ShardingSphere解析:分布式数据库中间件的分片设计与事务管理实践
引用
在现代互联网业务高速扩张的背景下,单机数据库的性能瓶颈与扩展性缺陷日益凸显。分库分表方案虽能有效解决数据存储压力,但手动实现分片路由、跨节点查询及分布式事务管理等复杂逻辑,往往导致开发成本剧增且难以维护。Apache ShardingSphere作为一款轻量级的分布式数据库中间件,通过透明化数据分片、读写分离和分布式事务支持,为开发者提供了开箱即用的企业级解决方案。
ShardingSphere以“可插拔架构”为核心设计理念,提供Sharding-JDBC(嵌入式SDK)与Sharding-Proxy(独立数据库代理)两种接入形态,兼顾高性能与多语言兼容性。其标准分片、行表达式、复合分片及Hint强制路由等策略,支持从简单取模分片到多字段联合分片的复杂场景。针对分布式事务难题,ShardingSphere整合XA强一致性事务与Seata AT柔性事务模型,覆盖金融级一致性需求与高吞吐量业务场景。然而,嵌套子查询、跨库关联等复杂SQL的解析限制,仍需开发者在表结构设计阶段规避。
ShardingSphere分布式数据库组件
ShardingSphere并非分布式数据库,只是一个分布式数据库组件,已代理的形式帮助单体数据库支持分片、分布式事务、跨节点查询。
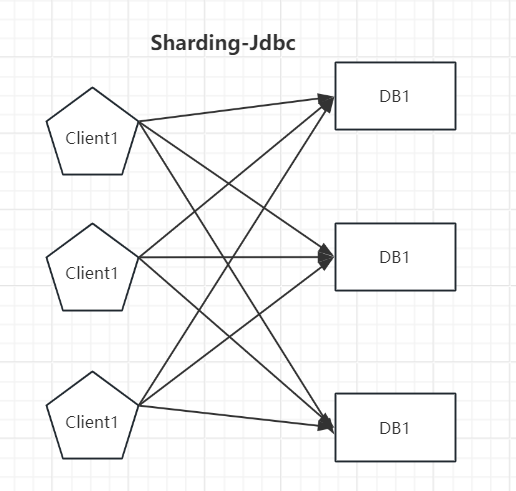
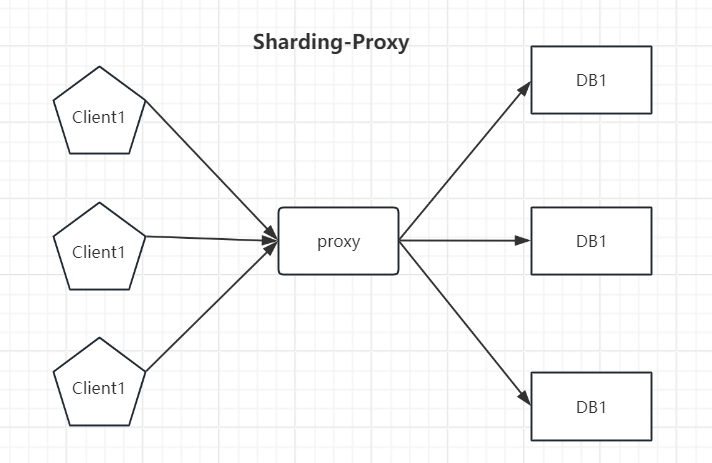
Sharding-JDBC和Sharding-Proxy对比
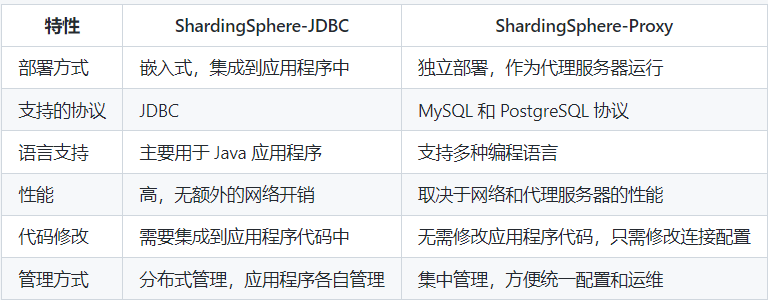
Sharding-JDBC适用场景
- 应用程序是 Java 编写的。
- 需要高性能,没有额外的网络开销。
- 希望有更多的灵活性和自定义能力。
- 需要一个轻量级的嵌入式解决方案。
- 消耗数据库连接数更多。
Sharding-Proxy适用场景
- 应用程序使用多种编程语言。
- 不希望修改现有的应用程序代码。
- 需要集中管理分片和读写分离策略。
- 希望独立部署和维护数据库代理层。
- 消耗数据库连接数更少。
数据库消耗连接数对比
Sharding-JDBC消耗数据库连接数 = 应用实例数 * 分片数据库数。
Sharding-Proxy消耗数据库连接数 = 分片数据库数。
分布式事务
本地事务(默认)
完全支持非跨库事务。例如:仅分表,或分库但是路由的结果在单库中。
完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库宕机,则只有第二个库数据提交。
XA事务
ShardingSphere整合Atomikos对XA分布式事务的支持。执行的过程中需要对所需资源进行锁定,它更加适用于执行时间确定的短事务。对于长事务来说,整个事务进行期间对数据的独占,将会对并发场景下的性能产生一定的影响。
Base事务(柔性事务)
BASE事务,属于柔性事务,数据最终一致性。ShardingSphere是基于Seata的AT模式进行二阶段提交来实现事务管理的。
分片策略
标准分片策略
标准分片策略(standard)适用于具有单一分片键的标准分片场景。该策略支持精确分片,即在SQL中包含=、in操作符,以及范围分片,包括BETWEEN AND、>、<、>=、<=等范围操作符。
通过实现PreciseShardingAlgorithm设置精准分片策略,实现RangeShardingAlgorithm设置范围分片策略。
spring:shardingsphere:sharding:#唯一库数据,当某些查询没有明确的分片规则,#或在某些情况下无法确定数据应该存储在哪个分片中的时候 #ShardingSphere会将这些操作路由到默认的数据源default-data-source-name: db0#分库default-database-strategy:standard:# 添加数据分库字段(根据字段插入数据到那个表)sharding-column: id#精确分片precise-algorithm-class-name: com.example.sharding_test.strategy.database.DatabasePreciseAlgorithm#范围分片range-algorithm-class-name: