CVPR2024迁移学习《Unified Language-driven Zero-shot Domain Adaptation》
摘要
本文提出了一个名为 Unified Language-driven Zero-shot Domain Adaptation(ULDA)的新任务设置,旨在使单一模型能够适应多种目标领域,而无需明确的领域标识(domain-ID)知识。现有语言驱动的零样本领域适应任务存在限制,例如需要领域ID和领域特定模型,这限制了模型的灵活性和可扩展性。为了解决这些问题,作者提出了一个包含三个组件的新框架:层次上下文对齐(Hierarchical Context Alignment, HCA)、领域一致表示学习(Domain Consistent Representation Learning, DCRL)和文本驱动校正器(Text-Driven Rectifier, TDR)。这些组件协同工作,分别在多个视觉层面上对齐模拟特征与目标文本、保留不同区域表示之间的语义相关性以及校正模拟特征与真实目标视觉特征之间的偏差。大量实证评估表明,该框架在两种设置中均取得了具有竞争力的性能,甚至超越了需要领域ID的模型,展现了其优越性和泛化能力。该方法不仅有效,而且在推理时不会引入额外的计算成本,具有实用性和效率。
Introduction
拟解决的问题:
- 领域适应中的灵活性和可扩展性问题:现有方法需要领域ID来选择领域特定的模型,这限制了模型在实际应用中的灵活性和可扩展性。例如,在“雨中驾驶”和“雪中驾驶”两种任务领域中,需要分别训练两个独立的模型来适应这些领域。
- 缺乏目标领域数据时的模型适应性问题:在实际应用中,由于隐私问题或数据稀缺性,可能无法直接访问目标领域的图像数据。因此,需要开发一种能够在没有目标领域图像的情况下,仅通过文本描述来适应目标领域的模型。
