AKS升级路线最佳实践方案
前言
Kubernetes 社区大约每 4 个月发布次要版本,次要版本包括新增功能和改进。补丁发布更为频繁(有时每周都会发布),适用于次要版本中的关键 Bug 修复。修补程序版本包括针对安全漏洞或主要 bug 的修复。对于受支持版本列表以外的群集,AKS 将不会在正常运行时间或其他方面做出任何保证。为了使AKS版本始终能获得支持,需要制定计划将AKS升级至受支持版本。在AKS Kubernetes 发布日历(https://learn.microsoft.com/zh-cn/azure/aks/supported-kubernetes-versions?tabs=azure-cli#aks-kubernetes-release-calendar)上参考即将推出的版本发布和弃用事项。
AKS版本升级路径说明
升级受支持的 AKS 群集时,不能跳过 Kubernetes 次要版本。Kubernetes 控制平面版本倾斜策略不支持跳过次要版本。例如,对于以下升级过程:
-
1.28.x ->1.29.x:允许。
-
1.27.x ->1.28.x:允许。
-
1.27.x ->1.29.x:允许。
若要从 1.27.x ->1.29.x 升级,请执行以下操作:
-
从 1.27.x ->1.28.x 升级。
-
从 1.28.x ->1.29.x 升级。
仅当从不受支持的版本升级回受支持的最低版本时,才能跳过多个版本。例如,如果 1.27 是最低受支持的次要版本,可以从不受支持的 1.25.x 升级到受支持的 1.27.x。
从跳过两个或更多次要版本的不支持版本执行升级时,执行升级时不保证任何功能,并且不在服务级别协议和有限保修范围内。运行不受支持的版本的群集具有将控制平面升级与节点池升级分离的灵活性。但是,如果版本明显过期,建议重新创建群集。
AKS升级策略
从 Kubernetes 1.19 开始,开源社区已将支持时间延长到 1 年。AKS 承诺启用修补程序并提供与上游承诺使用量匹配的支持。对于版本 1.19 和更高版本上的 AKS 群集,每年至少升级一次,以便始终使用受支持的版本。
AKS升级将会有什么影响
-
AKS次要版本升级将会更新弃用API,如果在升级AKS前不对弃用API进行处理,两个版本的AKS API不兼容,会造成AKS升级失败和使用弃用API的资源部署失败。已弃用 API 的迁移指南(https://kubernetes.io/zh-cn/docs/reference/using-api/deprecation-guide/)。
-
所有pod将会重启。2024年06月06日国内关闭了docker hub镜像缓存服务,在这期间pod没有重启过的在AKS升级后镜像会丢失,而且无法从docker hub中拉取,从而导致pod拉取镜像失败。
-
没有对节点池预设的labels和Taints在AKS升级后会被清除。
-
会对有依赖性的服务产生影响,需要按照启动的先后顺序重启服务。
升级步骤
升级状态跟踪表
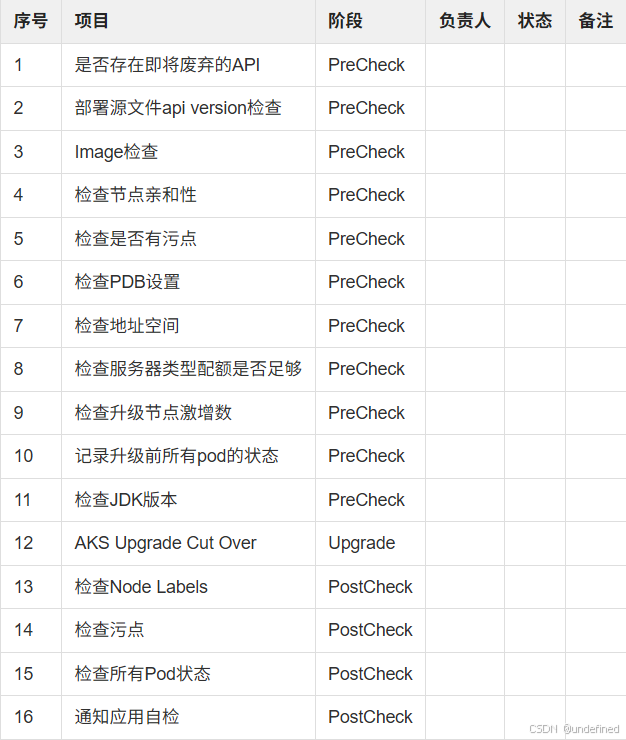
升级路线
例:1.22.6 → 1.27.3 → 1.28.9 → 1.29.4
AKS Upgrade PreCheck
-
在升级前进行AKS现状检查,并进行统计,需要处理的邮件发送至各位Owner及时处理。
-
与客户及涉及到的各个应用沟通时间窗口并安排升级计划。
-
提前发送邮件book需要参与AKS升级的相关人员(应用开发/Cloud Team/SRE Team)的时间。
检查是否存在即将废弃的API
-
微软提供的查询语句
查询query:
AzureDiagnostics
| where Category == "kube-audit"
