面对3倍流量激增,「纽约时报」如何既稳又省?
引言
在这个信息爆炸的时代,一条突发新闻可能会在几分钟内吸引上百万用户同时涌入网站。
作为全球最具影响力的新闻机构之一,《纽约时报》如何应对这样的超高流量冲击?如何有效减少流量高峰期资源配置下的高昂成本?如何在短时间内完成快速弹性伸缩?
本文根据《纽约时报》高级软件工程师 Mel Cone 和 Deepak Goel 在2023年北美 KubeCon 上分享的实践案例整理而成,揭密他们如何以低成本、高效率应对突发新闻带来的流量洪峰。

面临的挑战
突发新闻推送(Breaking News Alert)——即短时间内向用户发送通知,吸引用户进入网页和手机应用,能够瞬间引发流量的激增,一分钟内流量可能增长 2-3 倍。这不是普通的业务高峰,而是带有突发性与不可预测性的“流量地震”。
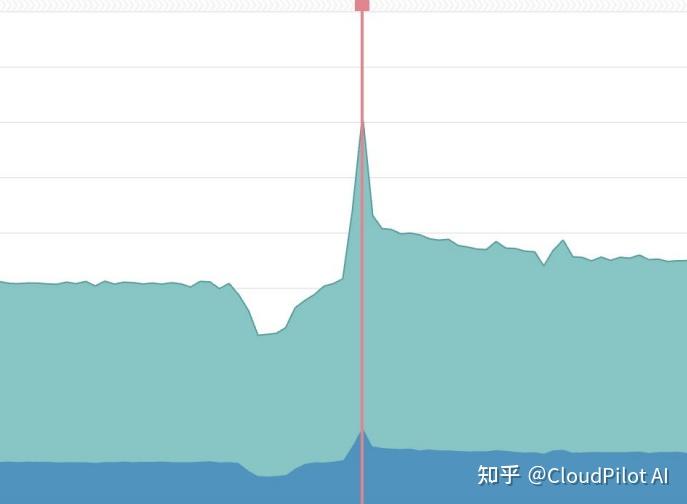
除了突发新闻,还有一些可预测的日常高峰,例如每天某款小游戏上线发布时,也会引发类似的波动——通常会带来 3 倍左右的瞬时访问量。
过去,工程师团队通常简单粗暴地“配置更多资源”来应对这一问题,但这会带来非常昂贵的成本代价和不必要的资源浪费。
因此,《纽约时报》需要一种能快速弹性伸缩的方案,以减少基础设施浪费。
为什么出现流量激增?
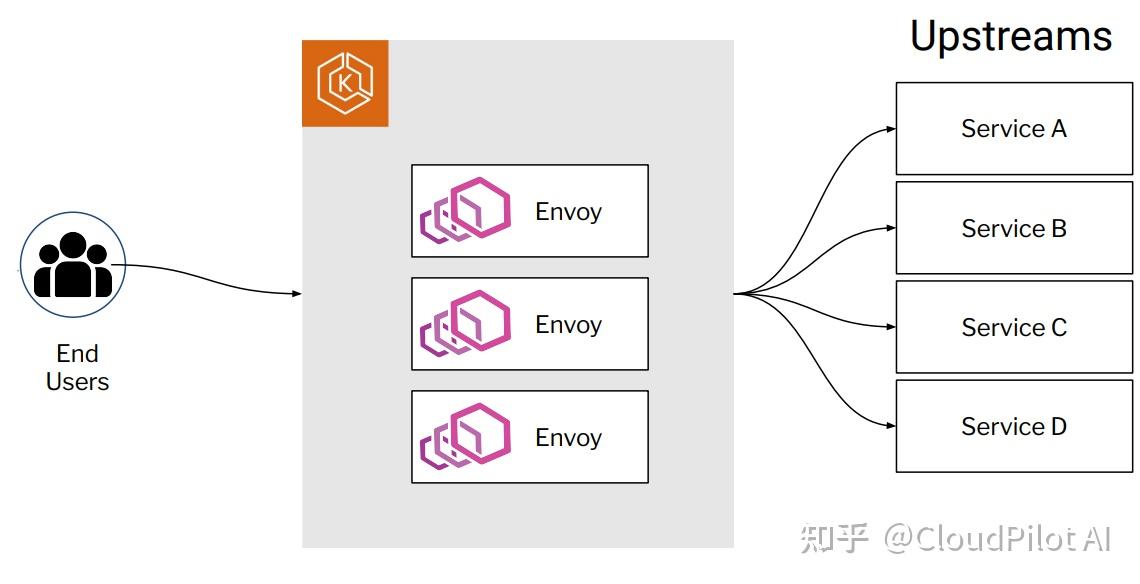
《纽约时报》采用统一的 HTTP Ingress 来处理内外流量,这是一个较新的架构,目标是让所有流量最终都通过 Ingress。
