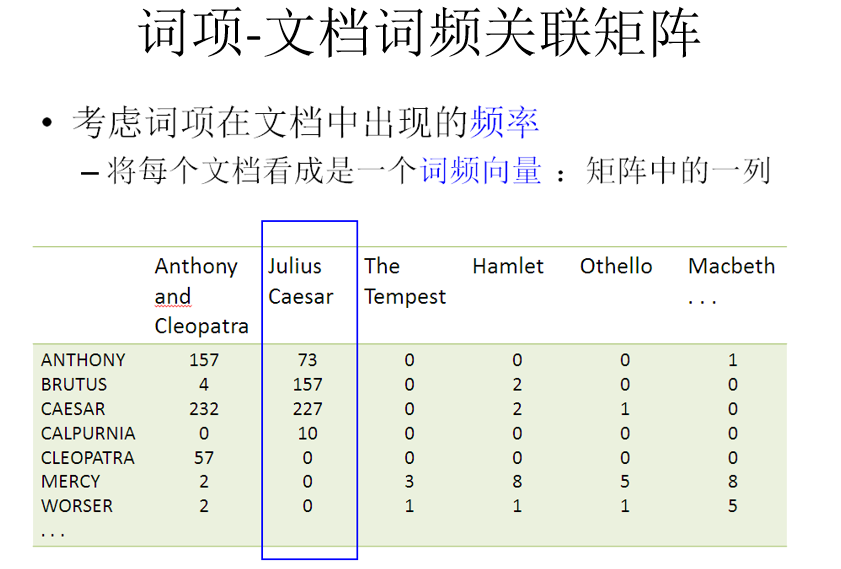

相关性不会正比于词项频率,所以用对数频率


三、tf-idf权重计算
除词项频率tf之外,我们还想利用词项在整个文档集中的频率进行权重和评分计算 罕见词项比常见词所蕴含的信息更多
对于含有两个以上查询词的query,idf才会影响排序结果

