强化微调技术与GRPO算法(1):简介
大语言模型(LLM)已经彻底改变了我们与技术互动的方式。但一个基础模型,无论多么强大,都只是一个“通才”。为了让它在特定任务上(无论是按特定风格写作、以某种安全级别回答问题,还是生成高质量代码)真正发挥作用,我们必须对其进行微调。
长期以来,监督微调(Supervised Fine-Tuning, SFT) 一直是主流方法。然而,SFT有其固有的局限性。这时,强化学习(Reinforcement Learning, RL) 应运而生,它提供了一种强大的范式,通过反馈而非简单的模仿,来使LLM的行为与我们的期望对齐。
这篇博客将带您走过从SFT到前沿强化学习技术的演进之路。我们将深入探讨:
-
监督微调(SFT)的基础知识。
-
强化学习(RL)的核心思想及其在LLM中的应用。
-
流行的RL算法,如RLHF和DPO。
-
一种强大的新型方法——组相对策略优化(Group Relative Policy Optimization, GRPO),它克服了许多前辈算法的挑战。
一、 奠基石:监督微调(SFT)
SFT本质上是一种“从演示中学习”的过程。你通过向LLM展示大量高质量的任务示例,来教会它一项新技能。
SFT 的工作流程
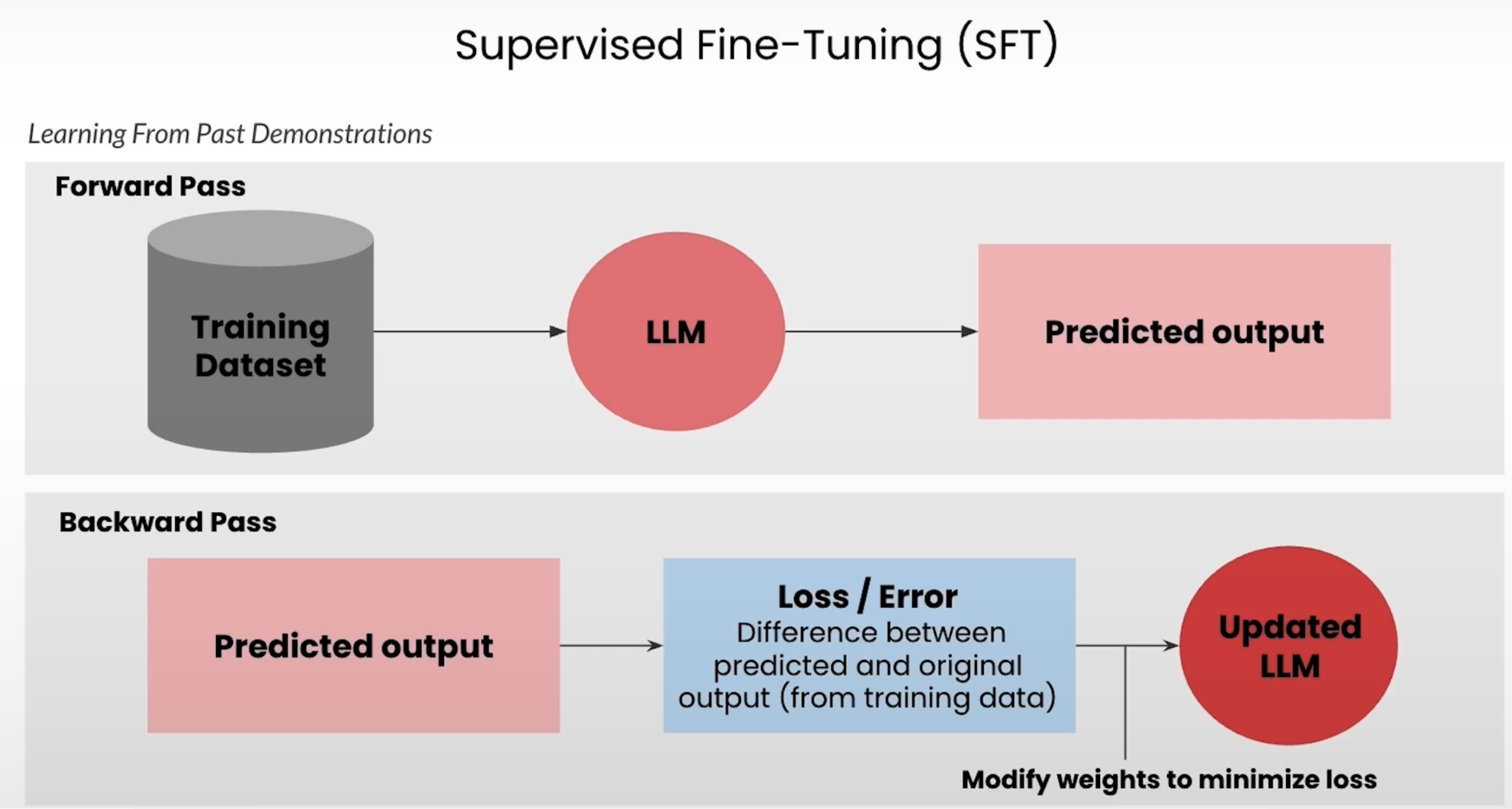
SFT的核心是一个在标注好的“提示-补全”数据集上进行的两步循环。
-
前向传播 (Forward Pass): LLM接收来自训练集的提示词,并生成一个预测的输出。
