python打卡day53
对抗生成网络GAN
知识点回顾:
- 对抗生成网络的思想:关注损失从何而来
- 生成器、判别器
- nn.sequential容器:适合于按顺序运算的情况,简化前向传播写法
- leakyReLU介绍:避免relu的神经元失活现象
GAN 的核心在于 对抗训练,由两个动态博弈的神经网络组成:
-
生成器(Generator, G):负责生成假数据(如假币),目标是骗过判别器。
-
判别器(Discriminator, D):负责区分真实数据和生成数据(如警察辨真假),目标是提高判别准确率
损失从何而来?
- 判别器的损失:来自分类任务(区分真实数据 vs. 生成数据)
- 生成器的损失:来自判别器的反馈(生成数据被判别为“假”时,损失大;反之损失小)
损失如何定义?
- 判别器损失(D Loss):真实数据判为“真” + 生成数据判为“假” → 二分类交叉熵(BCE)
- 生成器损失(G Loss):生成数据被判别为“真” → 反向传播优化生成器
选用鸢尾花数据集来举个例子
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题LATENT_DIM = 10 # 潜在空间的维度,这里根据任务复杂程度任选
EPOCHS = 10000 # 训练的回合数,一般需要比较长的时间
BATCH_SIZE = 32 # 每批次训练的样本数
LR = 0.0002 # 学习率
BETA1 = 0.5 # Adam优化器的参数# 检查是否有可用的GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# --- 2. 加载并预处理数据 ---iris = load_iris()
X = iris.data
y = iris.target# 只选择 'Setosa' (类别 0)
X_class0 = X[y == 0] # 一种简便写法# 数据缩放到 [-1, 1]
scaler = MinMaxScaler(feature_range=(-1, 1))
X_scaled = scaler.fit_transform(X_class0) # 转换为 PyTorch Tensor 并创建 DataLoader
# 注意需要将数据类型转为 float
real_data_tensor = torch.from_numpy(X_scaled).float()
dataset = TensorDataset(real_data_tensor)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)print(f"成功加载并预处理数据。用于训练的样本数量: {len(X_scaled)}")
print(f"数据特征维度: {X_scaled.shape[1]}")1、生成器
# (A) 生成器 (Generator)
class Generator(nn.Module):def __init__(self):super(Generator, self).__init__()self.model = nn.Sequential(nn.Linear(LATENT_DIM, 16),nn.ReLU(),nn.Linear(16, 32),nn.ReLU(),nn.Linear(32, 4),# 最后的维度只要和目标数据对齐即可nn.Tanh() # 输出范围是 [-1, 1])def forward(self, x):return self.model(x) # 因为没有像之前一样做定义x=某些东西,所以现在可以直接输出模型这里我们用了torch中的容器这个概念,sequential是一个按顺序存放神经网络的容器,这样写神经网路的属性的时候,把这些内容都写在一个容器中,然后作为属性,后面定义前向传播的时候会方便很多,不用像之前那样
sequential适合线性顺序执行的网络。但对于网络包含复杂分支结构(如 ResNet 的残差连接、Inception 的多分支),建议手动编写forward()方法,比如
def forward(self, x):identity = xout = self.conv1(x)out = self.relu(out)out = self.conv2(out)out += identity # 残差连接(无法用Sequential实现)return self.relu(out)2、判别器
# (B) 判别器 (Discriminator)
class Discriminator(nn.Module):def __init__(self):super(Discriminator, self).__init__()self.model = nn.Sequential(nn.Linear(4, 32),nn.LeakyReLU(0.2), # LeakyReLU 是 GAN 中的常用选择nn.Linear(32, 16),nn.LeakyReLU(0.2), # 负斜率参数为0.2nn.Linear(16, 1), # 这里最后输出1个神经元,所以用sigmoid激活函数nn.Sigmoid() # 输出 0 到 1 的概率)def forward(self, x):return self.model(x)之前的激活函数都是用的标准ReLU:f(x) = max(0, x),但当输入为负时,输出全部置为零,此时梯度为零更新不了参数,这就是神经元死亡问题
