2025.6.12 【校内 NOI 训练赛】记录(集训队互测选做)
文章目录
- 【qoj 5020】举办乘凉州喵,举办乘凉州谢谢喵(有根树点分治,树链剖分)
- 【qoj 4893】Imbalance(根本不会题)
- 【qoj 5175】翻修道路(状压,最短路)
- 【qoj 5017】相等树链(点分治,集合 h a s h hash hash,哈希表)
- 【qoj 5097】小 P P P 爱学习(根号分治优化 d p dp dp,计数基本功)
都是好题啊。
比赛得分: 100 + 10 + 100 + 100 + 60 = 370
其中 T4 是我负责改题面造数据的因此之前就过了,考试只不过再交一次。
【qoj 5020】举办乘凉州喵,举办乘凉州谢谢喵(有根树点分治,树链剖分)
题意:
给定一棵大小为 n n n 的树, q q q 次询问,每次给你 ( x i , y i , d i ) (x_i, y_i, d_i) (xi,yi,di),你需要求出距离路径 ( x i , y i ) (x_i, y_i) (xi,yi) 不超过 d i d_i di 的点集大小。
定义一个点与一条路径的距离为点到路径上所有点的距离的最小值。
1 ≤ n , q ≤ 2 × 10 5 , 0 ≤ d i ≤ n 1 \leq n, q \leq 2 \times 10^5, 0 \leq d_i \leq n 1≤n,q≤2×105,0≤di≤n。
分析:
正解是 有根树点分治,但是我考场上写了一个 点分治 + 长剖 + 重剖的思路。下面写一下我的思路:
考虑每次询问满足 x i = y i x_i = y_i xi=yi 怎么做,发现直接点分治即可。复杂度容易做到单 l o g log log。
现在变成了一条路径,设路径两段点的 l c a lca lca 为 u u u,我们将所有点分成两类: u u u 子树内的点(假设以 1 1 1 为根),和 u u u 子树外的点。
发现 u u u 子树外的点到路径的距离一定等于到 u u u 的距离,因此将询问拆到 u u u 上,跑一遍点分治就可以求出这一部分的答案。
对于 u u u 子树内的点,考虑对树进行 重链剖分,那么路径会拆到 log n \log n logn 条重链上,我们发现贡献形如:
- 在每条重链的段首/段尾求出 子树内 距离当前点 ≤ d i \leq d_i ≤di 的点的数量。这里贡献系数可能是负数,因为跳重链时求贡献可能要进行一些容斥。
- 在每段的一个自上到下前缀求出 所有点 的 轻子树内 距离当前点 ≤ d i \leq d_i ≤di 的点的数量。
这样我们就把贡献拆到了 log n \log n logn 个单点求子树内距离当前点 ≤ d i \leq d_i ≤di 的点数 的询问,和 log n \log n logn 个求某条重链上一段点的各自的轻子树中距离当前点 ≤ d i \leq d_i ≤di 的点数。
对于第一个,长剖维护后缀和 即可做到 O ( 1 ) O(1) O(1) 查询,复杂度 O ( n log n ) O(n\log n) O(nlogn) 。
对于第二个,注意到 所有轻子树大小之和为 n log n n\log n nlogn,因此对每条重链从上到下暴力加入一个点的贡献复杂度就是对的。可以将一段 [ l , r ] [l, r] [l,r] 的询问拆成在 l l l 减,在 r r r 加,然后加入一个点轻子树的贡献同样可以 维护后缀和 做到 O ( n log n ) O(n\log n) O(nlogn) 加, O ( 1 ) O(1) O(1) 查。这一部分复杂度也是 O ( n log n ) O(n\log n) O(nlogn)。
实际上点分治也可以通过维护 后缀和 从而避免使用 树状数组,这样也就将复杂度做到了 O ( n log n ) O(n\log n) O(nlogn)。
总复杂度就是 O ( n log n ) O(n\log n) O(nlogn)。
代码很粪但是很清晰,也不难写。
CODE:
#include<bits/stdc++.h>
#define pb emplace_back
using namespace std;
const int N = 2e5 + 10;
int n, q, dep[N], sz[N], fat[N][19];
int big[N], L[N], R[N], ID[N], dfc, Top[N];
int ans[N];
vector< int > E[N];
void dfs0(int x, int fa) {dep[x] = dep[fa] + 1, fat[x][0] = fa; sz[x] = 1;for(int i = 1; i <= 18; i ++ ) fat[x][i] = fat[fat[x][i - 1]][i - 1];for(auto v : E[x]) {if(v == fa) continue;dfs0(v, x); sz[x] += sz[v];if(sz[v] > sz[big[x]]) big[x] = v;}
}
void dfs1(int x, int b) {Top[x] = b; L[x] = ++ dfc; ID[dfc] = x;if(big[x]) dfs1(big[x], b);for(auto v : E[x]) {if(v == fat[x][0] || v == big[x]) continue;dfs1(v, v);}R[x] = dfc;
}
inline int lca(int x, int y) {if(dep[x] < dep[y]) swap(x, y);for(int i = 18; i >= 0; i -- ) if(dep[fat[x][i]] >= dep[y]) x = fat[x][i];if(x == y) return x;for(int i = 18; i >= 0; i -- ) if(fat[x][i] != fat[y][i]) x = fat[x][i], y = fat[y][i];return fat[x][0];
}
struct qry {int d, f, idx; // 距离, 符号, 编号
};
namespace ST { // 子树 长链剖分板子 维护后缀和即可vector< qry > q[N];int *f[N], g[N], son[N], len[N], dfn[N], dfc; // f[x][i] 表示距离 x >= i 的点的数量void dfs0(int x, int fa) {for(auto v : E[x]) {if(v == fa) continue;dfs0(v, x);if(len[v] > len[son[x]]) son[x] = v;}len[x] = len[son[x]] + 1;}void dfs1(int x, int fa) {dfn[x] = ++ dfc;if(son[x]) dfs1(son[x], x); for(auto v : E[x]) {if(v == fa || v == son[x]) continue;dfs1(v, x);}}void dfs2(int x, int fa) {if(son[x]) dfs2(son[x], x);f[x][0] ++;if(son[x]) f[x][0] += f[x][1];for(auto v : E[x]) {if(v == fa || v == son[x]) continue;dfs2(v, x);for(int j = len[v] - 1; j >= 0; j -- ) f[x][j + 1] += f[v][j];f[x][0] += f[v][0];}for(auto v : q[x]) {ans[v.idx] += v.f * (f[x][0] - (len[x] - 1 > v.d ? f[x][v.d + 1] : 0));}}inline void solve() {dfs0(1, 0);dfs1(1, 0);for(int i = 1; i <= n; i ++ ) f[i] = (g + dfn[i]);dfs2(1, 0); // 回答询问}