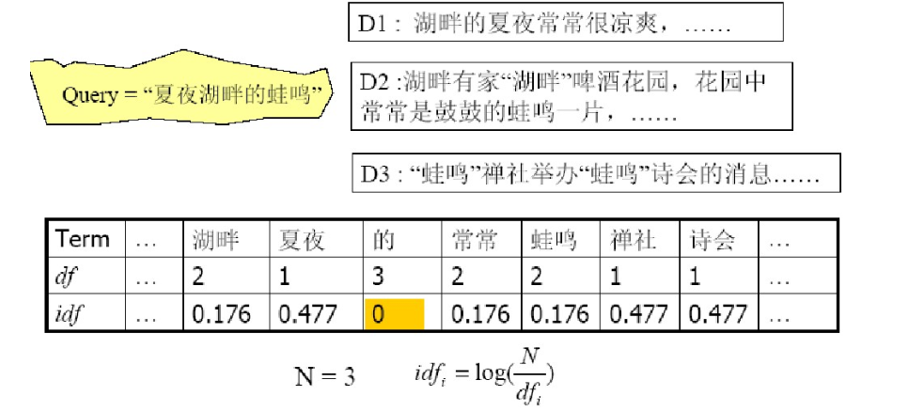

公式要记住!!!
tf-idf值随着词项在单个文档中出现次数(tf)增加而增大,随着词项在文档集中数目(df)增加而减小


TF-IDF是一种统计方法
四、向量空间模型
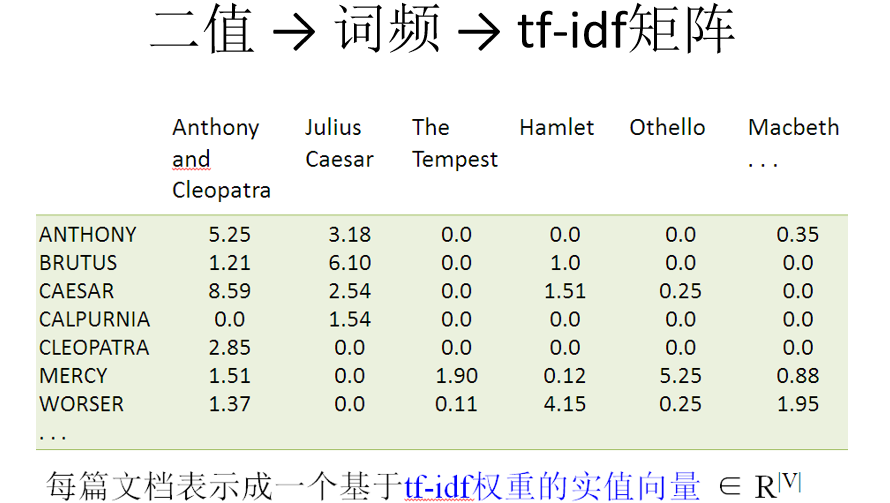


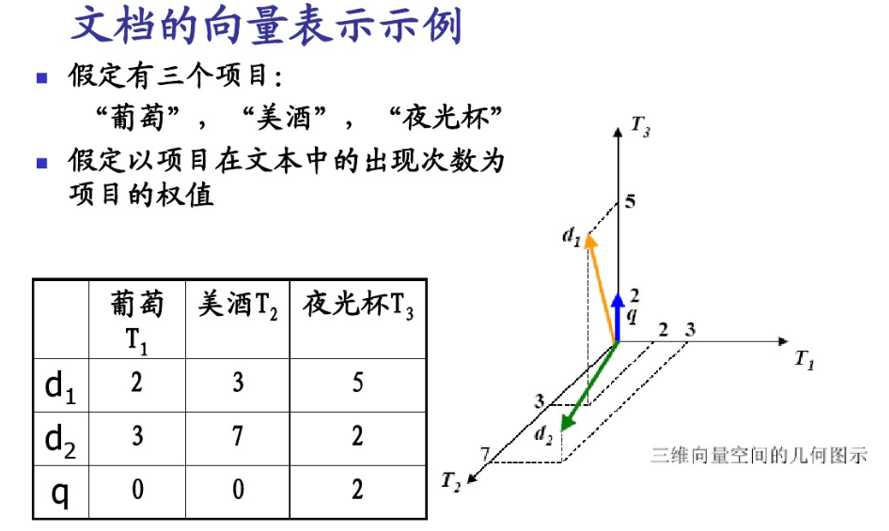
相似度计算
Jaccard相似度:比较文本相似度,用于文本查重与去重- 集合;欧式距离-点;余弦相似度-向量
不用欧式距离:
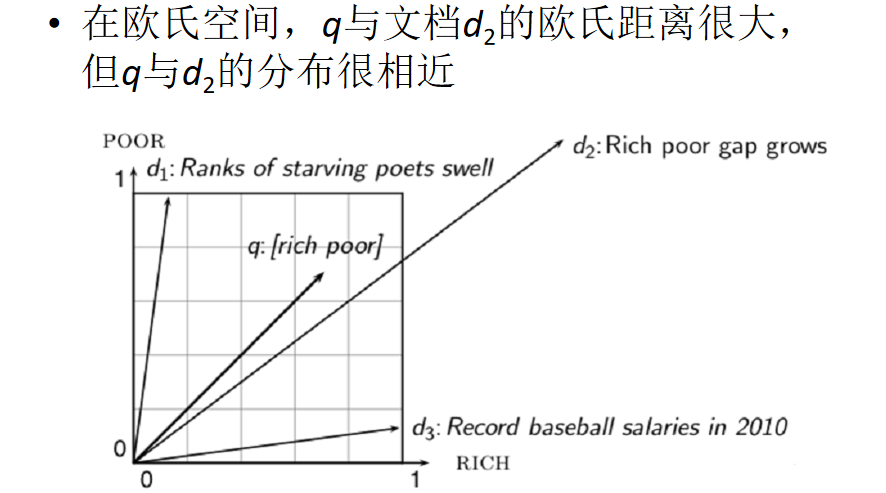
用余弦相似度:更多的是从方向上区分差异,而对的数值不敏感
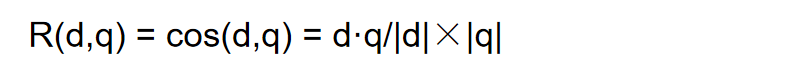

文档长度归一化
长短文档差异不会影响相关性

向量空间模型

当向量空间模型的向量值采用 tf-idf ,对一般的文档集合,效果比较好
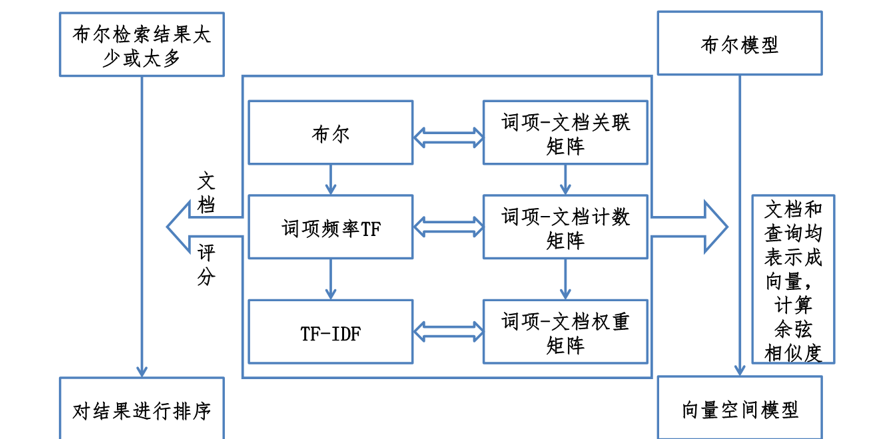
Vector Space Model, VSM 文本内容的处理简化为向量空间中的向量 以空间上的相似度表达语义的相似度 相比于布尔模型要求的准确匹配, VSM模型采用了“部分匹配”的检索策略(即:出现部分索引词也可以出现在检索结果中)。 通过给查询或文档中的索引词分配非二值权值来实现, 有序
向量空间模型的特点
优点: 帮助改善了检索结果; 部分匹配的文档也可以被检索到; 可以基于向量cosine 的值进行排序,提供给用户。
缺点: 这种方法假设标记词是相互独立的,但实际可能不是这样,如同义词、近义词等往往被认为是不相关的词;维度非常高:特别是互联网搜索引擎,空间可能达到千万维或更高;向量空间非常稀疏:对每个向量来说大部分都是0
在 VSM/BoW 里,系统把每个词当成独立打分员。一篇文档对一个查询的总分 = 各个词各自给的分相加。
词与词之间不互相影响,也没有“配合加分”。