LeakyReLU: f(x) = max(0.01x, x) 对负数输入保留一个小的梯度(如0.01倍),在输入为负时,仍有非零梯度(如 0.01),避免神经元永久死亡
许多 GAN 变体(如 DCGAN、WGAN)都默认使用 LeakyReLU,实践证明它能显著提高模型收敛速度和生成质量
# 实例化模型并移动到指定设备
generator = Generator().to(device)
discriminator = Discriminator().to(device)print(generator)
print(discriminator)# --- 4. 定义损失函数和优化器 ---criterion = nn.BCELoss() # 二元交叉熵损失# 分别为生成器和判别器设置优化器
g_optimizer = optim.Adam(generator.parameters(), lr=LR, betas=(BETA1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LR, betas=(BETA1, 0.999))# --- 5. 执行训练循环 ---print("\n--- 开始训练 ---")
for epoch in range(EPOCHS):for i, (real_data,) in enumerate(dataloader):# 将数据移动到设备real_data = real_data.to(device)current_batch_size = real_data.size(0)# 创建真实和虚假的标签real_labels = torch.ones(current_batch_size, 1).to(device)fake_labels = torch.zeros(current_batch_size, 1).to(device)# ---------------------# 训练判别器# ---------------------d_optimizer.zero_grad() # 梯度清零# (1) 用真实数据训练real_output = discriminator(real_data)d_loss_real = criterion(real_output, real_labels)# (2) 用假数据训练noise = torch.randn(current_batch_size, LATENT_DIM).to(device)# 使用 .detach() 防止在训练判别器时梯度流回生成器,这里我们未来再说fake_data = generator(noise).detach() fake_output = discriminator(fake_data)d_loss_fake = criterion(fake_output, fake_labels)# 总损失并反向传播d_loss = d_loss_real + d_loss_faked_loss.backward()d_optimizer.step()# ---------------------# 训练生成器# ---------------------g_optimizer.zero_grad() # 梯度清零# 生成新的假数据,并尝试"欺骗"判别器noise = torch.randn(current_batch_size, LATENT_DIM).to(device)fake_data = generator(noise)fake_output = discriminator(fake_data)# 计算生成器的损失,目标是让判别器将假数据误判为真(1)g_loss = criterion(fake_output, real_labels)# 反向传播并更新生成器g_loss.backward()g_optimizer.step()# 每 1000 个 epoch 打印一次训练状态if (epoch + 1) % 1000 == 0:print(f"Epoch [{epoch+1}/{EPOCHS}], "f"Discriminator Loss: {d_loss.item():.4f}, "f"Generator Loss: {g_loss.item():.4f}")print("--- 训练完成 ---")# --- 6. 生成新数据并进行可视化对比 ---print("\n--- 生成并可视化结果 ---")
# 将生成器设为评估模式
generator.eval()# 使用 torch.no_grad() 来关闭梯度计算
with torch.no_grad():num_new_samples = 50noise = torch.randn(num_new_samples, LATENT_DIM).to(device)generated_data_scaled = generator(noise)# 将生成的数据从GPU移到CPU,并转换为numpy数组
generated_data_scaled_np = generated_data_scaled.cpu().numpy()# 逆向转换回原始尺度
generated_data = scaler.inverse_transform(generated_data_scaled_np)
real_data_original_scale = scaler.inverse_transform(X_scaled)# 可视化对比