为了让 Ingress 控制器能应对突发新闻推送和游戏发布带来的流量突增,我们经常需要将 Ingress 的副本数扩容 3 倍。
当用户访问《纽约时报》网站或 App 时,请求会先经过 HTTP Ingress,然后被路由到对应的上游服务。
但这些服务通常还需要调用其他内部服务——例如,首页服务会调用关闭服务(Off service)以检查用户是否登录和订阅服务,或调用个性化定制服务,最后再调回首页服务。这种“内部调用链”会进一步增加 Ingress 的流量负担。
多租户架构
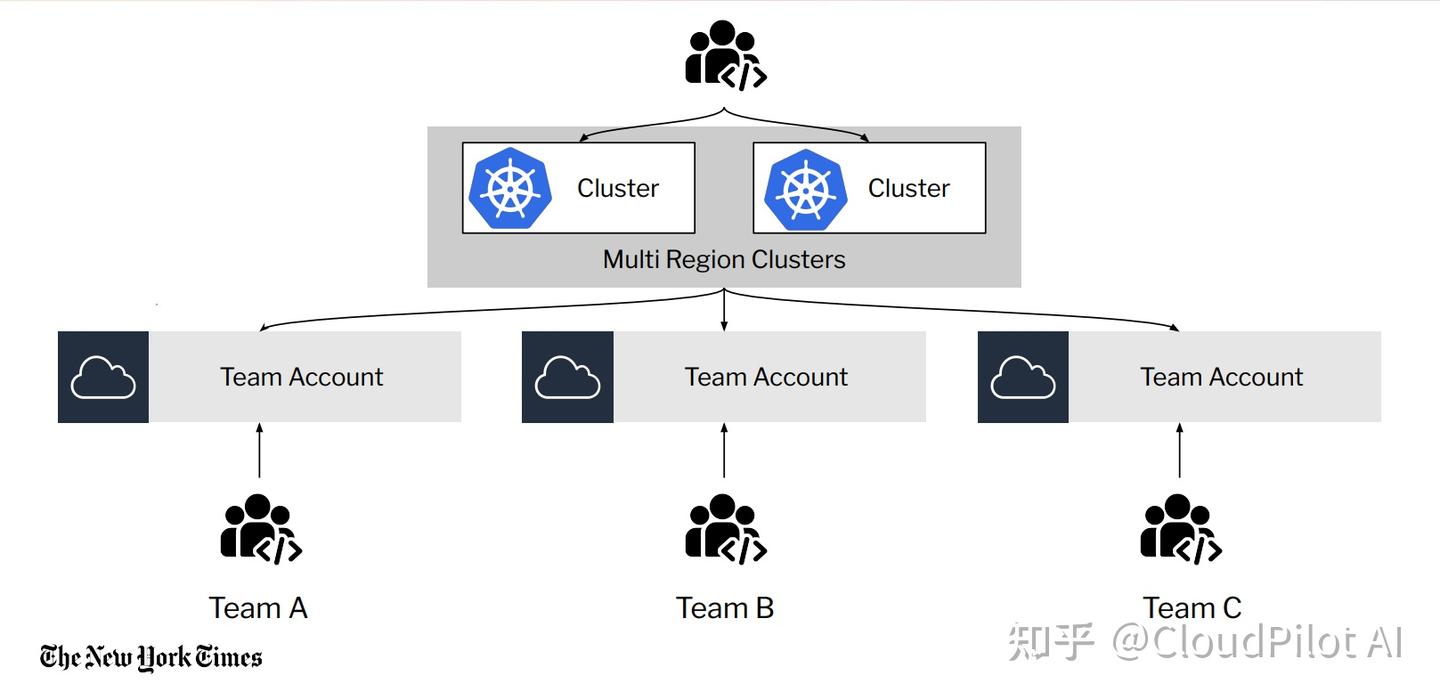
Mel 介绍了《纽约时报》共享平台的一部分,特别是 AWS 上的共享 Kubernetes 集群。
“我们运行的是一个多租户的 Kubernetes 运行时环境,包含部署在多个区域和环境的集群,其中包含一个用于测试变更的沙箱集群。
每个团队都会获得一个租户级别的云账户,同时在开发环境和生产环境的集群中拥有属于该团队的命名空间(Namespace)。
所以每当我们需要进行扩容时,扩容操作往往需要在多个集群之间同时进行。当然,生产环境的扩容规模更大,但其实所有集群都会涉及。”
解决方案
为什么不用 Cluster Autoscaler?
- Karpenter 是原生 Kubernetes 扩展工具,通过 CRD 安装,能无缝集成到现有的 GitOps 工作流。
- Cluster Autoscaler 需要额外维护 Terraform 脚本,每个环境都要单独配置。

Karpenter 的优势
