梯度下降相关
文章目录
- 梯度下降
- 梯度下降
- 随机梯度下降
- 小批量随机梯度下降
- 对比
- 原始梯度下降的缺陷
梯度下降
梯度下降
- 最简单的迭代求解算法
-
选取开始点 x 0 \mathbf{x}_0 x0,对 t = 1 , … , T t=1, \ldots, T t=1,…,T
x t + 1 = x t − η ∇ f ( x t ) \mathbf{x}_{t+1}=\mathbf{x}_{t}-\eta \nabla f\left(\mathbf{x}_{t}\right) xt+1=xt−η∇f(xt)
η \eta η 叫做学习率
随机梯度下降
- 有 n n n 个样本时,计算 f ( x ) = 1 n ∑ i = 0 n ℓ i ( x ) f(\mathbf{x})=\frac{1}{n} \sum_{i=0}^n \ell_i(\mathbf{x}) f(x)=n1∑i=0nℓi(x) 的导数太贵,一般不用梯度下降
- 随机梯度下降在时间 t t t 随机选项样本 t i t_i ti 来近似 f ( x ) f(x) f(x)
x t + 1 = x t − η t + 1 ∇ ℓ t i ( x t ) E [ ∇ ℓ t i ( x ) ] = E [ ∇ f ( x ) ] \begin{aligned} & \mathbf{x}_{t+1}=\mathbf{x}_{t}-\eta_{t+1} \nabla \ell_{t_i}\left(\mathbf{x}_{t}\right) \\ & \mathbb{E}\left[\nabla \ell_{t_i}(\mathbf{x})\right]=\mathbb{E}[\nabla f(\mathbf{x})] \end{aligned} xt+1=xt−ηt+1∇ℓti(xt)E[∇ℓti(x)]=E[∇f(x)]
小批量随机梯度下降
-
这个基本上是深度学习中真正用的
-
计算单样本的梯度难完全利用硬件资源
-
小批量随机梯度下降在时间 t t t 采样一个随机子集 I t ⊂ { 1 , … , n } I_t \subset\{1, \ldots, n\} It⊂{1,…,n} 使得 ∣ I t ∣ = b \left|I_t\right|=b ∣It∣=b
x t + 1 = x t − η t + 1 b ∑ i ∈ I t ∇ ℓ i ( x t ) \mathbf{x}_{t+1}=\mathbf{x}_{t}-\frac{\eta_{t+1}}{b} \sum_{i \in I_t} \nabla \ell_i\left(\mathbf{x}_{t}\right) xt+1=xt−bηt+1i∈It∑∇ℓi(xt)
b即是batch_size -
同样,这是一个无偏的近似,但降低了方差
E [ 1 b ∑ i ∈ I t ∇ ℓ i ( x ) ] = ∇ f ( x ) \mathbb{E}\left[\frac{1}{b} \sum_{i \in I_t} \nabla \ell_i(\mathbf{x})\right]=\nabla f(\mathbf{x}) E[b1i∈It∑∇ℓi(x)]=∇f(x) -
