MultiTalk 是一种音频驱动的多人对话视频生成模型
TL;DR:MultiTalk 是一种音频驱动的多人对话视频生成。它支持多人对话💬、唱🎤歌、交互控制和👬卡通🙊的视频创建。
视频演示
| 001.mp4 | 004.mp4 | 003.mp4 |
| 002.mp4 | 005.mp4 | 006.mp4 |
| 003.mp4 | 002.mp4 | 003.mp4 |
✨ 主要特点
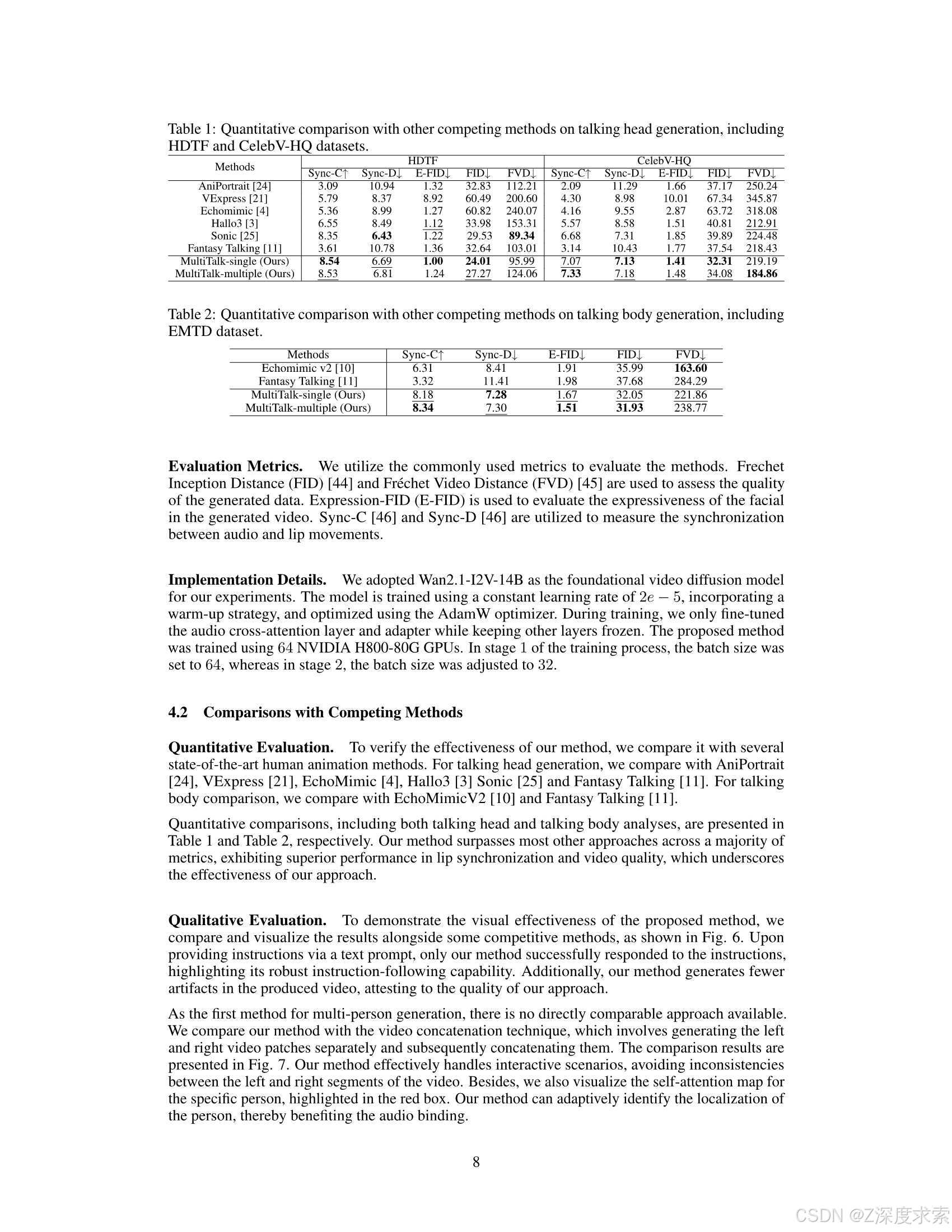
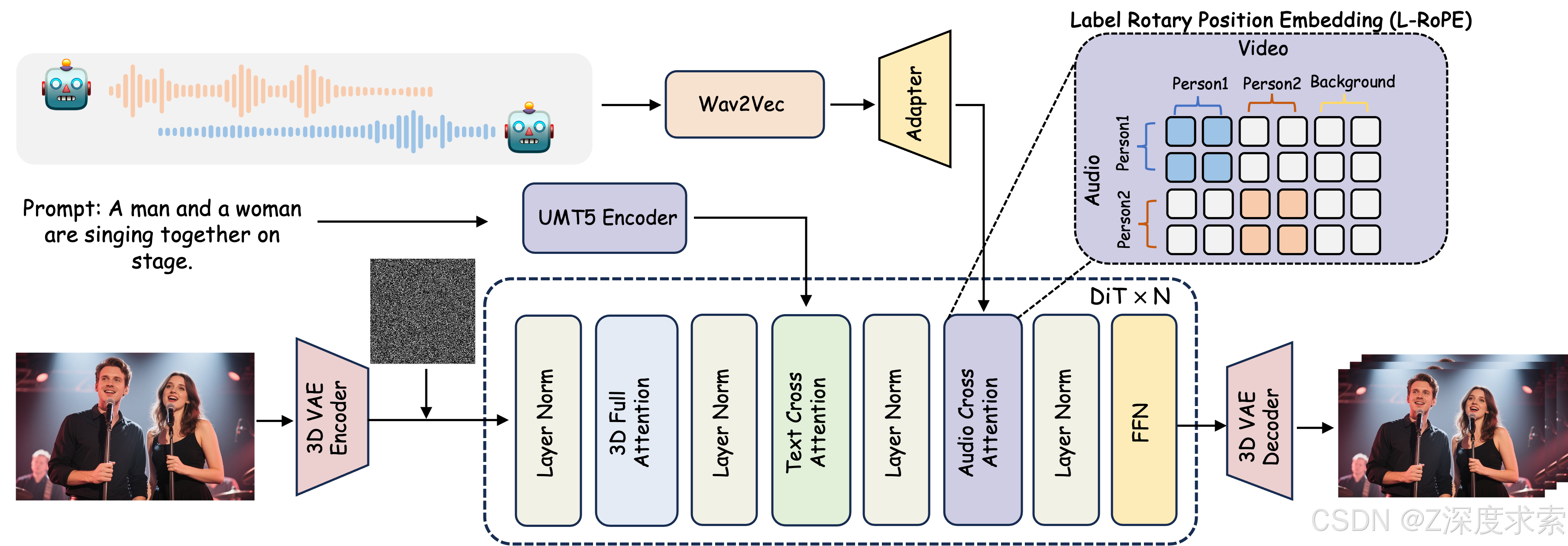
我们提出了 MultiTalk ,一种用于音频驱动的多人对话视频生成的新颖框架。给定一个多流音频输入、一个参考图像和一个提示,MultiTalk 会生成一个视频,其中包含跟随提示的交互,并与音频保持一致的嘴唇动作。
- 💬 真实的对话 - 支持单人和多人生成
- 👥 交互式角色控制 - 通过提示引导虚拟人
- 🎤 泛化表演 - 支持生成卡通人物和歌唱
- 📺 分辨率灵活性:任意纵横比下的480p和720p输出
- ⏱️ 长视频生成:支持最长 15 秒的视频生成
🧱模型准备
1. 模型下载
| 模型 | 下载链接 | 笔记 |
|---|---|---|
| 广域网2.1-I2V-14B-480P | 🤗 拥抱脸 | 基本模型 |
| 中文-WAV2VEC2-基 | 🤗 拥抱脸 | 音频编码器 |
| 美原-MultiTalk | 🤗 拥抱脸 | 我们的音频条件权重 |
使用 huggingface-cli 下载模型:
huggingface-cli download Wan-AI/Wan2.1-I2V-14B-480P --local-dir ./weights/Wan2.1-I2V-14B-480P huggingface-cli download TencentGameMate/chinese-wav2vec2-base --local-dir ./weights/chinese-wav2vec2-base huggingface-cli download MeiGen-AI/MeiGen-MultiTalk --local-dir ./weights/MeiGen-MultiTalk
2. 将 MultiTalk 模型链接或复制到 wan2.1-I2V-14B-480P 目录
链接方式:
mv weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json_old
sudo ln -s {Absolute path}/weights/MeiGen-MultiTalk/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/
sudo ln -s {Absolute path}/weights/MeiGen-MultiTalk/multitalk.safetensors weights/Wan2.1-I2V-14B-480P/
或者,通过以下方式复制:
mv weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/diffusion_pytorch_model.safetensors.index.json_old
cp weights/MeiGen-MultiTalk/diffusion_pytorch_model.safetensors.index.json weights/Wan2.1-I2V-14B-480P/