- Pod级调度:通过 Binpack 策略优化节点资源利用率。
- 多实例类型支持:可以指定多种实例类型,Karpenter会自动选择成本最优的选项。
- 节点整合能力(Node Consolidation):当它发现可以用单个更便宜的大节点替代多个小节点时,就会创建新节点并迁移工作负载,这种动态优化能显著降低我们的基础设施成本。
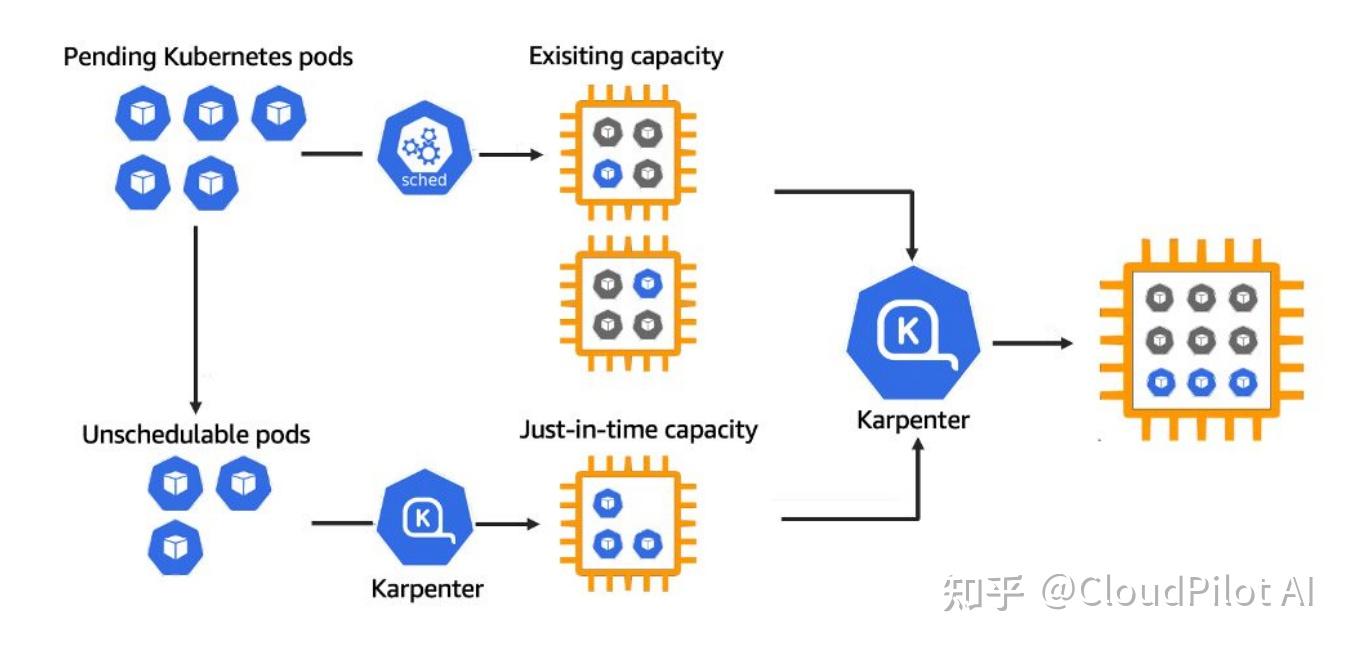
从这张架构图可以看出 Karpenter 的工作原理
- 如果现有节点有足够资源,调度器会直接将这些 Pod 配置到现有节点上;
- 如果没有合适节点,Karpenter就会自动创建新节点
Karpenter 采用无组自动扩展(Groupless Autoscaling)机制,从托管节点组迁移到这种模式时确实有些复杂。
这种模式通过安全组和子网标签来定位资源(Karpenter会添加特定标签来标识资源创建位置),之所以称为“无组”是因为要支持多种实例类型的灵活调度。
我们启用了节点整合功能,这是实现成本优化的主要方式,Karpenter 提供三种整合策略:
- 删除空节点
- 用单个节点替换多个节点(当工作负载可以合并时)
- 用更经济的节点替换现有节点
如何利用 KEDA 实现弹性扩展
什么是 KEDA?
KEDA(Kubernetes-based Event Driven Autoscaler)是一款基于 Kubernetes 的事件驱动型自动扩缩工具。
它能够根据待处理事件的数量,对 Kubernetes 集群中的任意容器实现弹性伸缩。