}
namespace LT { // 轻子树vector< qry > q[N];int cnt[N], len, tmp = 0, tc[N]; // 还是维护后缀和inline void add(int x) {// tmp 现在等于 0for(auto v : E[x]) {if(v == big[x] || v == fat[x][0]) continue;for(int i = L[v]; i <= R[v]; i ++ ) tc[dep[ID[i]] - dep[x]] ++, tmp = max(tmp, dep[ID[i]] - dep[x]);}tc[0] ++; int sum = 0;for(int i = tmp; i >= 0; i -- ) {sum += tc[i];cnt[i] += sum;}len = max(len, tmp);for(int i = 0; i <= tmp; i ++ ) tc[i] = 0; tmp = 0;}inline void solve() { // 对每条重链分别处理for(int i = 1; i <= n; i ++ ) {if(Top[i] == i) { // 找到一个链顶int j = L[i];while(Top[ID[j]] == Top[i]) j ++;j --; // i -> j 是一条链len = 0;for(int k = L[i]; k <= j; k ++ ) {// 先处理减法询问for(auto v : q[ID[k]]) if(v.f == -1) ans[v.idx] += (-1) * (cnt[0] - (len > v.d ? cnt[v.d + 1] : 0));add(ID[k]);for(auto v : q[ID[k]])if(v.f == 1) ans[v.idx] += (cnt[0] - (len > v.d ? cnt[v.d + 1] : 0));}for(int j = 0; j <= len; j ++ ) cnt[j] = 0;}}}
}
namespace CN { // 淀粉质vector< qry > q[N]; // 求所有距离 x <= d 的数量值和int siz[N], Maxn[N], root, all;bool vis[N];inline void get_root(int x, int fa) {siz[x] = 1; Maxn[x] = 0;for(auto v : E[x]) {if(v == fa || vis[v]) continue;get_root(v, x); siz[x] += siz[v];Maxn[x] = max(Maxn[x], siz[v]);}Maxn[x] = max(Maxn[x], all - siz[x]);if(Maxn[x] < Maxn[root]) root = x;}inline void get_sz(int x, int fa) {siz[x] = 1;for(auto v : E[x]) {if(v == fa || vis[v]) continue;get_sz(v, x); siz[x] += siz[v];}}int cnt[N], tc[N], len, tmp;inline void add(int x) {tc[x] ++; tmp = max(tmp, x);}inline void Add() {int sum = 0;for(int i = tmp; i >= 0; i -- ) {sum += tc[i];cnt[i] += sum;}len = max(len, tmp);for(int i = 0; i <= tmp; i ++ ) tc[i] = 0;tmp = 0;}inline void clr() {for(int i = 0; i <= len; i ++ ) cnt[i] = 0;len = 0;}inline void ask(int x, int d) {for(auto v : q[x]) { if(d > v.d) continue;ans[v.idx] += cnt[0] - (len > v.d - d ? cnt[v.d - d + 1] : 0);}}void Ask(int x, int fa, int d) {ask(x, d);for(auto v : E[x]) {if(v == fa || vis[v]) continue;Ask(v, x, d + 1);}}void ins(int x, int fa, int d) {add(d);for(auto v : E[x]) {if(v == fa || vis[v]) continue;ins(v, x, d + 1);}}inline void Sol(int rt) { // 正着加一遍, 反着加一遍vis[rt] = 1;add(0); Add();for(int i = 0; i < E[rt].size(); i ++ ) {int v = E[rt][i];if(vis[v]) continue;Ask(v, rt, 1);ins(v, rt, 1);Add();}clr();for(int i = E[rt].size() - 1; i >= 0; i -- ) {int v = E[rt][i];if(vis[v]) continue;Ask(v, rt, 1);ins(v, rt, 1);Add();}ask(rt, 0);clr();for(auto v : E[rt]) {if(vis[v]) continue;all = siz[v]; root = 0;get_root(v, rt); get_sz(root, 0);Sol(root);}}inline void solve() {all = n; root = 0; Maxn[0] = n + 1;get_root(1, 0);get_sz(root, 0);Sol(root);for(int i = 1; i <= n; i ++ ) {for(auto v : q[i]) ans[v.idx] ++; // 加上 i 这个点}}
}
inline void Set(int x, int y, int d, int idx) {if(x == y) {CN::q[x].pb((qry) {d, 1, idx}); return ;}int lc = lca(x, y);bool f = 0; // lc 是否已经是 "轻子树"while(Top[x] != Top[lc]) {// 链底是 "子树"int p = Top[x];ST::q[x].pb((qry) {d, 1, idx});// 链顶有 "子树"if(d) ST::q[p].pb((qry) {d - 1, -1, idx});// 链底的父亲到链顶是一段轻if(x != p) LT::q[p].pb((qry) {d, -1, idx}), LT::q[fat[x][0]].pb((qry) {d, 1, idx});x = fat[p][0];}if(x != lc) {ST::q[x].pb((qry) {d, 1, idx});LT::q[lc].pb((qry) {d, -1, idx}), LT::q[fat[x][0]].pb((qry) {d, 1, idx});f = 1;}while(Top[y] != Top[lc]) {// 链底是 "子树"int p = Top[y];ST::q[y].pb((qry) {d, 1, idx});// 链顶有 "子树"if(d) ST::q[p].pb((qry) {d - 1, -1, idx});// 链底的父亲到链顶是一段轻if(y != p) LT::q[p].pb((qry) {d, -1, idx}), LT::q[fat[y][0]].pb((qry) {d, 1, idx});y = fat[p][0];}if(y != lc) {ST::q[y].pb((qry) {d, 1, idx});LT::q[lc].pb((qry) {d, -1, idx}), LT::q[fat[y][0]].pb((qry) {d, 1, idx});f = 1;}if(!f) ST::q[lc].pb((qry) {d, 1, idx});CN::q[lc].pb((qry) {d, 1, idx}); // lc 子树外ST::q[lc].pb((qry) {d, -1, idx});
