零基础实战:用 Docker 和 vLLM 本地部署 BGE-M3 文本嵌入模型
沉湎过往,恐惧将来,都不如珍惜眼前。 往昔是烟,明日是雾,当下才是实实在在的生活。
一、BGE-M3 模型
BGE-M3(BAAI General Embedding-M3)是北京智源人工智能研究院(BAAI)推出的多语言、多功能文本嵌入模型,支持稠密检索、稀疏检索和多向量检索三种模式。该模型基于大规模预训练,适用于跨语言语义匹配、信息检索等任务,在 MTEB 等基准测试中表现优异。
二、Docker 与 vLLM 的作用
Docker 提供容器化环境,解决依赖冲突和部署一致性问题,适合快速部署复杂模型。
vLLM 是高效推理框架,针对大语言模型优化,支持高吞吐量推理和显存管理,能加速 BGE-M3 这类大规模模型的本地运行。
三、本地运行的核心优势
- 隐私保护:数据无需上传云端,适合敏感场景。
- 定制化:可调整模型参数或微调以适应特定任务。
- 成本可控:长期使用比云服务成本更低。
此方案适合开发者、研究人员快速验证 BGE-M3 能力,或集成到本地 NLP pipeline 中。
四、Docker 安装与配置
下载并执行 Docker 官方安装脚本:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh# 启动Docker服务
sudo systemctl start docker
sudo systemctl enable docker
配置国内 Docker 镜像源与 GPU:
vim /etc/docker/daemon.json
{"dns": ["8.8.8.8","8.8.4.4"],"registry-mirrors": ["https://docker.m.daocloud.io/","https://huecker.io/","https://dockerhub.timeweb.cloud","https://noohub.ru/","https://dockerproxy.com","https://docker.mirrors.ustc.edu.cn","https://docker.nju.edu.cn","https://registry.docker-cn.com","http://hub-mirror.c.163.com"],"runtimes": {"nvidia": {"args": [],"path": "nvidia-container-runtime"}}
}
五、使用 vLLM 官方 Docker 镜像
vLLM 提供了用于部署的官方 Docker 镜像,该镜像可用于运行与 OpenAI 兼容的服务器,官方示例脚本如下:
docker run --runtime nvidia --gpus all \-v ~/.cache/huggingface:/root/.cache/huggingface \--env "HUGGING_FACE_HUB_TOKEN=<secret>" \-p 8000:8000 \--ipc=host \vllm/vllm-openai:latest \--model mistralai/Mistral-7B-v0.1
官方脚本从 huggingface 下载模型,可能会遇到网络问题,因此我们从 modelscope 下载 bge-m3,对脚本修改一点点细节:
docker run --name bge-m3 -d --runtime nvidia --gpus all \-v ~/.cache/modelscope:/root/.cache/modelscope \--env "VLLM_USE_MODELSCOPE=True" \-p 8000:8000 \--ipc=host \vllm/vllm-openai:latest \--model BAAI/bge-m3 \--gpu_memory_utilization 0.9
这里我们可以使用 ipc=host 标志或 --shm-size 标志来允许容器访问主机的共享内存。vLLM 使用 PyTorch,它在底层使用共享内存来在进程之间共享数据,特别是对于张量并行推理。镜像标签 (vllm/vllm-openai:latest) 之后添加引擎参数 (engine-args)。

六、文本嵌入测试
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
import os# 设置环境变量
os.environ["OPENAI_BASE_URL"] = "http://localhost:8000/v1"
os.environ["OPENAI_API_KEY"] = "EMPTY"# 加载文档
file_path = "../langchain/data/0001.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
print(f"文档页数:{len(docs)} 页")# 切割文档
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100, add_start_index=True
)
all_splits = text_splitter.split_documents(docs)len(all_splits)# 嵌入模型
embeddings = OpenAIEmbeddings(model="BAAI/bge-m3")# 向量存储
vector_store = InMemoryVectorStore(embeddings)
ids = vector_store.add_documents(documents=all_splits)#向量查询
results = vector_store.similarity_search("混凝土"
)print(results[0])
运行效果:

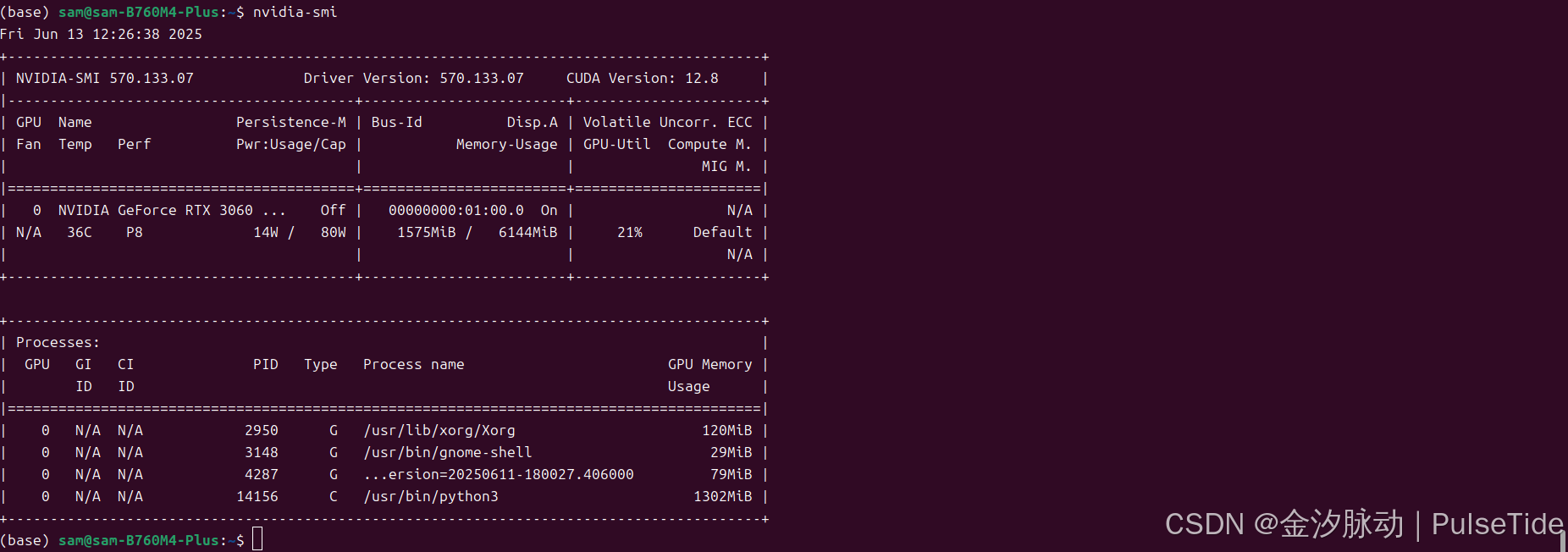
七、GPU 使用情况
nvidia-smi
参考文档
- https://docs.vllm.com.cn/en/latest/deployment/docker.html
- https://modelscope.cn/models/BAAI/bge-m3/summary
- https://www.runoob.com/docker/ubuntu-docker-install.html