五、向量空间模型的价值
VSM模型的价值:将无结构化文本表示为向量,各种数学处理成为可能


查询与文档的相似度:4种
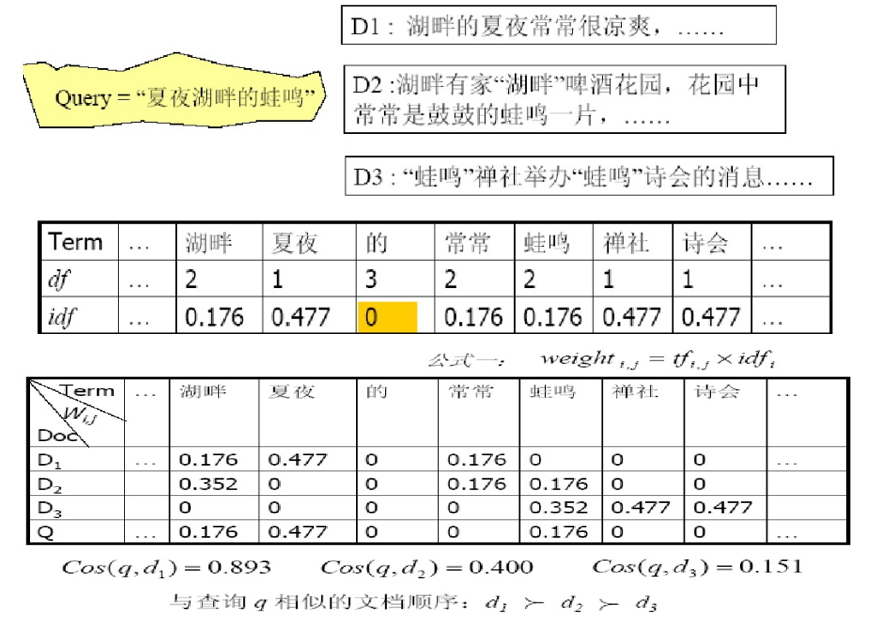
相关性:词频TF->词频关联矩阵 相差过大->对数词频
匹配得分:D和Q同时出现的 sum(1+logTF)
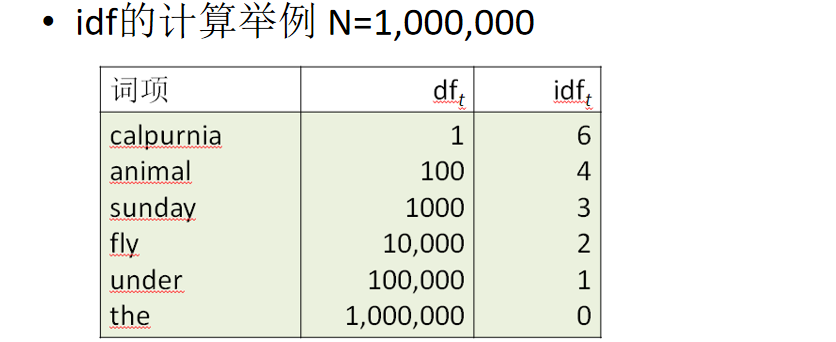
考虑罕见词的权重更高(停用词零权重) 越不常见,idf越大,idf = lg(n/df)
w = (1+logtf)*lg(N/df) 要记住!!! ->tf-idf矩阵,内容为w
每个维度对应一个词项(认为每个维度独立,把语义割裂了);Q看作特殊的文档
有向量空间,进行相似度方法:余弦,不用欧式距离(文章越长,距离越大) QD差距太大,需要归一化
优缺点
纬度高,稀疏
降维时可以加入语义关联
价值
第六讲 概率检索模型
布尔模型最大的问题:非1即0
向量空间模型
文档表示成向量, 查询也表示成向量, 两个向量之间的相似度:余弦相似度,内积相似度等等, 在向量表示中的词项权重计算方法,主要是tf-idf公式, 余弦相似度: 实际考虑 tf, idf以及文档长度三个因素

-
tf(term frequency):某词在当前文档/图像中出现“多频繁”。
-
df(document frequency):在整个语料库里,有多少文档包含该词。NNN 为总文档数,dft\text{df}_tdft 为包含词 ttt 的文档数。
-
归一化:把一篇文档的整条向量缩放,消除文档长短、字多少带来的可比性问题。
在视觉 BoVW 里,可把“文档=图像”,“词=视觉词(聚类中心)”。
A) tf(左列)
-
n(natural)
-
直觉:原始词频,越多越重要。
-
公式:tft,d\mathrm{tf}_{t,d}tft,d
-
优点简单;缺点:burstiness(同一局部反复出现)会把权重推得很高。
-
-
l(logarithm,对数 tf / 次线性缩放)
-
直觉:出现 10 次不一定比 5 次“重要两倍”,用对数“压一压”。
-
公式:1+log(tft,d)1+\log(\mathrm{tf}_{t,d})1+log(tft,d)(tf=0\mathrm{tf}=0tf=0 时定义为 0)
-
常用,鲁棒性好,是很多检索/分类的默认。
-
-
a(augmented,放缩到 [0.5,1])
-
直觉:按该文档内出现最多的词做相对缩放,压制极高频词。
-
公式:0.5+0.5⋅tft,dmaxt′(tft′,d)0.5+0.5\cdot \dfrac{\mathrm{tf}_{t,d}}{\max_{t'}(\mathrm{tf}_{t',d})}0.5+0.5⋅maxt′(tft′,d)tft,d
-
适用于“文档内部词频跨度特别大”的场景。
-
-
b(boolean)
-
直觉:只关心“出现没出现”,不关心次数。
-
公式:1[tft,d>0]\mathbb{1}[\mathrm{tf}_{t,d}>0]1[tft,d>0]
-
适合很稀疏、噪声较大或只做粗检索/过滤。
-
-
L(log ave,对数并做文档内平均纠正)
-
直觉:对数缩放后,再除以“该文档的平均对数 tf”,进一步抵消“这篇文档整体词都很多/很少”的影响。
-
公式:1+log(tft,d)1+log(avet′(tft′,d))\displaystyle \frac{1+\log(\mathrm{tf}_{t,d})}{1+\log(\text{ave}_{t'}(\mathrm{tf}_{t',d}))}1+log(avet′(tft′,d))1+log(tft,d)
-
B) df / idf(中列)
-
n(no idf)
-
不用 idf(权重乘 1)。当词表已经非常“干净”、或者只做同域内相似度、不希望稀有词被过分放大时使用。
-
-
t(idf)
-
直觉:越“稀有”的词越能区分文档。
-
公式:idft=logNdft\mathrm{idf}_t=\log \dfrac{N}{\mathrm{df}_t}idft=logdftN(可加平滑,如 log1+N1+dft\log\frac{1+N}{1+\mathrm{df}_t}log1+dft1+N)
-
最常用;在 BoVW 中可显著抑制“到处都有的纹理词”。
-
-
p(prob idf,概率型 idf)
-
直觉:衡量“出现 vs 不出现”的对数几率。
-
公式:max (0, logN−dftdft)\max\!\left(0,\ \log \dfrac{N-\mathrm{df}_t}{\mathrm{df}_t}\right)max(0, logdftN−dft)
-
对非常常见的词给更强的惩罚(甚至截断为 0),在抗噪/防止常见词主导上更激进。
-
C) 归一化(右列)
-
n(none)
-
不归一化。仅限长度近似一致、或你另有长度控制时。
-
-
c(cosine,L2 归一化)
-
直觉:把整条向量缩到长度 1,比较方向而非模长。
-
公式:整篇文档的权重向量 w←w/∥w∥2\mathbf{w}\leftarrow \mathbf{w}/\|\mathbf{w}\|_2w←w/∥w∥2
-
文本与视觉检索里最通用;与余弦相似度天然匹配。
-
-
u(pivoted unique / pivoted length)
-
直觉:根据文档“独特词数/长度”做倾斜归一化,比简单 L2 更细致地修正“长文优势”。
-
常见形式:1(1−α)+α⋅len(d)pivot\displaystyle \frac{1}{(1-\alpha)+\alpha\cdot \frac{\text{len}(d)}{\text{pivot}}}(1−α)+α⋅pivotlen(d)1,α∈(0,1)\alpha\in(0,1)α∈(0,1)。
-
适合长度差异巨大的集合(长网页 vs 短网页、长描述 vs 短描述)。
-
-
b(byte/char 长度归一)
-
直觉:按字符/字节长度做缩放:1CharLengthα (0<α<1)\displaystyle \frac{1}{\text{CharLength}^\alpha}\,(0<\alpha<1)CharLengthα1(0<α<1)。
-
多用于工程场景的简单长度校正。
-
把概率加入模型
一、 Probability ranking principle PRP
有QD,相关概率多少?按照概率大小排序
概率检索模型作为一个分类问题, P(R=1|q,d)代表给定一个文档D对应的相关性概率, P(R=0|q,d)代表给定一个文档D对应的不相关概率。
获得每种概率的分布,朴素贝叶斯
思想:文档每一个词计算相关度,再相加