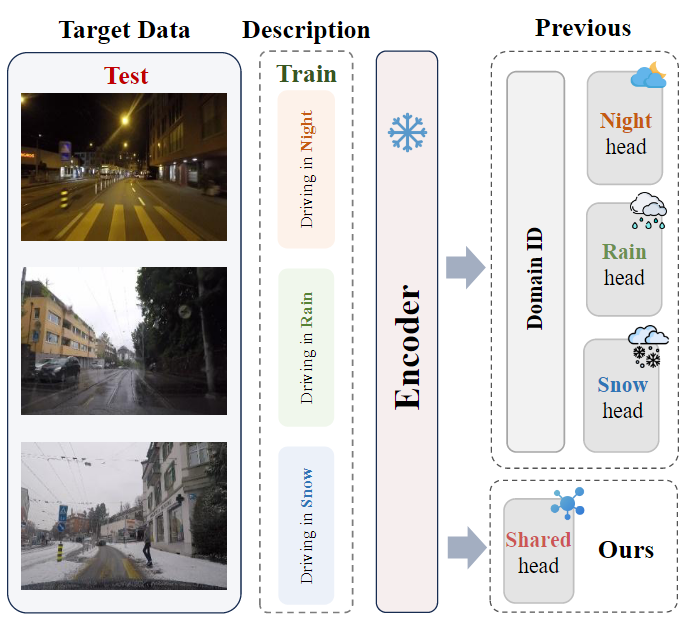
如下图所示。我们提出的统一语言驱动的领域适应(ULDA)任务侧重于现实世界的实际场景。在训练阶段,ULDA不允许访问目标域的图像,只提供源域图像和文本描述。在测试期间,ULDA需要一个单一的模型来适应不同的目标域,而不是像以前的方法那样使用特定于域的头。
创新之处:
提出了一种新的任务设置ULDA:与现有方法不同,ULDA要求单个模型能够适应多种目标领域,而无需在测试时提供领域ID,这更符合实际应用场景。
设计了一个包含三个关键组件的新框架:
- 层次上下文对齐(HCA):通过在场景级别、区域级别和像素级别对齐特征与文本嵌入,解决了全局对齐可能导致的语义损失问题。
- 领域一致表示学习(DCRL):通过保留不同类别在不同领域中的语义相关性,确保了模型在不同领域之间的结构一致性。
- 文本驱动校正器(TDR):通过利用文本嵌入来校正模拟特征,减少了模拟特征与真实目标特征之间的偏差,提高了模型的泛化能力。
在推理阶段不引入额外计算成本:该方法在保持有效性的同时,确保了模型在实际应用中的实用性和效率。
Preliminary
PØDA 是一种用于计算机视觉中零样本领域适应(Zero-shot Domain Adaptation, ZSDA)的范式。它通过仅利用目标领域的自然语言描述,而无需目标领域的图像数据来训练模型,从而实现从源领域到目标领域的适应。PØDA 的核心思想是利用预训练的 CLIP 编码器来优化源特征的转换,并将其与目标领域的文本嵌入对齐。
PØDA 的训练过程分为两个阶段:
第一阶段:模拟目标特征(Simulating Target Features)
-
Prompt-driven Instance Normalization (PIN):PØDA 引入了 PIN 操作,通过可学习的变量 μ 和 σ,这些变量由目标领域的文本提示引导,来模拟目标领域的知识。具体公式如下:
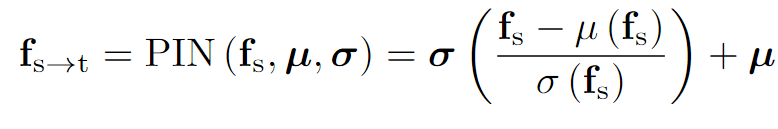
其中,fs 是源域特征,μ(fs) 和 σ(fs) 分别是源特征的均值和标准差。
对齐目标文本嵌入:为了确保从源域到目标域的适当转换,需要通过以下损失函数促进 fs→tPIN 与 CLIP 文本嵌入 TrgEmb 之间的相似性:
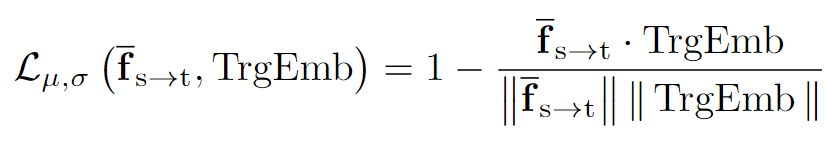
其中,是通过 Prompt-driven Instance Normalization (PIN) 转换后的全局特征,TrgEmb 是目标文本嵌入。
第二阶段:微调分割头(Fine-tuning the Segmentation Head)
在第一阶段获得模拟特征后,PØDA 对预训练的分割头进行微调,使模型能够更好地适应目标领域的下游任务。这一阶段的训练由分割预测与真实掩码之间的交叉熵损失监督。
方法
提出了一种名为 Unified Language-driven Zero-shot Domain Adaptation (ULDA) 的新方法,旨在使单一模型能够适应多种目标领域,而无需明确的领域标识(domain-ID)。该方法的核心在于通过语言驱动的方式,仅利用源域数据和目标域的文本描述,来实现对目标域的有效适应。ULDA框架包含三个关键组件:层次上下文对齐(HCA)、领域一致表示学习(DCRL) 和 文本驱动校正器(TDR)。这些组件协同工作,分别从特征对齐、语义一致性保持和特征校正三个方面提升模型的泛化能力和适应性。
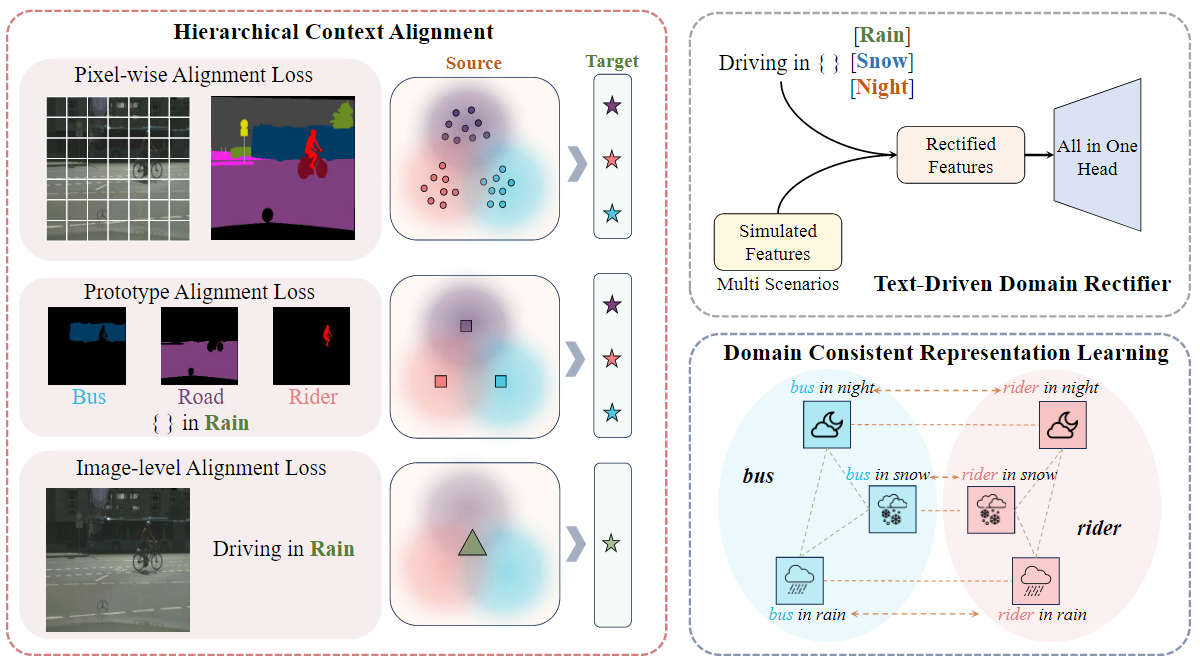
1. 层次上下文对齐(Hierarchical Context Alignment, HCA)