com.example.sharding_test.strategy.database.DatabaseRangeAlgorithm #分表tables:#表名db_user:actual-data-nodes: db$->{0..1}.db_user_$->{0..2}key-generator:column: id # 主键IDtype: SNOWFLAKE # 生成策略雪花idtable-strategy:standard:sharding-column: id#精确分片precise-algorithm-class-name: com.example.sharding_test.strategy.table.TablePreciseAlgorithm#范围分片range-algorithm-class-name: com.example.sharding_test.strategy.table.TableRangeAlgorithm
行表达式分片策略
行表达式分片策略(inline)适用于具有单一分片键的简单分片场景,支持SQL语句中=和in操作符。它的配置相当简洁,该分片策略支持在配置属性algorithm-expression中书写Groovy表达式,用来定义对分片健的运算逻辑,无需单独定义分片算法了。
spring:shardingsphere:sharding:#唯一库数据default-data-source-name: db0#分库default-database-strategy:inline:# 添加数据分表字段(根据字段插入数据到那个表)sharding-column: id# 分片算法表达式 => 通过id取余algorithm-expression: db$->{id % 2}#分表tables:#表名db_user:actual-data-nodes: db$->{0..1}.db_user_$->{0..2}key-generator:column: id # 主键IDtype: SNOWFLAKE # 生成策略雪花idinline:# 添加数据分表字段(根据字段插入数据到那个表)sharding-column: id# 分片算法表达式 => 通过id取余algorithm-expression: db_user_$->{id % 3}复合分片策略
复合分片策略(complex)适用于多个分片键的复杂分片场景,属性sharding-columns中多个分片键以逗号分隔。支持 SQL 语句中有>、>=、<=、<、=、IN 和 BETWEEN AND 等操作符。
比如:我们希望通过user_id和order_id等多个字段共同运算得出数据路由到具体哪个分片中,就可以应用该策略。
通过实现ComplexKeysShardingAlgorithm自定义分库、分表策略。
spring:shardingsphere:sharding:#唯一库数据default-data-source-name: db0#分库default-database-strategy:#复合分片complex:sharding-columns: id,agealgorithm-class-name: com.example.sharding_test.strategy.database.DatabaseComplexAlgorithm#分表tables:#表名db_user:actual-data-nodes: db$->{0..1}.db_user_$->{0..2}key-generator:column: id # 主键IDtype: SNOWFLAKE # 生成策略雪花idtable-strategy:#复合分片complex:sharding-columns: id,agealgorithm-class-name: com.example.sharding_test.strategy.table.TableComplexAlgorithmHint分片策略
该策略无需配置分片健,由外部指定分库和分表的信息,可以让SQL在指定的分库、分表中执行。
通过实现HintShardingAlgorithm自定义分片策略。