二、 Binary Independence Model BIM
二值独立概率模型,假设每个词是独立的
文档有这个词是1,没有就是0
也是词包模型,没有了tf
与布尔模型有什么联系与区别?


几率(odds) 定义:事件发生的概率与该事件不发生的概率的比值
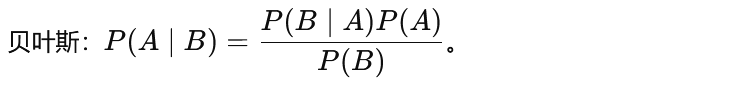
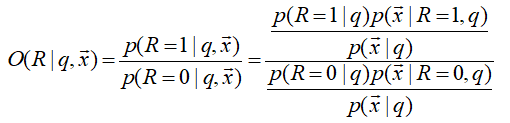

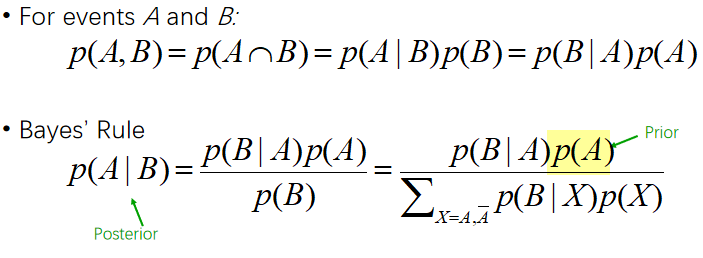
每个词出现的可能性:
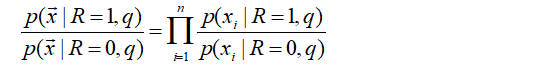
最后得到:
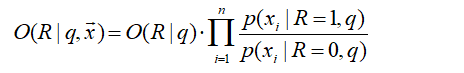
x有两种情况,展开;并用pr符号简化表示:
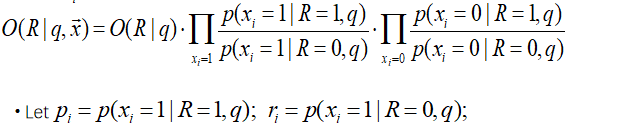
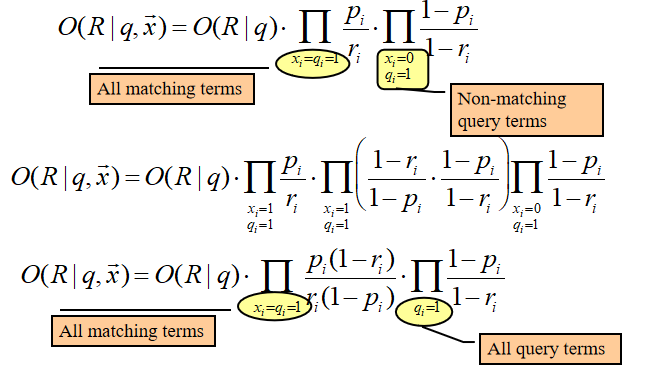
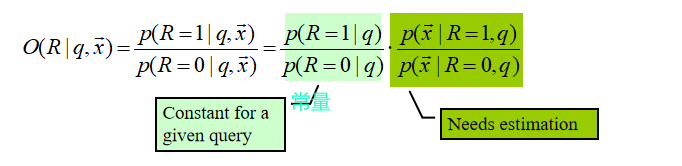
pi=P(xi=1∣R=1,q)、ri=P(xi=1∣R=0,q)只取决于“查询 q 和全局统计/估计方式”,一旦 q 固定,它们就不随文档 x 改变
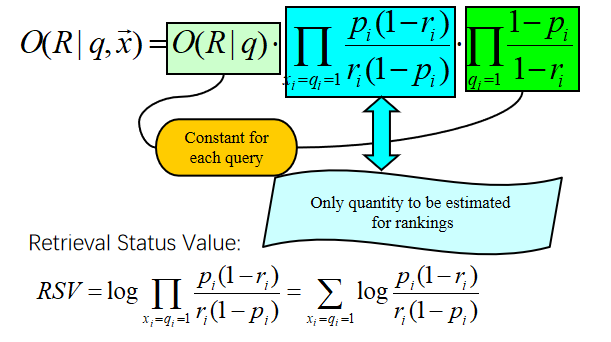
要记住蓝色部分的公式!!!
取对数容易计算