-
反向传播 (Backward Pass): 将这个预测输出与数据集中的“正确”答案进行比较。两者之间的差异被计算为损失(Loss)或误差(Error)。然后,模型的内部权重会被调整以最小化这个误差,使其在下一次更有可能产生正确的输出。
通过重复这个过程成千上万次,模型就能学习到潜在的模式,并能为新的、未见过的提示生成符合期望的输出。
使用SFT实现推理
你甚至可以通过在补全中包含“思维链”来教授复杂的、多步骤的推理。通过将推理步骤用特殊标签(如 <think>)包裹,并将最终答案用 <answer> 标签包裹,模型可以同时学会逐步推理的逻辑和期望的输出格式。
-
简单的SFT数据集:
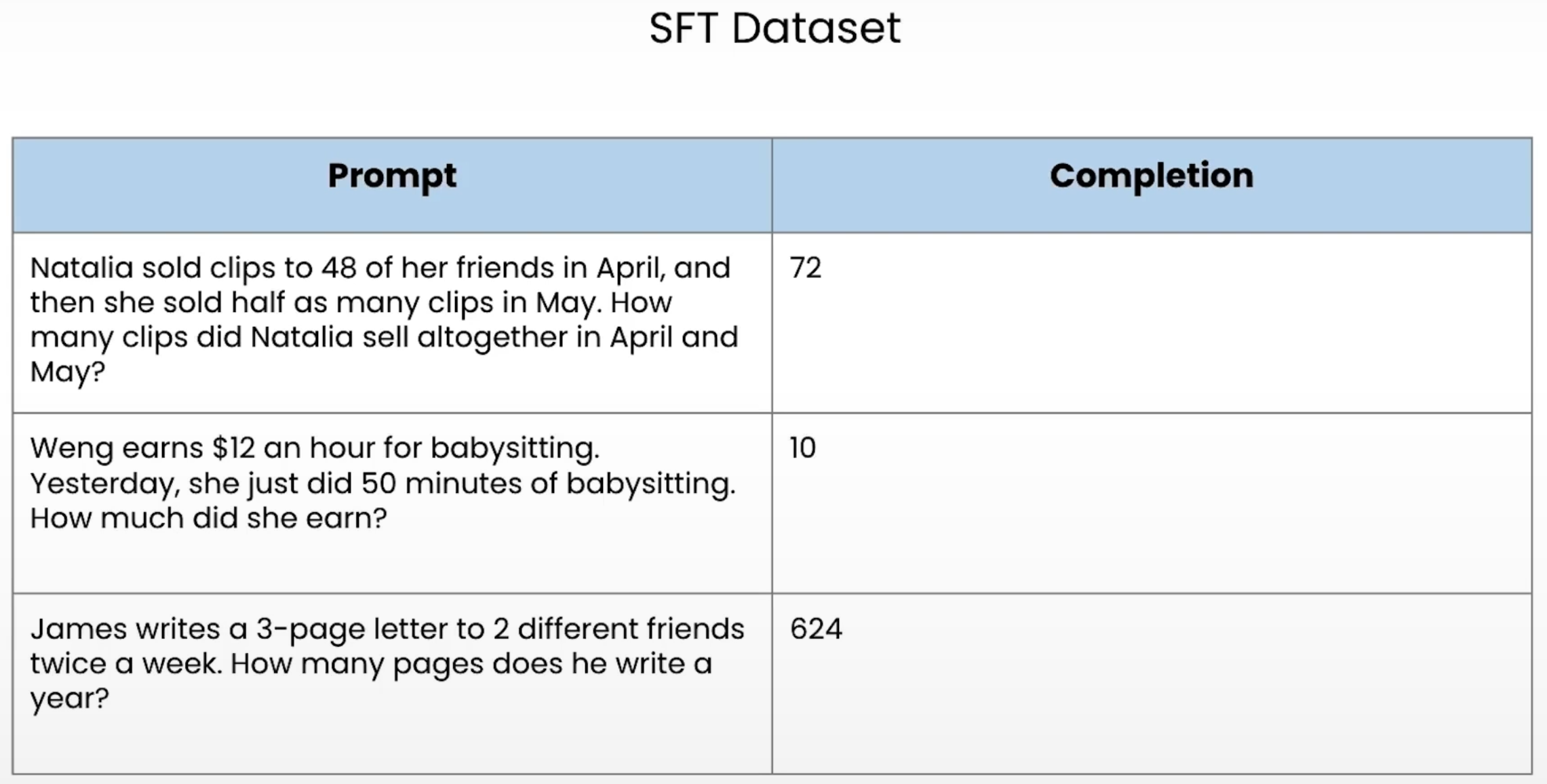
-
包含推理过程的SFT数据集:

监督微调的局限性
尽管SFT行之有效,但它有两个显著的局限性:

-
严重依赖标注数据: SFT需要成千上万个高质量、准确标注的示例。创建这些数据集通常耗时、昂贵,并需要大量的人力投入。
-
过拟合 (Overfitting): 模型可能会过于擅长“背诵”训练样本,学习到过于特定的模式,导致它无法很好地泛化到新的、略有不同的输入上。它精通了“模拟考”,却在“真实世界”中表现不佳。
这些挑战促使我们寻找一种更灵活的训练方法——一种能够引导模型走向期望行为,而不仅仅是依赖一套固定的“正确答案”的方法。
二、 新范式:用于LLM的强化学习(RL)