}
int main() {scanf("%d", &n);for(int i = 1; i < n; i ++ ) {int u, v; scanf("%d%d", &u, &v);E[u].pb(v); E[v].pb(u);}dfs0(1, 0);dfs1(1, 1);scanf("%d", &q);for(int i = 1; i <= q; i ++ ) {int x, y, d; scanf("%d%d%d", &x, &y, &d);Set(x, y, d, i);}ST::solve(); LT::solve(); CN::solve();for(int i = 1; i <= q; i ++ ) printf("%d\n", ans[i]);return 0;
}
// 有点粪。
// 考虑单点怎么做, 明显可以淀粉质
// 那么对于一条路径,lca 子树外的点的贡献可以通过淀粉质算 lca 的贡献求出, 需要减去 lca 子树内 <= d_i 的数量
// 那么只需要考虑 lca 子树内的贡献
// 树剖, 那么一条路径会被拆成 log 条重链。 考虑在重链上怎么算贡献呢?发现相当于有 log 个点需要统计 "子树内距离 x <= d_i" 的数量。 有 log 段需要统计 "轻子树内距离 x <= d_i" 的数量
// 对于 log 个点, 离线下来后长剖可以解决。 对于 log 段, 我们不能枚举所有点, 因此考虑变成前缀和相减的形式。由于所有轻子树的大小之和为 nlogn, 所以可以对一个点 x 求出 d(x, c) 表示轻子树中距离 x <= c 的点的数量。 然后对每条重链自上到下求出 d(x, c) 的前缀和, 暴力即可。 最后在每一段的两个端点查询。
// 复杂度: 一个路径有 log 个点, log 段(log 个左右端点)。 维护后缀和,那么查询和添加复杂度都是 nlogn。淀粉治也是单log。。【qoj 4893】Imbalance(根本不会题)
题意:
定义一个 01 01 01 串是平衡的当且仅当它的 01 01 01 个数相同。
给定 n , k n, k n,k 和一个长度为 m m m 的字符串 S S S,求有多少个长度为 n n n 且以 S S S 为前缀的 01 01 01 串满足其不存在长度为 k k k 的平衡子串,答案对 998244353 998244353 998244353 取模。
1 ≤ m + 1 ≤ k ≤ n ≤ 114 1 \leq m + 1 \leq k \leq n \leq 114 1≤m+1≤k≤n≤114 , k k k 为偶数。
分析:
一点不会。鸽了。
【qoj 5175】翻修道路(状压,最短路)
题意:
给定一张 n n n 个点, m m m 条 有向边 的图,第 i i i 条边有两个权值 a i , b i a_i,b_i ai,bi,满足 a i ≥ b i a_i \geq b_i ai≥bi,最初所有边的边权都是 a i a_i ai。
给定 k k k 和 k k k 个互不相同的关键点 p 1 , … p k p_1,\dots p_k p1,…pk,你需要对所有 x ∈ [ 0 , m ] x \in [0, m] x∈[0,m] 都求出:
- 如果最多将 x x x 条边的边权由 a i a_i ai 变为 b i b_i bi,那么 1 1 1 号点到 k k k 个关键点的 最短距离的最大值 最小是多少。
1 ≤ n , m ≤ 100 , k ≤ 8 1 \leq n, m \leq 100, k \leq 8 1≤n,m≤100,k≤8, 1 ≤ b i ≤ a i ≤ 10 5 1 \leq b_i \leq a_i \leq 10^5 1≤bi≤ai≤105。保证从 1 1 1 出发能到达所有关键点。
分析:
称一条边的边权由 a i a_i ai 变为 b i b_i bi 为 翻转 这条边。
如果翻转了哪些边已经知道,那么直接跑一遍 d i j k s t r a dijkstra dijkstra 即可。但是我们不可能 2 m 2^m 2m 枚举所有翻转情况。
有一个显然错误的想法:我们给每条最短路分配一个翻转边数,然后跑 d i j k s t r a dijkstra dijkstra 的时候多记一维状态表示起点到当前点已经翻转了几条边,容易求出所有的 d i s x , c dis_{x, c} disx,c,最后做一遍背包合并所有的 d p p i , c i dp_{p_i, c_i} dppi,ci。
错误原因是 如果有一些翻转边被多条路径共用,那么它只应该被算 1 1 1 次,而不是多次。
考虑哪些边会被多条最短路共用:
设 R i R_{i} Ri 表示翻转边固定时,从 1 1 1 到 p i p_i pi 的最短路径依次经过的点的编号序列。 有结论:
- 一定存在一种对每个关键点选择最短路的方案,使得任意 i ≠ j i \ne j i=j, R i R_i Ri 和 R j R_j Rj 相同的部分都是一段前缀。这个等价于 任意两条路径在某个点发生分岔后,一定不会再都经过同一个点。
证明比较简单:如果它们分岔后又都经过了同一个点,记分叉点为 x x x,相汇点为 y y y,那么就有两条 x → y x \to y x→y 的路径。显然可以把较长的那一条调整成较短的哪一条更优,如果长度相同可以任意选择一条调整成另一条,最后所有路径就满足上述结论了。
有了这个结论就比较可做了:因为两条路径一旦分岔,那么它们接下来翻转的边就不再共用,可以加起来统计数量。
感知这个多条路径依次分岔的过程,可以列出状态:设 f x , c , s f_{x, c, s} fx,c,s 表示起点在 x x x 号点,接下来最多翻转 c c c 条边,你要到达 s s s 集合中的关键点,这些最短路径长度最大值的最小值是多少。那么最后答案就是 f 1 , i , U f_{1, i, U} f1,i,U, U U U 表示全集。
由这些最短路径的形态可知:一定是从当前点 x x x 带着多个目标点走到一个点 y y y,这途中可能翻转一些边,然后在 y y y 将路径分岔,也就是把目标点分成多个部分接着从 y y y 开始做这个过程。我们 d p dp dp 是将这个顺序倒过来,因此转移也分为两类:
- f x , c , S = { f x , c , S ⊕ { x } { x } ⊂ S min S ′ ⊂ S min c ′ = 0 c max ( f x , c ′ , S ′ , f x , c − c ′ , S ⊕ S ′ ) o t h e r w i s e f_{x, c, S} = \begin{cases} f_{x, c, S \oplus \{x\}} & \{x\} \subset S\\ \min\limits_{S' \subset S}\min\limits_{c' = 0}^{c}\max(f_{x, c', S'}, f_{x, c - c', S \oplus S'}) & otherwise \end{cases} fx,c,S=⎩ ⎨ ⎧fx,c,S⊕{x}S′⊂Sminc′=0mincmax(fx,c′,S′,fx,c−c′,S⊕S′){x}⊂Sotherwise