spring:shardingsphere:sharding:#唯一库数据default-data-source-name: db0#分库default-database-strategy:#行分片inline:# 添加数据分表字段(根据字段插入数据到那个表)sharding-column: id# 分片算法表达式 => 通过id取余algorithm-expression: db$->{id % 2}#分表tables:#表名db_user:actual-data-nodes: db$->{0..1}.db_user_$->{0..2}key-generator:column: id # 主键IDtype: SNOWFLAKE # 生成策略雪花idtable-strategy:#强制分片hint:algorithm-class-name: com.example.sharding_test.strategy.table.TableHintAlgorithmpackage com.example.sharding_test.strategy.table;import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.Arrays;
import java.util.Collection;public class TableHintAlgorithm implements HintShardingAlgorithm<Integer> {@Overridepublic Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {String logicTableName = hintShardingValue.getLogicTableName();// 取代码中通过addTableShardingValue设置表序号String dbName = logicTableName + "_" + hintShardingValue.getValues().toArray()[0];return Arrays.asList(dbName);}
}// 测试用例,代码中通过addTableShardingValue设置表序号
@Test
void selectHintData(){HintManager manager = HintManager.getInstance();manager.addTableShardingValue("db_user",2);LambdaQueryWrapper<DbUser> wrapper = Wrappers.lambdaQuery();wrapper.eq(DbUser::getAge,34);List<DbUser> dbUsers = dbUserMapper.selectList(wrapper);dbUsers.forEach(System.out::println);
}不支持语句
- VALUES语句不支持运算表达式
INSERT INTO tbl_name (col1, col2, …) VALUES(1+2, ?, …)- INSERT … SELECT
INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ?- HAVING
SELECT COUNT(col1) as count_alias FROM tbl_name GROUP BY col1 HAVING count_alias > ?- UNION
SELECT * FROM tbl_name1 UNION SELECT * FROM tbl_name2- UNION ALL
SELECT * FROM tbl_name1 UNION ALL SELECT * FROM tbl_name2- 包含schema
SELECT * FROM ds.tbl_name1- 同时使用普通聚合函数和DISTINCT聚合函数
SELECT SUM(DISTINCT col1), SUM(col1) FROM tbl_name- 只支持解析一层子查询,不支持多层嵌套的子查询
SELECT COUNT(*) FROM (SELECT * FROM t_order o WHERE o.id IN (SELECT id FROM t_order WHERE status = ?))- 跨库关联查询不被支持
感谢您的阅读!如果文章中有任何问题或不足之处,欢迎及时指出,您的反馈将帮助我不断改进与完善。期待与您共同探讨技术,共同进步!