VOSK 离线中文语音识别实战:精准转文字、格式避坑全解析
言简意赅的讲解VOSK解决的痛点
💡 推荐配套阅读 → XTTS实现语音克隆:精确控制音频格式与生成流程【TTS的实战指南】
这篇文章详细讲解了音频在语音克隆中的处理流程,也提到了一个常见但容易忽略的问题——双声道音频在语音工具中经常导致错误,本篇将对此问题深入剖析并提供实战代码!
🧠 什么是 VOSK?
VOSK 是一款轻量级、支持多语言的 离线语音识别引擎,支持:
- 零依赖运行在本地,不需要联网
- 多语言识别(包含中文)
- 支持 Raspberry Pi、服务器甚至 Android 端部署
- 高准确率,适配普通话、方言、短语音等语境
📎 示例语音下载
在本案例中,我们将使用以下样例音频进行识别:
🎧 下载链接:克隆过滤版output.wav
⚠️ 音频格式踩坑警告(必看)
VOSK 对音频格式的要求非常严格,以下是它的硬性要求:
| 参数 | 要求 |
|---|---|
| 文件格式 | .wav |
| 编码类型 | PCM(未压缩) |
| 声道 | 单声道(mono) |
| 采样率 | 16000Hz 推荐 |
| 采样位深 | 16-bit |
❌ 如果你传入了双声道音频,将报如下错误:
Audio file must be WAV format mono PCM.
这意味着你的音频格式无法解析!
✅ 正确的音频预处理方式
在你传入音频到 VOSK 之前,务必预处理音频为 mono 声道、16kHz、16位 PCM,推荐使用 torchaudio 处理:
import torchaudiodef convert_to_mono_16k(input_path, output_path):signal, sr = torchaudio.load(input_path)if signal.shape[0] > 1:signal = signal.mean(dim=0, keepdim=True) # 转为 monoif sr != 16000:resampler = torchaudio.transforms.Resample(sr, 16000)signal = resampler(signal)torchaudio.save(output_path, signal, 16000)
🧪 VOSK 中文识别核心代码
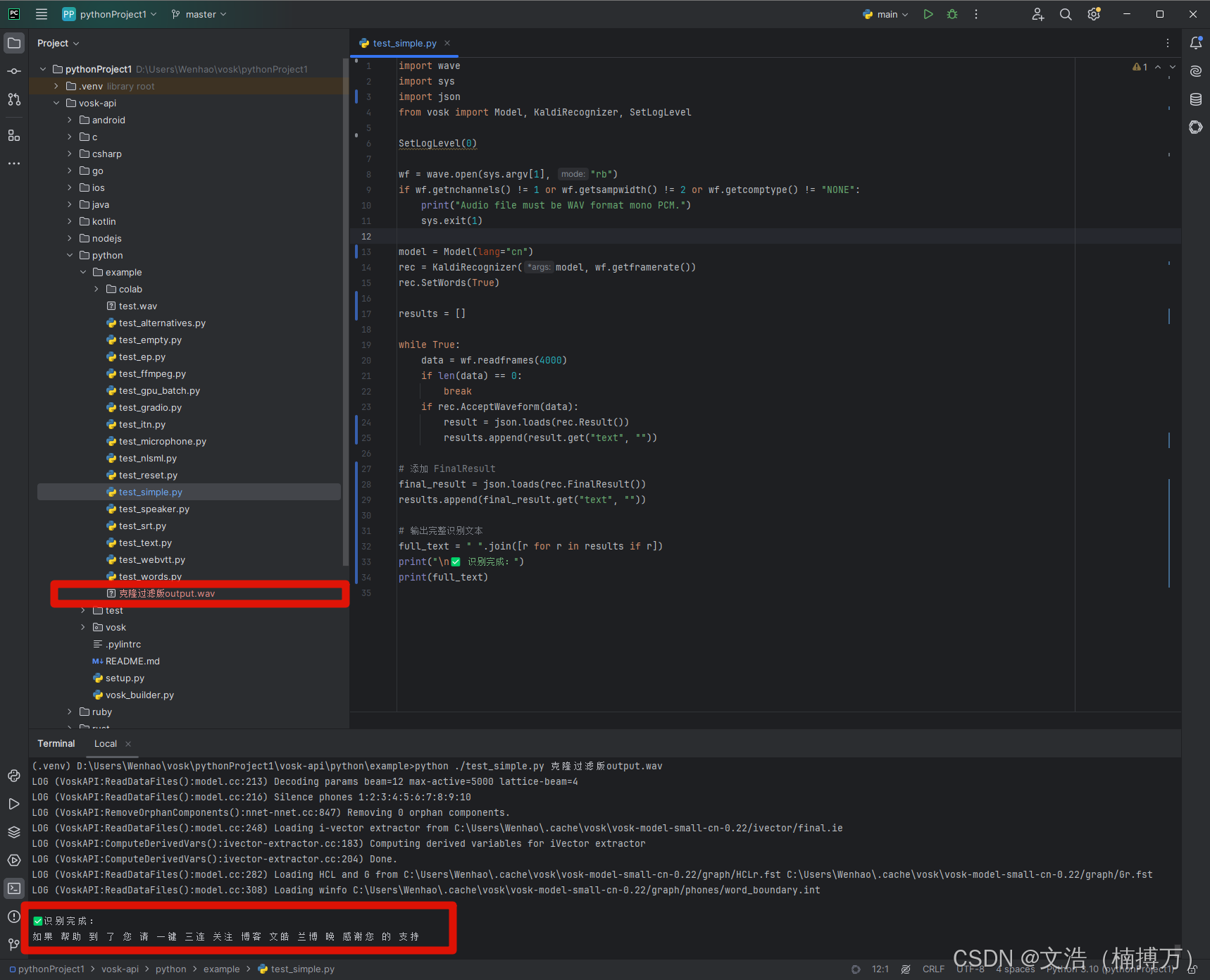
import wave
import sys
import json
from vosk import Model, KaldiRecognizer, SetLogLevelSetLogLevel(0)wf = wave.open(sys.argv[1], "rb")
if wf.getnchannels() != 1 or wf.getsampwidth() != 2 or wf.getcomptype() != "NONE":print("Audio file must be WAV format mono PCM.")sys.exit(1)model = Model(lang="cn")