| where log_s has 'deprecated' and TimeGenerated > ago(1d)
| extend log = parse_json(tostring(parse_json(log_s)))
| extend removed_release = toreal(tostring(log.annotations['k8s.io/removed-release']))
| where removed_release == '1.26' or removed_release == '1.27'
| extend verb = tostring(log.verb)
| extend userAgent = tostring(log.userAgent)
| extend username = tostring(log.user.username)
| extend resource = tostring(log.objectRef.resource)
| extend apiGroup = tostring(log.objectRef.apiGroup)
| extend apiVersion = tostring(log.objectRef.apiVersion)
| extend requestURI = tostring(split(log.requestURI, '?')[0])
| extend source_ip = tostring(log.sourceIPs[0])
| extend api = strcat(apiGroup, '/', apiVersion)
| project TimeGenerated, userAgent, username, api, resource, verb, requestURI, source_ip, Resource
-
命令检查废弃API
例:从 v1.27 版本开始不再提供 storage.k8s.io/v1beta1 API 版本的 CSIStorageCapacity。
$ kubectl get csistoragecapacities.storage.k8s.io -A -o=jsonpath="{$.items[?(@.apiVersion=='storage.k8s.io/v1beta1')].metadata.name}";注意:在AKS升级前,需要为所有可能的中断做好准备。 这些中断包括 API 中断性变更、弃用以及 Helm 和容器存储接口 (CSI) 等依赖项导致的中断。 预测这些中断并在不停机的情况下迁移关键工作负载可能比较困难。可以将 AKS 群集配置为自动停止包含次要版本更改和已弃用 API 的升级操作,并提醒你注意此问题。 此功能有助于避免意外中断,并使你有时间在继续升级之前及时解决已弃用的 API。参考:发生 API 中断性变更时自动停止 Azure Kubernetes 服务 (AKS) 群集升级
检查部署源文件api version
检查部署源文件中的api version,例如helm等,如果存在目标版本即将要废弃的api version,需要在AKS升级前计划修改,在修改前注意检查是否开启资源自动同步。
检查公共Image
-
检查是否存在已经丢失公共镜像源的服务。
-
检查是否存在仍然在使用被自动清除策略删除的镜像。
附:扫描namespace下所有镜像的检查命令
$ kubectl describe pod -n <namespace> | grep Image | awk '{print $2}' | grep -v 'ID' | sort -u检查节点亲和性
检查是否存在有节点依赖的服务。