词袋模型:不考虑语序,只考虑词是否出现


 先假设p为0.5
先假设p为0.5

实际相关的S远远小于N,n远小于N

再优化矫正:

优缺点
优点:BIM在数学基础上,理论性强
缺点:需要估计参数;原始的BIM没有考虑TF,文档长度因素;独立性假设;二元
三、BM25
非深度模型中表现最好

预测出现多少次:

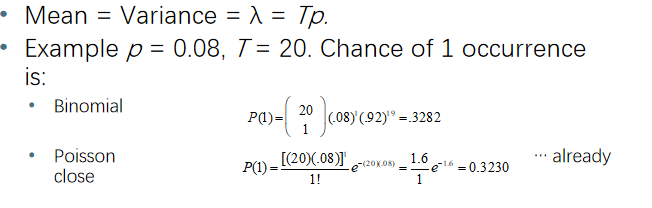
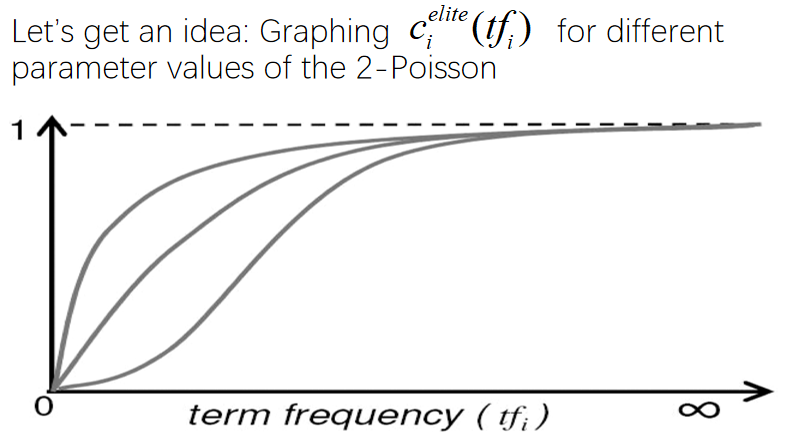
问题:是否有精英词


三个参数不知道,但有特点:
初始值为0,接近无穷时为1
可尝试用饱和函数代替:
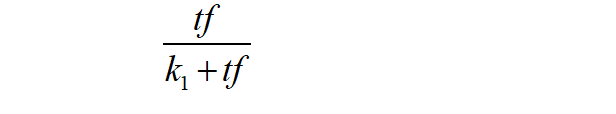
k1与趋势无关:
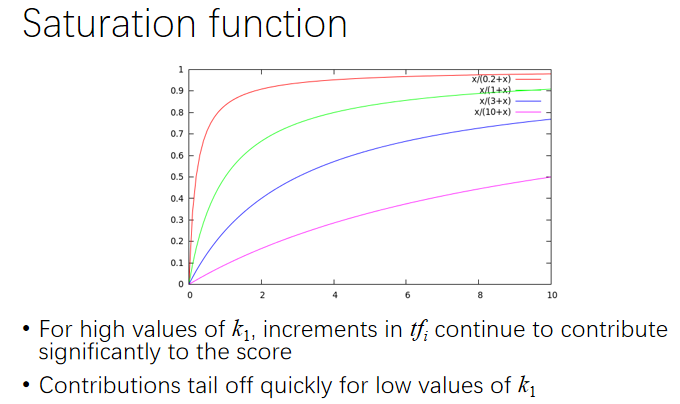

ver2限制tf的增长极限
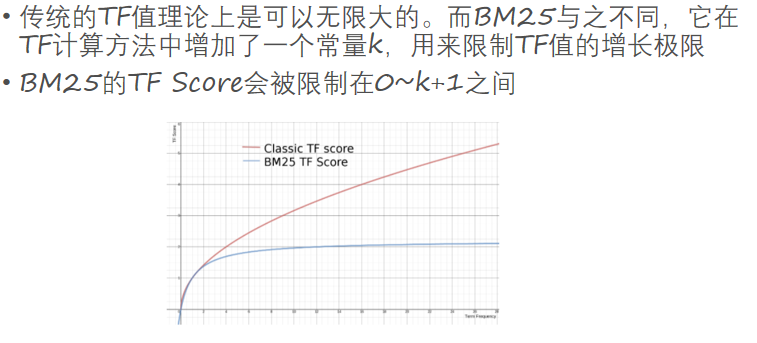
但是还没有长度的归一化

最终公式:
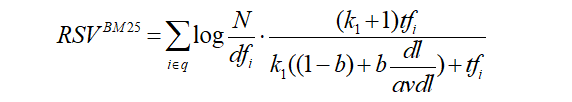
更近一步,查询很长时:

实现方式: 在Lucene中,可以使用BM25 Similarity类来实现BM25算法。 创建一个Similarity对象,并将其设置为BM25 Similarity,然后将其应用到IndexWriterConfig和IndexSearcher中。 这样,在创建索引和进行查询时,Lucene就会使用BM25算法来计算文档的相关性得分。



理解
为什么要关注一个词是否出现?