- f x , c , S = min y min c ′ ≤ c ( f y , c ′ , S + d i s ( x , y , c − c ′ ) ) f_{x, c, S} = \min\limits_{y}\min\limits_{c' \leq c}(f_{y, c', S} + dis(x, y, c - c')) fx,c,S=yminc′≤cmin(fy,c′,S+dis(x,y,c−c′))
其中第一个转移是 分岔 的情况,第二个转移是 某些路径共用一些边走到某个点 的情况。
发现第一个转移一定是从 S S S 更小的状态转移过来的,也由此能知道转移的过程:按照 S S S 从小到大依次确定所有 f x , c , S f_{x, c, S} fx,c,S。对于一个 S S S,先进行第一个转移,然后固定 S S S,对前两维状态跑一遍类似 最短路 的过程进行转移,这是因为这个转移是有环的。
但是预处理后暴力进行转移复杂度是: O ( 3 k n m 2 + 2 k ( n m ) 2 ) O(3^knm^2 + 2^k(nm)^2) O(3knm2+2k(nm)2) 的,显然需要优化:
对于第一个转移,发现固定 S ′ S' S′ 后随着 c ′ c' c′ 的增大, f x , c ′ , S ′ f_{x, c', S'} fx,c′,S′ 单调不增, f x , c − c ′ , S ⊕ S ′ f_{x, c - c', S \oplus S'} fx,c−c′,S⊕S′ 单调不降,那么一定存在一个分界点满足在分界点左右 O ( 1 ) O(1) O(1) 个位置取到最优,二分出这个分界点 O ( 1 ) O(1) O(1) 转移即可。 复杂度优化至 O ( 3 k n m log 2 m ) O(3^knm\log_2 m) O(3knmlog2m)。当然也可以双指针做到 O ( 3 k n m ) O(3^knm) O(3knm),我偷懒没写。
对于第二个转移,发现不需要去预处理 d i s ( x , y , c ) dis(x, y, c) dis(x,y,c),这样刻意的枚举 y , c ′ y, c' y,c′ 反而会增大复杂度。实际上这个转移就是对二维状态 ( x , c ) (x, c) (x,c) 不断松弛的结果,因此直接跑 d i j k s t r a dijkstra dijkstra 复杂度就是 O ( m 2 log ( n m ) ) O(m^2\log (nm)) O(m2log(nm)) 的。然后你可以从小到大枚举 c c c 去分层松弛,层与层之间手动转移一遍,然后就可以做到 O ( m 2 log n ) O(m^2 \log n) O(m2logn)。 这一部分复杂度优化至 O ( 2 k n m log n ) O(2^knm\log n) O(2knmlogn)。
总复杂度 O ( 3 k n m log 2 m + 2 k m 2 log n ) O(3^knm\log_2 m + 2^km^2\log n) O(3knmlog2m+2km2logn) 。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 10;
const int M = 105;
int n, m, K, p[N], idx[M];
int f[M][M][1 << 8]; // f[x][c][S] 表示以 x 为起点, 最多还能反转 c 条边, 到 S 这些终点的最大路径的最小值
bool vis[M];
int dis[M];
inline int lowbit(int x) {return x & -x;}
struct node {int x, w;friend bool operator < (node a, node b) {return a.w > b.w;}
};
priority_queue< node > q;
struct edge {int v, last, a, b;
} E[M * 2];
int tot, head[M];
inline void add(int u, int v, int a, int b) {E[++ tot] = (edge) {v, head[u], a, b};head[u] = tot;
}
inline void dij() {memset(vis, 0, sizeof vis);for(int i = 1; i <= n; i ++ ) q.push((node) {i, dis[i]});while(!q.empty()) {node u = q.top(); q.pop();int x = u.x;if(vis[x]) continue;vis[x] = 1;for(int i = head[x]; i; i = E[i].last) {int v = E[i].v, w = E[i].a;if(dis[v] > dis[x] + w) {dis[v] = dis[x] + w;q.push((node) {v, dis[v]});}}}
}
int main() {freopen("universe.in", "r", stdin);freopen("universe.out", "w", stdout);scanf("%d%d%d", &n, &m, &K);memset(idx, -1, sizeof idx);for(int i = 1; i <= K; i ++ ) scanf("%d", &p[i]), idx[p[i]] = i - 1;for(int i = 1; i <= m; i ++ ) {int u, v, a, b; scanf("%d%d%d%d", &u, &v, &a, &b);add(v, u, a, b); // 只建立反向边}memset(f, 0x3f, sizeof f);for(int x = 1; x <= n; x ++ ) for(int c = 0; c <= m; c ++ ) f[x][c][0] = 0;for(int s = 1; s < (1 << K); s ++ ) {for(int x = 1; x <= n; x ++ ) {for(int c = 0; c <= m; c ++ ) {if(idx[x] != -1 && (s >> idx[x] & 1)) f[x][c][s] = f[x][c][s ^ (1 << idx[x])];else {int o = lowbit(s), ts = (s ^ o);for(int _s = ts; ; _s = (_s - 1 & ts)) {// 这个应该可以二分断点int l = 0, r = c, mid, rs = 0;while(l <= r) {mid = (l + r >> 1);if(f[x][mid][_s ^ o] >= f[x][c - mid][ts ^ _s]) rs = mid, l = mid + 1;else r = mid - 1;}f[x][c][s] = min(f[x][c][s], max(f[x][rs][_s ^ o], f[x][c - rs][ts ^ _s]));if(rs < c) f[x][c][s] = min(f[x][c][s], max(f[x][rs + 1][_s ^ o], f[x][c - rs - 1][ts ^ _s]));if(_s == 0) break;}}}}// 下面就是一起走到分散点的转移了// 固定 s, (x, c) <- (y, c')for(int x = 1; x <= n; x ++ ) dis[x] = f[x][0][s];for(int c = 0; c <= m; c ++ ) { dij();for(int x = 1; x <= n; x ++ ) f[x][c][s] = dis[x];if(c == m) break;for(int x = 1; x <= n; x ++ ) dis[x] = min(dis[x], f[x][c + 1][s]);for(int x = 1; x <= n; x ++ ) {for(int i = head[x]; i; i = E[i].last) {int v = E[i].v;dis[v] = min(dis[v], f[x][c][s] + E[i].b); // 反转一次}}}}for(int i = 0; i <= m; i ++ ) printf("%d ", f[1][i][(1 << K) - 1]);return 0;