cp weights/MeiGen-MultiTalk/multitalk.safetensors weights/Wan2.1-I2V-14B-480P/
🔑 快速推理
我们的型号兼容 480P 和 720P 分辨率。当前代码仅支持 480P 推理。720P 推理需要多个 GPU,我们将很快提供更新。
一些提示
- 唇形同步精度: 音频 CFG 在 3-5 之间效果最佳。增加音频 CFG 值以获得更好的同步。
- 视频剪辑长度:该模型以 25 FPS 的速度在 81 帧视频上进行训练。为了获得最佳的提示跟随性能,请在 81 帧处生成剪辑。最多可以生成 201 帧,但较长的剪辑可能会降低提示跟随性能。
- 长视频生成:音频 CFG 会影响各段落之间的色调一致性。将此值设置为 3 可减轻色调变化。
- 采样步骤:如果你想快速生成视频,你可以将采样步骤减少到 10 个甚至 10 个,这不会损害嘴唇同步的准确性,但会影响动作和视觉质量。采样步骤越多,视频质量越好。
1. 单人
1) 生成一个 1 块的短视频
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/single_example_1.json --sample_steps 40 --frame_num 81 --mode clip --save_file single_exp2) 长视频生成
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/single_example_1.json --sample_steps 40 --mode streaming --save_file single_long_exp2. 多人
1) 生成一个 1 块的短视频
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/multitalk_example_1.json --sample_steps 40 --frame_num 81 --mode clip --save_file multi_exp
2) 长视频生成
python generate_multitalk.py --ckpt_dir weights/Wan2.1-I2V-14B-480P \--wav2vec_dir 'weights/chinese-wav2vec2-base' --input_json examples/multitalk_example_2.json --sample_steps 40 --mode streaming --save_file multi_long_expMultiTalk,这是一种用于音频驱动的多人对话视频生成的新颖框架。给定一个多流音频输入、一个参考图像和一个提示,MultiTalk 会生成一个视频,其中包含跟随提示的交互,并与音频保持一致的嘴唇动作。
生成卡通视频

生成歌唱视频

生成遵循指令的视频
在一个舒适、温暖的房间里,尼克·王尔德(Nick Wilde)——一只带着调皮的笑容的狐狸——坐在朱迪·霍普斯(Judy Hopps)对面,朱迪·霍普斯(Judy Hopps)是一只表情坚定的兔子。 两人都穿着休闲;Nick 穿着绿色衬衫和条纹领带,Judy 穿着蓝色衣服,耳机放在桌子上。 他们之间的木桌上放着一个迪士尼品牌的杯子。 背景以质朴的内饰为特色,配有灯、窗户和各种家居用品,营造出温馨的氛围。 当 Nick 拿起杯子并轻轻触摸 Judy 的头部时,一个中景镜头捕捉到了他们的互动,暗示了一段友情和联系。

