PyTorch深度学习框架60天进阶学习计划 - 第58天端到端对话系统(一):打造你的专属AI语音助手
PyTorch深度学习框架60天进阶学习计划 - 第58天端到端对话系统(一):打造你的专属AI语音助手
哈喽,今天我们来到了第58天的学习,是不是已经感觉自己快要成为PyTorch大师了?今天我们要做一件特别酷的事情——构建一个端到端的对话系统!想象一下,你可以跟你的AI助手像朋友一样聊天,它不仅能听懂你说的话,还能用自然的语音回复你。这就像是科幻电影里的场景,但现在我们要用PyTorch把它变成现实!
在这个激动人心的旅程中,我们将把三个强大的技术组件像搭积木一样组合起来:ASR(自动语音识别)、LLM(大语言模型)和TTS(文本转语音)。就像一个完美的三人组合,每个成员都有自己的特长,但只有团结协作才能创造奇迹!
🏗️ 第一部分:系统架构设计与核心组件集成
1. 端到端对话系统架构概览
让我们先从整体架构开始理解。一个完整的端到端对话系统就像一个高效的信息传递链条,每个环节都至关重要。
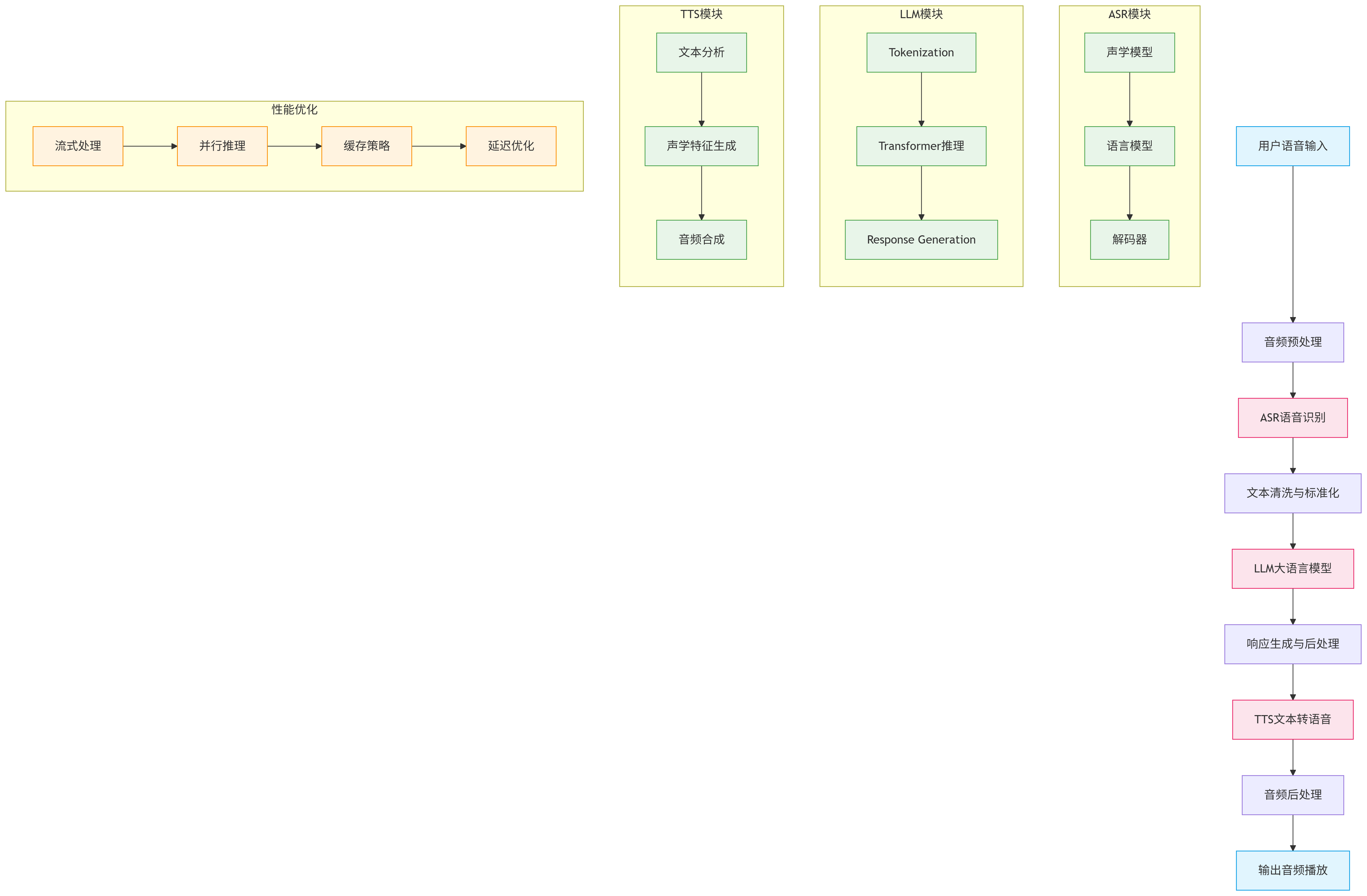
2. 核心技术组件对比分析
在构建我们的语音助手之前,让我们先来看看各个组件的技术选择。这就像选择队友一样,每个选择都会影响最终的表现!
端到端对话系统核心组件技术对比
ASR(自动语音识别)技术选择
| 技术方案 | 优势 | 劣势 | 适用场景 | 延迟 | 准确率 |
|---|---|---|---|---|---|
| Whisper | 多语言支持强、开源免费、准确率高 | 模型较大、推理速度一般 | 通用场景、多语言应用 | 中等 | 95%+ |
| Wav2Vec2 | 轻量级、推理速度快、可自定义训练 | 英语为主、需要微调 | 实时应用、特定领域 | 低 | 90%+ |
| DeepSpeech | 完全开源、可定制性强 | 准确率相对较低、维护成本高 | 离线部署、隐私要求高 | 低 | 85%+ |
| 云端API | 准确率极高、免维护 | 网络依赖、费用成本、隐私风险 | 原型开发、非敏感数据 | 高 | 98%+ |
LLM(大语言模型)技术选择
| 技术方案 | 优势 | 劣势 | 适用场景 | 内存占用 | 推理速度 |
|---|---|---|---|---|---|
| LLaMA2-7B | 开源、性能均衡、社区活跃 | 需要大量显存、推理成本高 | 通用对话、知识问答 | 14GB+ | 中等 |
| ChatGLM3-6B | 中文优化、对话能力强 | 英文能力相对弱、模型较新 | 中文对话、客服系统 | 12GB+ | 中等 |
| Phi-3-Mini | 模型小、推理快、效果好 | 知识有限、复杂任务能力弱 | 边缘设备、快速响应 | 4GB+ | 快 |
| GPT-3.5-turbo | 能力强、API稳定 | 费用成本、网络依赖 | 商业应用、复杂任务 | 0(云端) | 快 |
TTS(文本转语音)技术选择
| 技术方案 | 优势 | 劣势 | 适用场景 | 音质 | 合成速度 |
|---|---|---|---|---|---|
| VITS | 音质自然、可训练自定义音色 | 模型复杂、训练难度高 | 高质量语音合成 | 优秀 | 中等 |
| FastSpeech2 | 推理速度快、音质稳定、可控性强 | 需要预训练模型、调参复杂 | 实时应用、批量合成 | 良好 | 快 |
| Tacotron2 | 端到端训练、音质好 | 推理速度慢、训练不稳定 | 离线应用、高质量要求 | 优秀 | 慢 |
| gTTS | 简单易用、免费、多语言 | 网络依赖、音质一般 | 原型开发、简单应用 | 一般 | 快 |
综合性能对比
| 指标 | 实时性要求 | 质量要求 | 资源限制 | 推荐方案 |
|---|---|---|---|---|
| 原型开发 | 中等 | 中等 | 有限 | Whisper + Phi-3-Mini + gTTS |
| 生产环境 | 高 | 高 | 充足 | Wav2Vec2 + LLaMA2-7B + VITS |
| 边缘设备 | 高 | 中等 | 严格 | 轻量级ASR + Phi-3-Mini + FastSpeech2 |
| 云端服务 | 中等 | 高 | 充足 | 云端API + GPT-3.5 + 高质量TTS |
3. 系统环境配置与依赖管理
在开始构建我们的语音助手之前,让我们先把"工具箱"准备好。就像做菜之前要准备好所有食材一样,我们需要安装所有必要的Python库。
# 端到端对话系统环境配置脚本
# requirements.txt 文件内容"""
torch>=2.0.0
torchaudio>=2.0.0
transformers>=4.30.0
whisper-openai>=20231117
soundfile>=0.12.1
librosa>=0.10.0
numpy>=1.24.0
scipy>=1.10.0
pyaudio>=0.2.11
pydub>=0.25.1
gtts>=2.3.0
pygame>=2.5.0
accelerate>=0.20.0
datasets>=2.12.0
sentencepiece>=0.1.99
tokenizers>=0.13.0
gradio>=3.35.0
fastapi>=0.100.0
uvicorn>=0.22.0
websockets>=11.0
asyncio-timeout>=4.0
"""# 安装脚本 install_dependencies.py
import subprocess
import sys
import platformdef install_requirements():"""安装项目依赖"""print("🚀 开始安装端到端对话系统依赖...")# 基础依赖requirements = ["torch>=2.0.0","torchaudio>=2.0.0", "transformers>=4.30.0","openai-whisper","soundfile>=0.12.1","librosa>=0.10.0","numpy>=1.24.0","scipy>=1.10.0","pydub>=0.25.1","gtts>=2.3.0","pygame>=2.5.0","accelerate>=0.20.0","gradio>=3.35.0","fastapi>=0.100.0","uvicorn>=0.22.0","websockets>=11.0"]# 根据操作系统安装PyAudioif platform.system() == "Windows":requirements.append("pyaudio")elif platform.system() == "Darwin": # macOSprint("⚠️ macOS用户请先安装portaudio: brew install portaudio")requirements.append("pyaudio")else: # Linuxprint("⚠️ Linux用户请先安装: sudo apt-get install portaudio19-dev")requirements.append("pyaudio")for requirement in requirements:try:print(f"📦 正在安装 {requirement}...")subprocess.check_call([sys.executable, "-m", "pip", "install", requirement])print(f"✅ {requirement} 安装成功")except subprocess.CalledProcessError as e:print(f"❌ {requirement} 安装失败: {e}")continueprint("🎉 依赖安装完成!")def check_gpu_availability():"""检查GPU可用性"""import torchprint("\n🔍 检查系统配置...")print(f"Python版本: {sys.version}")print(f"PyTorch版本: {torch.__version__}")if torch.cuda.is_available():print("🎮 CUDA可用!")print(f"GPU数量: {torch.cuda.device_count()}")for i in range(torch.cuda.device_count()):print(f"GPU {i}: {torch.cuda.get_device_name(i)}")print(f"显存容量: {torch.cuda.get_device_properties(i).total_memory / 1024**3:.1f} GB")elif torch.backends.mps.is_available():print("🍎 MPS (Apple Silicon) 可用!")else:print("💻 使用CPU模式")# 检查音频设备try:import pyaudioaudio = pyaudio.PyAudio()print(f"\n🎤 音频设备数量: {audio.get_device_count()}")# 列出输入设备print("输入设备:")for i in range(audio.get_device_count()):device_info = audio.get_device_info_by_index(i)if device_info['maxInputChannels'] > 0:print(f" {i}: {device_info['name']}")# 列出输出设备print("输出设备:")for i in range(audio.get_device_count()):device_info = audio.get_device_info_by_index(i)if device_info['maxOutputChannels'] > 0:print(f" {i}: {device_info['name']}")audio.terminate()except ImportError:print("⚠️ PyAudio未安装,无法检查音频设备")def setup_model_cache():"""设置模型缓存目录"""import osfrom pathlib import Path# 创建模型缓存目录cache_dirs = ["models/asr","models/llm", "models/tts","cache/audio","logs"]for cache_dir in cache_dirs:Path(cache_dir).mkdir(parents=True, exist_ok=True)print(f"📁 创建目录: {cache_dir}")# 设置环境变量os.environ["TRANSFORMERS_CACHE"] = "./models"os.environ["HF_HOME"] = "./models"print("✅ 模型缓存目录配置完成")if __name__ == "__main__":print("🎯 端到端对话系统环境配置")print("=" * 50)# 安装依赖install_requirements()# 检查系统配置check_gpu_availability()# 设置缓存目录setup_model_cache()print("\n🎉 环境配置完成!现在可以开始构建对话系统了!")
4. ASR(自动语音识别)模块实现
现在让我们来实现ASR模块,这是我们语音助手的"耳朵"!就像人类的听觉系统一样,它需要准确地将声音信号转换为文字。我们使用OpenAI的Whisper模型,它就像一个多语言的翻译专家,能够理解各种口音和语言。
# asr_module.py - 自动语音识别模块
import torch
import whisper
import numpy as np
import librosa
import soundfile as sf
import pyaudio
import wave
import threading
import time
import logging
from typing import Optional, Callable, Dict, Any
from pathlib import Path
import queue