}【qoj 5017】相等树链(点分治,集合 h a s h hash hash,哈希表)
题意:
给定 2 2 2 棵点集均为 { 1 , 2 , … , n } \{1,2,\dots ,n\} {1,2,…,n} 的树 T 1 , T 2 T_1, T_2 T1,T2。问有多少个点的非空子集 S S S 在 T 1 , T 2 T_1,T_2 T1,T2 上均为一条链。
1 ≤ n ≤ 2 × 10 5 1 \leq n \leq 2 \times 10^5 1≤n≤2×105。
分析:
神仙题,感觉做法涉及到了 点分治 的核心适用条件。
考虑对 T 1 T1 T1 点分治,设当前分治中心为 u u u,如果存在一条链 x → u → y x \to u \to y x→u→y 和 T 2 T2 T2 中的一条链 w → u → z w \to u \to z w→u→z 相同:
不妨认为所有计算的链长度都是 ≥ 2 \geq 2 ≥2 的(等于 1 1 1 的可以特殊处理)。
记 P i ( x , y ) P_i(x, y) Pi(x,y) 表示在 T i T_i Ti 中 x → y x \to y x→y 路径上所有点的编号集合。设 S x = P 1 ( x , u ) / { u } S_{x} = P_1(x, u) / \{u\} Sx=P1(x,u)/{u}, S y = P 2 ( y , u ) / { u } S_y = P_2(y, u) / \{u\} Sy=P2(y,u)/{u}。
可以发现 S x S_x Sx 在 P 2 ( w , z ) P_2(w, z) P2(w,z) 中一定存在最多两个边界满足这两个边界形成的路径完全包含 S x S_x Sx。形式化的,设有 k k k 个边界 a 1 … a k a_1 \dots a_k a1…ak,那么一定满足:
- 1 ≤ k ≤ 2 1 \leq k \leq 2 1≤k≤2
- ∀ i ∈ [ 1 , k ] , a i ∈ S x \forall i \in [1, k],a_i \in S_x ∀i∈[1,k],ai∈Sx
- S x ⊂ ⋃ P 2 ( a i , u ) / { u } S_x \subset \bigcup P_2(a_i, u) / \{u\} Sx⊂⋃P2(ai,u)/{u}
同理,对 S y S_y Sy 也一定存在类似的 t t t 个边界 b 1 … b t b_1 \dots b_t b1…bt。( 1 ≤ t ≤ 2 1 \leq t \leq 2 1≤t≤2)
讨论 w , z w,z w,z 是属于 S x S_x Sx 还是 S y S_y Sy:
- w , z ∈ S x w, z \in S_x w,z∈Sx。那么 S x S_x Sx 的两个边界一定分别是 w , z w, z w,z,因此有 S x ⊕ S y = ⨁ P 2 ( a i , u ) / { u } S_x \oplus S_y = \bigoplus P_2(a_i, u) / \{u\} Sx⊕Sy=⨁P2(ai,u)/{u}。
- w , z ∈ S y w, z \in S_y w,z∈Sy。与上面类似,有 S x ⊕ S y = ⨁ P 2 ( b j , u ) / { u } S_x \oplus S_y = \bigoplus P_2(b_j, u) / \{u\} Sx⊕Sy=⨁P2(bj,u)/{u}。
- w , z w, z w,z 一个在 S x S_x Sx 中, 另一个在 S y S_y Sy 中。那么一定有唯一的 a i a_i ai 取到 w / z w/z w/z,有唯一的 b j b_j bj 取到 w / z w/z w/z,因此有 S x ⊕ S y = P 2 ( a i ′ , u ) ⊕ P 2 ( b j ′ , u ) S_x \oplus S_y = P_2(a_{i'}, u) \oplus P_2(b_{j'}, u) Sx⊕Sy=P2(ai′,u)⊕P2(bj′,u)。
下面就是最核心的一步了:移项!!
我们将只跟 x x x 有关的移到一边,只跟 y y y 有关的移到另一边。那么上面三种情况的式子就变成了:
- S x ⊕ ⨁ P 2 ( a i , u ) / { u } = S y S_{x} \oplus \bigoplus P_{2}(a_i, u) / \{u\} = S_y Sx⊕⨁P2(ai,u)/{u}=Sy。
- S x = S y ⊕ ⨁ P 2 ( b j , u ) / { u } S_{x} = S_y \oplus \bigoplus P_2(b_j, u) / \{u\} Sx=Sy⊕⨁P2(bj,u)/{u}。
- S x ⊕ P 2 ( a i ′ , u ) = S y ⊕ P 2 ( b j ′ , u ) S_{x} \oplus P_2(a_{i'}, u) = S_y \oplus P_2(b_{j'}, u) Sx⊕P2(ai′,u)=Sy⊕P2(bj′,u)。
这样 x , y x, y x,y 的信息就变得独立了。设左边的值为 v x v_{x} vx,右边的为 v y v_y vy ,那么相当于我们要统计出有多少点对满足 v x = v y v_x = v_y vx=vy,这就和正常的点分治要解决的东西类似。
可以设计这样的算法流程:
首先肯定是要对集合 h a s h hash hash 的。开三个 哈希表 分别维护 S x ⊕ P 2 ( a i , u ) / { u } S_x \oplus P_2(a_i, u) / \{u\} Sx⊕P2(ai,u)/{u}, S x S_x Sx, 最多两种 a i a_i ai 下的 S x ⊕ P 2 ( a i ′ , u ) S_x \oplus P_2(a_{i'}, u) Sx⊕P2(ai′,u)。然后对于当前递归到的 y y y,假设我们会快速维护 S y S_y Sy 和 S y S_y Sy 的边界 b j b_j bj,那么在第一个哈希表里查 S y S_y Sy 出现了多少次加入答案中,在第二个表里查 S y ⊕ ⨁ P 2 ( b j , u ) / { u } S_y \oplus \bigoplus P_2(b_j, u) / \{u\} Sy⊕⨁P2(bj,u)/{u},在第三个表里查最多两个 b j ′ b_{j'} bj′ 的 S y ⊕ P 2 ( b j ′ , u ) S_y \oplus P_2(b_{j'}, u) Sy⊕P2(bj′,u)。最后求完分治中心的一棵子树的贡献后把它们加入哈希表中。
考虑这样的过程有什么问题:
发现对于第一种和第二种情况,所有方案都会被统计一次,并且所有被统计进来的一定是合法的方案,因此这一部分算出来的贡献是 充要的。
对于第三种情况,我们发现任意一种合法的方案都只会被统计一次,但是所有被统计进来的一定都合法吗?
