数据可视化——一图胜千言
第04篇:数据可视化——一图胜千言
写在前面:大家好,我是蓝皮怪!前面几篇我们聊了统计学的基本概念、数据类型和描述性统计,这一篇我们要聊聊数据分析中最直观、最有趣的部分——数据可视化。你有没有发现,很多时候一张图胜过千言万语?无论是新闻报道、商业分析,还是朋友圈晒步数,数据可视化都无处不在。今天我们就来聊聊,如何用图表让数据"说话"。
🎯 这篇文章你能学到什么
- 数据可视化的基本概念、发展与作用
- 常见统计图表的类型、适用场景、优缺点和解读方法
- 生活化案例与常见陷阱
- Python可视化代码示例
- 如何用图表讲好数据的故事
1. 从生活说起:为什么要学数据可视化?
你有没有遇到过这些场景:
📈 看新闻时:一张房价走势图让你一秒看懂十年变化。
🍰 点外卖时:饼图显示不同菜品的销量占比,帮你选出"爆款"。
🏃 刷朋友圈时:步数排行榜一目了然,谁最爱运动一看便知。
其实,数据可视化早已渗透到我们生活的方方面面。它能让复杂的数据变得直观、易懂,也能帮助我们发现数据背后的规律和故事。
2. 数据可视化的核心概念与发展
2.1 什么是数据可视化?
数据可视化,就是用图形、图表等视觉手段,把抽象的数据变成直观的信息。它的本质是"让数据说话",帮助我们更快、更准确地理解数据。
2.2 为什么要做可视化?
- 直观表达:一张图能让人秒懂数据全貌。
- 发现规律:图表能揭示数据中的趋势、分布和异常。
- 辅助决策:可视化结果常常是决策的依据。
- 沟通交流:图表是团队、公众沟通的"通用语言"。
2.3 可视化的历史与发展
- 18世纪:最早的统计图表(如威廉·普莱费尔的条形图、折线图、饼图)
- 19世纪:南丁格尔玫瑰图、约翰·斯诺霍乱地图等推动了数据可视化在医学、社会科学的应用
- 20世纪:计算机普及,图表类型和交互方式极大丰富
- 21世纪:大数据、AI、交互式可视化(如Tableau、PowerBI、ECharts、D3.js)成为主流
3. 常见统计图表类型与适用场景
| 图表类型 | 适用数据 | 主要作用 | 优点 | 局限 | 生活例子 |
|---|---|---|---|---|---|
| 条形图 | 分类/分组 | 比较各类别数量 | 直观、易读 | 类别过多时拥挤 | 各城市人口、不同菜品销量 |
| 饼图 | 分类/比例 | 显示各部分占比 | 形象、突出比例 | 类别多时难分辨 | 市场份额、预算分配 |
| 直方图 | 连续/分组 | 展示分布形态 | 反映分布、异常 | 只适合数值型 | 成绩分布、身高分布 |
| 箱线图 | 数值型 | 展示分布特征和异常值 | 显示中位数、离群值 | 不显示分布细节 | 班级成绩、工资分布 |