例子
import torch import torch.nn as nn import matplotlib.pyplot as plt# 1. 准备数据 ,创建一些样本数据 X 和对应的真实标签 y, y = 2*X + 1 + noise, noise是噪音 X = torch.randn(100, 1) * 10 # 100个样本,每个样本1个特征 y_true = 2*X + 1 + torch.randn(100, 1) * 2 # 加上一些噪声# 2. 定义模型,使用线性回归模型 class LinearRegressionModel(nn.Module):def __init__(self):super(LinearRegressionModel, self).__init__()self.linear = nn.Linear(1, 1) # 输入维度为1,输出维度为1def forward(self, x):return self.linear(x)model = LinearRegressionModel()# 打印模型初始化的随机参数 print(f"训练前,随机初始化的权重和偏置: {list(model.parameters())}\n")# 3. 定义损失函数和优化器 learning_rate = 0.001 loss_fn = nn.MSELoss() # 使用均方误差损失 # 使用随机梯度下降 (Stochastic Gradient Descent) optimizer = torch.optim.SGD(model.parameters(), # 自动获取模型中所有需要训练的参数lr=learning_rate, # 学习率)# 4. 训练循环 num_epochs = 10 # 训练迭代次数 # 新增一个列表,用于记录每一次的loss值 all_losses = []for epoch in range(num_epochs):# forwardy_pred = model(X)# 计算lossloss = loss_fn(y_pred, y_true)# 记录lossall_losses.append(loss.item())# -------- 梯度下降三步曲 --------# 4.1. 清零过往梯度optimizer.zero_grad()# 4.2. 计算当前梯度loss.backward()# 4.3. 更新模型参数optimizer.step()# 每50步打印损失信息if (epoch == 0) or ((epoch + 1) % 2) == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')# 5. 