发现只有当 P 2 ( a i ′ , u ) P_2(a_{i'}, u) P2(ai′,u) 和 P 2 ( b j ′ , u ) P_2(b_{j'}, u) P2(bj′,u) 仅在 u u u 相交的情况才合法,如果它们的交集大小大于 { u } \{u\} {u},那么是不合法的但是也有可能统计到,比如下面这种:
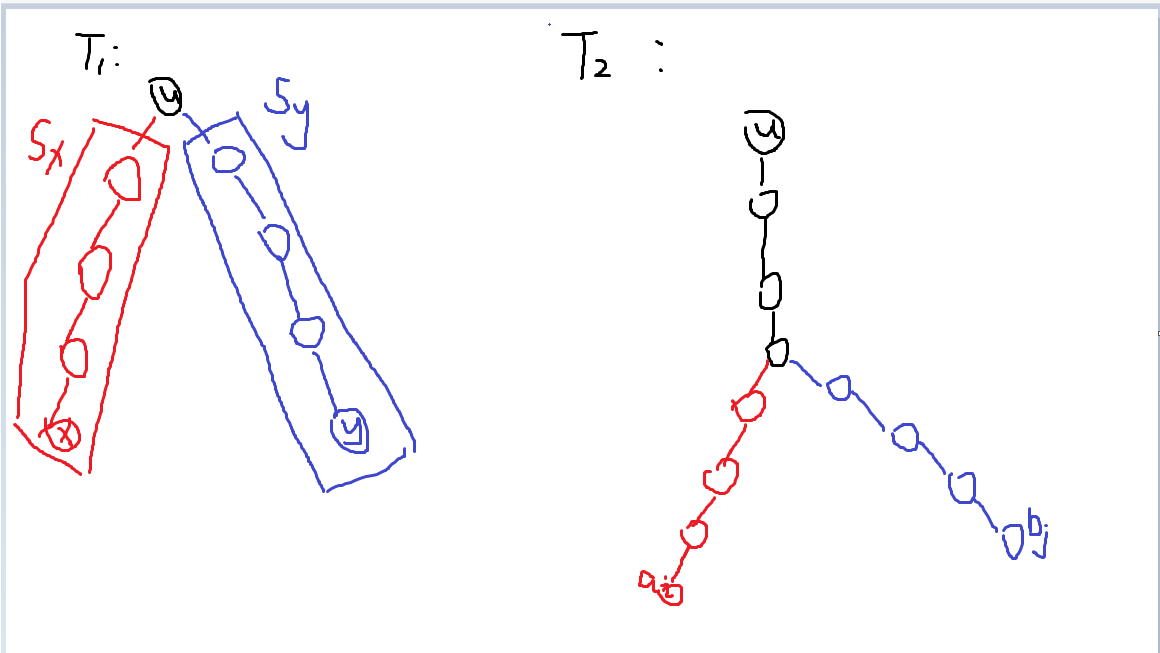
考虑这样的情况有什么特征:设 N ( x , y ) N(x, y) N(x,y) 表示 T 2 T_2 T2 上 x → y x \to y x→y 路径上第一个经过的非 x x x 的点的编号,那么这种不合法但被算到的情况都满足:
- S x ⊕ P 2 ( a i ′ , u ) = S y ⊕ P 2 ( b j ′ , u ) S_{x} \oplus P_2(a_{i'}, u) = S_y \oplus P_2(b_{j'}, u) Sx⊕P2(ai′,u)=Sy⊕P2(bj′,u)。
- N ( u , a i ′ ) = N ( u , b j ′ ) N(u, a_{i'}) = N(u, b_{j'}) N(u,ai′)=N(u,bj′)。
因此我们把第三种情况插入的 h a s h hash hash 值按照 N ( u , a i ′ ) N(u, a_{i'}) N(u,ai′) 分类再重新做一遍上述过程就能算出不合法的数量。
最后一个问题:怎么快速维护 a i a_{i} ai?
发现我们从 f a x fa_{x} fax 递归到 x x x 的时候, S x S_{x} Sx 就等于 S f a x ∪ { x } S_{fa_{x}} \cup \{x\} Sfax∪{x}。也就是我们只需要支持 动态往点集加点,判断点集是否在一条链上,维护点集距离最远的两个点。判断是否在一条链上可以看原来链的两个端点和加入点的距离之间的关系,维护距离最远的两个点也是很好做的。
这样就做完了。总复杂度 O ( n log n ) O(n \log n) O(nlogn)。
总结:
点分治的核心问题在于如何将两条一端为分治中心的链的信息变得独立,以及如何对这些信息建立联系并用合适的数据结构统计。
CODE:
#include<bits/stdc++.h>
#define pb emplace_back
#define MP make_pair
using namespace std;
typedef long long LL;
typedef unsigned long long ull;
typedef pair< LL, int > PII;
const int N = 2e5 + 10;
mt19937_64 rnd(time(0));
ull val[N], w[N], tw[N]; // 异或 hash
int dep[N], pos[N], euler[N * 2], mn[20][N * 2], tot; // O(1) lca
int n, Fa[N][20], fat[2][N], sz[N], Maxn[N], root, all;
bool vis[N];
LL res;
vector< int > G[2][N];
void dfs(int x, int fa) {w[x] = (w[fa] ^ val[x]); euler[++ tot] = x, pos[x] = tot; dep[x] = dep[fa] + 1;for(auto v : G[1][x]) {if(v != fa) dfs(v, x), euler[++ tot] = x;}
}
inline void build_st() {for(int i = 1; i <= tot; i ++ ) mn[0][i] = euler[i];for(int i = 1; (1 << i) <= tot; i ++ ) for(int j = 1; j + (1 << i) - 1 <= tot; j ++ ) mn[i][j] = (dep[mn[i - 1][j]] <= dep[mn[i - 1][j + (1 << i - 1)]] ? mn[i - 1][j] : mn[i - 1][j + (1 << i - 1)]);
}
inline int lca(int x, int y) {int l = pos[x], r = pos[y];if(l > r) swap(l, r);int k = log2(r - l + 1);return (dep[mn[k][l]] <= dep[mn[k][r - (1 << k) + 1]] ? mn[k][l] : mn[k][r - (1 << k) + 1]);
}
inline int dis(int x, int y) {return dep[x] + dep[y] - 2 * dep[lca(x, y)];}
inline ull W(int x, int y) {return (w[x] ^ w[y] ^ val[lca(x, y)]);}
void get_root(int x, int fa) {sz[x] = 1; Maxn[x] = 0;for(auto v : G[0][x]) if(v != fa && !vis[v]) get_root(v, x), sz[x] += sz[v], Maxn[x] = max(Maxn[x], sz[v]);Maxn[x] = max(Maxn[x], all - sz[x]);if(Maxn[x] < Maxn[root]) root = x;
}
void get_sz(int x, int fa) {sz[x] = 1;for(auto v : G[0][x]) if(v != fa && !vis[v]) get_sz(v, x), sz[x] += sz[v];
}
const int mod = 6e6 + 7;
struct Hash { // hash表struct hs {ull v; int cnt, lst;} h[N * 2];int head[mod], use[N * 2], tot = 0, len = 0;inline void ins(ull v) { // 插入int k = v % (1LL * mod); assert(k >= 0 && k < mod);for(int i = head[k]; i; i = h[i].lst) if(h[i].v == v) {h[i].cnt ++; return ;}if(!head[k]) use[++ len] = k;h[++ tot] = (hs) {v, 1, head[k]};head[k] = tot;}inline int cnt(ull v) {int k = v % mod;for(int i = head[k]; i; i = h[i].lst) if(h[i].v == v) return h[i].cnt;return 0;}inline void clr() {for(int i = 1; i <= len; i ++ ) head[use[i]] = 0;len = tot = 0;}
} mp[3], o;
vector< PII > S[N];
vector< int > unio;
vector< int > node[N], A[N]; // 直径端点, 边界端点
inline int Find(int x, int y) { // 找到 y -> x 第一个经过的点int lc = lca(x, y);if(lc != y) return fat[1][y];else {int k = dep[x] - dep[y] - 1;for(int i = 19; i >= 0; i -- ) {if(k >> i & 1) x = Fa[x][i];}return x;}
}