| 折线图 | 时间序列 | 展示趋势变化 | 反映趋势 | 不适合离散类别 | 股价走势、气温变化 |
| 散点图 | 数值型 | 展示变量关系 | 发现相关性 | 变量多时难读 | 身高与体重、收入与消费 |
| 热力图 | 分组/矩阵 | 展示分布密度 | 直观、对比强 | 需二维分组 | 城市与性别分布 |
| 密度图 | 数值型 | 展示分布平滑曲线 | 细腻、平滑 | 受带宽影响 | 收入分布、消费分布 |
| 分组对比 | 分类+数值 | 多组对比 | 直观对比 | 组数多时拥挤 | 各城市步数对比 |
| 相关性热力图 | 多变量 | 展示变量间相关性 | 一目了然 | 只反映线性相关 | 多指标分析 |
4. 实际案例与可视化代码
这里我们用一组模拟数据,展示不同类型的可视化效果。
4.1 生成示例数据
import numpy as np
import pandas as pd
np.random.seed(42)
n = 300
data = {'性别': np.random.choice(['男', '女'], n, p=[0.52, 0.48]),'城市': np.random.choice(['北京', '上海', '广州', '深圳', '杭州'], n),'年龄': np.random.normal(32, 8, n).round(1),'身高': np.random.normal(168, 8, n).round(1),'月收入': np.random.lognormal(9.2, 0.5, n).round(0),'步数': np.random.poisson(8000, n),'消费': np.random.gamma(2, 2000, n).round(0)
}
df = pd.DataFrame(data)
df['年龄'] = np.clip(df['年龄'], 18, 65)
df['身高'] = np.clip(df['身高'], 150, 190)
4.2 条形图:不同城市样本数量
import matplotlib.pyplot as plt
city_counts = df['城市'].value_counts()
plt.figure(figsize=(7,5))
city_counts.plot(kind='bar', color='skyblue')
plt.title('不同城市样本数量')
plt.xlabel('城市')
plt.ylabel('人数')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