强化学习提供了这种灵活性。智能体(Agent) 不再从静态数据集中学习,而是通过与环境(Environment) 互动,并因其动作(Actions) 获得奖励(Rewards) 来学习执行任务。其目标是在一段时间内最大化总奖励。
为了更好地理解这个概念,让我们来看一个生活中的例子:训练一只小狗。
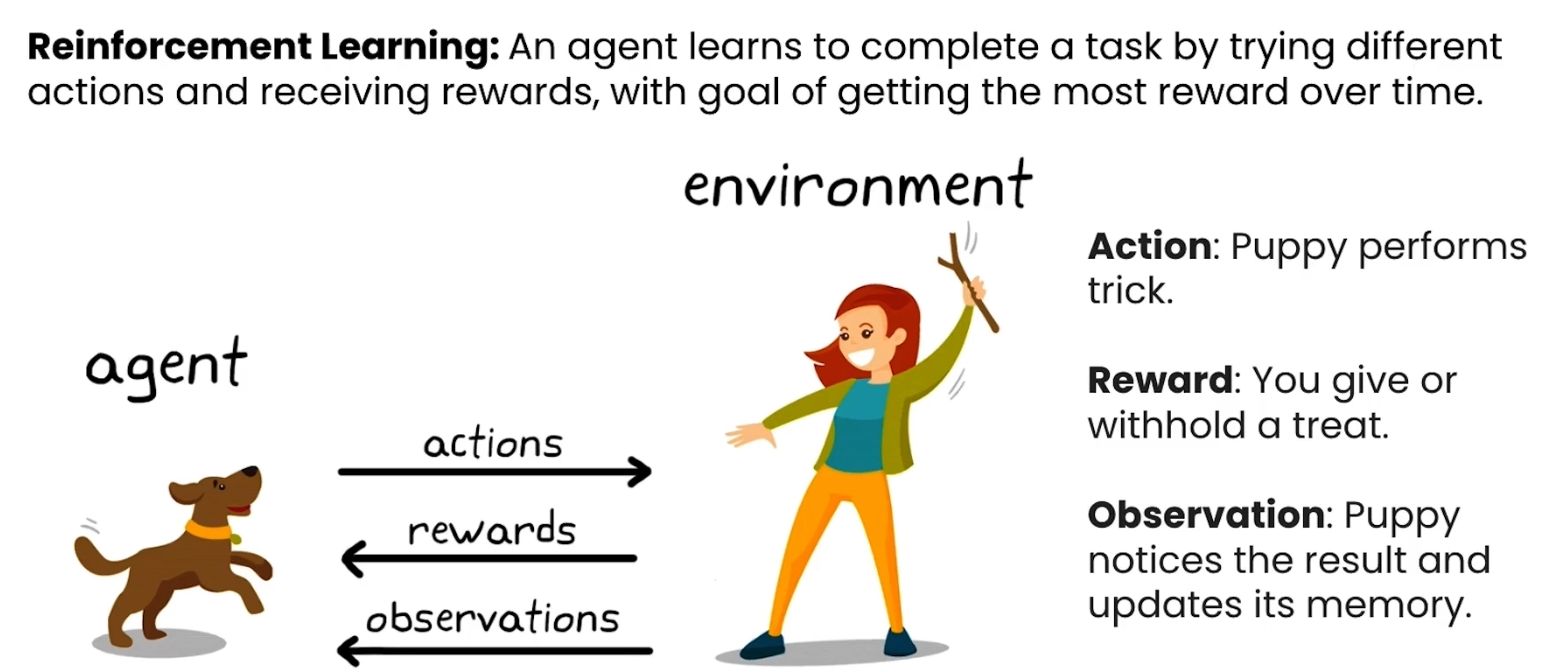
在这个例子中:
-
智能体 (Agent): 小狗。
-
环境 (Environment): 它的主人和周围的环境。
-
动作 (Action): 小狗可以执行很多动作,比如坐下、打滚,或者捡回主人扔出的树枝。当它执行“捡回树枝”这个技巧时,就是在执行一个动作。
-
奖励 (Reward): 当小狗执行了我们期望的动作后,主人会给它一个零食作为奖励。这个奖励信号是正向的。如果它执行了别的动作,则可能得不到奖励。
-
观察 (Observation): 小狗观察到“捡回树枝”这个行为带来了奖励,而其他行为则没有。它会更新自己的“记忆”,从而在未来更倾向于执行能带来奖励的动作。
这个过程完美地诠释了强化学习的核心循环。
这个概念可以完美地映射到LLM上:
-
智能体 (Agent): LLM本身。
-
环境 (Environment): 上下文,包括用户的提示词。
-
动作 (Action): LLM生成的回复。
-
奖励 (Reward): 一个评估回复质量的分数。
将RL应用于LLM微调
现在,让我们将这个思想应用到LLM上。训练过程变成了一个动态的反馈循环:
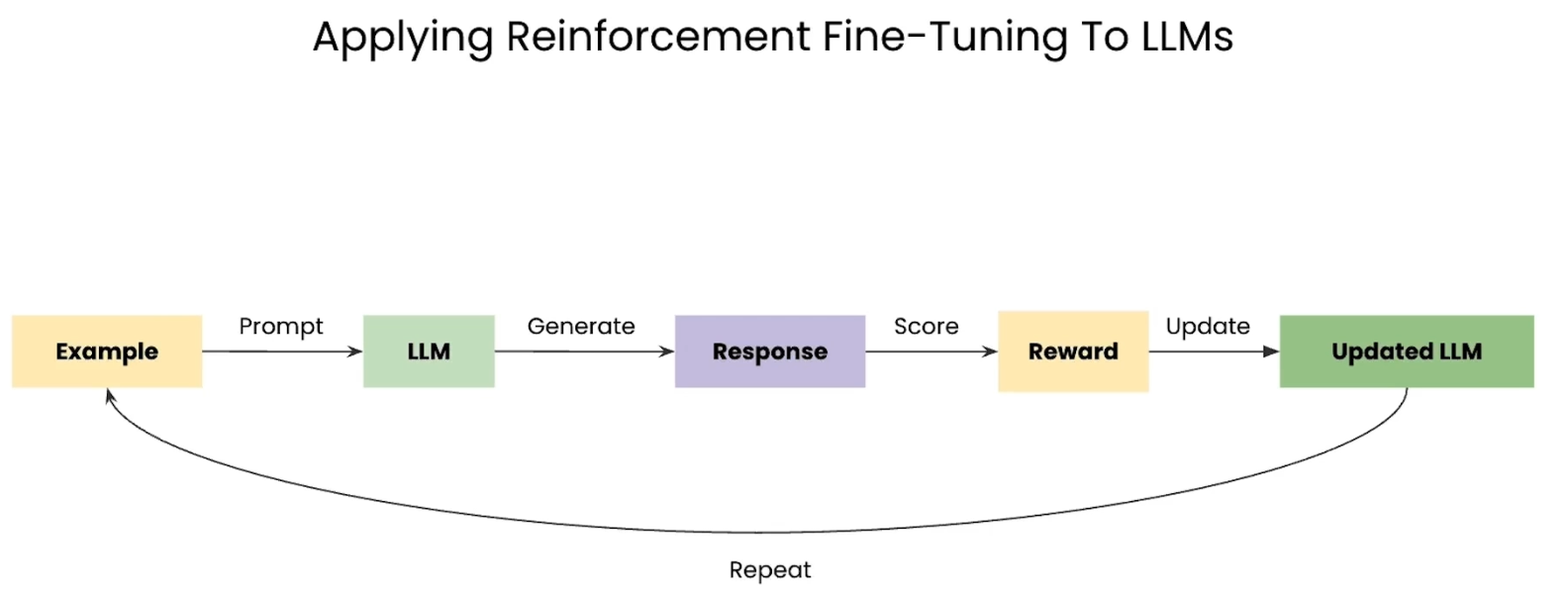
-
一个prompt(提示词)被输入到LLM(智能体)。
-
LLM 生成一个回复(动作)。
-
这个回复被评估,并得到一个奖励分数。该分数可以基于质量、正确性、人类偏好或任何其他可编程的指标。
-
奖励信号被用来更新LLM的权重,鼓励它在未来产生能获得更高奖励的回复。
这种方法允许模型通过试错来探索和学习什么构成“好”的回复,超越了简单模仿的范畴。
三、 流行的LLM对齐强化学习算法
目前,有几种主流的强化学习算法被用于微调LLM。
算法一:基于人类反馈的强化学习 (Reinforcement Learning with Human Feedback, RLHF)
RLHF是早期像ChatGPT等模型背后著名的、多阶段的流程。它利用人类的偏好来创建一个奖励信号。

RLHF的4步工作流:
-
生成回复: 对于给定的提示词,LLM生成多个候选回复(例如A, B, C, D)。
-
获取人类反馈: 人类标注员将这些回复从最好到最差进行排序(例如,C > D > A > B)。这会创建一个偏好数据集。
-
训练奖励模型: 在这个偏好数据上训练一个独立的模型。它的工作是预测任何给定“提示-回复”对的人类偏好分数。
-
更新LLM: 使用像PPO这样的RL算法对原始LLM进行微调。LLM生成回复,奖励模型对其评分,然后LLM的权重被更新以最大化该分数。