LL calc(int x, int fa, int p, int st, int u) {tw[x] = (tw[fa] ^ val[x]); node[x] = node[fa]; // 加入 xif(node[x].size() < 2) node[x].pb(x);else {int u = node[x][0], v = node[x][1]; node[x].clear();if(max(dis(u, x), dis(v, x)) > dis(u, v)) {if(dis(u, x) > dis(v, x)) node[x].pb(u), node[x].pb(x);else node[x].pb(v), node[x].pb(x);}else node[x].pb(u), node[x].pb(v);}A[x].clear();if(node[x].size() == 1) A[x].pb(node[x][0]);else {int a = dis(node[x][0], u), b = dis(node[x][1], u), c = dis(node[x][0], node[x][1]);if(a > b) swap(a, b);if(b > c) swap(b, c);if(a + b == c) {if(c == dis(node[x][0], node[x][1])) A[x] = node[x];else if(c == dis(node[x][0], u)) A[x].pb(node[x][0]);else A[x].pb(node[x][1]);}}LL res = 0;if(!A[x].empty()) { // 有用的// 分三种情况计算LL nw = ((A[x].size() == 1 ? W(A[x][0], u) : W(A[x][0], A[x][1])) ^ val[u]);if(p == 0) { res += mp[0].cnt(nw ^ tw[x]) + mp[1].cnt(tw[x]);for(int i = 0; i < A[x].size(); i ++ ) res += mp[2].cnt(tw[x] ^ W(A[x][i], u));}else { // 加入mp[0].ins(tw[x]); mp[1].ins(nw ^ tw[x]);for(int i = 0; i < A[x].size(); i ++ ) {mp[2].ins(tw[x] ^ W(A[x][i], u));int anc = Find(A[x][i], u);unio.pb(anc); S[anc].pb(MP(tw[x] ^ W(A[x][i], u), st));}}}for(auto v : G[0][x]) {if(v == fa || vis[v]) continue;res += calc(v, x, p, st, u);}return res;
}
void solve(int rt) {vis[rt] = 1; tw[rt] = 0; node[rt].clear();mp[0].ins(0);for(auto v : G[0][rt]) {if(vis[v]) continue;res += calc(v, rt, 0, v, rt); // 计算calc(v, rt, 1, v, rt); // 加入}for(auto v : unio) { // 减去重复for(int i = 0; i < S[v].size();) {int j = i;while(j < S[v].size() && S[v][j].second == S[v][i].second) j ++;for(int k = i; k < j; k ++ ) res -= o.cnt(S[v][k].first);for(int k = i; k < j; k ++ ) o.ins(S[v][k].first);i = j;}o.clr(); S[v].clear();}for(int i = 0; i < 3; i ++ ) mp[i].clr();unio.clear();for(auto v : G[0][rt]) {if(vis[v]) continue;all = sz[v], root = 0;get_root(v, 0);get_sz(root, 0);solve(root);}
}
int main() {scanf("%d", &n);for(int t = 0; t <= 1; t ++ ) for(int i = 2; i <= n; i ++ ) {scanf("%d", &fat[t][i]);G[t][fat[t][i]].pb(i); G[t][i].pb(fat[t][i]);}for(int i = 1; i <= n; i ++ ) Fa[i][0] = fat[1][i];for(int i = 1; i <= 19; i ++ ) for(int x = 1; x <= n; x ++ ) Fa[x][i] = Fa[Fa[x][i - 1]][i - 1];for(int i = 1; i <= n; i ++ ) val[i] = rnd();dfs(1, 0); build_st();all = n; root = 0; Maxn[0] = n + 1; get_root(1, 0);get_sz(root, 0);solve(root);cout << res + n << endl;return 0;
}
【qoj 5097】小 P P P 爱学习(根号分治优化 d p dp dp,计数基本功)
题意:
给定 n , m n, m n,m 和 n × m n \times m n×m 个非负整数 { a i } \{a_i\} {ai},你需要把它们划分成若干组,并且需要满足每组内正整数的个数都是 m m m 的倍数。一种划分的权值为 每组正整数的和的乘积,你需要求出所有划分的权值和,答案对 10 9 + 7 10^9 + 7 109+7 取模。
两种划分不同当且仅当存在两个下标 i , j i, j i,j 满足在一种划分中 a i , a j a_i,a_j ai,aj 在同一组,另一种划分中不在同一组。
1 ≤ n ≤ 1500 1 \leq n \leq 1500 1≤n≤1500, 1 ≤ m ≤ 100 1 \leq m \leq 100 1≤m≤100, 0 ≤ a i < 10 9 + 7 0 \leq a_i < 10^9 + 7 0≤ai<109+7。
分析:
一种划分的权值形如: ( . . . + b 1 + . . . ) × ( . . . + b 2 + . . . ) × . . . × ( . . . + b k + . . . ) (...+b_1+...) \times(...+b_2+...) \times ... \times (...+ b_k+ ...) (...+b1+...)×(...+b2+...)×...×(...+bk+...)。
将乘积拆开,变成 ∑ ∏ b i \sum \prod b_i ∑∏bi,相当于从每组里面任选一个数求它们的乘积再加起来。
那么我们枚举 S S S,计算 ∏ x ∈ S a x \prod\limits_{x\in S}a_x x∈S∏ax 会被算多少次。它会在 S S S 中的元素被分到不同的组的划分中被计算一次,因此可以设出状态:
f i , j f_{i, j} fi,j 表示当前考虑了前 i i i 个数,当前往 S S S 中选了 j j j 个数的所有乘积的和。
转移就是对 a i + 1 a_{i + 1} ai+1 选或不选分别转移:如果选了就是 f i , j × a i + 1 → f i + 1 , j + 1 f_{i, j} \times a_{i + 1} \to f_{i + 1, j + 1} fi,j×ai+1→fi+1,j+1,不选就是 f i , j → f i + 1 , j f_{i, j} \to f_{i + 1, j} fi,j→fi+1,j。