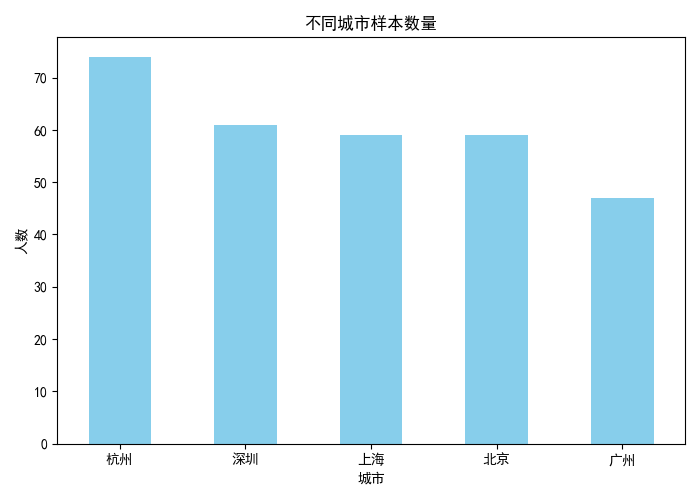
- 条形图适合比较各类别数量,直观反映不同城市的样本分布。
4.3 饼图:性别比例
plt.figure(figsize=(4,4))
df['性别'].value_counts().plot(kind='pie', autopct='%1.1f%%', colors=['lightblue','lightpink'])
plt.title('性别比例')
plt.ylabel('')
plt.tight_layout()
plt.show()
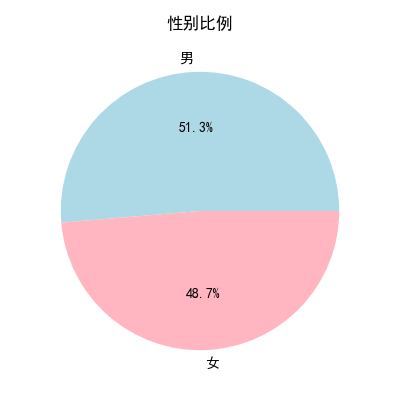
- 饼图突出比例关系,适合展示性别、市场份额等占比。
4.4 直方图:年龄分布
plt.figure(figsize=(7,5))
plt.hist(df['年龄'], bins=15, color='lightgreen', edgecolor='black')
plt.title('年龄分布直方图')
plt.xlabel('年龄')
plt.ylabel('人数')
plt.tight_layout()
plt.show()
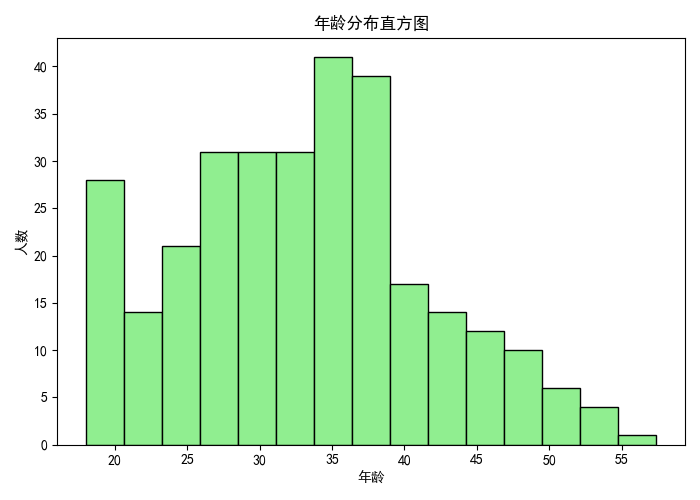
- 直方图反映年龄的分布形态,是否偏态、集中或分散。
4.5 箱线图:身高分布
import seaborn as sns
plt.figure(figsize=(6,5))
sns.boxplot(y=df['身高'], color='gold')
plt.title('身高分布箱线图')
plt.ylabel('身高 (cm)')
plt.tight_layout()
plt.show()
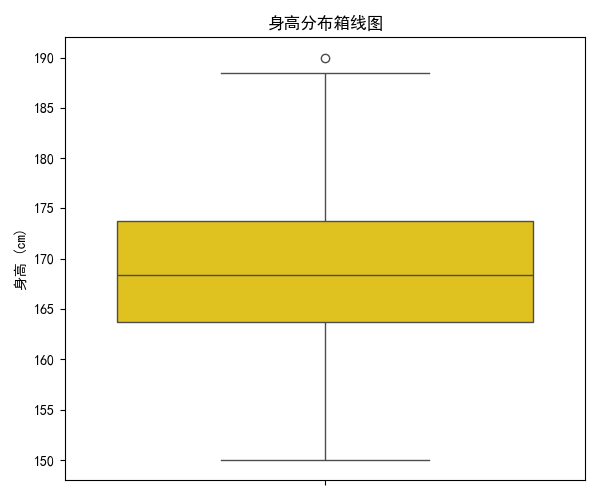
- 箱线图揭示身高的中位数、四分位数和异常值。
4.6 折线图:某城市月收入趋势
months = np.arange(1,13)
city_income = np.random.normal(12000, 2000, 12)
plt.figure(figsize=(7,5))
plt.plot(months, city_income, marker='o', color='orange')
plt.title('某城市月收入趋势')
plt.xlabel('月份')
plt.ylabel('月收入 (元)')
plt.xticks(months)
plt.tight_layout()
plt.show()
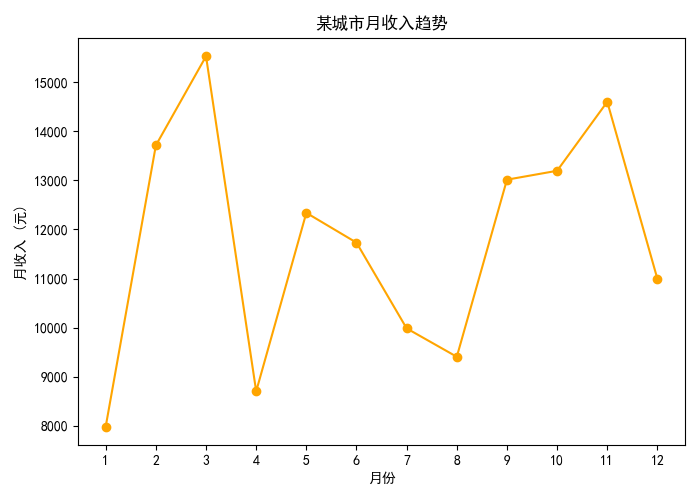
