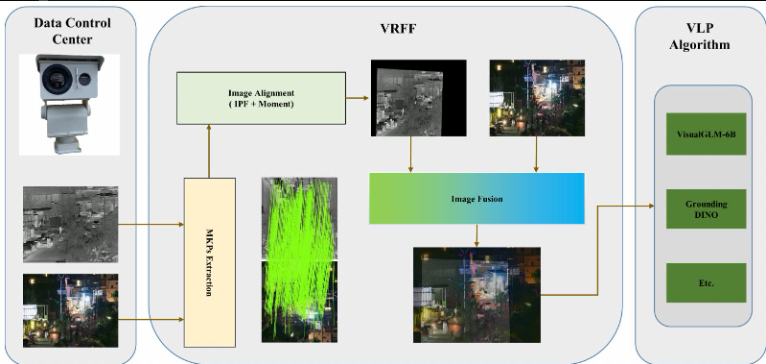
VRFF: Video Registration and Fusion Framework
一、研究背景与问题提出
- 现有技术的局限性:传统图像配准与融合技术直接应用于视频时,存在两大核心问题:
- 闪烁效应:相邻帧变形矩阵差异大,导致融合结果不稳定。
- 关键点匹配不足:极端条件下关键点数量少、准确性低,导致空间对齐错误。
2. 现有挑战
- 关键点匹配难题:现有方法在复杂环境中难以提取足够准确的匹配关键点(MKPs),导致变形矩阵构建错误。
- 时间信息利用不足:图像级方法未考虑视频序列的时间连续性,相邻帧变形矩阵突变引发闪烁。
- 融合视觉效果待提升:现有融合方法对人类视觉敏感的可见光特征保留不足。
- 缺乏专用数据集:现有数据集多为静态图像对,缺乏带时间关系的视频标注。
二、核心方法:VRFF 框架
1. 整体架构
VRFF 基于图像配准与融合框架(IRFF),将流程拆解为关键点提取、图像对齐、图像融合三阶段,并针对视频特性引入时间关系处理策略。

3. 图像融合:UFusion 网络
- 设计思路:基于生成对抗网络(GAN),结合双分支结构与频率分离策略,保留红外高频特征(边缘)和可见光低频特征(纹理)。
- 网络结构:
- 生成器:采用 U 型残差结构,提取深层特征并通过跳跃连接增强细节保留。

- 损失函数:包含对抗损失、SSIM 损失、TV 损失和梯度损失,确保融合图像的视觉真实性与结构完整性。
4. 数据集创新:MMVS
- 构建:基于 FLIR 数据集,手动标注红外 - 可见光视频对齐标签,包含 6 组道路场景视频(早晚 / 夜间)。
- 作用:为视频级配准与融合提供带时间关系的评估基准。
三、实验验证
1. 实验设置
- 关键点提取:以 MatchFormer 为骨干,通过 CPSTN 框架重训练(CPSTN-M),提升红外图像关键点提取能力。
- 评估指标:
- 对齐质量:MSE、NCC、LNCC(衡量红外与可见光对齐精度)。
- 融合效果:AG、SF、EN、MS-SSIM(评估融合图像的细节、对比度等)。
- 对比方法:ReDFeat、LoFTR、MatchFormer、DenseFuse、U2Fusion 等 10 余种现有技术。

四、创新点总结
- 框架创新:提出首个针对视频流的配准与融合框架 VRFF,解决图像方法直接应用于视频的闪烁问题。
- 时间关系处理:IPF 策略与 Moment 算法结合,利用视频时序信息提升关键点数量和变形矩阵稳定性。
- 融合网络设计:UFusion 通过双判别器分离高频 / 低频特征,兼顾红外显著性与可见光视觉舒适性。
- 数据集贡献:构建 MMVS 数据集,为视频级多模态融合提供标准化评估基准。
ATGAN 更为适合;如果你更关注全局融合质量、生成图像的真实性和平衡性,DDCGAN 会是一个更稳健的选择。