查看训练结果 print(f"\n训练后,学习到的权重和偏置,目标权重应接近 [2.],偏置应接近 [1.]:\n {list(model.parameters())}")# 使用训练好的模型进行预测 test_input = torch.tensor([[10.0]]) predicted_value = model(test_input).item() print(f"\n使用训练好的模型预测 x=10 的值,y = {predicted_value:.4f}")# 6. 可视化结果 (新增部分) # 关闭梯度计算,以便进行绘图 with torch.no_grad():# 创建一个 1 行 2 列的画布,设置画布大小fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))# --- 左图:数据散点图和拟合直线 ---ax1.set_title('Data and Regression Line')ax1.set_xlabel('X')ax1.set_ylabel('y')# 绘制原始数据 (X, y_true) 的散点图# .detach() 是为了从计算图中分离张量,.numpy() 是为了转换为numpy数组以供matplotlib使用ax1.scatter(X.detach().numpy(), y_true.detach().numpy(), label='Original Data')# 绘制模型学习到的拟合直线ax1.plot(X.detach().numpy(), model(X).detach().numpy(), color='red', label='Fitted Line')ax1.legend()# --- 右图:Loss下降曲线 ---ax2.set_title('Training Loss')ax2.set_xlabel('Epoch')ax2.set_ylabel('Loss')# 绘制loss随epoch变化的曲线ax2.plot(range(num_epochs), all_losses)# 调整子图布局,防止标题重叠plt.tight_layout()# 显示图形plt.show()"""输出如下""" 训练前,随机初始化的权重和偏置: [Parameter containing: tensor([[-0.3955]], requires_grad=True), Parameter containing: tensor([0.8991], requires_grad=True)]Epoch [1/10], Loss: 584.4702 Epoch [2/10], Loss: 381.5853 Epoch [4/10], Loss: 163.5495 Epoch [6/10], Loss: 71.1610 Epoch [8/10], Loss: 32.0131 Epoch [10/10], Loss: 15.4249训练后,学习到的权重和偏置,目标权重应接近 [2.],偏置应接近 [1.]:[Parameter containing: tensor([[1.7706]], requires_grad=True), Parameter containing: tensor([0.9309], requires_grad=True)]使用训练好的模型预测 x=10 的值,y = 18.6368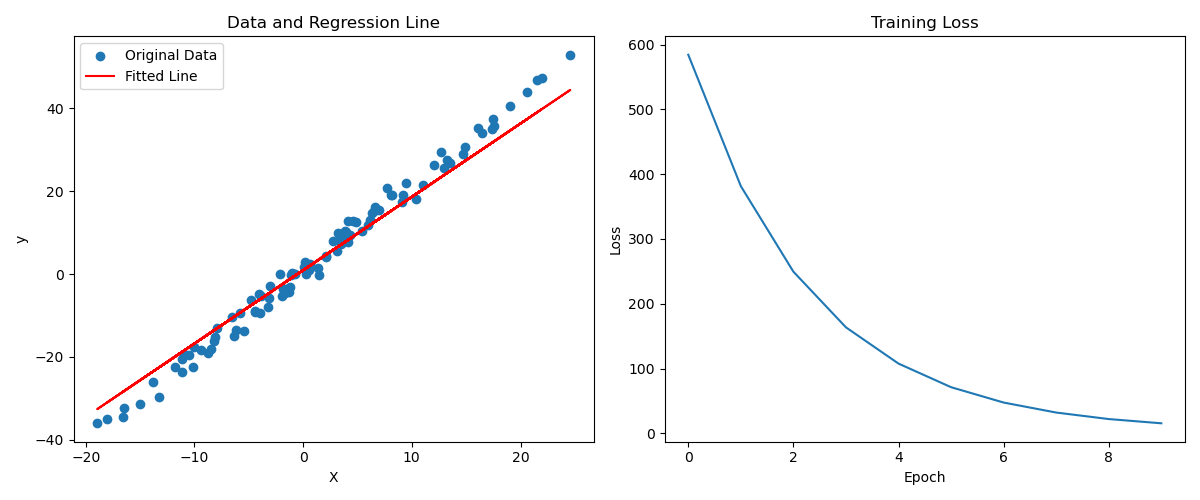