看图像







第七讲 搜索引擎工具
一、全文检索的流程

搜索引擎主要技术:爬虫;文本分析,NLP;建立索引;查询,查询分析 NLP,相关度计算;排序
二、开源搜索引擎 Lucene
2.1 Lucence概述
Lucene:免费Java信息检索程序库
PyLucene
https://lucene.apache.org/pylucene/ 基于Python的Lucene
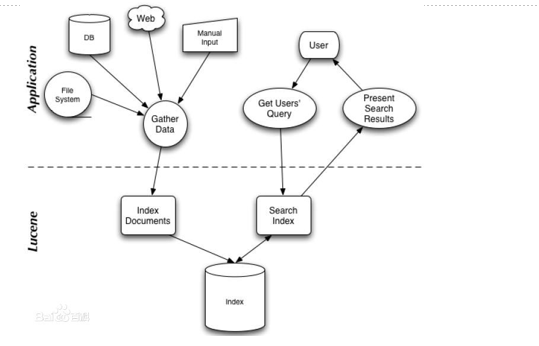
没有爬虫,交互界面
2.2. 创建索引
全文检索的流程分为两大部分:
索引流程: 确定原始内容即要搜索的内容
2.2.1 采集原始内容数据 2.2.2 创建文档 2.2.3 分析文档(分词) 2.2.4 创建索引
搜索流程
2.2.1 采集数据-文件格式
1、网页,通过http协议抓取html网页内容到本地。 Lucene提供了内置的HTML解析器,用于解析HTML文件的内容。 获取文件的标题、摘要以及元标签等信息。
2、数据在数据库中,需要通过jdbc访问数据库表中的内容。 文本、数值、日期、二进制字段
3、Adobe reader *.pdf
PDFBox PDF文本抽取工具 http://sourceforge.net/projects/pdfbox 不支持中文
Xpdf http://www.foolabs.com/xpdf/download.html
4、Word excel
OPI http://jakarta.apache.org/opi
5、文件系统中的某个文件,就通过I/O读取文件的内容。
最好是纯文本
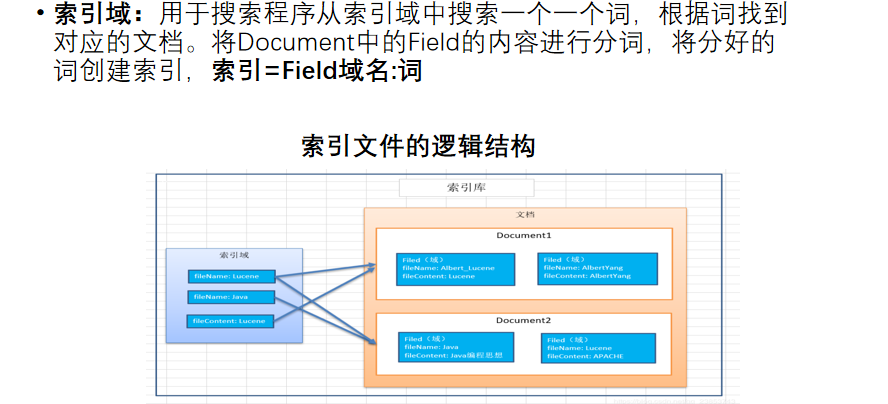
2.2.2 创建文档对象(Document)
把查询的内容构建成lucene能识别的Document对象
在索引前需要将原始内容创建成文档
每个文档都有一个唯一的编号,就是文档 id
文档中包括一个一个的域(Field), 这个域对应就是表中的列
每个 Document 可以有多个 Field, 不同的 Document 可以有不同的 Field, 同一个Document 可以有相同的 Field(域名和域值都相同)

2.2.3 分析文档(分词)
分析文档 : 将原始内容创建为包含域(Field)的文档(document), 需要再对域中的内容进行分析
分析的过程 对原始文档提取单词、 将字母转为小写、 去除标点符号、 去除停用词等 生成最终的语汇单元term ,可以将语汇单元理解为一个一个的单词。
分析文档:
词条化(Tokenization) 对原始文档提取单词、将字母转为小写、去除标点符号 中文分词 “我是中国人”,分词:我、是、中国、中国人、国人
词项归一化 (Normalization)
词干还原 (Stemming)
词形归并 (Lemmatization)
停用词 (Stop Words)
词项词典建立 term
Lucene自带的中文分词器(效果不好)
StandardAnalyzer:单字分词: 就是按照中文一个字一个字地进行分词。 如:“我是中国人”, 效果:“我”、“是”、“中”、“国”、“人”。 CJKAnalyzer二分法分词: 按两个字进行切分。 如:“我是中国人”, 效果:“我是”、“是中”、“中国”“国人”。
第三方中文分词器 Ikanalyzer 注意版本
下载地址: https://code.google.com/archive/p/ik-analyzer/downloads
工作过程 在项目中添加ikanalyzer的jar包 修改分词器代码 Analyzer analyzer = new IKAnalyzer(); 扩展中文词库和停用词表 文件的编码要是utf-8。
注意:不要用记事本保存扩展词文件和停用词文件
2.2.4 创建索引
Lucene建立索引步骤