算法二:直接策略优化 (Direct Policy Optimization, DPO)
DPO是一种更新、更高效的算法。它通过去除独立的奖励模型,简化了RLHF的流程。

DPO的工作流:
-
生成回复: LLM为每个提示生成两个回复(A和B)。
-
获取人类反馈: 人类只需选择更偏好的那个回复(例如,“B比A好”)。
-
创建偏好数据集: 这会创建一个由(提示词, 偏好的回复, 不偏好的回复)组成的数据集。
-
直接更新LLM: DPO算法使用这些偏好数据直接更新LLM的权重。它调整权重以增加生成“偏好回复”的概率,同时降低生成“不偏好回复”的概率。
RLHF与DPO面临的挑战
尽管这些方法很强大,但它们都有共同的挑战,如下表所示。关键在于,这两种方法都严重依赖昂贵的人工标注偏好数据。
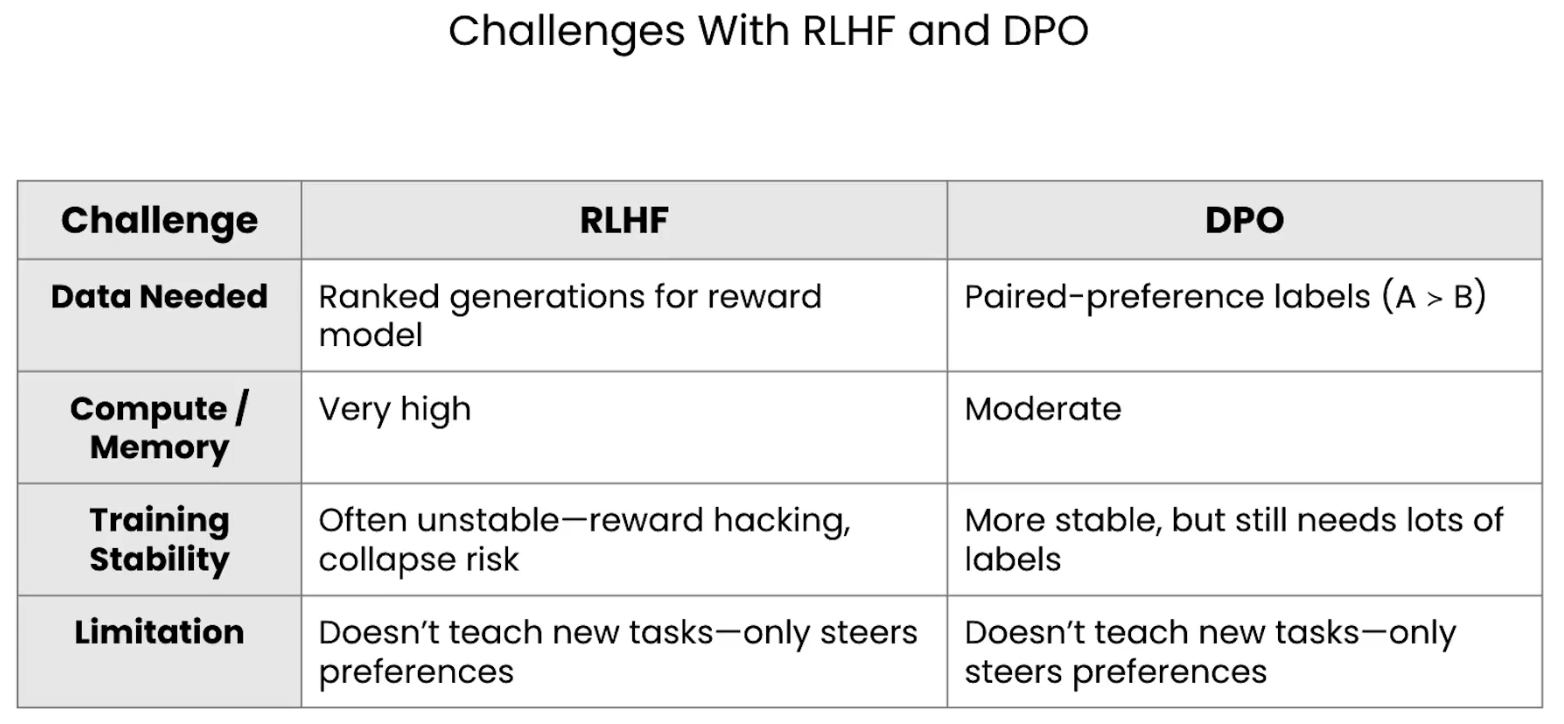
| 挑战 | RLHF | DPO |
| 所需数据 | 用于奖励模型的排名生成 | 成对的偏好标签 (如 A > B) |
| 计算/内存 | 非常高 (需要多个模型副本) | 中等 (比RLHF更高效) |
| 训练稳定性 | 通常不稳定,有奖励被“黑”、模型崩溃的风险 | 更稳定,但仍需大量标签 |
| 局限性 | 不教授新任务,只引导偏好 | 不教授新任务,只引导偏好 |
四、 GRPO:强化微调的下一步
组相对策略优化 (Group Relative Policy Optimization, GRPO),由DeepSeek团队开发的,是一种旨在解决RLHF和DPO局限性的前沿算法。
