目标检测——YOLOv12算法解读
论文:YOLOv12: Attention-Centric Real-Time Object Detectors (2025.2.18)
作者:Yunjie Tian, Qixiang Ye, David Doermann
链接:https://arxiv.org/abs/2502.12524
代码:https://github.com/sunsmarterjie/yolov12
YOLO系列算法解读:
YOLOv1通俗易懂版解读、SSD算法解读、YOLOv2算法解读、YOLOv3算法解读、YOLOv4算法解读、YOLOv5算法解读、YOLOR算法解读、YOLOX算法解读、YOLOv6算法解读、YOLOv7算法解读、YOLOv8算法解读、YOLOv9算法解读、YOLOv10算法解读、YOLO11算法解读、YOLOv12算法解读
PP-YOLO系列算法解读:
PP-YOLO算法解读、PP-YOLOv2算法解读、PP-PicoDet算法解读、PP-YOLOE算法解读、PP-YOLOE-R算法解读
R-CNN系列算法解读:
R-CNN算法解读、SPPNet算法解读、Fast R-CNN算法解读、Faster R-CNN算法解读、Mask R-CNN算法解读、Cascade R-CNN算法解读、Libra R-CNN算法解读
文章目录
- 1、算法概述
- 2、YOLOv12算法细节
- 2.1 区域注意力机制Area Attention