作为单一功能的轻量级组件,KEDA 可以无缝集成到任何 Kubernetes 集群中。其设计具有以下核心优势:
- 协同工作:与 Horizontal Pod Autoscaler(HPA)等标准 Kubernetes 组件协同工作,通过功能扩展而非覆盖或重复实现。
- 精准控制:支持选择性配置需要事件驱动扩缩的应用,其他应用保持原有运行方式不变。
- 安全兼容:可灵活部署于任何 Kubernetes 环境,与各类应用框架共存互不影响。
Karpenter 与 KEDA 协同工作
以可预测的流量高峰(如新闻定期发布)为例,使用 KEDA 的 Cron 触发器,在预定时间将 Ingress 控制器扩展到指定副本数。虽然 Kubernetes 原生 CronJob 也能实现,但 KEDA 的优势在于:
- 将所有伸缩逻辑集中在一个 YAML 中定义
- 自动管理副本数调整
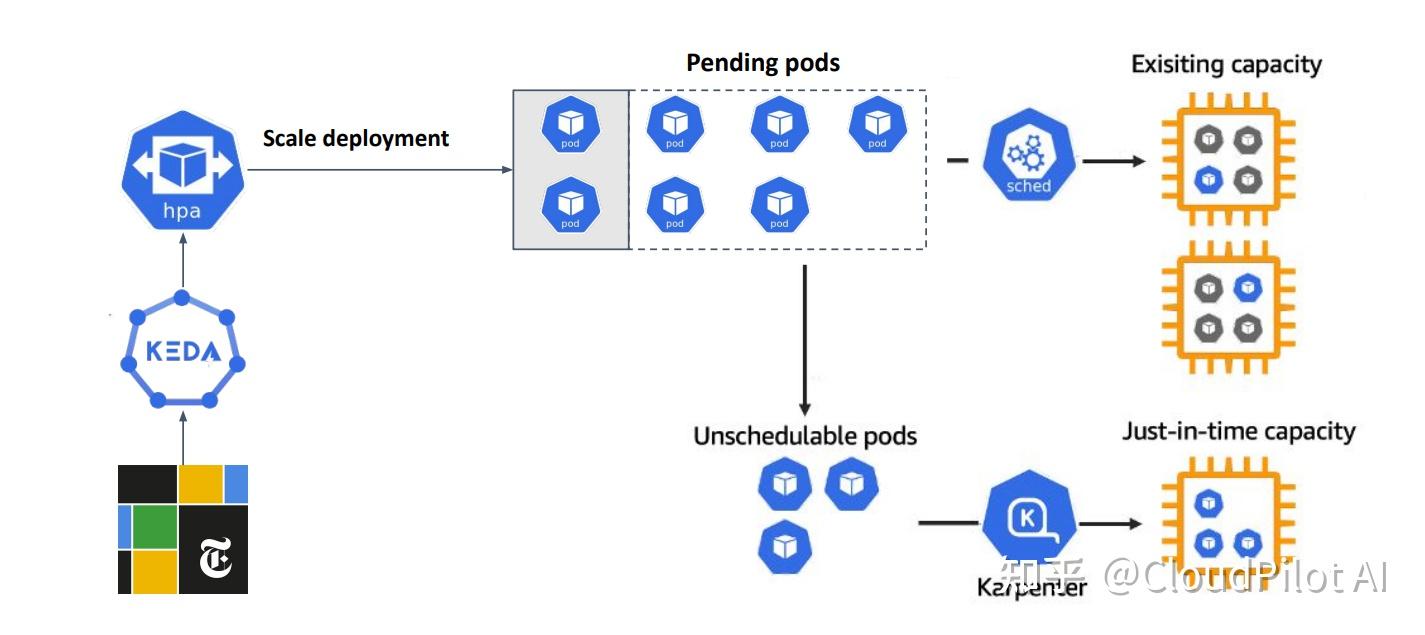
当事件触发时:
- KEDA 先调整 Ingress 控制器副本数(通过修改HPA)
- Karpenter 随后响应,动态调整节点池以满足 Pod 调度需求
- 智能选择最优实例类型
- 事件结束后自动缩容,触发节点合并或删除
外部推送触发机制
接下来我们回到“突发新闻推送”的场景。
我们知道,每当要发送一条突发新闻通知时,我们就需要以某种方式根据这个事件触发扩容。但问题是:这种事件不可预测,不像每天固定时间发生,因此不能使用类似 CronJob 的定时方案。