2.3 搜索流程

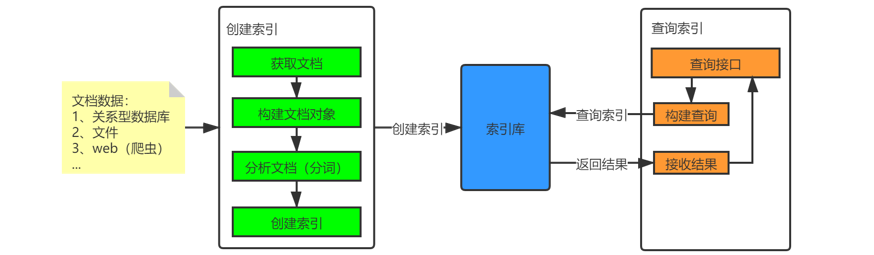

Lucene搜索索引过程

组合查询



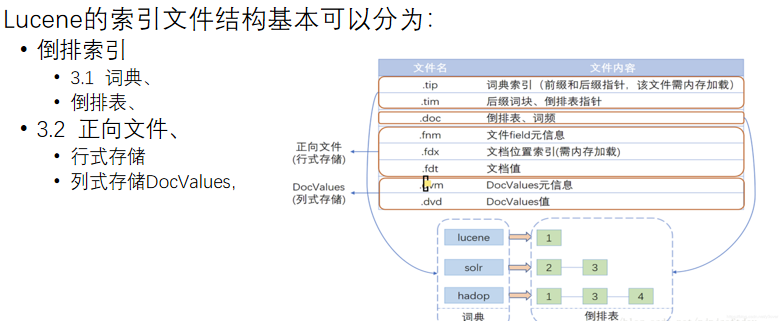
三、Lucene索引的文件结构
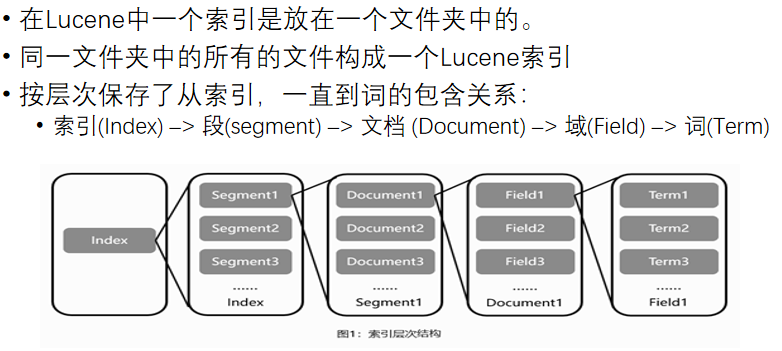
Lucene的索引结构是有层次结构的,主要包括索引(Index)、段(Segment)、文档(Document)和域(Field)等层次。
索引是放在一个文件夹中的,一个索引可以包含多个段,每个段包含多篇文档,而每篇文档由多个域组成。
词是索引的最小单位,经过词法分析和语言处理后的字符串被用作索引的基本单位。
Lucene通过这种结构化的方式,使得非结构化数据能够被有效地索引和检索
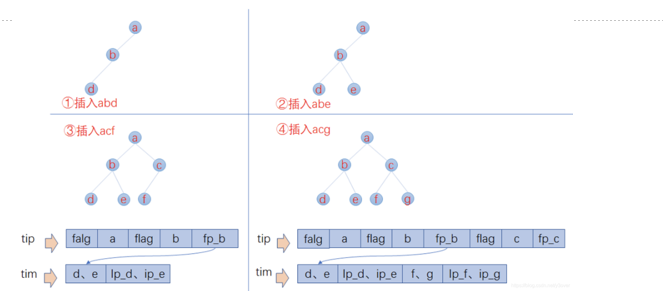
3.1 词典数据结构
排序列表(数组、list) 使用二分查找, 不平衡
跳跃表 占用内存小,可调整, 对模糊查询不友好
B树 磁盘索引,多用于关系型数据库
哈希表 效率高, 内存消耗大
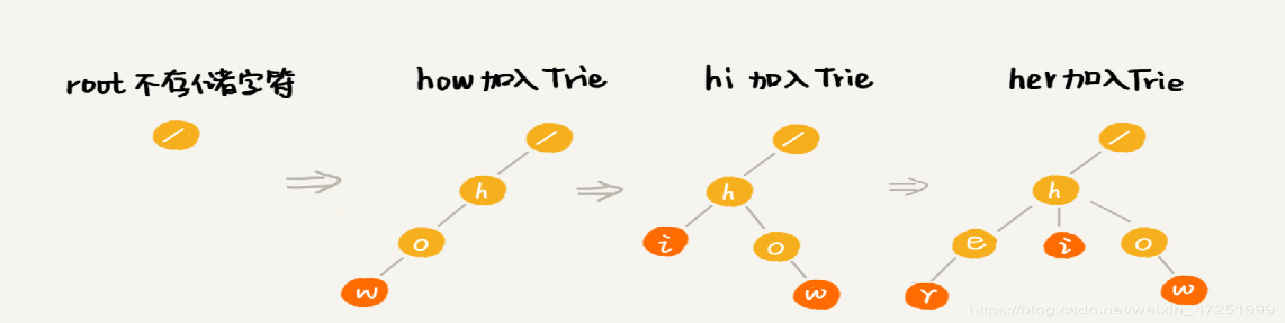
字典树 又称单词查找树,Trie树, 是一种树形结构, 是一种哈希树的变种。 利用字符串之间的公共前缀,将重复的前缀合并在一起 中文字典数:为每个中文字符创建一个字典树节点 查询效率与字符串长度有关
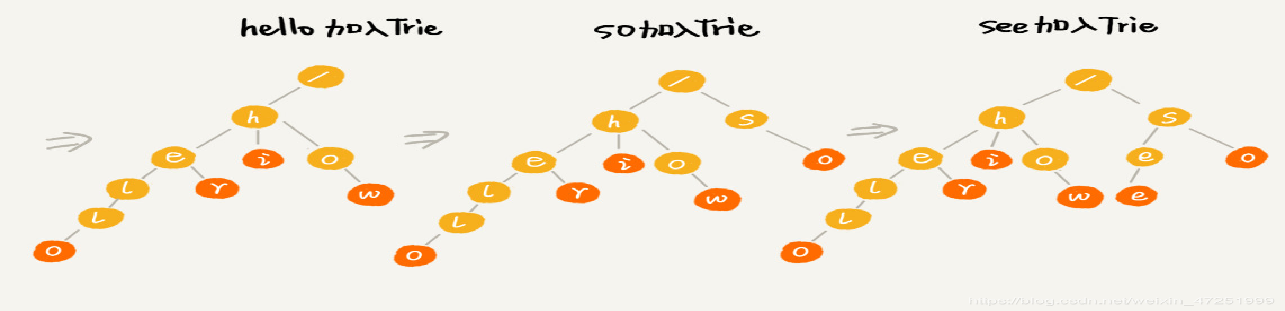
中文也可以这样放
词典数据结构