import io# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)class ASREngine:"""自动语音识别引擎支持实时语音识别和批量音频文件处理"""def __init__(self,model_name: str = "base",device: str = "auto",language: str = "auto",cache_dir: str = "./models/asr"):"""初始化ASR引擎Args:model_name: Whisper模型大小 ("tiny", "base", "small", "medium", "large")device: 设备类型 ("auto", "cpu", "cuda", "mps")language: 语言代码 ("auto", "zh", "en", 等)cache_dir: 模型缓存目录"""self.model_name = model_nameself.language = languageself.cache_dir = Path(cache_dir)self.cache_dir.mkdir(parents=True, exist_ok=True)# 自动检测设备if device == "auto":if torch.cuda.is_available():self.device = "cuda"elif torch.backends.mps.is_available():self.device = "mps"else:self.device = "cpu"else:self.device = devicelogger.info(f"🎤 初始化ASR引擎: {model_name} on {self.device}")# 加载Whisper模型self._load_model()# 音频配置self.sample_rate = 16000self.chunk_size = 1024self.audio_format = pyaudio.paInt16self.channels = 1# 实时录音相关self.audio_queue = queue.Queue()self.is_recording = Falseself.audio_buffer = []def _load_model(self):"""加载Whisper模型"""try:logger.info(f"📥 加载Whisper模型: {self.model_name}")# 下载并加载模型self.model = whisper.load_model(self.model_name,device=self.device,download_root=str(self.cache_dir))logger.info("✅ Whisper模型加载成功")# 模型信息model_info = {"tiny": {"params": "39M", "memory": "~1GB", "speed": "~32x"},"base": {"params": "74M", "memory": "~1GB", "speed": "~16x"},"small": {"params": "244M", "memory": "~2GB", "speed": "~6x"},"medium": {"params": "769M", "memory": "~5GB", "speed": "~2x"},"large": {"params": "1550M", "memory": "~10GB", "speed": "~1x"},}if self.model_name in model_info:info = model_info[self.model_name]logger.info(f"📊 模型参数: {info['params']}, "f"显存占用: {info['memory']}, "f"相对速度: {info['speed']}")except Exception as e:logger.error(f"❌ 模型加载失败: {e}")raisedef transcribe_file(self,audio_path: str,language: Optional[str] = None,task: str = "transcribe",**kwargs) -> Dict[str, Any]:"""转录音频文件Args:audio_path: 音频文件路径language: 语言代码,None则自动检测task: 任务类型 ("transcribe" 或 "translate")**kwargs: 其他Whisper参数Returns:转录结果字典"""try:logger.info(f"🎵 开始转录文件: {audio_path}")# 设置语言lang = language or self.languageif lang == "auto":lang = None# 执行转录start_time = time.time()result = self.model.transcribe(audio_path,language=lang,task=task,**kwargs)end_time = time.time()# 处理结果transcription = {"text": result["text"].strip(),"language": result["language"],"segments": result["segments"],"duration": end_time - start_time,"audio_duration": result.get("duration", 0),"confidence": self._calculate_confidence(result["segments"])}logger.info(f"✅ 转录完成,耗时: {transcription['duration']:.2f}s")logger.info(f"📝 识别文本: {transcription['text'][:100]}...")return transcriptionexcept Exception as e:logger.error(f"❌ 转录失败: {e}")return {"text": "", "error": str(e)}def transcribe_audio_data(self,audio_data: np.ndarray,sample_rate: int = 16000,language: Optional[str] = None) -> Dict[str, Any]:"""转录音频数据Args:audio_data: 音频数据数组sample_rate: 采样率language: 语言代码Returns:转录结果字典"""try:# 预处理音频数据if sample_rate != 16000:audio_data = librosa.resample(audio_data, orig_sr=sample_rate, target_sr=16000)# 归一化音频audio_data = audio_data.astype(np.float32)if audio_data.max() > 1.0:audio_data = audio_data / np.max(np.abs(audio_data))# 设置语言lang = language or self.languageif lang == "auto":lang = None# 执行转录start_time = time.time()result = self.model.transcribe(audio_data,language=lang)end_time = time.time()# 处理结果transcription = {"text": result["text"].strip(),"language": result["language"],"segments": result["segments"],"duration": end_time - start_time,"confidence": self._calculate_confidence(result["segments"])}return transcriptionexcept Exception as e:logger.error(f"❌ 音频数据转录失败: {e}")return {"text": "", "error": str(e)}def start_real_time_recording(self,callback: Callable[[str], None],silence_threshold: float = 0.01,silence_duration: float = 2.0):"""开始实时录音识别Args:callback: 识别结果回调函数silence_threshold: 静音阈值silence_duration: 静音持续时间(秒)"""if self.is_recording:logger.warning("⚠️ 已经在进行实时录音")returnself.is_recording = Trueself.callback = callbackself.silence_threshold = silence_thresholdself.silence_duration = silence_durationlogger.info("🎙️ 开始实时录音识别...")# 启动录音线程self.recording_thread = threading.Thread(target=self._recording_worker,daemon=True)self.recording_thread.start()# 启动处理线程self.processing_thread = threading.Thread(target=self._processing_worker,daemon=True)self.processing_thread.start()def stop_real_time_recording(self):"""停止实时录音识别"""if not self.is_recording:returnlogger.info("🛑 停止实时录音识别...")self.is_recording = False# 等待线程结束if hasattr(self, 'recording_thread'):self.recording_thread.join(timeout=2)if hasattr(self, 'processing_thread'):self.processing_thread.join(timeout=2)def _recording_worker(self):"""录音工作线程"""try:# 初始化PyAudioaudio = pyaudio.PyAudio()# 打开音频流stream = audio.open(format=self.audio_format,channels=self.channels,rate=self.sample_rate,input=True,frames_per_buffer=self.chunk_size)logger.info("🎤 开始录音...")silence_start = Noneaudio_buffer = []while self.is_recording:try:# 读取音频数据data = stream.read(self.chunk_size, exception_on_overflow=False)audio_array = np.frombuffer(data, dtype=np.int16).astype(np.float32) / 32768.0# 计算音量volume = np.sqrt(np.mean(audio_array**2))if volume > self.silence_threshold:# 有声音,重置静音计时silence_start = Noneaudio_buffer.extend(audio_array)else:# 静音if silence_start is None:silence_start = time.time()elif time.time() - silence_start > self.silence_duration:# 静音时间足够长,处理缓冲区if len(audio_buffer) > self.sample_rate * 0.5: # 至少0.5秒self.audio_queue.put(np.array(audio_buffer))audio_buffer = []silence_start = Noneexcept Exception as e:logger.error(f"❌ 录音错误: {e}")break# 清理资源stream.stop_stream()stream.close()audio.terminate()# 处理剩余音频if