“KEDA 支持一种叫做外部推送触发器(External Push Trigger) 的机制,所以我们自己搭建了一个服务,用来在发生突发事件时主动向 Karpenter 发出扩容信号。”
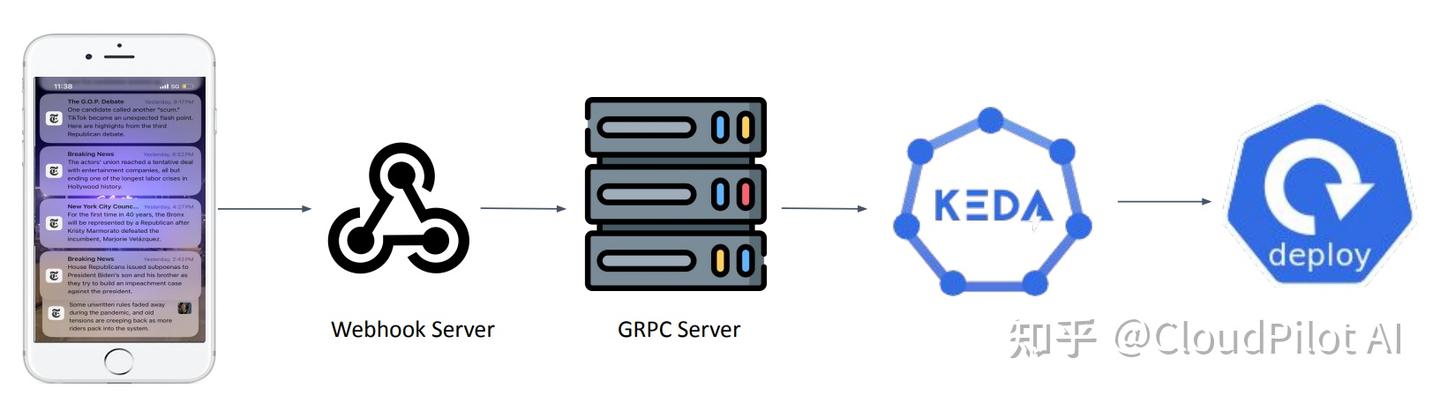
如图所示,整个流程是这样的:
- 首先,一篇文章发布后,我们会发送一条突发新闻通知;
- 接着,发送通知的团队会通过 Webhook 将一个“扩容请求”发送给我们自建的服务;
- 为了让这个机制运作,我们搭建了一个支持 gRPC 的外部服务,KEDA 可以监听它;
- Webhook server 会接收到突发通知事件,然后转发给 gRPC 服务器;
- 一旦 gRPC 服务收到事件,KEDA 就会感知到并立即触发扩容;
整体效果就是:每当一条突发新闻发出,KEDA 就会自动扩容到设定的副本数 X。
通过这种事件驱动的自动伸缩方案,它比定时扩容更灵活,特别适合这种“说来就来”的突发流量场景。
经验总结
通过 KEDA + Karpenter 的组合,我们显著节省了 25% 的云成本,让我们的日常运维轻松了很多,被 Pager 警报叫醒的频率明显减少了。
成本节省效果
我们最初的目标是通过减少过度配置来节省资源成本。不过考虑到突发新闻通知的触发方式,这其实非常困难。

突发新闻通知的“预警时间”其实非常短,只有几秒钟,而实际的流量高峰可能会在 20 到 40 秒内爆发,然后只持续大概两分半钟,但峰值却是非常高。这也意味着:等你刚刚扩容完,差不多就该缩容了。