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle('真实数据 vs. GAN生成数据 的特征分布对比 (PyTorch)', fontsize=16)feature_names = iris.feature_namesfor i, ax in enumerate(axes.flatten()):ax.hist(real_data_original_scale[:, i], bins=10, density=True, alpha=0.6, label='Real Data')ax.hist(generated_data[:, i], bins=10, density=True, alpha=0.6, label='Generated Data')ax.set_title(feature_names[i])ax.legend()plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()# 将生成的数据与真实数据并排打印出来看看
print("\n前5个真实样本 (Setosa):")
print(pd.DataFrame(real_data_original_scale[:5], columns=feature_names))print("\nGAN生成的5个新样本:")
print(pd.DataFrame(generated_data[:5], columns=feature_names))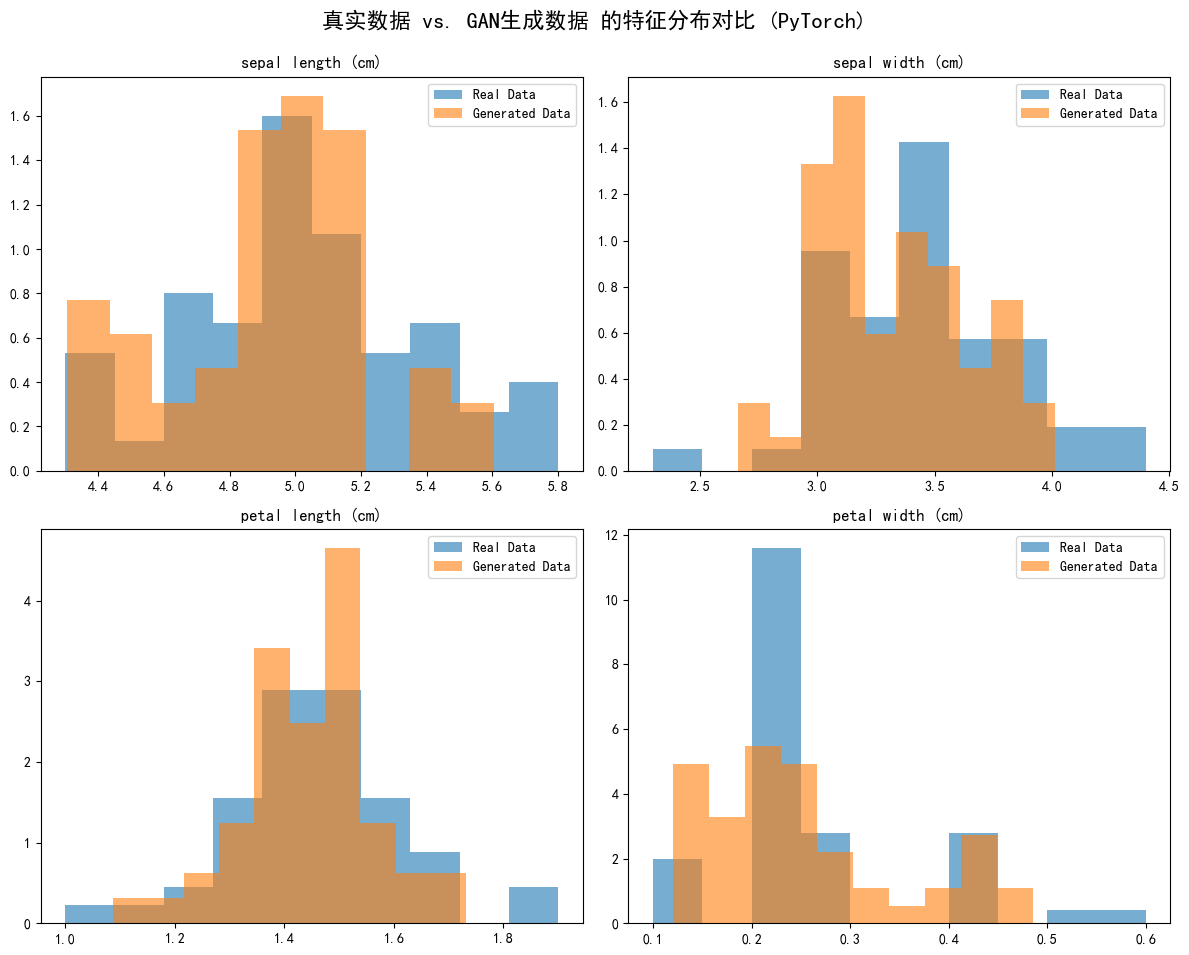
GAN 训练效果的关键指标是 生成数据分布与真实数据分布的重合度:
- 若两者分布高度重叠 → 生成数据质量高,GAN 学得好
- 若分布差异大、峰谷错位明显 → 生成数据存在偏差,GAN 学习不充分
作业:对于心脏病数据集,对于病人这个不平衡的样本用GAN来学习并生成病人样本,观察不用GAN和用GAN的F1分数差异
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, classification_report
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")# 检查是否有可用的GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")# 加载数据
data = pd.read_csv('/kaggle/input/heart12/heart (3).csv')
X = data.drop('target', axis=1).values
y = data['target'].values# 查看类别分布
print(pd.Series(y).value_counts()) # 假设1是少数类(病人)# 标准化
scaler = StandardScaler()
X = scaler.fit_transform(X)# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 转换为PyTorch张量
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)# 提取少数类样本(病人),但其实病人样本更多,但题目要求生成病人样本,硬做呗
minority_samples = X_train[y_train == 1]
minority_labels = y_train[y_train == 1]# 参数设置
input_dim = X.shape[1] # 特征维度
latent_dim = 100 # 噪声维度
epochs = 5000
batch_size = 64
lr = 0.0002
BETA1 = 0.5class Generator(nn.Module):def __init__(self, input_dim, output_dim):super().__init__()self.model = nn.Sequential(nn.Linear(input_dim, 128),nn.LeakyReLU(0.2),nn.Linear(128, 256),nn.LeakyReLU(0.2),nn.Linear(256, output_dim),nn.Tanh() # 使用Tanh将输出缩放到[-1,1])def forward(self, x):return self.model(x)class Discriminator(nn.Module):def __init__(self, input_dim):super().__init__()self.model = nn.Sequential(nn.Linear(input_dim, 256),nn.LeakyReLU(0.2),nn.Dropout(0.3),nn.Linear(256, 128),nn.LeakyReLU(0.2),nn.Dropout(0.3),nn.Linear(128, 1),nn.Sigmoid())def forward(self, x):return self.model(x)# 初始化模型
G = Generator(latent_dim, input_dim).to(device)
D = Discriminator(input_dim).to(device)# 损失函数和优化器