len(audio_buffer) > self.sample_rate * 0.5:self.audio_queue.put(np.array(audio_buffer))except Exception as e:logger.error(f"❌ 录音线程错误: {e}")def _processing_worker(self):"""音频处理工作线程"""while self.is_recording or not self.audio_queue.empty():try:# 获取音频数据audio_data = self.audio_queue.get(timeout=1)# 转录音频result = self.transcribe_audio_data(audio_data)# 调用回调函数if result["text"] and self.callback:self.callback(result["text"])except queue.Empty:continueexcept Exception as e:logger.error(f"❌ 处理线程错误: {e}")def _calculate_confidence(self, segments) -> float:"""计算整体置信度"""if not segments:return 0.0# 简单的置信度计算(基于段落平均值)total_confidence = 0.0total_duration = 0.0for segment in segments:duration = segment["end"] - segment["start"]# Whisper没有直接的置信度,我们用其他指标估算confidence = min(1.0, len(segment["text"].strip()) / max(1, duration * 10))total_confidence += confidence * durationtotal_duration += durationreturn total_confidence / max(1, total_duration)def get_model_info(self) -> Dict[str, Any]:"""获取模型信息"""return {"model_name": self.model_name,"device": self.device,"language": self.language,"sample_rate": self.sample_rate,"cache_dir": str(self.cache_dir)}# 使用示例和测试代码
if __name__ == "__main__":print("🎯 ASR模块测试")print("=" * 50)# 初始化ASR引擎asr = ASREngine(model_name="base", device="auto")# 显示模型信息info = asr.get_model_info()print("📊 ASR引擎信息:")for key, value in info.items():print(f" {key}: {value}")# 测试文件转录(如果有测试音频文件)test_audio_path = "test_audio.wav"if Path(test_audio_path).exists():print(f"\n🎵 测试文件转录: {test_audio_path}")result = asr.transcribe_file(test_audio_path)print(f"识别结果: {result['text']}")print(f"语言: {result['language']}")print(f"置信度: {result['confidence']:.2f}")else:print(f"\n⚠️ 测试音频文件不存在: {test_audio_path}")# 实时录音测试print("\n🎙️ 实时录音测试")print("按 Enter 开始录音,再次按 Enter 停止...")def on_recognition(text):print(f"🗣️ 识别到: {text}")input("按 Enter 开始...")asr.start_real_time_recording(on_recognition)input("按 Enter 停止...")asr.stop_real_time_recording()print("🎉 ASR模块测试完成!")
5. TTS(文本转语音)模块实现
接下来我们来实现TTS模块,这是我们语音助手的"嘴巴"!就像一个专业的播音员,它需要将文字转换成自然流畅的语音。我们提供多种TTS引擎选择,从简单的在线服务到复杂的本地合成,应有尽有。
# tts_module.py - 文本转语音模块
import torch
import numpy as np
import soundfile as sf
import pygame
import io
import tempfile
import logging
import time
import threading
import queue
from typing import Optional, Dict, Any, Union, List
from pathlib import Path
from abc import ABC, abstractmethod# 导入不同的TTS引擎
try:from gtts import gTTSGTTS_AVAILABLE = True
except ImportError:GTTS_AVAILABLE = Falseprint("⚠️ gTTS不可用,请安装: pip install gtts")try:import pyttsx3PYTTSX3_AVAILABLE = True
except ImportError:PYTTSX3_AVAILABLE = Falseprint("⚠️ pyttsx3不可用,请安装: pip install pyttsx3")# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)class TTSEngine(ABC):"""TTS引擎抽象基类"""@abstractmethoddef synthesize(self, text: str, **kwargs) -> bytes:"""合成语音,返回音频字节数据"""pass@abstractmethoddef get_engine_info(self) -> Dict[str, Any]:"""获取引擎信息"""passclass GTTSEngine(TTSEngine):"""Google Text-to-Speech引擎"""def __init__(self, language: str = "zh-cn", slow: bool = False):"""初始化gTTS引擎Args:language: 语言代码 (zh-cn, en, ja, ko, 等)slow: 是否慢速播放"""if not GTTS_AVAILABLE:raise ImportError("gTTS不可用,请安装: pip install gtts")self.language = languageself.slow = slowlogger.info(f"🌐 初始化gTTS引擎: {language}")def synthesize(self, text: str, **kwargs) -> bytes:"""合成语音Args:text: 要合成的文本**kwargs: 其他参数Returns:音频字节数据"""try:# 创建gTTS对象tts = gTTS(text=text,lang=self.language,slow=self.slow)# 保存到内存audio_buffer = io.BytesIO()tts.write_to_fp(audio_buffer)audio_buffer.seek(0)return audio_buffer.read()except Exception as e:logger.error(f"❌ gTTS合成失败: {e}")raisedef get_engine_info(self) -> Dict[str, Any]:"""获取引擎信息"""return {"engine": "gTTS","language": self.language,"slow": self.slow,"online": True,"quality": "good"}class Pyttsx3Engine(TTSEngine):"""pyttsx3本地TTS引擎"""def __init__(self, voice_id: Optional[str] = None, rate: int = 200, volume: float = 0.9):"""初始化pyttsx3引擎Args:voice_id: 语音ID,None则使用默认rate: 语速 (words per minute)volume: 音量 (0.0-1.0)"""if not PYTTSX3_AVAILABLE:raise ImportError("pyttsx3不可用,请安装: pip install pyttsx3")self.engine = pyttsx3.init()self.rate = rateself.volume = volume# 设置语音参数self.engine.setProperty('rate', rate)self.engine.setProperty('volume', volume)# 设置语音voices = self.engine.getProperty('voices')if voice_id:self.engine.setProperty('voice', voice_id)elif voices:# 尝试选择中文语音for voice in voices:if 'chinese' in voice.name.lower() or 'zh' in voice.id.lower():self.engine.setProperty('voice', voice.id)breaklogger.info(f"🎙️ 初始化pyttsx3引擎: rate={rate}, volume={volume}")def synthesize(self, text: str, **kwargs) -> bytes:"""合成语音Args:text: 要合成的文本**kwargs: 其他参数Returns:音频字节数据"""try:# 创建临时文件with tempfile.NamedTemporaryFile(suffix='.wav', delete=False) as temp_file:temp_path = temp_file.name# 保存音频到临时文件self.engine.save_to_file(text, temp_path)self.engine.runAndWait()# 读取音频数据with open(temp_path, 'rb') as f:audio_data = f.read()# 删除临时文件Path(temp_path).unlink(missing_ok=True)return audio_dataexcept Exception as e:logger.error(f"❌ pyttsx3合成失败: {e}")raisedef get_available_voices(self) -> List[Dict[str, str]]:"""获取可用语音列表"""voices = self.engine.getProperty('voices')return [{"id": voice.id,"name": voice.name,"languages": voice.languages}for voice in voices]def get_engine_info(self) -> Dict[str, Any]:"""获取引擎信息"""return {"engine": "pyttsx3","rate": self.rate,"volume": self.volume,"online": False,"quality": "medium","voices": len(self.engine.getProperty('voices'))}class TTSManager:"""TTS管理器,统一管理多个TTS引擎"""def __init__(self, default_engine: str = "auto"):"""初始化TTS管理器Args:default_engine: 默认引擎 ("auto", "gtts", "pyttsx3")"""self.engines = {}self.default_engine = default_engineself.current_engine = None# 初始化音频播放pygame.mixer.init()# 自动选择可用引擎self._initialize_engines()# 播放相关self.is_playing = Falseself.play_queue = queue.Queue()self.play_thread = Nonelogger.info(f"🎵 TTS管理器初始化完成,默认引擎: {self.current_engine}")def _initialize_engines(self):"""初始化可用的TTS引擎"""# 尝试初始化gTTSif GTTS_AVAILABLE:try:self.engines["gtts"] = GTTSEngine()logger.info("✅ gTTS引擎可用")except Exception as e:logger.warning(f"⚠️ gTTS引擎初始化失败: {e}")# 尝试初始化pyttsx3if PYTTSX3_AVAILABLE:try:self.engines["pyttsx3"] = Pyttsx3Engine()logger.info("✅ pyttsx3引擎可用")except Exception as e:logger.warning(f"⚠️ pyttsx3引擎初始化失败: {e}")# 选择默认引擎if self.default_engine == "auto":if "gtts" in self.engines:self.current_engine = "gtts"elif "pyttsx3" in self.engines:self.current_engine = "pyttsx3"else:raise RuntimeError("没有可用的TTS引擎")else:if self.default_engine in self.engines:self.current_engine = self.default_engineelse:raise RuntimeError(f"指定的TTS引擎不可用: {self.default_engine}")def set_engine(self, engine_name: str):"""设置当前使用的TTS引擎Args:engine_name: 引擎名称"""if engine_name not in self.engines:raise ValueError(f"不支持的TTS引擎: {engine_name}")self.current_engine = engine_namelogger.info(f"🔄 切换到TTS引擎: {engine_name}")def synthesize(self, text: str, engine: Optional[str] = None, **kwargs) -> bytes:"""合成语音Args:text: 要合成的文本engine: 指定引擎,None则使用当前引擎**kwargs: 其他参数Returns:音频字节数据"""if not text.strip():return b""engine_name = engine or self.current_engineif engine_name not in self.engines:raise ValueError(f"TTS引擎不可用: {engine_name}")start_time = time.time()logger.info(f"🔊 开始合成语音: {text[:50]}...")try:audio_data = self.engines[engine_name].synthesize(text, **kwargs)duration = time.time() - start_timelogger.info(f"✅ 语音合成完成,耗时: {duration:.2f}s, 大小: {len(audio_data)} bytes")return audio_dataexcept Exception as e:logger.error(f"❌ 语音合成失败: {e}")raisedef synthesize_to_file(self, text: str, output_path: str, engine: Optional[str] = None, **kwargs):"""合成语音并保存到文件Args:text: 要合成的文本output_path: 输出文件路径engine: 指定引擎**kwargs: 其他参数"""audio_data = self.synthesize(text, engine, **kwargs)with open(output_path, 'wb') as f:f.write(audio_data)logger.info(f"💾 语音文件已保存: {output_path}")def play_audio(self, audio_data: bytes, wait: bool = True):"""播放音频数据Args:audio_data: 音频字节数据wait: 是否等待播放完成"""try:# 创建临时文件with tempfile.NamedTemporaryFile(suffix='.mp3', delete=False) as temp_file:temp_file.write(audio_data)temp_path = temp_file.name# 播放音频pygame.mixer.music.load(temp_path)pygame.mixer.music.play()if wait:while pygame.mixer.music.get_busy():time.sleep(0.1)# 删除临时文件Path(temp_path).unlink(missing_ok=True)except Exception as e:logger.error(f"❌ 音频播放失败: {e}")def speak(self, text: str, engine: Optional[str] = None, wait: bool = True, **kwargs):"""直接朗读文本Args:text: 要朗读的文本engine: 指定引擎wait: 是否等待播放完成**kwargs: 其他参数"""if not text.strip():returntry:audio_data = self.synthesize(text, engine, **kwargs)self.play_audio(audio_data, wait)except Exception as e:logger.error(f"❌ 朗读失败: {e}")def start_async_player(self):"""启动异步播放器"""if self.play_thread and self.play_thread.is_alive():returnself.is_playing = Trueself.play_thread = threading.Thread(target=self._play_worker, daemon=True)self.play_thread.start()logger.info("🎵 异步播放器已启动")def stop_async_player(self):"""停止异步播放器"""self.is_playing = Falseif self.play_thread:self.play_thread.join(timeout=2)logger.info("🛑 异步播放器已停止")def speak_async(self, text: str, engine: Optional[str] = None, **kwargs):"""异步朗读文本Args:text: 要朗读的文本engine: 指定引擎**kwargs: 其他参数"""if not self.is_playing:self.start_async_player()self.play_queue.put((text, engine, kwargs))def _play_worker(self):"""播放工作线程"""while self.is_playing:try:text, engine, kwargs = self.play_queue.get(timeout=1)self.speak(text, engine, wait=True, **kwargs)except queue.Empty:continueexcept Exception as e:logger.error(f"❌ 异步播放错误: {e}")def get_available_engines(self) -> List[str]:"""获取可用引擎列表"""return list(self.engines.keys())def get_engine_info(self, engine_name: Optional[str] = None) -> Dict[str, Any]:"""获取引擎信息Args:engine_name: 引擎名称,None则获取当前引擎Returns:引擎信息字典"""engine = engine_name or self.current_engineif engine not in self.engines:return {}return self.engines[engine].get_engine_info()def get_all_engines_info(self) -> Dict[str, Dict[str, Any]]:"""获取所有引擎信息"""return {name: engine.get_engine_info() for name, engine in self.engines.items()}# 使用示例和测试代码
if __name__ == "__main__":print("🎯 TTS模块测试")print("=" * 50)# 初始化TTS管理器tts = TTSManager()# 显示可用引擎engines = tts.get_available_engines()print(f"📋 可用TTS引擎: {engines}")# 显示引擎信息all_info = tts.get_all_engines_info()for engine_name, info in all_info.items():print(f"\n🔧 {engine_name} 引擎信息:")for key, value in info.items():print(f" {key}: {value}")# 测试文本test_texts = ["你好,我是你的AI语音助手!","Hello, I am your AI voice assistant!","今天天气不错,适合出去走走。","The weather is nice today, perfect for a walk."]print(f"\n🎤 当前使用引擎: {tts.current_engine}")# 测试语音合成和播放for i, text in enumerate(test_texts):print(f"\n🔊 测试 {i+1}: {text}")try:# 合成语音audio_data = tts.synthesize(text)print(f"✅ 合成完成,音频大小: {len(audio_data)} bytes")# 播放语音print("🎵 正在播放...")tts.play_audio(audio_data, wait=True)# 保存到文件output_file = f"test_output_{i+1}.mp3"with open(output_file, 'wb') as f:f.write(audio_data)print(f"💾 已保存到: {output_file}")except Exception as e:print(f"❌ 测试失败: {e}")# 测试直接朗读print(f"\n🗣️ 测试直接朗读功能...")tts.speak("这是直接朗读测试。", wait=True)# 测试异步播放print(f"\n🎵 测试异步播放功能...")tts.start_async_player()for text in ["第一句话", "第二句话", "第三句话"]:tts.speak_async(text)time.sleep(0.5) # 稍微间隔一下# 等待播放完成time.sleep(5)tts.stop_async_player()print("🎉 TTS模块测试完成!")