Vanilla scene-text 对齐会导致语义丢失。PØDA 通过等式直接将池化特征 fs→t 与文本嵌入 TrgEmb 对齐,在场景级别实现了视觉语言对齐。然而,模型仅通过调整全局上下文以适应目标域来实现与目标域的良好对齐具有挑战性,因为在将场景中不同对象的特征对齐到单个共享目标域嵌入时这可能会导致潜在的语义损失,从而导致偏离它们各自的真实语义分布。为了缓解这个问题,我们提出了一种分层上下文对齐 (HCA) 策略,该策略可以在多个级别上对特征进行复杂的对齐,包括 1) 整个场景,2) 场景中的区域,以及 3) 场景中的像素。
1.1 场景级别对齐

HCA 的第一个层次是场景级别对齐,目标是将全局特征与目标文本嵌入对齐。具体来说,通过以下公式实现:
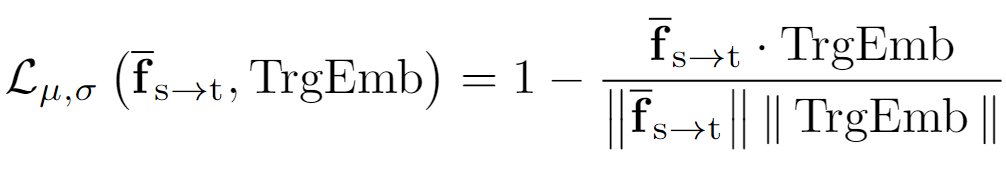
其中,是通过 Prompt-driven Instance Normalization (PIN) 转换后的全局特征,TrgEmb 是目标文本嵌入。该损失函数通过最大化全局特征与文本嵌入的相似性,使模型能够适应目标域的整体语义。
1.2 区域级别对齐

区域级别对齐的目标是保留不同类别在场景中的独特语义特征。具体步骤如下:
1.利用类别名称和目标域描述生成细粒度的文本嵌入,其中 n 是类别数量,d 是嵌入维度。
2.将图像特征图与类别标签
转换为二值掩码
。
3.通过掩码平均池化(Masked Average Pooling, MAP)计算每个类别的区域原型:
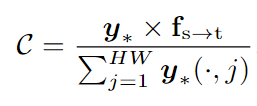
4.计算区域原型 C 与文本嵌入 T 之间的相似性矩阵:
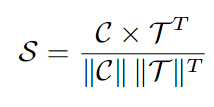
5.通过以下公式优化区域对齐损失:
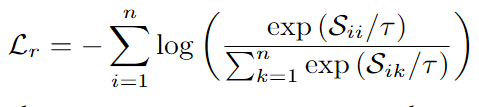
1.3 像素级别对齐
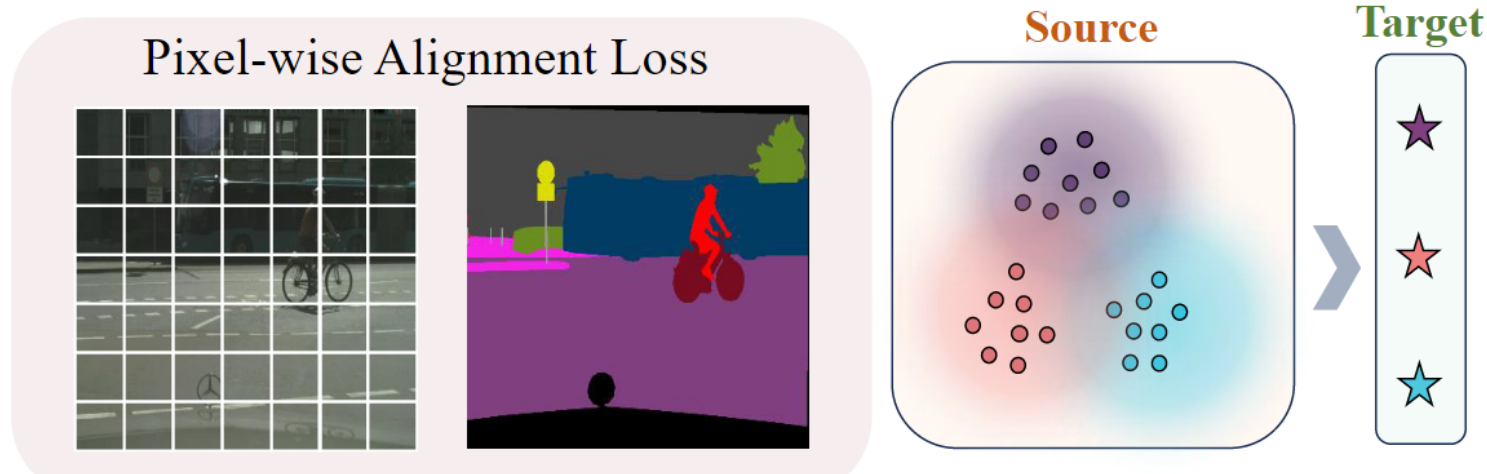
像素级别对齐进一步细化特征与文本嵌入之间的对齐,目标是使每个像素的特征更接近目标域的语义。具体步骤如下:
1.计算每个像素的类别概率:
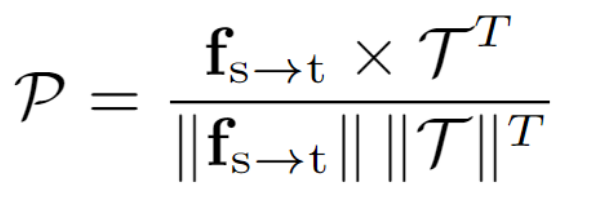
2.使用像素级标签计算交叉熵损失:
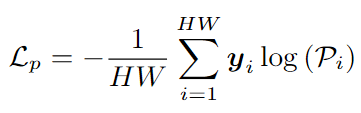
1.4 总体损失
HCA 的总体损失函数为:
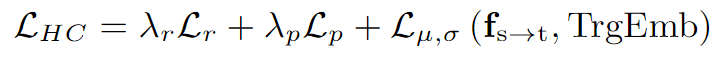
2. 领域一致表示学习(Domain Consistent Representation Learning, DCRL)
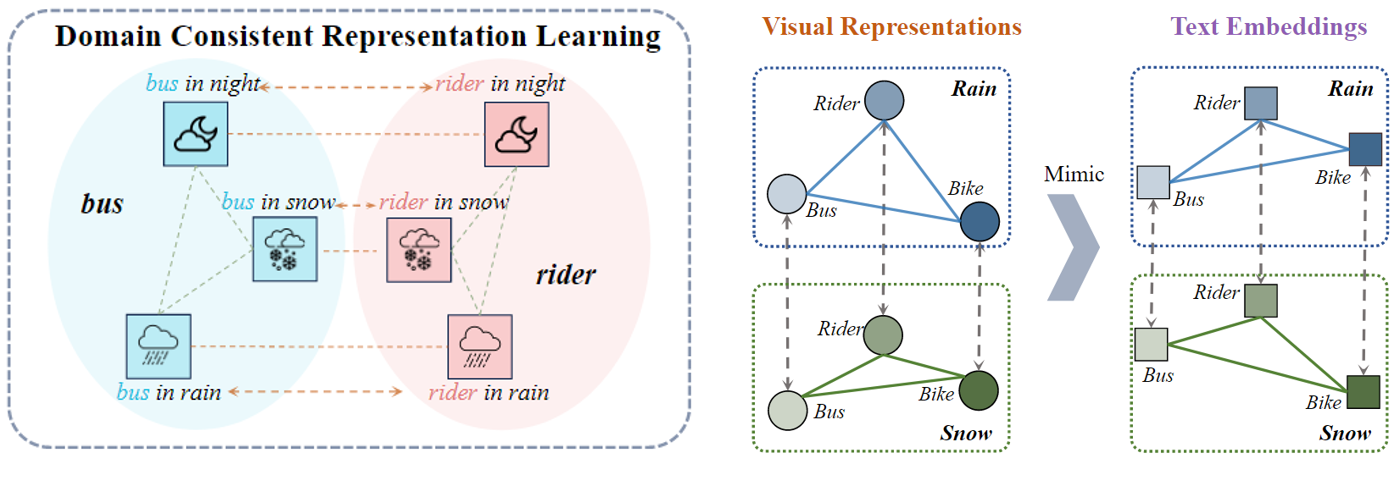
DCRL 的目标是确保不同领域之间的语义相关性保持一致。例如,“雪中的公共汽车”、“雨中的公共汽车”和“夜间的公共汽车”的文本嵌入可能与“雪”、“雨”和“夜”背景下的视觉对应物相比可能具有不同的相关性。具体来说,对于 m 个目标领域中的 n 个类别,分别计算每个领域的类别原型和文本嵌入
,并将它们组合成扩展的原型矩阵
和
。然后,通过以下公式优化领域一致性损失:
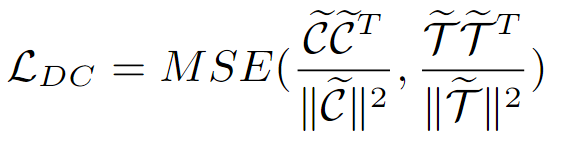
该损失函数通过最小化不同领域中类别原型与文本嵌入之间的相关性差异,确保模型在不同领域之间保持一致的语义表示。
3. 文本驱动校正器(Text-Driven Rectifier, TDR)
在第二阶段微调时,模型利用模拟的目标域特征来微调分割头,使模型能够有效地适应目标域。然而,模拟特征与实际目标域特征之间可能存在差异。考虑这些差异至关重要,因为直接使用模拟特征可能会导致分割头与真实目标分布的偏差,从而在调整后产生更差的分割性能。