FST


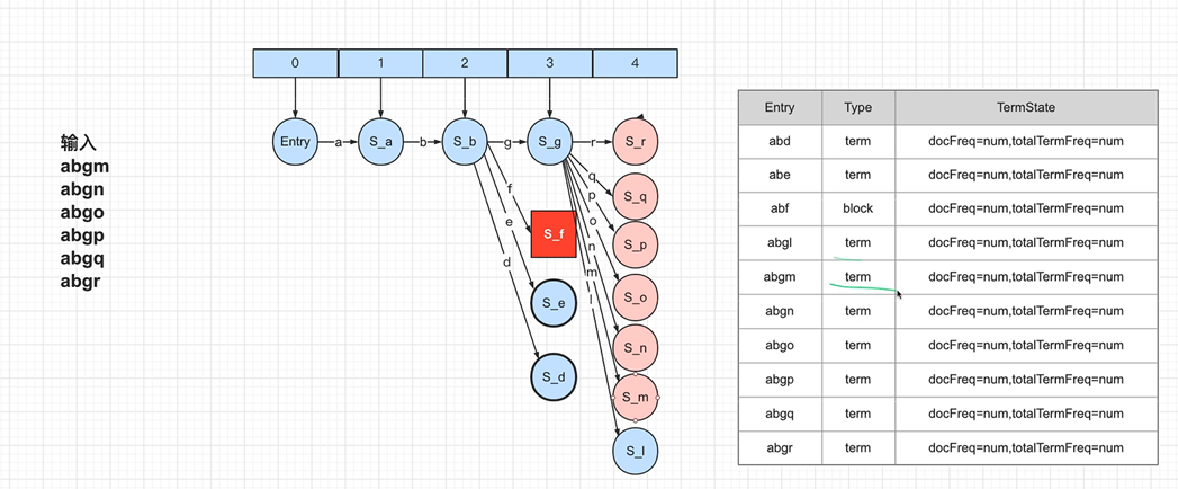
正向索引(term-vector)与反向倒排(inverted-index)索引
倒排索引: 分词(Term)到文档ID的映射关系。 field -> term -> doc -> freq/pos/offset/payload 倒排索引数据结构的设计更加适合回答一般的查询, 比如,我们查询某个值出现在哪些文档中。这是search engine中最基本的查询功能
正向索引: 文档ID到文档内容,文档字段(Field)的关联关系。 doc -> field -> term -> freq/pos/offset/payload 当我们已经找到了一个文档时,可以充分利用正向索引数据结构的设计,确切地找出搜索term在文档中的位置,并通过高亮显示在结果中
3.2 正向索引
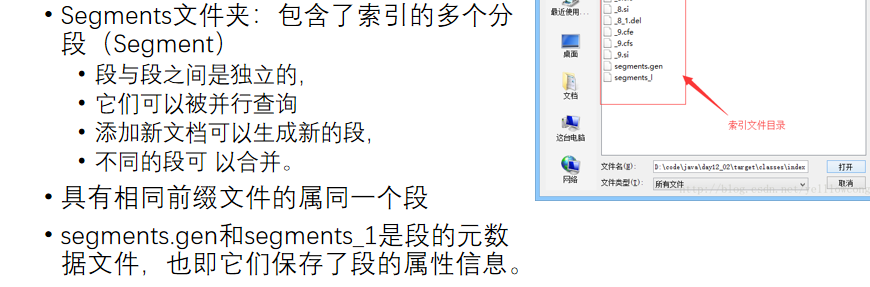
Segments文件夹:包含了索引的多个分段(Segment) 段与段之间是独立的, 它们可以被并行查询 添加新文档可以生成新的段, 不同的段可 以合并
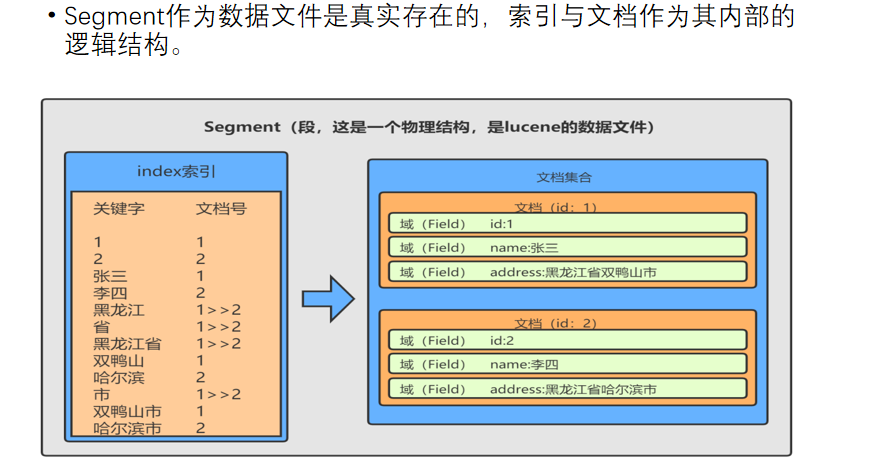
正向文件


四、Lucene相关工具软件

4.1 Nutch


4.2 Solr

4.3 ElasticSearch
