LLM 系列(二) :基础概念篇
一个面向 Java 开发者的 Sring-Ai 示例工程项目,该项目是一个 Spring AI 快速入门的样例工程项目,旨在通过一些小的案例展示 Spring AI 框架的核心功能和使用方法。 项目采用模块化设计,每个模块都专注于特定的功能领域,便于学习和扩展。欢迎感兴趣的小伙伴们关注和 Star。
项目地址:https://github.com/java-ai-tech/spring-ai-summary*
大语言模型 (LLMs) 正以前所未有的方式重塑我们的世界。无论您是技术爱好者、产品经理,还是希望把握时代脉搏的探索者,理解其背后的核心原理都至关重要。这份摘要旨在为您提供一张清晰、易懂的 LLM 知识地图。
🏛️ 一、核心数学与算法
揭示了驱动所有神经网络(包括 LLM)学习的底层循环逻辑。
神经网络的学习循环
想象一个学生在不断学习:做题 → 对答案 → 总结错误 → 改进方法。神经网络的学习与此类似。
核心循环: 预测 → 评估 → 修正
-
🎯 预测 (Prediction)
- 模型根据现有知识(模型参数)对问题进行猜测。例如,预测下一个词是什么。这本质上是一个 分类 (Classification) 任务。这个过程叫作 前向传播 (Forward Propagation)。
-
📝 评估 (Evaluation)
- 使用 损失函数 (Loss Function) 这把“尺子”来衡量模型的预测结果与正确答案之间的差距(即“损失”或“误差”)。
-
🧠 修正 (Correction)
-
通过反向传播 (Backpropagation),模型计算出每个参数对造成误差的“责任”有多大,这个“责任”就是梯度 (Gradient)。
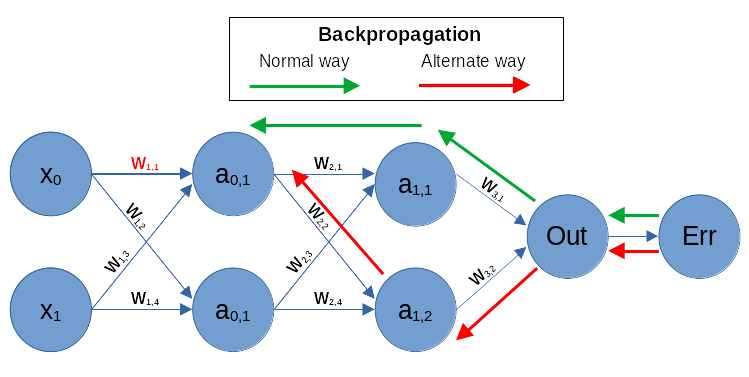 Backpropagation
Backpropagation -
随后,模型使用 梯度下降 (Gradient Descent) 算法,朝着减小误差的方向,聪明地微调自己的参数。
-
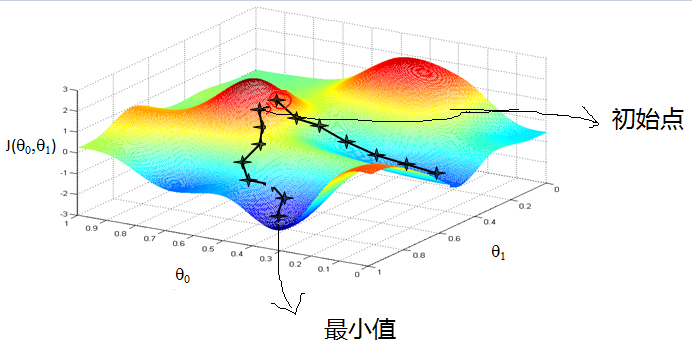 Gradient
Gradient
关键组件
- 激活函数 (Activation Function):为神经网络注入“灵魂”——非线性,让它能学习超越简单线性关系的复杂模式。
- 损失函数 (Loss Function):为模型的优化提供一个清晰的“靶心”,告诉它努力的方向。