核心创新:可编程的奖励
GRPO的精妙之处在于它完全摆脱了对人类偏好标签的依赖。取而代之的是,它依赖一个或多个你自定义的可编程奖励函数。这些函数可以检查你关心的任何事情:
-
最终答案的正确性。
-
是否遵循特定格式(如JSON)。
-
是否包含引文。
-
是否包含有害内容。
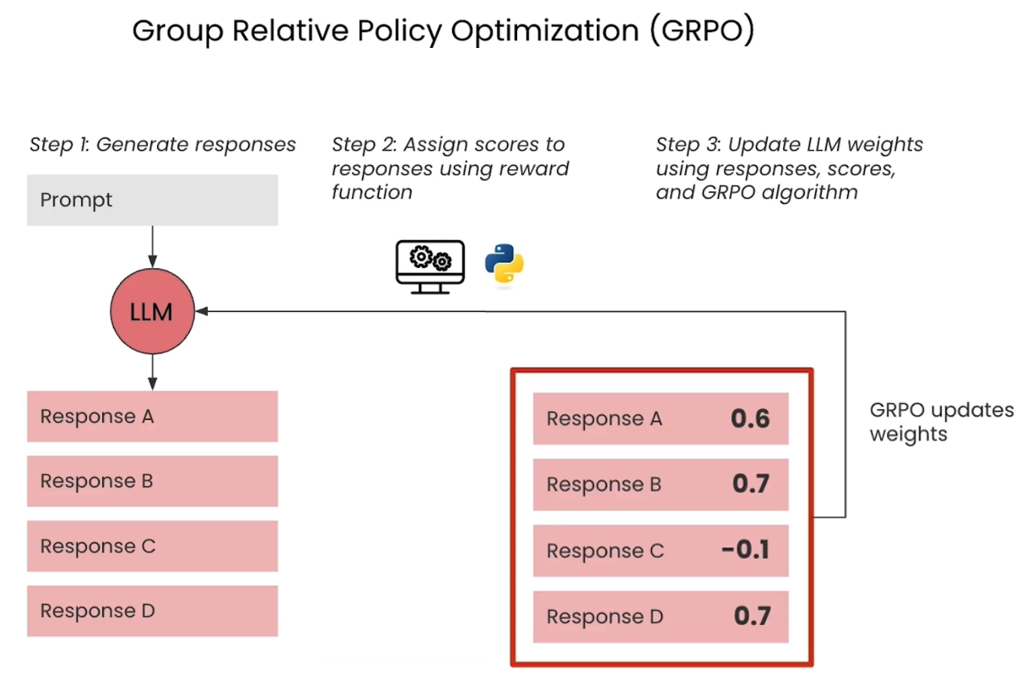
GRPO的3步循环
-
生成回复: 与RLHF类似,LLM为单个提示生成一个组的候选回复。
-
分配分数: 你自定义的奖励函数会自动为该组中的每个回复打分。这会产生一系列分数(例如,0.6, 0.7, -0.1, 0.7)。
-
更新LLM权重: GRPO算法将这些分数作为直接的训练信号。它更新LLM的权重,以:
-
提升生成组内高于平均分的回复的概率。
-
降低生成组内低于平均分的回复的概率。
-
通过重复这个循环,GRPO直接在你关心的指标上对模型进行微调,即使在人类标签稀缺或无法获得的情况下,也能释放强化微调的力量。
结论
LLM微调的演变是一条从模仿到对齐的旅程。
-
SFT 通过从示例中学习,为我们奠定了坚实的基础。
-
RLHF 和 DPO 通过将模型与人类偏好对齐来增强这一点,但代价是高昂的标注和计算成本。
-
GRPO 代表了下一个前沿,它使用自动化的、可编程的奖励来实现强大的强化微调。这使得整个过程更具可扩展性、成本效益更高、也更易于实现,让开发者能够在没有大量人力投入的情况下,将LLM与复杂、客观的标准对齐。