rec = KaldiRecognizer(model, wf.getframerate())
rec.SetWords(True)results = []while True:data = wf.readframes(4000)if len(data) == 0:breakif rec.AcceptWaveform(data):result = json.loads(rec.Result())results.append(result.get("text", ""))# 添加 FinalResult
final_result = json.loads(rec.FinalResult())
results.append(final_result.get("text", ""))# 输出完整识别文本
full_text = " ".join([r for r in results if r])
print("\n✅ 识别完成:")
print(full_text)
🚀 使用步骤总结
1️⃣ 克隆 VOSK 官方仓库:
git clone https://github.com/alphacep/vosk-api.git
cd vosk-api/python/example
2️⃣ 准备音频并执行识别:
将处理好的音频放入当前目录:
python ./test_simple.py 克隆过滤版output.wav
3️⃣ 示例输出结果:
✅ 识别完成:
如果 帮助 到 了 您 请 一键 三连 关注 博客 文浩 楠博万 感谢您 的 支持
📦 模型说明与更多语言支持
你也可以手动下载并加载 VOSK 的离线模型,中文模型推荐:
- vosk-model-cn-0.22 官方下载地址
加载方式如下:
model = Model("models/vosk-model-cn-0.22")
🧠 应用场景拓展
| 场景 | 示例 |
|---|---|
| 智能字幕生成 | 视频自动添加中文字幕 |
| 会议录音转写 | 本地语音笔记识别并提取文本 |
| 语音控制系统 | 本地识别语音命令,嵌入设备控制 |
| 教育语言学习工具 | 分析学生发音并进行打分反馈 |
✅ 总结
- VOSK 是功能强大的离线语音识别工具,适合中文本地识别需求;
- 使用前务必将音频转换为单声道、16kHz、16-bit PCM,否则将报错;
- 脚本结构清晰,可用于快速部署在视频字幕、对话识别等场景中;
- 推荐结合我前篇 TTS 博客一同参考,掌握音频在识别与合成之间的完整处理流程。
📌 再次推荐点击阅读 ➤
👉 XTTS实现语音克隆:精确控制音频格式与生成流程【TTS的实战指南】
通过上述内容,你就已经基本理解了这个方法,基础用法我也都有展示。如果你能融会贯通,我相信你会很强
Best
Wenhao (楠博万)