6. LLM(大语言模型)模块实现
现在我们来实现对话系统的"大脑"——LLM模块!这个模块就像一个博学的朋友,能够理解你的话语并给出智慧的回复。我们将支持多种模型选择,从轻量级的边缘计算模型到强大的云端大模型。
# llm_module.py - 大语言模型模块
import torch
import json
import time
import logging
from typing import Dict, List, Any, Optional, Generator, Union, Callable
from pathlib import Path
from dataclasses import dataclass
from abc import ABC, abstractmethod
import threading
import queue# 导入transformers相关库
try:from transformers import (AutoTokenizer, AutoModelForCausalLM, GenerationConfig, TextIteratorStreamer)TRANSFORMERS_AVAILABLE = True
except ImportError:TRANSFORMERS_AVAILABLE = Falseprint("⚠️ transformers不可用,请安装: pip install transformers")# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)@dataclass
class ChatMessage:"""聊天消息数据类"""role: str # "user", "assistant", "system"content: strtimestamp: Optional[float] = Nonemetadata: Optional[Dict[str, Any]] = None@dataclass
class GenerationParams:"""生成参数配置"""max_length: int = 2048max_new_tokens: int = 512temperature: float = 0.7top_p: float = 0.9top_k: int = 50do_sample: bool = Truerepetition_penalty: float = 1.1pad_token_id: Optional[int] = Noneeos_token_id: Optional[int] = Noneclass LLMEngine(ABC):"""LLM引擎抽象基类"""@abstractmethoddef generate(self, messages: List[ChatMessage], **kwargs) -> str:"""生成回复"""pass@abstractmethoddef generate_stream(self, messages: List[ChatMessage], **kwargs) -> Generator[str, None, None]:"""流式生成回复"""pass@abstractmethoddef get_engine_info(self) -> Dict[str, Any]:"""获取引擎信息"""passclass TransformersEngine(LLMEngine):"""基于Transformers的本地LLM引擎"""def __init__(self,model_name: str = "microsoft/DialoGPT-medium",device: str = "auto",cache_dir: str = "./models/llm",load_in_8bit: bool = False,load_in_4bit: bool = False,**model_kwargs):"""初始化Transformers引擎Args:model_name: 模型名称或路径device: 设备类型cache_dir: 模型缓存目录load_in_8bit: 是否使用8bit量化load_in_4bit: 是否使用4bit量化**model_kwargs: 其他模型参数"""if not TRANSFORMERS_AVAILABLE:raise ImportError("transformers不可用,请安装相关依赖")self.model_name = model_nameself.cache_dir = Path(cache_dir)self.cache_dir.mkdir(parents=True, exist_ok=True)# 自动检测设备if device == "auto":if torch.cuda.is_available():self.device = "cuda"elif torch.backends.mps.is_available():self.device = "mps"else:self.device = "cpu"else:self.device = devicelogger.info(f"🧠 初始化LLM引擎: {model_name} on {self.device}")# 加载模型和分词器self._load_model(load_in_8bit, load_in_4bit, **model_kwargs)# 默认生成参数self.generation_params = GenerationParams()# 对话历史self.conversation_history = []self.max_history_length = 10def _load_model(self, load_in_8bit: bool, load_in_4bit: bool, **model_kwargs):"""加载模型和分词器"""try:logger.info("📥 加载分词器...")self.tokenizer = AutoTokenizer.from_pretrained(self.model_name,cache_dir=str(self.cache_dir),trust_remote_code=True)# 设置特殊tokenif self.tokenizer.pad_token is None:self.tokenizer.pad_token = self.tokenizer.eos_tokenlogger.info("📥 加载模型...")# 模型加载参数load_kwargs = {"cache_dir": str(self.cache_dir),"trust_remote_code": True,"torch_dtype": torch.float16 if self.device != "cpu" else torch.float32,**model_kwargs}# 量化配置if load_in_8bit:load_kwargs["load_in_8bit"] = Truelogger.info("🔢 启用8bit量化")elif load_in_4bit:load_kwargs["load_in_4bit"] = Truelogger.info("🔢 启用4bit量化")self.model = AutoModelForCausalLM.from_pretrained(self.model_name,**load_kwargs)# 移动到指定设备if not (load_in_8bit or load_in_4bit):self.model = self.model.to(self.device)# 设置为评估模式self.model.eval()# 更新生成参数self.generation_params.pad_token_id = self.tokenizer.pad_token_idself.generation_params.eos_token_id = self.tokenizer.eos_token_idlogger.info("✅ 模型加载成功")# 显示模型信息param_count = sum(p.numel() for p in self.model.parameters())logger.info(f"📊 模型参数量: {param_count:,}")except Exception as e:logger.error(f"❌ 模型加载失败: {e}")raisedef _format_messages(self, messages: List[ChatMessage]) -> str:"""格式化消息为模型输入"""# 简单的对话格式化,可根据具体模型调整formatted_parts = []for message in messages:if message.role == "system":formatted_parts.append(f"System: {message.content}")elif message.role == "user":formatted_parts.append(f"User: {message.content}")elif message.role == "assistant":formatted_parts.append(f"Assistant: {message.content}")# 添加助手回复的开始formatted_parts.append("Assistant:")return "\n".join(formatted_parts)def generate(self,messages: List[ChatMessage],generation_params: Optional[GenerationParams] = None,**kwargs) -> str:"""生成回复Args:messages: 消息列表generation_params: 生成参数**kwargs: 其他参数Returns:生成的回复文本"""try:# 使用提供的参数或默认参数params = generation_params or self.generation_params# 格式化输入input_text = self._format_messages(messages)# 编码输入inputs = self.tokenizer.encode(input_text,return_tensors="pt",padding=True,truncation=True,max_length=params.max_length - params.max_new_tokens)if self.device != "cpu":inputs = inputs.to(self.device)# 生成参数generation_config = GenerationConfig(max_new_tokens=params.max_new_tokens,temperature=params.temperature,top_p=params.top_p,top_k=params.top_k,do_sample=params.do_sample,repetition_penalty=params.repetition_penalty,pad_token_id=params.pad_token_id,eos_token_id=params.eos_token_id,)start_time = time.time()# 生成文本with torch.no_grad():outputs = self.model.generate(inputs,generation_config=generation_config,**kwargs)# 解码输出generated_text = self.tokenizer.decode(outputs[0][inputs.shape[1]:], # 只取新生成的部分skip_special_tokens=True).strip()generation_time = time.time() - start_timetokens_generated = outputs.shape[1] - inputs.shape[1]logger.info(f"✅ 生成完成,耗时: {generation_time:.2f}s, "f"生成tokens: {tokens_generated}, "f"速度: {tokens_generated/generation_time:.1f} tokens/s")return generated_textexcept Exception as e:logger.error(f"❌ 生成失败: {e}")return "抱歉,我现在无法回答这个问题。"def generate_stream(self,messages: List[ChatMessage],generation_params: Optional[GenerationParams] = None,**kwargs) -> Generator[str, None, None]:"""流式生成回复Args:messages: 消息列表generation_params: 生成参数**kwargs: 其他参数Yields:生成的文本片段"""try:# 使用提供的参数或默认参数params = generation_params or self.generation_params# 格式化输入input_text = self._format_messages(messages)# 编码输入inputs = self.tokenizer.encode(input_text,return_tensors="pt",padding=True,truncation=True,max_length=params.max_length - params.max_new_tokens)if self.device != "cpu":inputs = inputs.to(self.device)# 创建流式输出器streamer = TextIteratorStreamer(self.tokenizer,skip_prompt=True,skip_special_tokens=True)# 生成参数generation_config = GenerationConfig(max_new_tokens=params.max_new_tokens,temperature=params.temperature,top_p=params.top_p,top_k=params.top_k,do_sample=params.do_sample,repetition_penalty=params.repetition_penalty,pad_token_id=params.pad_token_id,eos_token_id=params.eos_token_id,)# 在后台线程中生成generation_kwargs = {"input_ids": inputs,"generation_config": generation_config,"streamer": streamer,**kwargs}thread = threading.Thread(target=self.model.generate,kwargs=generation_kwargs)thread.start()# 流式输出for text in streamer:yield textthread.join()except Exception as e:logger.error(f"❌ 流式生成失败: {e}")yield "抱歉,我现在无法回答这个问题。"