🧩 二、深度学习与 LLM 特有机制
将视野从通用神经网络拓宽到 LLM 所特有的概念和工作方式。
学习范式
层级关系: AI > 机器学习 (ML) > 深度学习 (DL)
 layer
layer
- 迁移学习 (Transfer Learning):LLM 成功的“秘密武器”。先在海量通用知识(如整个互联网的文本)上进行 预训练 (Pre-training),成为一个“通才”,然后再针对特定任务进行 微调 (Fine-tuning),成为“专才”。
- 强化学习 (Reinforcement Learning, RL):通过“奖惩”机制进行学习。在 LLM 中,大名鼎鼎的 RLHF 就是让模型通过人类的反馈(喜欢/不喜欢)来学习如何说出更符合人类偏好的话。
核心术语
- 参数 vs. 超参数:参数 (Parameters) 是模型学习到的知识(如权重);超参数 (Hyperparameters) 是我们为学习过程设定的规则(如学习率)。
- 训练节奏:
- Epoch:把整个题库刷一遍。
- Batch:一次做一小批题。
- Step/Iteration:做完一小批题,并订正一次。
- 文本处理流程:
- Tokenizer (分词器):将一句话切分成模型能理解的基本单位 Token (词元)。
- Embedding (嵌入):将每个离散的 Token 转换成一个充满语义信息的“数字坐标”(向量),让模型理解词与词之间的关系。

- 上下文学习 (In-Context Learning):LLM 惊人的“举一反三”能力。
- Zero-shot:不给例子,直接做题。
- One-shot:给一个例子,照着学。
- Few-shot:给几个例子,总结规律。
🛠️ 三、大模型训练与推理优化
聚焦于如何让一个“通才”模型变得更专业、更高效。
微调 (Fine-tuning) 的艺术
核心目标: 用更少的资源,让模型更好地适应特定任务。
- 监督微调 (SFT):最直接的方式,用“指令-回答”格式的数据集,手把手教模型如何遵循指令。
- RLHF:如前所述,通过训练一个“品味”模型(奖励模型)来学习人类的喜好,再用它来指导 LLM 的优化。
- •参数高效微调 (PEFT):为了省钱省力,只微调模型的一小部分参数。
- LoRA / Q-LoRA:给模型装上可插拔的“微调插件”,只训练插件。Q-LoRA 更进一步,先把模型压缩一下再装插件,极大地降低了硬件门槛。