参考资料
1. 监督微调 (SFT - Supervised Fine-Tuning)
SFT 是一个非常基础和广泛应用的概念,因此没有一篇单一的“SFT”开创性论文。它是在多篇里程碑式的论文中被提出和完善的。其中,Google的T5模型论文 对这种“指令微调”(Instruction-Tuning)的方法进行了系统性的探讨,是理解SFT思想的重要文献。
-
论文标题: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
-
核心思想: 提出了T5模型,并将几乎所有的NLP任务都统一为“文本到文本”的格式,通过在大量有监督的指令数据集上进行微调来激发模型的泛化能力。
-
论文地址: https://arxiv.org/abs/1910.10683
2. 基于人类反馈的强化学习 (RLHF - Reinforcement Learning from Human Feedback)
RLHF技术因OpenAI的 InstructGPT 而闻名,这篇论文是理解现代LLM对齐(Alignment)的必读文献。
-
论文标题: Training language models to follow instructions with human feedback
-
核心思想: 详细描述了使用人类反馈来微调语言模型的三步流程:SFT、训练奖励模型和使用PPO算法进行强化学习,以使模型输出更符合人类偏好。
-
论文地址: https://arxiv.org/abs/2203.02155
3. 直接策略优化 (DPO - Direct Policy Optimization)
DPO作为RLHF的一种更轻量、更稳定的替代方案,由斯坦福大学的研究者提出。
-
论文标题: Direct Preference Optimization: Your Language Model is Secretly a Reward Model
-
核心思想: 证明了可以跳过训练独立奖励模型的步骤,直接使用人类偏好数据(例如,A比B好)来优化语言模型的策略,过程更简单且效果相当甚至更好。
-
论文地址: https://arxiv.org/abs/2305.18290
4. 组相对策略优化 (GRPO - Group Relative Policy Optimization)
GRPO是当前的最新技术,由 DeepSeek团队提出,旨在完全摆脱对人类偏好数据的依赖。
-
论文标题: GRPO: Group Relative Policy Optimization for Large Language Model Alignment
-
核心思想: 提出了一种无需任何人类偏好标注的对齐方法。它通过生成一组候选回复,并使用可编程的奖励函数对这组回复进行“相对”打分,然后直接优化模型策略,使其倾向于生成组内得分更高的回复。
-
论文地址: https://arxiv.org/abs/2405.00934