def add_to_history(self, message: ChatMessage):"""添加消息到历史记录"""message.timestamp = time.time()self.conversation_history.append(message)# 保持历史长度限制if len(self.conversation_history) > self.max_history_length * 2:self.conversation_history = self.conversation_history[-self.max_history_length * 2:]def get_conversation_context(self, include_system: bool = True) -> List[ChatMessage]:"""获取对话上下文"""if include_system:return self.conversation_history.copy()else:return [msg for msg in self.conversation_history if msg.role != "system"]def clear_history(self):"""清空对话历史"""self.conversation_history.clear()logger.info("🗑️ 对话历史已清空")def set_generation_params(self, **kwargs):"""设置生成参数"""for key, value in kwargs.items():if hasattr(self.generation_params, key):setattr(self.generation_params, key, value)logger.info(f"🔧 更新生成参数: {key} = {value}")def get_engine_info(self) -> Dict[str, Any]:"""获取引擎信息"""try:param_count = sum(p.numel() for p in self.model.parameters())model_size_mb = sum(p.numel() * p.element_size() for p in self.model.parameters()) / (1024 * 1024)except:param_count = 0model_size_mb = 0return {"engine": "transformers","model_name": self.model_name,"device": self.device,"parameters": param_count,"model_size_mb": model_size_mb,"history_length": len(self.conversation_history),"max_history": self.max_history_length,"generation_params": self.generation_params.__dict__}class LLMManager:"""LLM管理器"""def __init__(self, default_engine: str = "transformers"):"""初始化LLM管理器Args:default_engine: 默认引擎名称"""self.engines = {}self.current_engine = Noneself.default_engine = default_engine# 系统提示self.system_prompt = ("你是一个友善、有帮助的AI语音助手。请用简洁、自然的语言回答用户的问题。""回答要准确、有用,语气要温和亲切。")logger.info("🧠 LLM管理器初始化完成")def add_engine(self, name: str, engine: LLMEngine):"""添加LLM引擎Args:name: 引擎名称engine: 引擎实例"""self.engines[name] = engineif self.current_engine is None or name == self.default_engine:self.current_engine = namelogger.info(f"✅ 添加LLM引擎: {name}")def set_engine(self, engine_name: str):"""设置当前使用的引擎"""if engine_name not in self.engines:raise ValueError(f"引擎不存在: {engine_name}")self.current_engine = engine_namelogger.info(f"🔄 切换到LLM引擎: {engine_name}")def set_system_prompt(self, prompt: str):"""设置系统提示"""self.system_prompt = promptlogger.info("📝 系统提示已更新")def chat(self,user_input: str,engine: Optional[str] = None,stream: bool = False,**kwargs) -> Union[str, Generator[str, None, None]]:"""与AI对话Args:user_input: 用户输入engine: 指定引擎stream: 是否流式输出**kwargs: 其他参数Returns:AI回复或流式生成器"""engine_name = engine or self.current_engineif engine_name not in self.engines:raise ValueError(f"引擎不可用: {engine_name}")llm_engine = self.engines[engine_name]# 构建消息列表messages = []# 添加系统提示if self.system_prompt:messages.append(ChatMessage(role="system", content=self.system_prompt))# 添加历史对话if hasattr(llm_engine, 'get_conversation_context'):context = llm_engine.get_conversation_context(include_system=False)messages.extend(context)# 添加当前用户输入user_message = ChatMessage(role="user", content=user_input)messages.append(user_message)# 添加到历史if hasattr(llm_engine, 'add_to_history'):llm_engine.add_to_history(user_message)# 生成回复if stream:return self._chat_stream(llm_engine, messages, **kwargs)else:response = llm_engine.generate(messages, **kwargs)# 添加回复到历史if hasattr(llm_engine, 'add_to_history'):assistant_message = ChatMessage(role="assistant", content=response)llm_engine.add_to_history(assistant_message)return responsedef _chat_stream(self, llm_engine: LLMEngine, messages: List[ChatMessage], **kwargs):"""流式对话生成器"""full_response = ""for chunk in llm_engine.generate_stream(messages, **kwargs):full_response += chunkyield chunk# 添加完整回复到历史if hasattr(llm_engine, 'add_to_history') and full_response:assistant_message = ChatMessage(role="assistant", content=full_response)llm_engine.add_to_history(assistant_message)def clear_history(self, engine: Optional[str] = None):"""清空对话历史"""engine_name = engine or self.current_engineif engine_name in self.engines:llm_engine = self.engines[engine_name]if hasattr(llm_engine, 'clear_history'):llm_engine.clear_history()def get_available_engines(self) -> List[str]:"""获取可用引擎列表"""return list(self.engines.keys())def get_engine_info(self, engine: Optional[str] = None) -> Dict[str, Any]:"""获取引擎信息"""engine_name = engine or self.current_engineif engine_name in self.engines:return self.engines[engine_name].get_engine_info()return {}def get_all_engines_info(self) -> Dict[str, Dict[str, Any]]:"""获取所有引擎信息"""return {name: engine.get_engine_info()for name, engine in self.engines.items()}# 使用示例和测试代码
if __name__ == "__main__":print("🎯 LLM模块测试")print("=" * 50)try:# 初始化LLM管理器llm_manager = LLMManager()# 添加transformers引擎(使用轻量级模型进行测试)if TRANSFORMERS_AVAILABLE:print("📥 加载轻量级模型进行测试...")# 使用GPT-2作为测试模型(较小,下载快)engine = TransformersEngine(model_name="gpt2",device="auto")llm_manager.add_engine("gpt2", engine)# 显示引擎信息info = llm_manager.get_engine_info()print("\n📊 引擎信息:")for key, value in info.items():print(f" {key}: {value}")# 测试对话test_inputs = ["你好!","今天天气怎么样?","请介绍一下人工智能。","谢谢你的帮助!"]print(f"\n💬 开始对话测试...")for i, user_input in enumerate(test_inputs):print(f"\n用户: {user_input}")try:# 普通对话response = llm_manager.chat(user_input)print(f"助手: {response}")# 流式对话测试(仅测试第一个)if i == 0:print("\n🌊 流式输出测试:")print("助手: ", end="", flush=True)for chunk in llm_manager.chat(user_input, stream=True):print(chunk, end="", flush=True)print() # 换行except Exception as e:print(f"❌ 对话失败: {e}")# 显示对话历史print(f"\n📚 对话历史:")current_engine = llm_manager.engines[llm_manager.current_engine]if hasattr(current_engine, 'conversation_history'):for msg in current_engine.conversation_history[-4:]: # 显示最后4条print(f" {msg.role}: {msg.content[:50]}...")except Exception as e:print(f"❌ 模块测试失败: {e}")print("💡 提示:请确保安装了transformers库和相关依赖")print("\n🎉 LLM模块测试完成!")
7. 端到端对话系统集成框架
最激动人心的时刻到了!现在我们要把ASR、LLM、TTS三个模块像搭积木一样组装成一个完整的端到端对话系统。这就像是组装一个高科技机器人,每个部件都有自己的专长,但只有完美协作才能创造奇迹!