- 折线图适合展示时间序列数据的趋势变化。
4.7 散点图:身高与月收入的关系
plt.figure(figsize=(7,5))
plt.scatter(df['身高'], df['月收入'], alpha=0.6, color='purple')
plt.title('身高与月收入的关系')
plt.xlabel('身高 (cm)')
plt.ylabel('月收入 (元)')
plt.tight_layout()
plt.show()
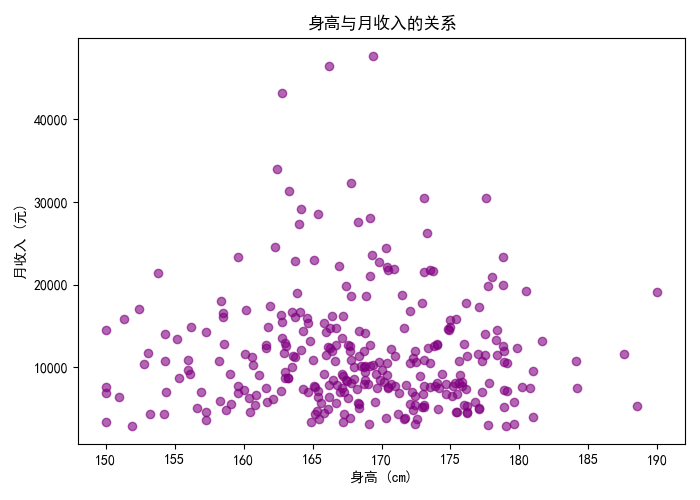
- 散点图揭示变量间的相关性和分布特征。
4.8 热力图:不同城市与性别的样本分布
pivot = pd.crosstab(df['城市'], df['性别'])
plt.figure(figsize=(6,5))
sns.heatmap(pivot, annot=True, cmap='YlGnBu', fmt='d')
plt.title('不同城市与性别的样本分布热力图')
plt.tight_layout()
plt.show()
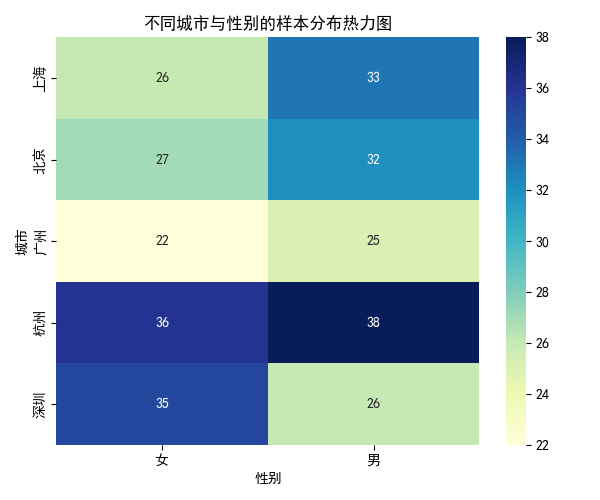
- 热力图适合展示二维分组数据的分布密度。
4.9 密度图:消费分布
plt.figure(figsize=(7,5))
sns.kdeplot(df['消费'], fill=True, color='teal')
plt.title('消费分布密度图')
plt.xlabel('消费 (元)')
plt.tight_layout()
plt.show()
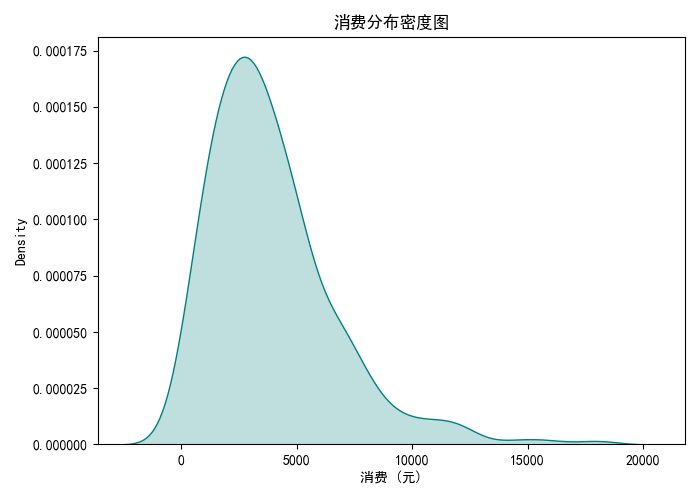
- 密度图平滑展示消费数据的分布形态。
4.10 分组对比箱线图:不同城市步数分布
plt.figure(figsize=(8,6))
sns.boxplot(x='城市', y='步数', data=df)
plt.title('不同城市步数分布箱线图')
plt.xlabel('城市')
plt.ylabel('步数')
plt.tight_layout()
plt.show()
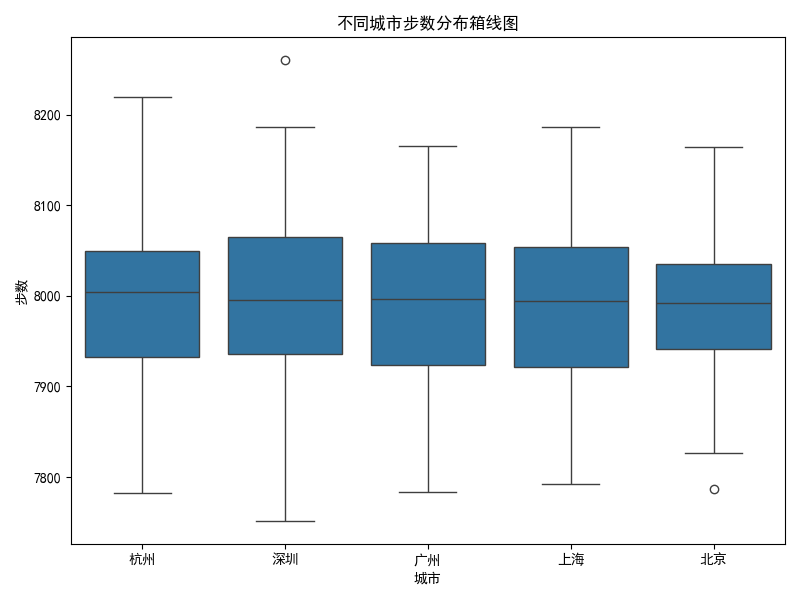
- 分组箱线图适合多组数值型数据的对比。
4.11 相关性热力图:数值变量相关性
corr = df[['年龄','身高','月收入','步数','消费']].corr()
plt.figure(figsize=(7,6))
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt='.2f')