- Prompt/Prefix-tuning:不改动模型本身,而是学习一段添加到输入中的、可训练的“魔法咒语”,引导模型产生期望的输出。
核心引擎:Attention 机制
一言以蔽之: 让模型在处理一句话时,能动态地抓住每个词的重点。
自注意力机制 (Self-Attention) 是 Transformer 架构的心脏。它通过复杂的 查询 (Q)、键 (K)、值 (V) 交互,计算出句子中任意两个词之间的关联度,从而理解长距离的依赖关系和复杂的语法结构。
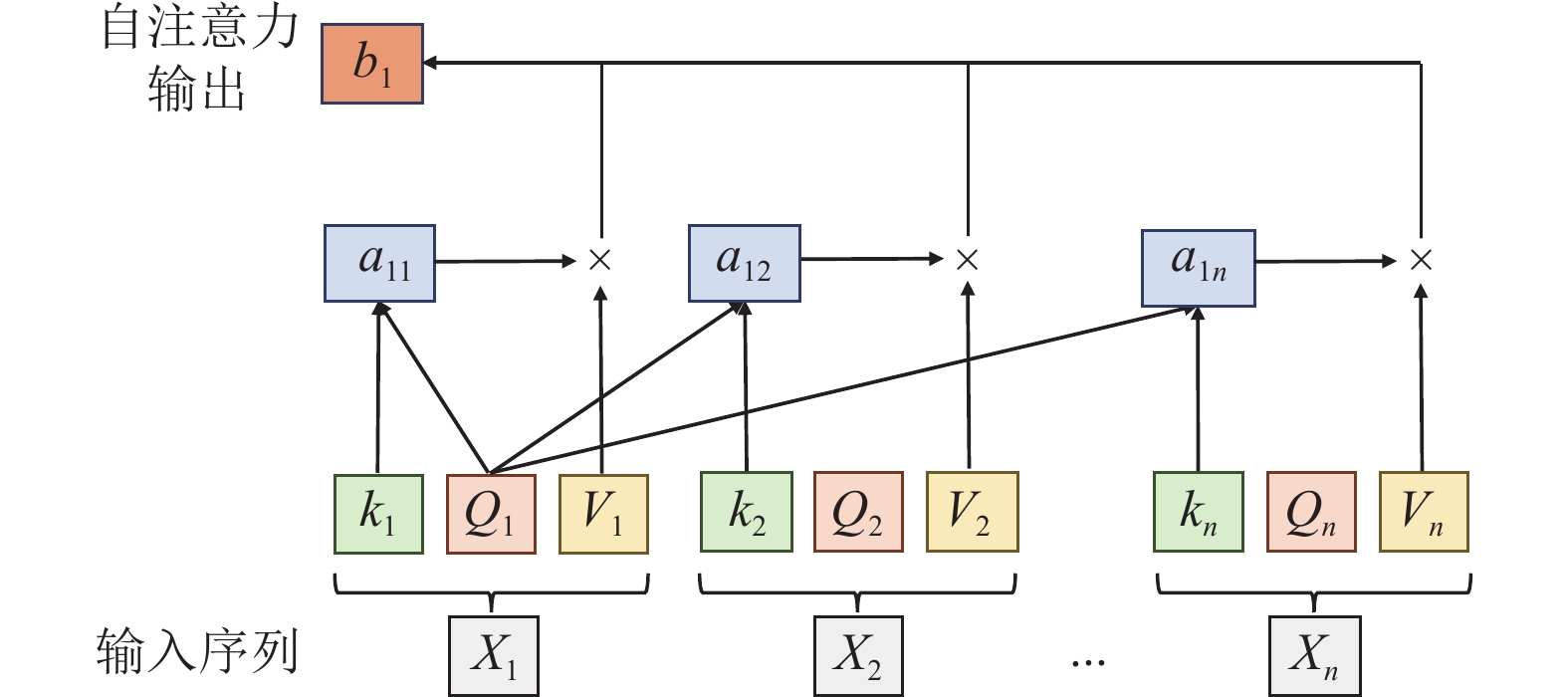
推理优化 (Inference Optimization)
- 预填充 (Prefill):快速“阅读”并理解你的输入提示,这个阶段计算量大。
- 解码 (Decode):逐字逐句地生成回答,这个阶段更考验内存的读写速度。
- KV 缓存 (KV Cache):一个聪明的“备忘录”,记住已经计算过的内容,避免重复劳动,是模型能够流畅回答的关键。
🚀 四、模型压缩与部署
探讨如何让庞大的模型“瘦身成功”,并真正走进我们的手机和电脑。
模型压缩技术
- 模型量化 (Quantization):降低参数的精度,好比把一本精装书变成平装本,内容没大变,但体积和重量都减小了。
- 模型蒸馏 (Distillation):让一个强大的“教师模型”把知识精华传授给一个轻巧的“学生模型”。
 Distillation
Distillation
- 模型剪枝 (Pruning):像修剪花草一样,剪掉模型中不重要、冗余的“枝叶”(参数)。
- 模型二值化 (Binarization):极致压缩,把参数简化到只有+1和-1,大幅提升计算速度。
部署策略
- 端侧部署 (Edge Deployment):让模型直接在你的手机或电脑上运行。优点是响应快、保护隐私。挑战是设备性能有限。
- 云-边-端协同 (Cloud-Edge-Device):一种混合策略。重活累活(如训练)在云端干,需要快速响应的轻活在靠近用户的“边缘”或设备端完成,实现性能与效率的最佳平衡。
欢迎进群交流~~~~

总结
LLM 的未来将走向效率与能力的平衡、普及多模态能力、增强智能体 (Agent) 功能,并持续关注安全与对齐。对我们学习者而言,最好的策略就是:夯实基础、动手实践、保持好奇,并以负责任的态度,迎接这个由 AI 驱动的全新时代。