$ kubectl get deployments.apps -A -o=jsonpath="{$.items[?(@.spec.template.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution)].metadata.name}";
$ kubectl get statefulsets.apps -A -o=jsonpath="{$.items[?(@.spec.template.spec.affinity.deAffinity.requiredDuringSchedulingIgnoredDuringExecution)].metadata.name}";
$ kubectl get deployments.apps -A -o=jsonpath="{$.items[?(@.apiVersion=='apps/v1')].spec.template.spec.nodeSelector}";
$ kubectl get statefulsets.apps -A -o=jsonpath="{$.items[?(@.apiVersion=='apps/v1')].spec.template.spec.nodeSelector}";查看所有节点及labels并记录。
$ kubectl get node --show-labels检查是否有污点
检查节点是否标记有污点并记录。
$ kubectl get nodes -o jsonpath='{range $.items[?(.spec.taints)]}{@.metadata.name} {@.spec.taints}{"\n"}{end}'检查PDB设置
升级前备份并删除PDB,系统PDB除外,否则会导致AKS集群升级失败。
参考:排查由于 PDB 导致的逐出失败而导致的 UpgradeFailed 错误(https://learn.microsoft.com/zh-cn/troubleshoot/azure/azure-kubernetes/create-upgrade-delete/error-code-poddrainfailure)
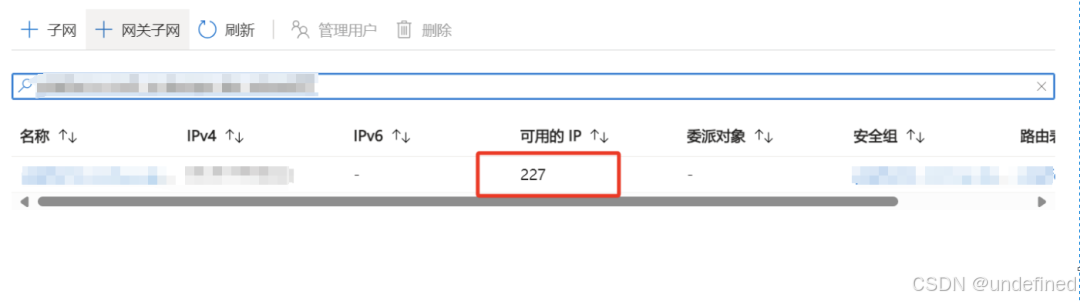
检查地址空间
升级前确认地址空间充足。
打开Azure Portal > Kubernetes 服务 > 设置 - 节点池 > 选择节点池 > 配置 - 子网 > 点击子网 > 复制Subnet并搜索
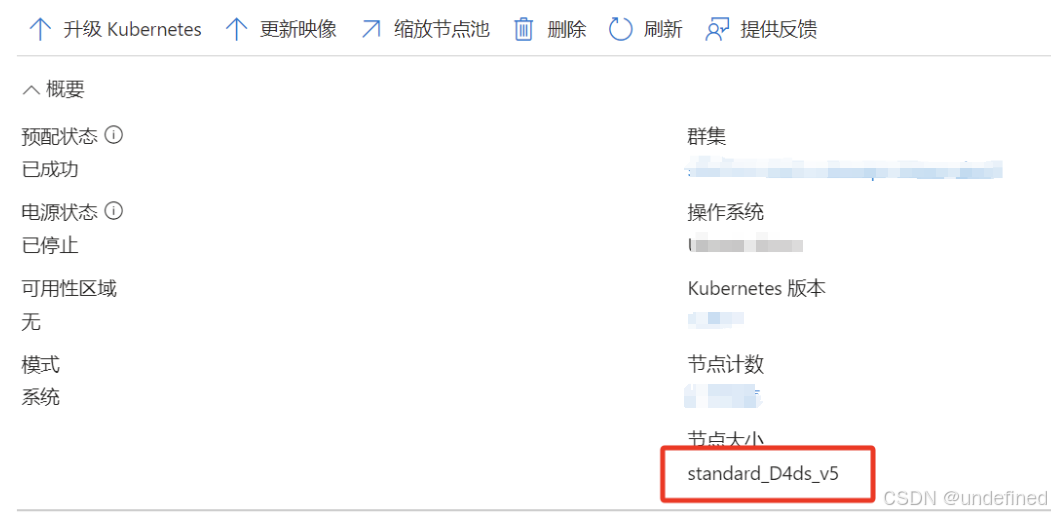
检查服务器类型配额是否足够
查看使用的服务器类型
检查升级节点激增数
$ az aks nodepool show --name <nodePool> --resource-group <resourceGroup> --cluster-name <clusterName> |grep maxSurge设置节点激增数(设置AKS集群升级中同时升级的节点数),一般是按照节点池总数的三分之一或二分之一设置。
# Set max surge for a new node pool
az aks nodepool add --name mynodepool --resource-group MyResourceGroup --cluster-name MyManagedCluster --max-surge 33%# Update max surge for an existing node pool
az aks nodepool update --name mynodepool --resource-group MyResourceGroup --cluster-name MyManagedCluster --max-surge 5检查并记录升级前所有pod状态
升级前记录所有pod状态,在AKS升级完成后作为参考。
检查JDK版本