- 2.2 残差高效聚合网络Residual Efficient Layer Aggregation Networks
- 2.3 整个YOLO网络结构优化
- 3、代码解析
- 4、实验
1、算法概述
虽然现如今自注意机制在建模能力方面具有优势,但在速度方面仍然不能和传统CNN结构相比,所以以往的YOLO结构都专注于利用CNN进行改进,而YOLOv12的作者提出利用自注意力机制对YOLO结构进行优化。相比于之前YOLO系列以及DETR系列,在推理速度、COCO数据集上mAP及Flops数量上都具有优势。如下图所示:
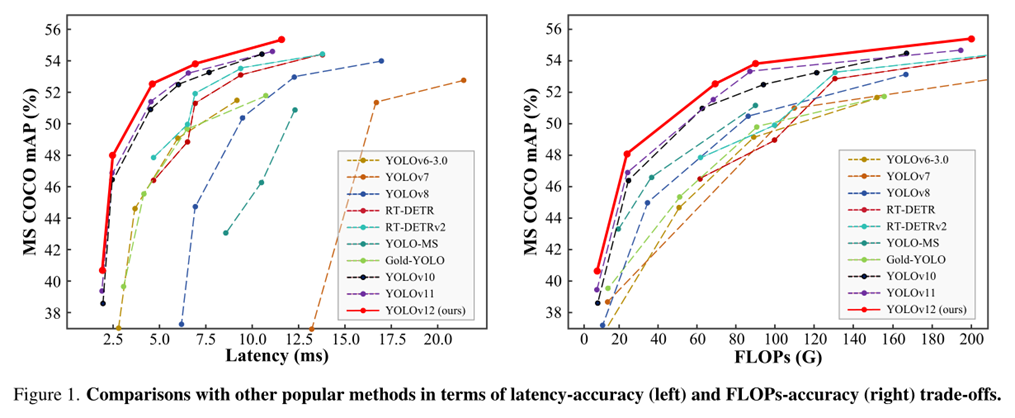
YOLOv12主要改进有如下几点:
1、 提出了区域注意力模块(area attention module, A2),在保持较大感受野的前提下减少了计算复杂度。
2、 引入残差高效聚合模块(residual efficient layer aggregation networks, R-ELAN)解决训练过程中注意力优化问题。它是基于YOLOv7中的ELAN模块进行了两点改进:(1)、block级别的缩放加残差连接;(2)、重新设计的聚合方式。
3、 基于整个YOLO架构也做了些优化改进,包括:引入flashattention、去除位置编码引入可分离卷积、调整MLP比率并用卷积替换全连接、减少堆叠块的数量。
2、YOLOv12算法细节
YOLO12网络结构如下所示
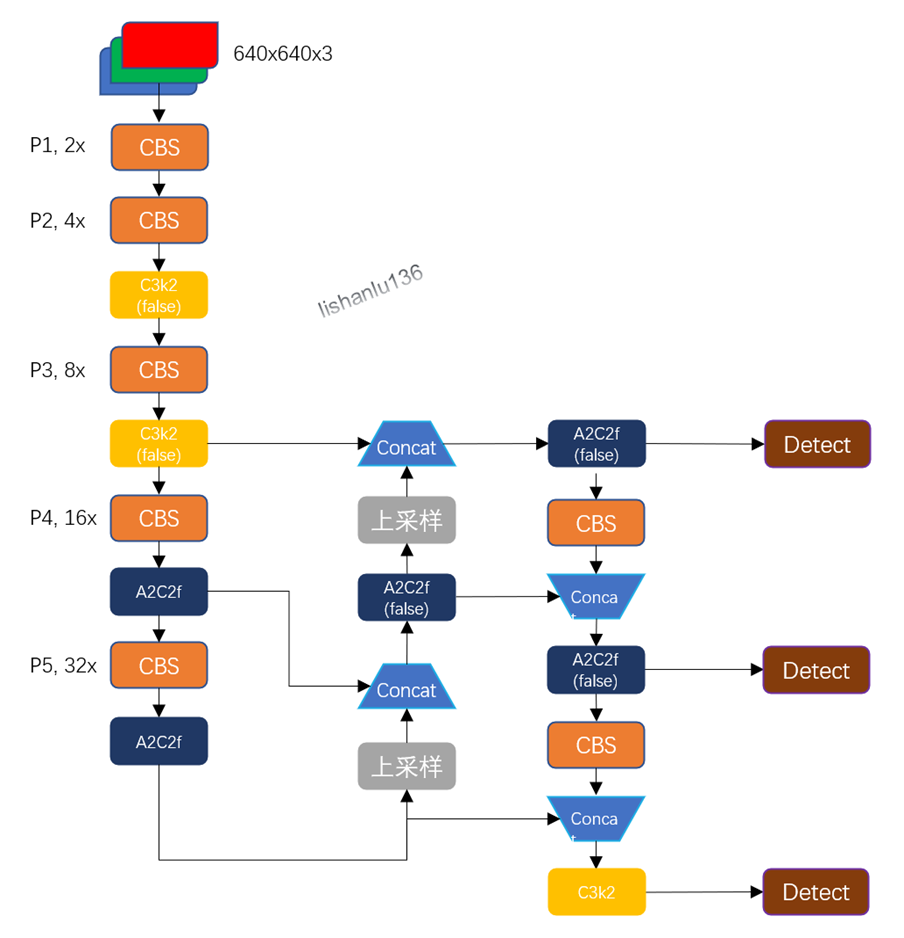