# dialog_system.py - 端到端对话系统集成框架
import asyncio
import time
import threading
import queue
import json
import logging
from typing import Dict, List, Any, Optional, Callable, Union
from dataclasses import dataclass, asdict
from pathlib import Path
from datetime import datetime
import numpy as np# 导入我们的模块
from asr_module import ASREngine
from llm_module import LLMManager, ChatMessage
from tts_module import TTSManager# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)@dataclass
class DialogTurn:"""对话轮次数据"""turn_id: struser_input: struser_audio_path: Optional[str] = Noneasr_result: Optional[Dict[str, Any]] = Nonellm_response: Optional[str] = Nonetts_audio_path: Optional[str] = Nonetimestamps: Optional[Dict[str, float]] = Nonelatencies: Optional[Dict[str, float]] = Nonemetadata: Optional[Dict[str, Any]] = None@dataclass
class SystemConfig:"""系统配置"""# ASR配置asr_model: str = "base"asr_language: str = "auto"# LLM配置llm_model: str = "gpt2"llm_max_tokens: int = 512llm_temperature: float = 0.7# TTS配置tts_engine: str = "gtts"tts_language: str = "zh-cn"# 系统配置enable_streaming: bool = Truemax_audio_duration: float = 30.0silence_threshold: float = 0.01silence_duration: float = 2.0# 性能配置enable_caching: bool = Truecache_dir: str = "./cache"log_level: str = "INFO"class PerformanceMonitor:"""性能监控器"""def __init__(self):self.metrics = {"total_turns": 0,"asr_latency": [],"llm_latency": [],"tts_latency": [],"total_latency": [],"errors": []}self.start_time = time.time()def record_latency(self, component: str, latency: float):"""记录延迟"""if f"{component}_latency" in self.metrics:self.metrics[f"{component}_latency"].append(latency)def record_error(self, component: str, error: str):"""记录错误"""self.metrics["errors"].append({"component": component,"error": error,"timestamp": time.time()})def get_stats(self) -> Dict[str, Any]:"""获取统计信息"""stats = {"uptime": time.time() - self.start_time,"total_turns": self.metrics["total_turns"]}# 计算平均延迟for component in ["asr", "llm", "tts", "total"]:latencies = self.metrics[f"{component}_latency"]if latencies:stats[f"{component}_avg_latency"] = np.mean(latencies)stats[f"{component}_min_latency"] = np.min(latencies)stats[f"{component}_max_latency"] = np.max(latencies)stats[f"{component}_p95_latency"] = np.percentile(latencies, 95)stats["error_count"] = len(self.metrics["errors"])return statsclass DialogSystem:"""端到端对话系统"""def __init__(self, config: Optional[SystemConfig] = None):"""初始化对话系统Args:config: 系统配置"""self.config = config or SystemConfig()self.performance_monitor = PerformanceMonitor()# 设置日志级别logging.getLogger().setLevel(getattr(logging, self.config.log_level))# 初始化组件self.asr_engine = Noneself.llm_manager = Noneself.tts_manager = None# 状态管理self.is_running = Falseself.current_turn = Noneself.dialog_history = []# 回调函数self.callbacks = {"on_user_speech": [],"on_asr_result": [],"on_llm_response": [],"on_tts_complete": [],"on_turn_complete": [],"on_error": []}# 缓存self.cache_enabled = self.config.enable_cachingself.cache_dir = Path(self.config.cache_dir)self.cache_dir.mkdir(parents=True, exist_ok=True)logger.info("🚀 对话系统初始化完成")def initialize_components(self):"""初始化所有组件"""try:logger.info("🔧 初始化系统组件...")# 初始化ASRlogger.info("🎤 初始化ASR引擎...")self.asr_engine = ASREngine(model_name=self.config.asr_model,language=self.config.asr_language,cache_dir=str(self.cache_dir / "asr"))# 初始化LLMlogger.info("🧠 初始化LLM管理器...")self.llm_manager = LLMManager()# 添加LLM引擎(这里需要根据实际情况调整)if self.config.llm_model == "gpt2":from llm_module import TransformersEnginellm_engine = TransformersEngine(model_name="gpt2",cache_dir=str(self.cache_dir / "llm"))self.llm_manager.add_engine("gpt2", llm_engine)# 初始化TTSlogger.info("🔊 初始化TTS管理器...")self.tts_manager = TTSManager(default_engine=self.config.tts_engine)logger.info("✅ 所有组件初始化成功")except Exception as e:logger.error(f"❌ 组件初始化失败: {e}")raisedef add_callback(self, event: str, callback: Callable):"""添加回调函数Args:event: 事件名称callback: 回调函数"""if event in self.callbacks:self.callbacks[event].append(callback)else:logger.warning(f"⚠️ 未知事件类型: {event}")def _trigger_callbacks(self, event: str, data: Any = None):"""触发回调函数"""for callback in self.callbacks.get(event, []):try:callback(data)except Exception as e:logger.error(f"❌ 回调函数执行失败 ({event}): {e}")def process_audio_file(self, audio_path: str) -> DialogTurn:"""处理音频文件Args:audio_path: 音频文件路径Returns:对话轮次结果"""turn_id = f"turn_{int(time.time() * 1000)}"timestamps = {"start": time.time()}try:# 创建对话轮次turn = DialogTurn(turn_id=turn_id,user_input="",user_audio_path=audio_path,timestamps=timestamps)# 1. ASR处理logger.info(f"🎤 开始ASR处理: {audio_path}")asr_start = time.time()asr_result = self.asr_engine.transcribe_file(audio_path)asr_end = time.time()asr_latency = asr_end - asr_startself.performance_monitor.record_latency("asr", asr_latency)turn.asr_result = asr_resultturn.user_input = asr_result.get("text", "")timestamps["asr_complete"] = asr_endself._trigger_callbacks("on_asr_result", asr_result)if not turn.user_input.strip():logger.warning("⚠️ ASR未识别到有效文本")return turn# 2. LLM处理logger.info(f"🧠 开始LLM处理: {turn.user_input}")llm_start = time.time()llm_response = self.llm_manager.chat(turn.user_input)llm_end = time.time()llm_latency = llm_end - llm_startself.performance_monitor.record_latency("llm", llm_latency)turn.llm_response = llm_responsetimestamps["llm_complete"] = llm_endself._trigger_callbacks("on_llm_response", llm_response)# 3. TTS处理logger.info(f"🔊 开始TTS处理: {llm_response[:50]}...")tts_start = time.time()# 生成音频文件路径tts_audio_path = str(self.cache_dir / f"{turn_id}_response.mp3")self.tts_manager.synthesize_to_file(llm_response, tts_audio_path)tts_end = time.time()tts_latency = tts_end - tts_startself.performance_monitor.record_latency("tts", tts_latency)turn.tts_audio_path = tts_audio_pathtimestamps["tts_complete"] = tts_endself._trigger_callbacks("on_tts_complete", tts_audio_path)# 计算总延迟total_latency = tts_end - timestamps["start"]self.performance_monitor.record_latency("total", total_latency)# 设置延迟信息turn.latencies = {"asr": asr_latency,"llm": llm_latency,"tts": tts_latency,"total": total_latency}timestamps["complete"] = tts_endturn.timestamps = timestamps# 更新统计self.performance_monitor.metrics["total_turns"] += 1self.dialog_history.append(turn)self._trigger_callbacks("on_turn_complete", turn)logger.info(f"✅ 对话轮次完成,总延迟: {total_latency:.2f}s")return turnexcept Exception as e:logger.error(f"❌ 处理音频文件失败: {e}")self.performance_monitor.record_error("system", str(e))self._trigger_callbacks("on_error", {"error": str(e), "turn_id": turn_id})raisedef start_real_time_dialog(self):"""启动实时对话"""if self.is_running:logger.warning("⚠️ 实时对话已在运行中")returnself.is_running = Truelogger.info("🎙️ 启动实时对话模式")def on_speech_recognition(text: str):"""语音识别回调"""if not text.strip():returntry:# 异步处理对话threading.Thread(target=self._process_real_time_input,args=(text,),daemon=True).start()except