这样复杂度看起来是 O ( ( n m ) 2 ) O((nm)^2) O((nm)2),但是发现 j j j 这一维的上界是 n n n,因为如果分的组数超过 n n n,不可能满足每组分的个数都是 m m m 的倍数。所以这个 d p dp dp 的转移就是 O ( n 2 m ) O(n^2m) O(n2m)。
我们还需要求出 n m nm nm 个数字分成 i i i 组,每组都有 m m m 的倍数个数,并且每组中都有一个元素是固定的方案数。考虑先忽略所有数的编号,求出每组都有 m m m 的倍数个数的方案数,我们想最后给方案赋上编号,那么就有 i i i 个编号是不自由的,剩下 n m − i nm - i nm−i 个数可以任意排列因此方案数是 ( n m − i ) ! (nm - i)! (nm−i)!。但是这样可能会算重,重复次数就是 ∏ j = 1 i ( c n t j − 1 ) ! \prod\limits_{j = 1}^{i}(cnt_{j} - 1) ! j=1∏i(cntj−1)!,表示每组内乱排的方案数。因此我们 d p dp dp 过程中每分一组就乘上一个 1 ( c n t j − 1 ) ! \frac{1}{(cnt_j - 1)!} (cntj−1)!1 的系数即可。
所以 d p dp dp 就很显然:设 g i , j g_{i, j} gi,j 表示分了 i i i 组,当前用了 j × m j \times m j×m 个数的方案数。转移为:
g i , j = ∑ k = 1 j g i − 1 , j − k × 1 ( k × m − 1 ) ! g_{i, j} = \sum\limits_{k = 1}^{j}g_{i - 1, j - k} \times \frac{1}{(k \times m - 1) !} gi,j=k=1∑jgi−1,j−k×(k×m−1)!1 。
求答案就是 ∑ i = 1 n f i × g i , n × ( n m − i ) ! \sum\limits_{i = 1}^{n}f_{i} \times g_{i, n} \times (nm - i)! i=1∑nfi×gi,n×(nm−i)!。求 g g g 的复杂度 O ( n 3 ) O(n^3) O(n3),还需要优化。
转移是卷积形式,但是模数是 10 9 + 7 10^9 + 7 109+7 因此不能多项式。正解是神秘根号分治优化转移:
我们设阈值 B B B,将组按照元素个数 ≤ B × m \leq B \times m ≤B×m 和 > B × m > B \times m >B×m 分组。
设 g 1 i , j g1_{i, j} g1i,j 表示分了 i i i 个 ≤ B × m \leq B \times m ≤B×m 的组,当前用了 j × m j \times m j×m 个数的方案数。
设 g 2 i , j g2_{i, j} g2i,j 表示分了 i i i 个 > B × m > B \times m >B×m 的组,当前用了 j × m j \times m j×m 个数的方案数。
然后 g 1 g1 g1 转移的复杂度就是 O ( n 2 B ) O(n^2B) O(n2B), g 2 g2 g2 的转移就是 O ( n B n 2 ) O(\frac{n}{B}n^2) O(Bnn2),取 B = n B = \sqrt{n} B=n 得到最优复杂度为 O ( n 2 n ) O(n^2\sqrt{n}) O(n2n)。
求答案只需要枚举 i i i 组里面有 j j j 组的大小 > B × m > B \times m >B×m,以及这 j j j 组用了几个数 p × m p \times m p×m。然后将 g 1 i − j , n − p g1_{i - j, n - p} g1i−j,n−p 和 g 2 j , p g2_{j, p} g2j,p 合并起来,需要乘上一些排列组的系数。求答案的复杂度也是 O ( n 2 n ) O(n^2\sqrt{n}) O(n2n) 的。
总复杂度 O ( n 2 n ) O(n^2\sqrt{n}) O(n2n)。
CODE:
#include<bits/stdc++.h>
using namespace std;
const int N = 1510;
const int C = 151000;
typedef long long LL;
const LL mod = 1e9 + 7;
int n, m, a[C];
namespace Main {inline LL Pow(LL x, LL y) {LL res = 1, k = x;while(y) {if(y & 1) res = res * k % mod;y >>= 1;k = k * k % mod;}return res;}LL g1[N][N], g2[N][N]; // 考虑把组按照物品数量分组: <= B, > B。 g1 为 <= B, g2 为 > B, 均摊 B 取 sqrt{n} 最优 LL fac[C], inv[C], dp[N]; // dp[i][j] 表示考虑到第 i 个物品, 当前选了 j 组的方案 f[i][j] 表示考虑了前 i 个, 当前用了 j 个 m 的方案数void solve() {fac[0] = 1; for(int i = 1; i < C; i ++ ) fac[i] = fac[i - 1] * i % mod;inv[C - 1] = Pow(fac[C - 1], mod - 2); for(int i = C - 2; i >= 0; i -- ) inv[i] = inv[i + 1] * (i + 1) % mod;dp[0] = 1;for(int i = 1; i <= n * m; i ++ ) {for(int j = n; j >= 1; j -- ) {dp[j] = (dp[j] + dp[j - 1] * a[i] % mod) % mod;}}int B = sqrt(n);g1[0][0] = 1; g2[0][0] = 1;for(int i = 1; i <= n; i ++ ) {for(int j = i; j <= min(i * B, n); j ++ ) {for(int k = 1; j - k >= i - 1 && k <= B; k ++ ) {g1[i][j] = (g1[i][j] + g1[i - 1][j - k] * inv[k * m - 1] % mod) % mod;}}}for(int i = 1; i <= n / (B + 1); i ++ ) {for(int j = (B + 1) * i; j <= n; j ++ ) {for(int k = B + 1; k <= j; k ++ ) {g2[i][j] = (g2[i][j] + g2[i - 1][j - k] * inv[k * m - 1] % mod) % mod;}}}LL res = 0;for(int i = 1; i <= n; i ++ ) {LL cnt = 0;for(int j = 0; j <= min(i, n / (B + 1)); j ++ ) {for(int k = j * (B + 1); k <= n; k ++ ) {cnt = (cnt + g2[j][k] * g1[i - j][n - k] % mod * fac[i] % mod * inv[j] % mod * inv[i - j] % mod) % mod;}}res = (res + dp[i] * cnt % mod * fac[n * m - i] % mod) % mod;}cout << res << endl;}
}
int main() {scanf("%d%d", &n, &m);for(int i = 1; i <= n * m; i ++ ) scanf("%d", &a[i]);Main::solve();return 0;
}