plt.title('数值变量相关性热力图')
plt.tight_layout()
plt.show()
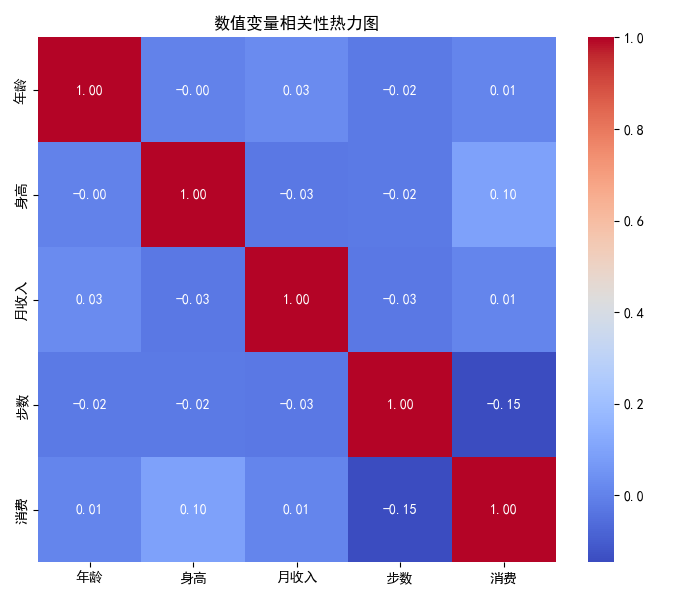
- 相关性热力图一目了然地展示多变量间的线性相关关系。
5. 别被这些误区骗了
❌ 误区1:图越花哨越好
真相:可视化的核心是清晰表达,过度装饰反而干扰理解。
❌ 误区2:图表越多越好
真相:图表不是越多越好,关键是选对、用好。过多的图表反而会分散重点,甚至造成信息干扰。
❌ 误区3:只看图不看数据
真相:图表是辅助理解,关键还是要结合数据本身。
❌ 误区4:图表类型随意选
真相:不同数据类型、分析目的需选用合适的图表。
6. 实际应用建议
- 选对图表类型,别"乱炖"。
- 图表要有标题、坐标轴、单位,必要时加注释。
- 颜色搭配要协调,避免过度花哨。
- 关注数据分布和异常值,别只看均值。
- 代码可复用,建议封装常用绘图函数。
- 结合交互式可视化工具(如Tableau、PowerBI、ECharts、Plotly等)提升分析效率。
7. 练习一下
基础题
- 哪些场景适合用条形图?哪些适合用折线图?
- 饼图和条形图的区别是什么?
- 箱线图能揭示哪些信息?
- 热力图和相关性热力图的区别?
思考题
- 你在生活中见过哪些有趣或误导的数据可视化?
- 如果要展示某公司三年内各部门员工人数变化,应该用什么图?为什么?
- 如何判断散点图中的变量是否存在线性相关?
动手题
- 用Python画出你自己的步数、体重或消费数据的趋势图。
- 用模拟数据画出身高与体重的散点图,并尝试解释相关性。
- 试着用箱线图和密度图对比同一组数据的分布特征。
8. 重点回顾
- 数据可视化让数据"说话",是数据分析的重要环节。
- 常见图表有条形图、饼图、直方图、箱线图、折线图、散点图、热力图、密度图、分组对比图、相关性热力图等。
- 选对图表类型,表达更清晰。
- 图表要关注分布、趋势、异常值。
9. 下期预告
下一篇我们将进入概率的世界,聊聊"概率基础:不确定性的数学"。你将学到:
- 概率的基本概念和计算方法
- 生活中的概率现象
- 概率与统计的关系
- 常见概率误区
概率是理解统计推断的基石,敬请期待!
📚 参考资料
- 吴喜之著《统计学:从数据到结论》,中国统计出版社
- 盛骤等著《概率论与数理统计》,高等教育出版社
- 作者个人学习和实践经验总结
写在最后:如果你觉得这篇文章对你有帮助,欢迎点赞、收藏和分享!有任何问题或建议,欢迎在评论区留言交流,我会认真回复每一条评论。让我们一起用统计学的眼光看世界,一起进步!📊