一男一女坐在户外的桌子旁,正在进行交谈。 这位女士身穿浅粉色上衣和白色开衫,手里拿着一个红色的罩杯 咖啡,啜饮一口,然后将其放回碟子上。那个男人,穿着 一件条纹衬衫套在一件白色 T 恤上,全神贯注地看着他的智能手机 专心致志地向下。桌子上装饰着两杯红色咖啡和一个盘子 配羊角面包。背景是一条迷人的欧洲街道,色彩柔和。 建筑物、绿色植物和一把半开着的绿色伞。场景捕获 一个随意的日常时刻,拥有温暖、诱人的氛围。
两个人坐在工作室的白色桌子旁,工作室里有蓝白相间的吸音墙板。 左边的一名男子穿着深色休闲上衣,手里拿着一个咖啡杯。 右边的女人身边放着一副录音室耳机。 男人在说话,而女人在听,偶尔点头。 女人拿起黑色耳机。大型壁挂式电视显示技术接口。 该场景暗示了在明亮的工作室环境中配备专业视听设备的协作工作空间。
More creative videos
Abstract
Audio-driven human animation methods, such as talking head and talking body generation, have made remarkable progress in generating synchronized facial movements and appealing visual quality videos. However, existing methods primarily focus on single human animation and struggle with multi-stream audio inputs, facing incorrect binding problems between audio and persons. Additionally, they exhibit limitations in instruction-following capabilities. To solve this problem, in this paper, we propose a novel task: Multi-Person Conversational Video Generation, and introduce a new framework, MultiTalk, to address the challenges during multi-person generation. Specifically, for audio injection, we investigate several schemes and propose the Label Rotary Position Embedding (L-RoPE) method to resolve the audio and person binding problem. Furthermore, during training, we observe that partial parameter training and multi-task training are crucial for preserving the instruction-following ability of the base model. MultiTalk achieves superior performance compared to other methods on several datasets, including talking head, talking body, and multi-person datasets, demonstrating the powerful generation capabilities of our approach.