criterion = nn.BCELoss()
G_optimizer = torch.optim.Adam(G.parameters(), lr=lr, betas=(BETA1, 0.999))
D_optimizer = torch.optim.Adam(D.parameters(), lr=lr, betas=(BETA1, 0.999))# 准备真实数据(少数类)
real_data = minority_samples
real_labels = torch.ones(len(real_data), 1)# 训练GAN
for epoch in range(epochs):# 训练判别器D_optimizer.zero_grad()# 真实数据real_output = D(real_data)d_loss_real = criterion(real_output, torch.ones_like(real_output))# 生成数据noise = torch.randn(len(real_data), latent_dim)fake_data = G(noise)fake_output = D(fake_data.detach())d_loss_fake = criterion(fake_output, torch.zeros_like(fake_output))d_loss = d_loss_real + d_loss_faked_loss.backward()D_optimizer.step()# 训练生成器G_optimizer.zero_grad()noise = torch.randn(len(real_data), latent_dim)fake_data = G(noise)fake_output = D(fake_data)g_loss = criterion(fake_output, torch.ones_like(fake_output))g_loss.backward()G_optimizer.step()if epoch % 500 == 0:print(f'Epoch {epoch}, D Loss: {d_loss.item()}, G Loss: {g_loss.item()}')# 生成新样本
num_samples = abs(len(y_train[y_train == 0]) - len(y_train[y_train == 1])) # 生成足够样本使类别平衡,绝对值保护一下,因为最开始病人其实更多
noise = torch.randn(num_samples, latent_dim)
generated_samples = G(noise).detach().numpy()
generated_labels = np.ones(num_samples)# 原始数据训练
rf_original = RandomForestClassifier()
rf_original.fit(X_train, y_train)
y_pred_original = rf_original.predict(X_test)
print("Original Data F1 Score:", f1_score(y_test, y_pred_original))
print(classification_report(y_test, y_pred_original))# 增强数据训练
X_train_augmented = np.concatenate([X_train, generated_samples])
y_train_augmented = np.concatenate([y_train.numpy(), generated_labels])rf_augmented = RandomForestClassifier()
rf_augmented.fit(X_train_augmented, y_train_augmented)
y_pred_augmented = rf_augmented.predict(X_test)
print("Augmented Data F1 Score:", f1_score(y_test, y_pred_augmented))
print(classification_report(y_test, y_pred_augmented))Original Data F1 Score: 0.8615384615384615precision recall f1-score support0 0.86 0.83 0.84 291 0.85 0.88 0.86 32accuracy 0.85 61macro avg 0.85 0.85 0.85 61
weighted avg 0.85 0.85 0.85 61Augmented Data F1 Score: 0.84375precision recall f1-score support0 0.83 0.83 0.83 291 0.84 0.84 0.84 32accuracy 0.84 61macro avg 0.84 0.84 0.84 61
weighted avg 0.84 0.84 0.84 61结果反而更差了,这个数据集健康样本138,病人样本165,不平衡问题不显著,GAN相当于过采样了,而且还生成的是病人样本,过度处理不平衡更不合理了
@浙大疏锦行