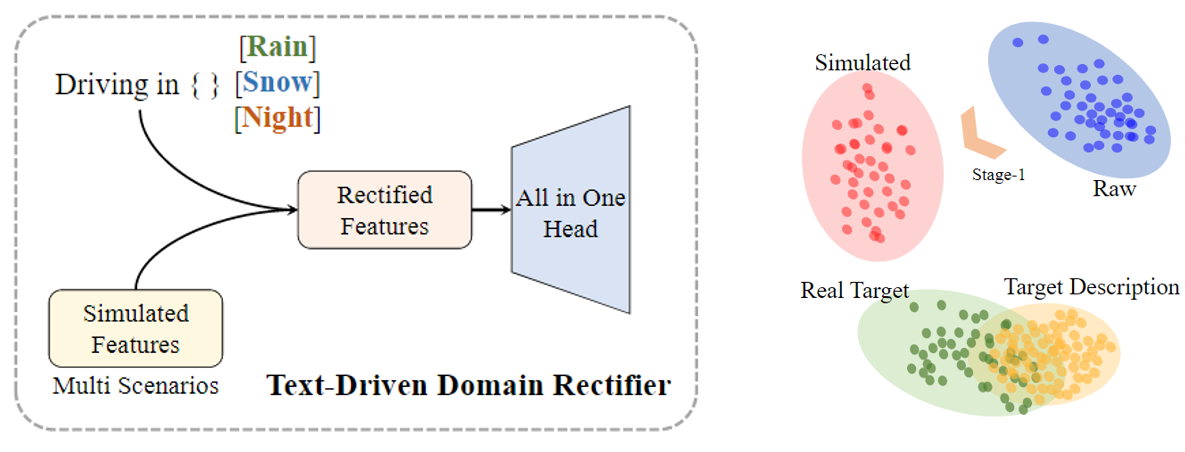
因此,我们建议通过利用 CLIP 获得的文本嵌入来解决这个问题,这些嵌入实际上类似于真实目标域中的分布。通过采用这些文本嵌入作为先验,我们可以纠正模拟过程,从而鼓励模拟特征与目标特征更紧密地对齐。纠正有利于适应。具体来说,TDR 的目标是校正模拟特征与真实目标特征之间的偏差。具体来说,在模型的第二阶段(微调阶段),通过以下公式对模拟特征进行校正:
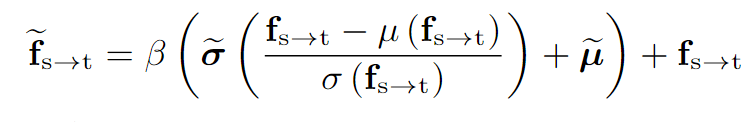
其中, 和
是通过文本嵌入经过线性层得到的目标特征的均值和标准差,β 是一个可学习的校正因子,用于控制校正的程度。通过这种方式,TDR 使模拟特征更接近真实目标特征,从而提高模型的泛化能力。
4.总结
训练过程:
- Stage-1:通过 PIN 生成模拟特征,并使用 HCA 和 DCRL 进行对齐。
- Stage-2:通过 TDR 校正模拟特征,并微调分割头以优化分割任务的性能。
推理过程: 对目标域图像进行特征提取、模拟特征生成、文本驱动校正和分割预测。
结论
-
ULDA框架的有效性:通过在多种目标领域上的实验验证,ULDA框架在零样本领域适应任务中取得了具有竞争力的性能,甚至在某些情况下超越了需要领域ID的方法,证明了其在实际应用中的可行性和优越性。
-
方法的实用性:ULDA方法在推理阶段不引入额外的计算成本,保持了模型的实用性和效率,使其更适合于实际的领域适应任务。
-
对领域适应任务的推动:ULDA的提出为领域适应任务提供了一种新的思路,即通过文本描述来适应目标领域,而无需直接访问目标领域的图像数据,这为解决实际应用中的数据稀缺问题提供了一种有效的解决方案。