Method
In this work, we propose MultiTalk, an audio-driven video generation framework. Our framework incorporates an additional audio cross-attention layer to support audio conditions. To achieve multi-person conversational video generation, we propose a Label Rotary Position Embedding (L-RoPE) for multi-stream audio injection.
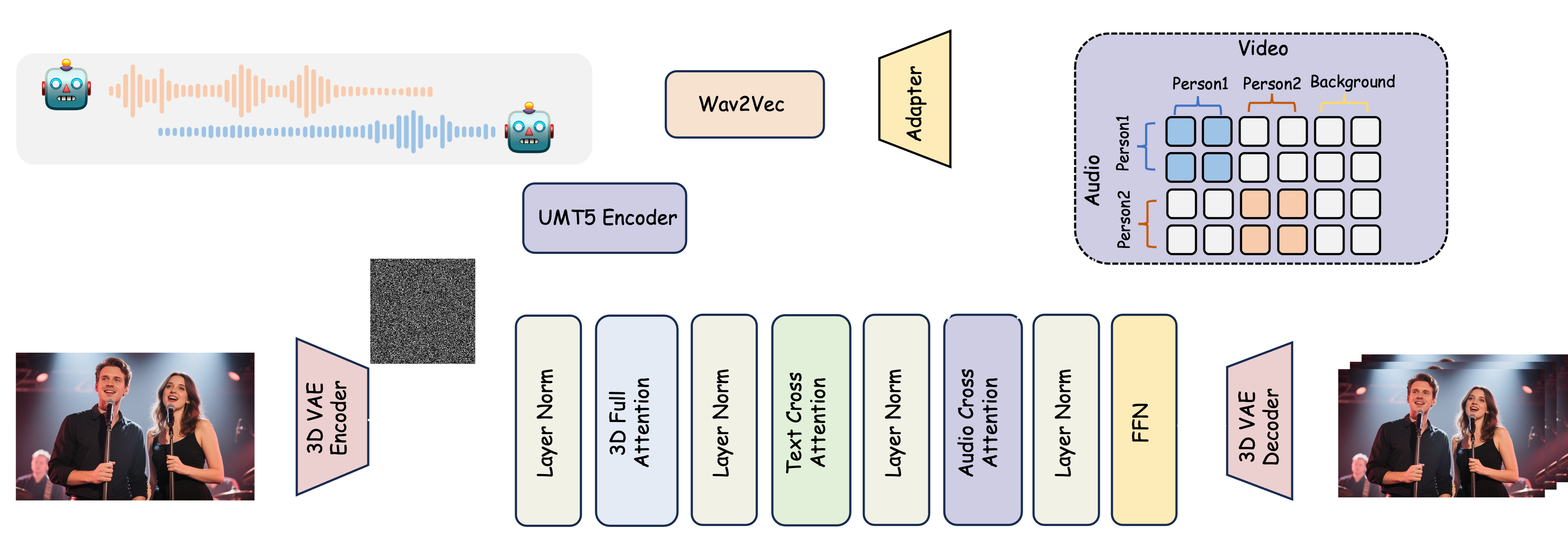

MultiTalk,一个音频驱动的视频生成框架。 我们的框架包含一个额外的音频交叉注意力层来支持音频条件。 为了实现多人对话视频的生成,我们提出了一种用于多流音频注入的标签旋转位置嵌入 (L-RoPE)。