YOLOv12是基于ultralytics开发的,对比YOLO11的yaml配置文件,可以看出两者的不同之处。左边为YOLO11,右边为YOLOv12。
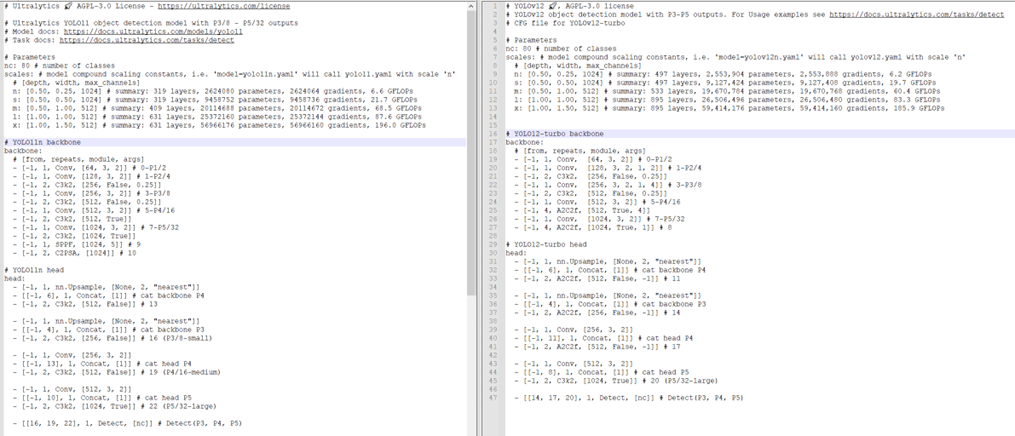
可以看到,在backbone中,YOLOv12将YOLO11中最后两个C3k2替换成了新提出的A2C2f,并且去掉了SPPF和C2PSA模块。而在head中,除了最后一个C3k2,也是将YOLO11中其余的C3k2替换成了A2C2f。
2.1 区域注意力机制Area Attention
图像自注意力(self-attention)天生就比CNN慢,这由下面两个因素造成的,复杂度和计算方式。
自注意机制运算的计算复杂度与输入序列长度L成二次关系,所以对于高分辨率图像或者长序列来讲,复杂度会成倍增加,再加上图像切块操作和位置编码等额外操作也会增加整体耗时。自注意力机制在计算过程中会需要比CNN计算更大的显存来缓存注意力图(QK矩阵)和softmax图(LxL)。由于二次方计算复杂性和低效的内存访问这两个因素,共同导致自注意力机制比CNN慢。所以很多研究者提出了对自注意力机制计算的优化,如下图所示。
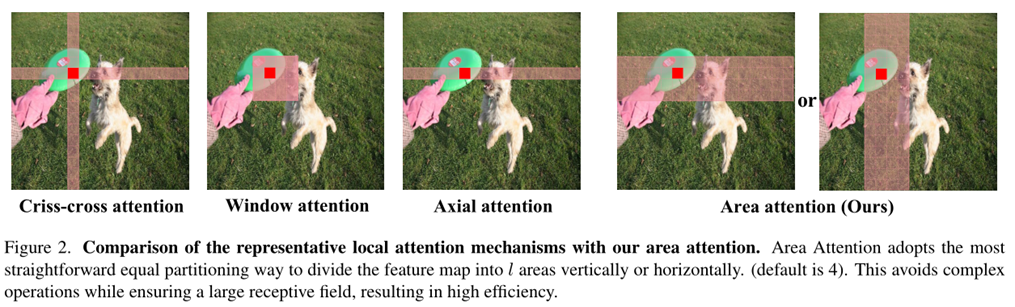
对比“交叉注意力”、“局部窗口注意力”、“轴方向注意力”作者提出了区域注意力,在保持较大感受野的前提下也同时减少了自注意力计算复杂度,图中作者将图片按水平或者垂直方向分成了4块,可以将原来的2n2hd变成0.5n2hd,对于YOLO的输入640x640而言,n是固定的640,可以达到实时处理,并且对精度影响不大。