在AKS升级到1.25版本后,Pod可能由于内存饱和或内存不足而停止工作。
现象:
-
节点上的内存压力
-
与升级前应用的内存使用量相比,增加了应用的内存使用率
-
节点上的 CPU 限制
-
由于 OOM 错误而导致 Pod 失败
在以下环境中运行的应用可能会降低性能:
-
对于 低于版本 11.0.18 或版本 1.8.0 372 的 JRE 版本 ,Java 运行时环境 (JRE) ()
-
低于版本 5.0 的 .NET 版本
-
Node.js
参考:群集升级到 Kubernetes 1.25 后,Pod 中会出现内存饱和
https://learn.microsoft.com/zh-cn/troubleshoot/azure/azure-kubernetes/create-upgrade-delete/aks-memory-saturation-after-upgrade
扫描namespace下所有pod的JDK版本
$ vim show_pods_jdk_version.sh#!/usr/bin/bashfor pod in `kubectl get po -n $1 | awk '{print $1}' | grep -v NAME`doecho $podresult=$(kubectl exec -it -n $1 $pod -- java -version 2>/dev/null)if [[ $? != 0 ]]; thenecho 'no_jdk'elseecho `kubectl exec -it -n $1 $pod -- java -version 2>/dev/null | grep 'openjdk version\|java version'`fidone$ bash show_pods_jdk_version.sh <namespace>
AKS Upgrade Cut Over
Kubernetes服务 > 群集配置 > 升级版本 > 选择下一个次版本 > 保存
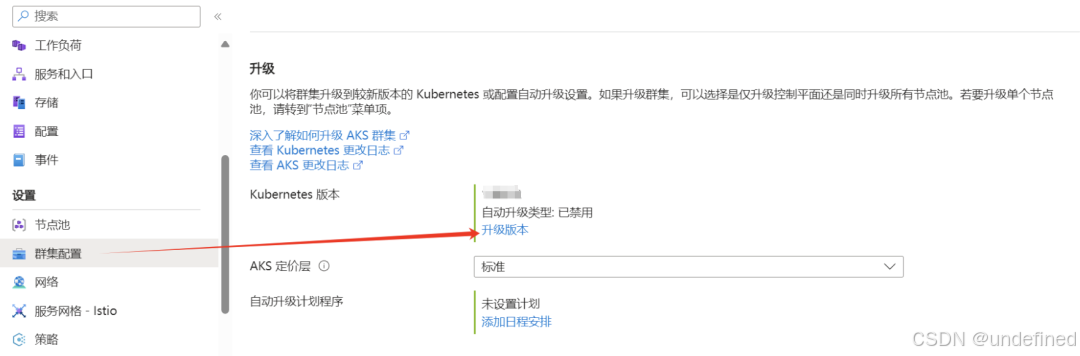
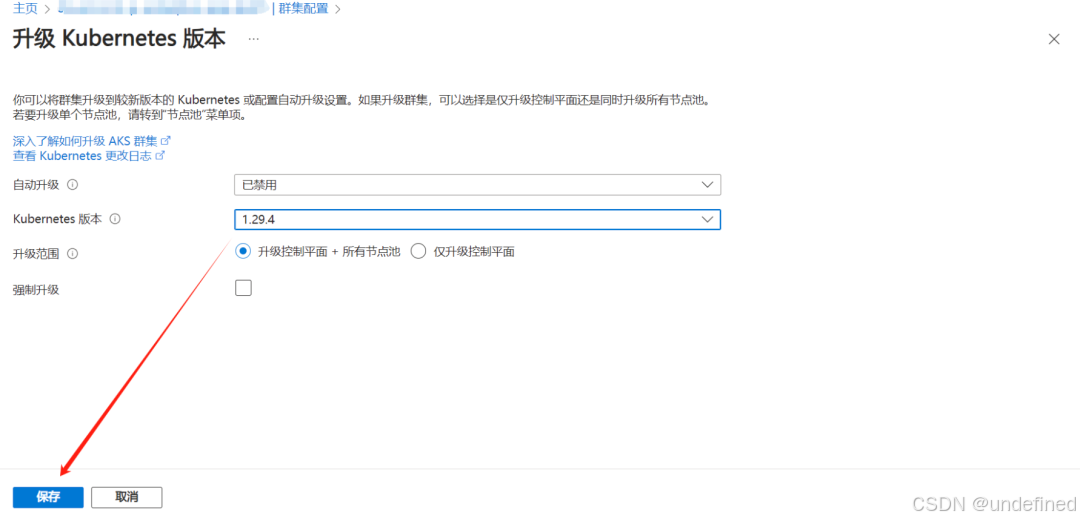
强制升级(可选项)
用户也可以尝试临时性的disable该检查,强制让aks先完成升级。但这就意味着后续升级到新版本之后,用户业务pod可能会直接无法使用(新k8s版本上老旧的api已经下架)
参考:Stop Azure Kubernetes Service (AKS) cluster upgrades automatically on API breaking changes
https://docs.azure.cn/en-us/aks/stop-cluster-upgrade-api-breaking-changes#bypass-validation-to-ignore-api-changes
$ az aks update --name myAKSCluster --resource-group myResourceGroup --enable-force-upgrade --upgrade-override-until 2023-10-01T13:00:00Z //预估的时间窗口AKS Upgrade PostCheck
检查node labels
设置labels
$ kubectl label nodes <node> <key>=<value>检查污点
设置污点
$ kubectl taint nodes <node> <key>=<value>:NoSchedule 检查所有pod状态
对比在PreCheck中记录的pod状态检查,如有问题及时处理。
通知应用自检查
确保所有pod正常启动后检查业务系统状态,更新完成CMDB,并汇总业务的反馈信息做升级报告提交。