对比
-
下面是各梯度下降的对比
特性 梯度下降 (GD) 随机梯度下降 (SGD) 小批量随机梯度下降 (MB-SGD) 每次更新使用样本数 全部 (m) 单个 (1) 小批量大小 (b), 1<b<m 梯度准确性 精确 (真实梯度) 噪声大 (高方差) 噪声较小 (方差降低) 更新频率 (每epoch) 1 m m/b 单次更新计算成本 高 (O(m⋅d)) 低 (O(d)) 中等 (O(b⋅d)) 每epoch总计算成本 高 (O(m⋅d)) 中等 (m⋅O(d)=O(m⋅d),但串行且低效) 中等 ((m/b)⋅O(b⋅d)=O(m⋅d),但可并行化) 单次更新内存使用 可能较高 (需访问整个数据集) 低 (单个样本) 中等 (小批量样本) 硬件并行化潜力 有限 (受限于单次大规模计算) 差 (本质上是串行的) 好 (可利用向量化/并行计算) 收敛路径 平滑 震荡 比SGD平滑 跳出局部极小点能力 容易陷入 因噪声可能跳出 可能跳出,但概率低于纯SGD -
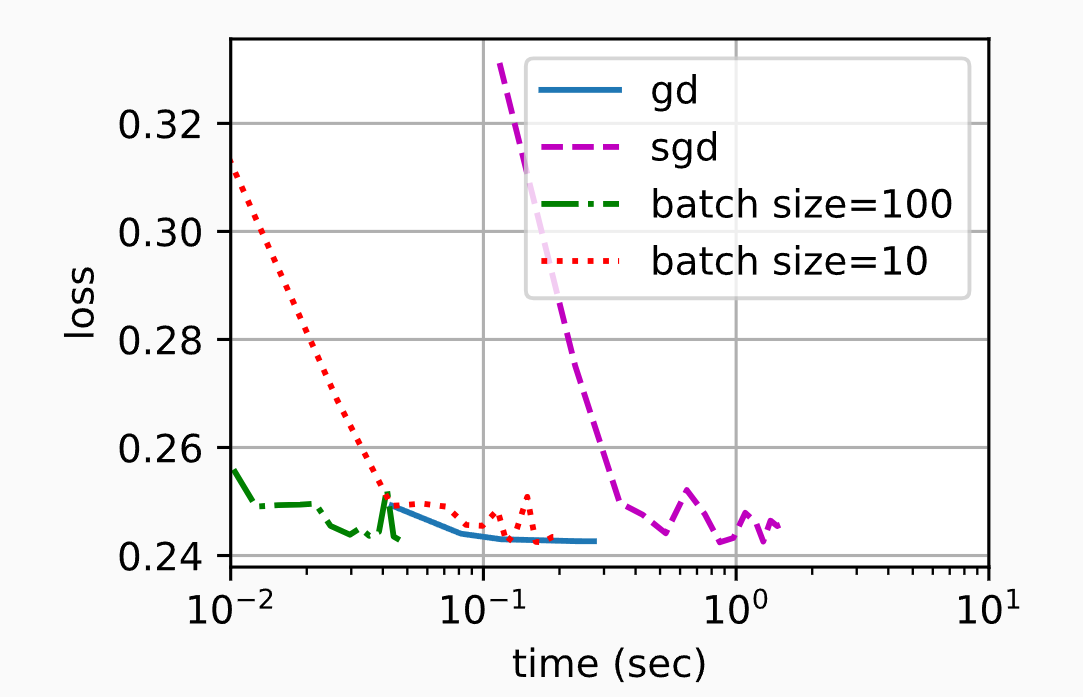
以下的图来自李沐的《动手学深度学习》
可以看出,尽管在处理的样本数方面,随机梯度下降的收敛速度快于梯度下降,但与梯度下降相比,它需要更多的时间来达到同样的损失,因为逐个样本来计算梯度并不那么有效,也没有办法利用硬件资源。 小批量随机梯度下降能够平衡收敛速度和计算效率。 大小为10的小批量比随机梯度下降更有效; 大小为100的小批量在运行时间上甚至优于梯度下降。
原始梯度下降的缺陷
-
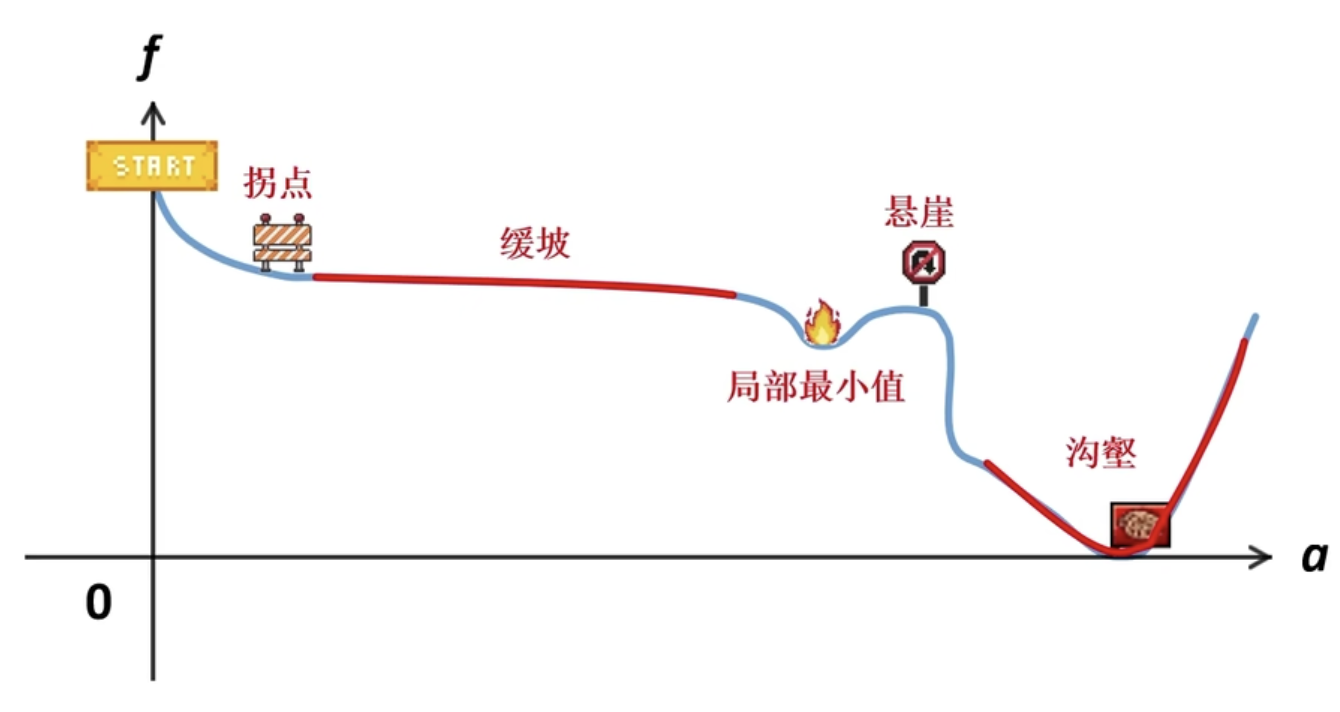
原始梯度下降有以下的缺陷
-
容易陷入拐点,鞍点,停止更新
-
缺乏加速机制,假设“缓坡”斜率为0.001,且我们给一个较大的学习率0.1,那么每一步走0.0001,假设缓坡长度为10个单位,则走完该“缓坡”需要10万步
-
难以跳出局部极小值,即使是一个很小的沟壑,也不一定能跳出
-
无法适应复杂的地形,以下图为例,可能会在悬崖地形中反复横跳,即在目标点和终点之间反复震荡,难以收敛
-
容易产生严重震荡
-
无法自适应调整学习率
-
-
优化
原始梯度下降的公式
x t + 1 = x t − η ∇ f ( x t ) \mathbf{x}_{t+1}=\mathbf{x}_{t}-\eta \nabla f\left(\mathbf{x}_{t}\right) xt+1=xt−η∇f(xt)
我们可以看到每一步梯度更新,与学习率η \eta η和当前梯度∇ f ( x t − 1 ) \nabla f\left(\mathbf{x}_{t-1}\right) ∇f(xt−1) 相关,所以我们可以分别对这两部分进行优化,即以下两种策略:- 对梯度项进行优化
- 对学习率进行优化