2.2 残差高效聚合网络Residual Efficient Layer Aggregation Networks
作者参考了YOLOv7的ELAN结构对其进行改进,如下图d所示:
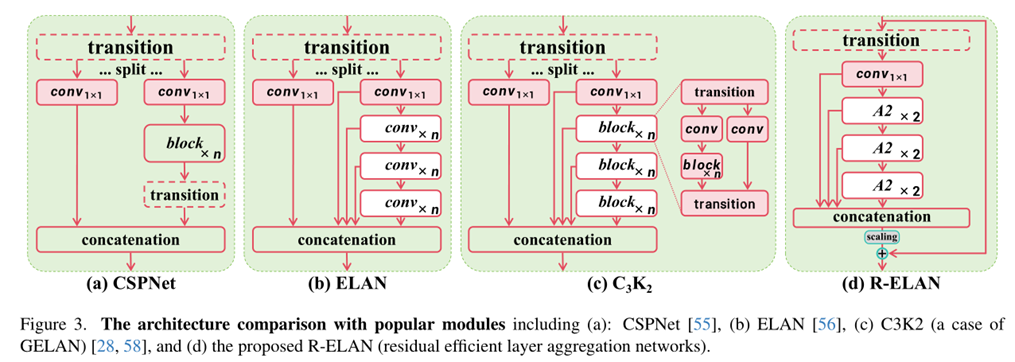
作者认为ELAN这种架构可能会引入不稳定性,这样的设计会导致梯度阻塞,并且缺乏从输入到输出的残差连接,而且为了精简计算,作者去掉了ELAN最开始的split操作。
2.3 整个YOLO网络结构优化
1、作者取消了backbone最后部分的三个blocks的堆叠,这点可以对比YOLO11的结构看出。
2、作者还调整了MLP的比率,由4减小到1.2,并且为了得到更高效的性能,将原来的nn.Linear+LN操作替换成了nn.Conv2d+BN操作。
3、作者移除了位置编码操作,增加了一个7x7的可分离卷积来帮助区域注意感知位置信息。
3、代码解析
其实YOLOv12的主要创新点就是提出了加速的区域自注意力机制(Area Attention)并且应用在R-ELAN模块中,R-ELAN的实现在官方代码https://github.com/sunsmarterjie/yolov12/blob/main/ultralytics/nn/modules/block.py中,如下:

A2C2f模块就是论文提到的R-ELAN模块,它主要包含了ABlock,也就是论文中的A2,A2就是区域注意力模块,代码如下:

这里可以看到这里的AAttn模块使用了area参数进行自注意力的计算,而且MLP也是像论文中提到的一样,作者改成了Conv操作。
4、实验
Comparison with State-of-the-arts
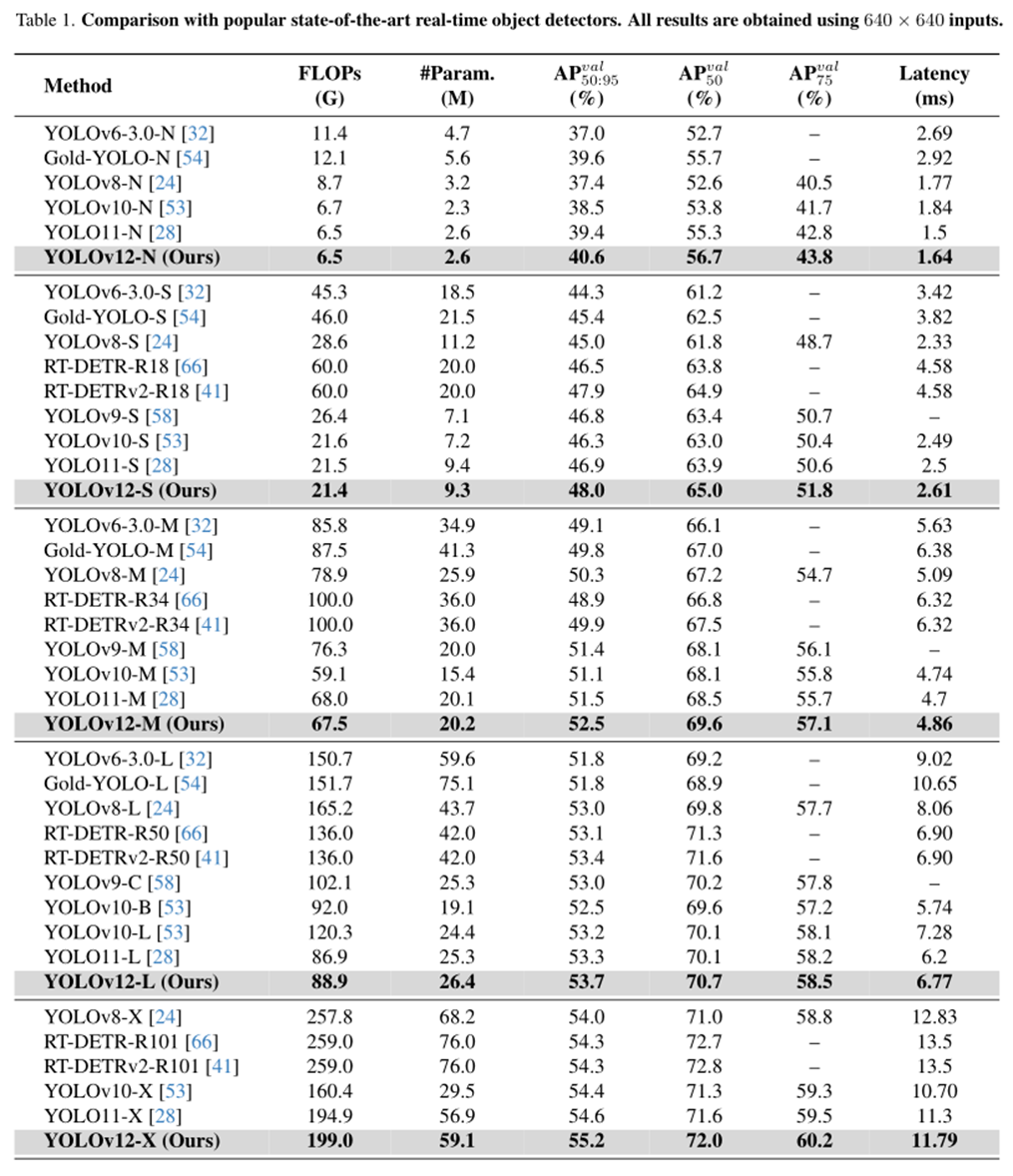
作者直接给出了一张对照表,按照多个尺度规模模型去对比YOLOv6,YOLOv8,YOLOv10,YOLO11以及RT-DETRv1/v2,结果表明,在FLOPs减少的情况下,mAP具有提升。
消融实验
关于R-ELAN模块的消融实验如下表所示:
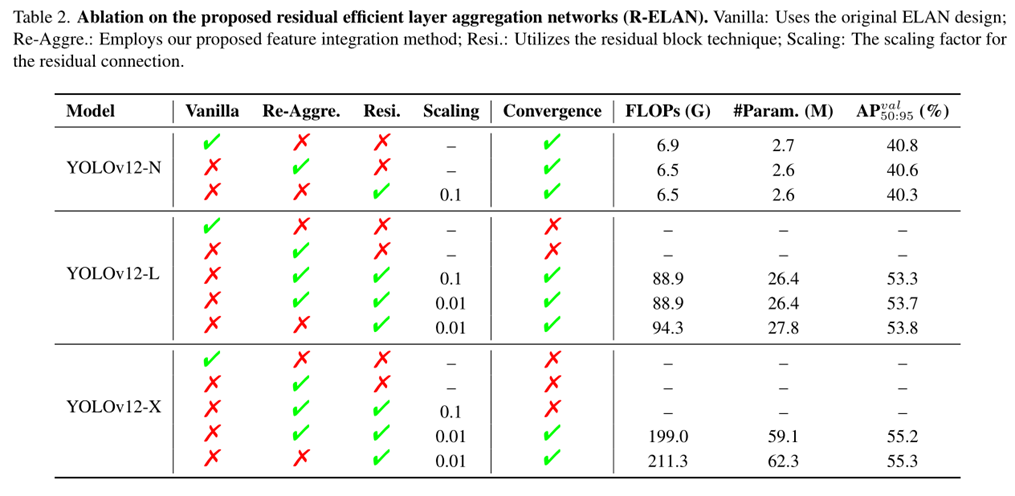
作者得出的结论有两个:
1、针对小规模模型比如YOLOv12-N,残留连接不会影响收敛,但会降低性能。相比之下,对于较大规模模型比如YOLOv12-L/X,它们对于稳定的训练是必不可少的。特别是YOLOv12-X要求最小的缩放因子0.01以保证收敛。
2、作者提出的特征聚合方式可以有效地降低了模型在FLOPs和参数方面的复杂性,但是会略微带来精度下降。
关于Area Attention作者在GPU/CPU上进行了速度方面的消融实验,如下表所示:
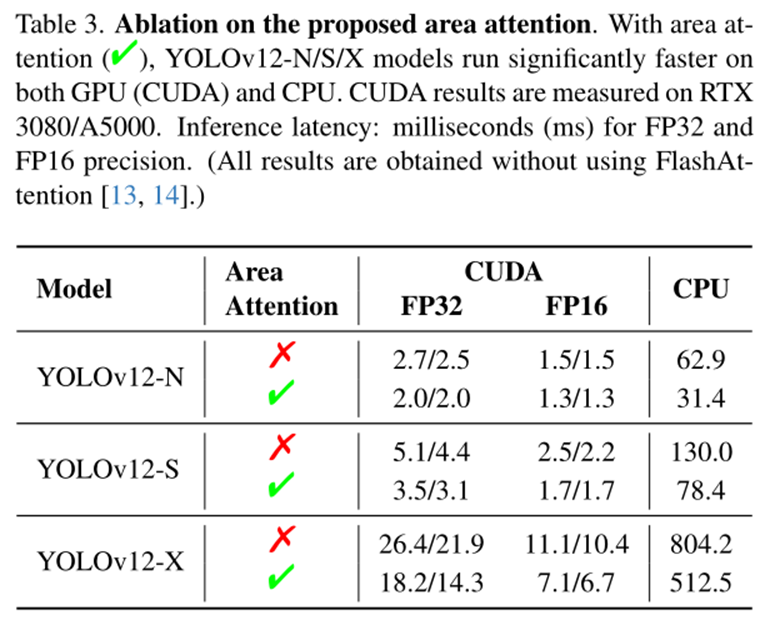
可以看到,无论是GPU或者CPU情况下,Area Attention相对于原始的自注意力机制都带来了加速的效果。