所以说实话,我们以前依赖的确实是“过度配置”来硬扛。现在虽然还是会这么做,但程度已经大大减少了。
其中一个重要改进就是前面提到的定时扩容(Cron-based scaling),还有就是 Karpenter 本身的智能调度机制。
Karpenter 默认会避免资源合并,也就是说它不会主动合并负载,而是直接选择当前性价比最高的节点类型。这一点非常关键—— 前提是你必须给它提供多种节点类型的选择空间。
如果你只允许它用一种特定的实例类型,那就没得选了:要么是 Spot 实例,要么是按需实例。
我们确实也有一些 Provisioner 是只使用按需实例的,因为那些服务非常关键。
通过 Cron 任务和策略化的资源配置,我们不再需要无意义地预留很多资源,可以根据实际观察到的流量趋势,调整 KEDA 的最大副本数。
构建统一的共享平台
在此之前,各个团队都是自行运行和维护自己的基础设施,这当然很正常,但也导致:
- 配置各异
- 有的靠经验,有的靠习惯,没法横向对比
- 管理优化困难
现在,我们把很多服务统一部署到了共享平台,建立了统一的资源使用标准,因此更容易发现异常和偏离指标的服务,从而快速分析出哪些服务真的需要高负载,哪些是资源使用不合理。
下一步优化方向
以我们统一的 HTTP Ingress 服务为例,因为它对网络和计算的需求都很高,我们目前只能为它配置一种实例类型,并且必须使用按需实例。所以,我们现在还没法在它身上使用 Karpenter,也没有进行节点合并。
但我们已经在探索是否可以增加更多可选节点类型,或者是否能把网络优化型实例换成计算优化型再进一步深入调研其资源使用情况。