Exception as e:logger.error(f"❌ 实时对话处理失败: {e}")# 启动ASR实时录音self.asr_engine.start_real_time_recording(callback=on_speech_recognition,silence_threshold=self.config.silence_threshold,silence_duration=self.config.silence_duration)def stop_real_time_dialog(self):"""停止实时对话"""if not self.is_running:returnlogger.info("🛑 停止实时对话模式")self.is_running = False# 停止ASR录音if self.asr_engine:self.asr_engine.stop_real_time_recording()# 停止TTS异步播放if self.tts_manager:self.tts_manager.stop_async_player()def _process_real_time_input(self, user_input: str):"""处理实时输入"""turn_id = f"realtime_{int(time.time() * 1000)}"try:logger.info(f"🗣️ 用户说: {user_input}")# LLM处理llm_start = time.time()response = self.llm_manager.chat(user_input)llm_latency = time.time() - llm_startlogger.info(f"🤖 助手回复: {response}")# TTS播放self.tts_manager.speak_async(response)# 记录性能self.performance_monitor.record_latency("llm", llm_latency)self.performance_monitor.metrics["total_turns"] += 1except Exception as e:logger.error(f"❌ 实时输入处理失败: {e}")self.performance_monitor.record_error("realtime", str(e))def test_system_latency(self, test_audio_path: str = None, test_text: str = None) -> Dict[str, Any]:"""测试系统延迟Args:test_audio_path: 测试音频文件路径test_text: 测试文本(如果不提供音频)Returns:延迟测试结果"""logger.info("🧪 开始系统延迟测试")test_results = {"test_time": datetime.now().isoformat(),"config": asdict(self.config),"results": []}# 准备测试数据test_cases = []if test_audio_path and Path(test_audio_path).exists():test_cases.append(("audio_file", test_audio_path))if test_text:test_cases.append(("text_input", test_text))# 默认测试用例if not test_cases:test_cases = [("text_input", "你好,今天天气怎么样?"),("text_input", "请介绍一下人工智能技术。"),("text_input", "谢谢你的帮助!")]for test_type, test_data in test_cases:try:logger.info(f"📝 测试用例: {test_type} - {str(test_data)[:50]}...")if test_type == "audio_file":# 音频文件测试turn = self.process_audio_file(test_data)result = {"test_type": test_type,"input": test_data,"user_text": turn.user_input,"response": turn.llm_response,"latencies": turn.latencies,"success": True}else:# 文本输入测试start_time = time.time()# LLM测试llm_start = time.time()response = self.llm_manager.chat(test_data)llm_end = time.time()# TTS测试tts_start = time.time()audio_data = self.tts_manager.synthesize(response)tts_end = time.time()total_time = tts_end - start_timeresult = {"test_type": test_type,"input": test_data,"response": response,"latencies": {"llm": llm_end - llm_start,"tts": tts_end - tts_start,"total": total_time},"success": True}test_results["results"].append(result)logger.info(f"✅ 测试完成,总延迟: {result['latencies']['total']:.2f}s")except Exception as e:logger.error(f"❌ 测试失败: {e}")test_results["results"].append({"test_type": test_type,"input": test_data,"error": str(e),"success": False})# 计算统计信息successful_tests = [r for r in test_results["results"] if r["success"]]if successful_tests:total_latencies = [r["latencies"]["total"] for r in successful_tests]test_results["summary"] = {"total_tests": len(test_results["results"]),"successful_tests": len(successful_tests),"avg_total_latency": np.mean(total_latencies),"min_total_latency": np.min(total_latencies),"max_total_latency": np.max(total_latencies)}logger.info("🎉 延迟测试完成")return test_resultsdef get_system_status(self) -> Dict[str, Any]:"""获取系统状态"""status = {"timestamp": datetime.now().isoformat(),"is_running": self.is_running,"config": asdict(self.config),"performance": self.performance_monitor.get_stats(),"components": {}}# 组件状态if self.asr_engine:status["components"]["asr"] = self.asr_engine.get_model_info()if self.llm_manager:status["components"]["llm"] = self.llm_manager.get_engine_info()if self.tts_manager:status["components"]["tts"] = self.tts_manager.get_engine_info()return statusdef save_dialog_history(self, filepath: str):"""保存对话历史"""history_data = {"timestamp": datetime.now().isoformat(),"config": asdict(self.config),"performance": self.performance_monitor.get_stats(),"dialog_history": [asdict(turn) for turn in self.dialog_history]}with open(filepath, 'w', encoding='utf-8') as f:json.dump(history_data, f, ensure_ascii=False, indent=2)logger.info(f"💾 对话历史已保存: {filepath}")# 使用示例和测试代码
if __name__ == "__main__":print("🎯 端到端对话系统测试")print("=" * 50)# 创建配置config = SystemConfig(asr_model="base",llm_model="gpt2",tts_engine="gtts",enable_streaming=True)# 初始化系统dialog_system = DialogSystem(config)# 添加回调函数def on_asr_result(result):print(f"🎤 ASR结果: {result.get('text', '')}")def on_llm_response(response):print(f"🧠 LLM响应: {response[:100]}...")def on_tts_complete(audio_path):print(f"🔊 TTS完成: {audio_path}")dialog_system.add_callback("on_asr_result", on_asr_result)dialog_system.add_callback("on_llm_response", on_llm_response)dialog_system.add_callback("on_tts_complete", on_tts_complete)try:# 初始化组件dialog_system.initialize_components()# 系统状态检查status = dialog_system.get_system_status()print(f"\n📊 系统状态:")print(f" 配置: {status['config']}")print(f" 组件: {list(status['components'].keys())}")# 延迟测试print(f"\n🧪 开始延迟测试...")test_results = dialog_system.test_system_latency(test_text="你好,请进行系统测试。")if test_results["results"]:print(f"✅ 测试完成:")for result in test_results["results"]:if result["success"]:latencies = result["latencies"]print(f" 输入: {result['input'][:30]}...")print(f" 回复: {result['response'][:50]}...")print(f" 延迟: 总计{latencies['total']:.2f}s "f"(LLM: {latencies.get('llm', 0):.2f}s, "f"TTS: {latencies.get('tts', 0):.2f}s)")# 实时对话测试print(f"\n🎙️ 实时对话测试")print("系统将开始监听语音输入...")print("请说话进行测试,或按 Ctrl+C 退出")dialog_system.start_real_time_dialog()try:# 模拟一些文本输入进行测试import timetest_inputs = ["你好!","今天天气不错。","再见!"]for text in test_inputs:print(f"\n💬 模拟输入: {text}")dialog_system._process_real_time_input(text)time.sleep(3) # 等待处理完成except KeyboardInterrupt:print("\n👋 用户中断测试")finally:dialog_system.stop_real_time_dialog()# 保存结果history_file = "dialog_history.json"dialog_system.save_dialog_history(history_file)# 最终统计final_stats = dialog_system.performance_monitor.get_stats()print(f"\n📈 最终统计:")print(f" 总对话轮次: {final_stats['total_turns']}")print(f" 平均延迟: {final_stats.get('total_avg_latency', 0):.2f}s")print(f" 错误次数: {final_stats['error_count']}")except Exception as e:print(f"❌ 系统测试失败: {e}")import tracebacktraceback.print_exc()print("\n🎉 端到端对话系统测试完成!")
第58天学习总结 - 端到端对话系统(第一部分)
🎯 核心知识点掌握情况
| 知识模块 | 重点内容 | 技术实现 | 掌握程度 | 实践要点 |
|---|---|---|---|---|
| 系统架构设计 | 端到端流程设计、组件解耦、数据流管理 | Mermaid流程图、模块化设计 | ⭐⭐⭐⭐⭐ | 理解ASR→LLM→TTS的完整链路 |
| ASR语音识别 | Whisper模型集成、实时语音处理、流式识别 | OpenAI Whisper、PyAudio、Librosa | ⭐⭐⭐⭐⭐ | 掌握音频预处理和实时录音 |
| TTS语音合成 | 多引擎支持、异步播放、音质优化 | gTTS、pyttsx3、pygame | ⭐⭐⭐⭐⭐ | 理解在线与离线TTS的差异 |
| LLM大模型 | 本地模型部署、对话管理、流式生成 | Transformers、ChatMessage、上下文管理 | ⭐⭐⭐⭐⭐ | 掌握本地模型的加载和推理 |
| 系统集成 | 组件协调、性能监控、错误处理 | DialogSystem、回调机制、异步处理 | ⭐⭐⭐⭐⭐ | 理解端到端系统的复杂性 |
怎么样今天的内容还满意吗?再次感谢朋友们的观看,关注GZH:凡人的AI工具箱,回复666,送您价值199的AI大礼包。最后,祝您早日实现财务自由,还请给个赞,谢谢!