技术研究 | 一种检测大模型是否泄露训练数据的新方法
“记忆是什么?是你无意间说出的话,是你不经意重现的句子,是在你以为早已遗忘时,某个点突然对上了光。”当语言模型变得越来越像人类,它们是否也会不小心“记住”本不该记住的事?
在今天这篇文章里,我们将深入解读一项关于「人工智能记忆边界」的研究成果。

无需窥探模型“内脏”,就能精准判断它是否“偷学”了你的数据,这究竟是如何做到的? 故事的序幕,就从一句AI常说的“你是不是偷偷学过我?”开始讲起
👇
“你是不是偷偷学过我?”——大模型“记性太好”惹的祸!
近年来,随着大语言模型(Large Language Models, LLMs)的广泛应用与飞速进步,我们进入了一个由人工智能深度参与信息生成与传播的新时代。ChatGPT、Claude、Gemini 等主流AI聊天工具正在以前所未有的速度融入我们的生产与生活,从日常问答、文案创作到代码辅助与学术研究,LLMs 已成为数字社会的“超级大脑”。然而,正当我们沉浸在这些模型带来的便捷与智能之中,一个愈发严峻的风险正在浮出水面——训练数据的泄露。
这些强大的语言模型是通过大量网络语料训练而成,这其中往往混杂着公开数据、未授权文本,甚至包括某些私人通信记录、受版权保护的内容、以及广泛使用的标准评测集等。一旦模型“记住”了这些本不该公开的语料,在生成新文本时不小心“复述”出来,就可能构成隐私泄露、知识产权侵权,甚至破坏评测体系的公正性,不仅带来法律责任,更模糊了人工智能模型可信度与伦理边界。正因如此,监管机构、模型开发者、数据提供者乃至普通用户对“模型记住了什么?”这一核心问题愈发关切。
在这一背景下,研究者们提出了一个名为“成员推理攻击(Membership Inference Attack, MIA)”的技术路径。MIA的目标是在无需完全读取模型训练数据的前提下,判断某一特定文本是否出现在模型的训练语料中,换句话说,就是让模型自己“泄露”它知道什么。MIA技术的核心价值,在于它为我们提供了一种分析模型记忆能力和数据泄露行为的工具,希望借助它来构建更可控、更安全的AI系统。
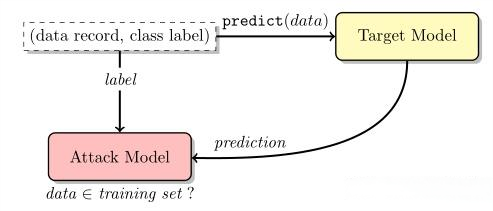
成员推理攻击的含义:本质是一个二分类问题,即判断某个成员记录是否属于目标模型的训练数据
传统的MIA方法大多依赖模型内部的信息——例如输入文本对应的概率(likelihood)或损失值(loss),因为在大多数神经语言模型中,如果一个文本曾被用于训练,那么模型比对其输出会更加“自信”,即赋予更高的概率和更低的损失值。于是研究者通过设定阈值来判断:如果某段文字的生成概率很高,可能就说明它曾出现在模型的训练数据中。这种方法简单有效,但也伴随着致命的前提假设:你得能从模型那里获得这些概率值或损失值。
然而,现实却并不如想象中那样理想。以ChatGPT、Claude、Gemini等闭源商业模型为例,这些系统并不对外公开它们的训练数据,也不提供用户对token-level 概率或loss信息的访问权限。也就是说,我们没有办法知道一个文本在模型眼里到底有多“熟”。结果就是,传统的MIA方法一旦面临这些“黑箱”环境,就完全无用武之地。
那么,在没有这些“内脏数据”——即损失函数值或生成概率的情况下,我们还有其他办法吗?有没有可能仅凭模型“说出来的话”,就推理出它是否见过某段文本?
这正是今天我们要深入介绍的全新技术——SaMIA(Sampling-based Membership Inference Attack)。它采用了一种巧妙的思路来绕过传统方法的限制,在不依赖任何内部概率与损失函数的前提下,仅仅通过模型的自然输出内容,便可高效判断某段文本是否“存在于记忆中”。
SaMIA的最大优势在于,它的适用性远超传统方法。无论你面对的是GPT-J、OPT等开源模型,还是ChatGPT、Gemini这种闭源模型,只要模型能够响应你的输入并生成文本——那么SaMIA就能工作。准确地说,它不需要“解剖”模型,只需要和AI对话,就能得到足以推理其数据来源的信号。
弄清楚了传统方法的局限,我们下一步就要来挖掘SaMIA是如何用“生成的文本”,替代“显式的概率”,精准判断模型训练记忆的。它是如何让语言模型露出“它见过你的样子”的呢?我们接着往下看 👇
“不看内脏,只看嘴”:大模型记没记住你,聊一聊就能试出来!
要理解 SaMIA是如何工作的,我们可以从一个类比开始:你给一个人一句话的前一半,然后让他试着将其补完。如果对方曾经背诵过那句话,他很有可能会复现出相同的表达方式,这种“超正常”记忆能力也许正是他见过这句话的最好证据。
而 SaMIA 的核心正是利用语言模型的“续写”能力来倒推出它是否在训练时见过某个文本。这个过程完全不需要依赖模型的概率或损失等内部信息,而是通过模型的公开接口多次“取样”,再利用文本重合度对目标文本是否“被记过”做出判断。
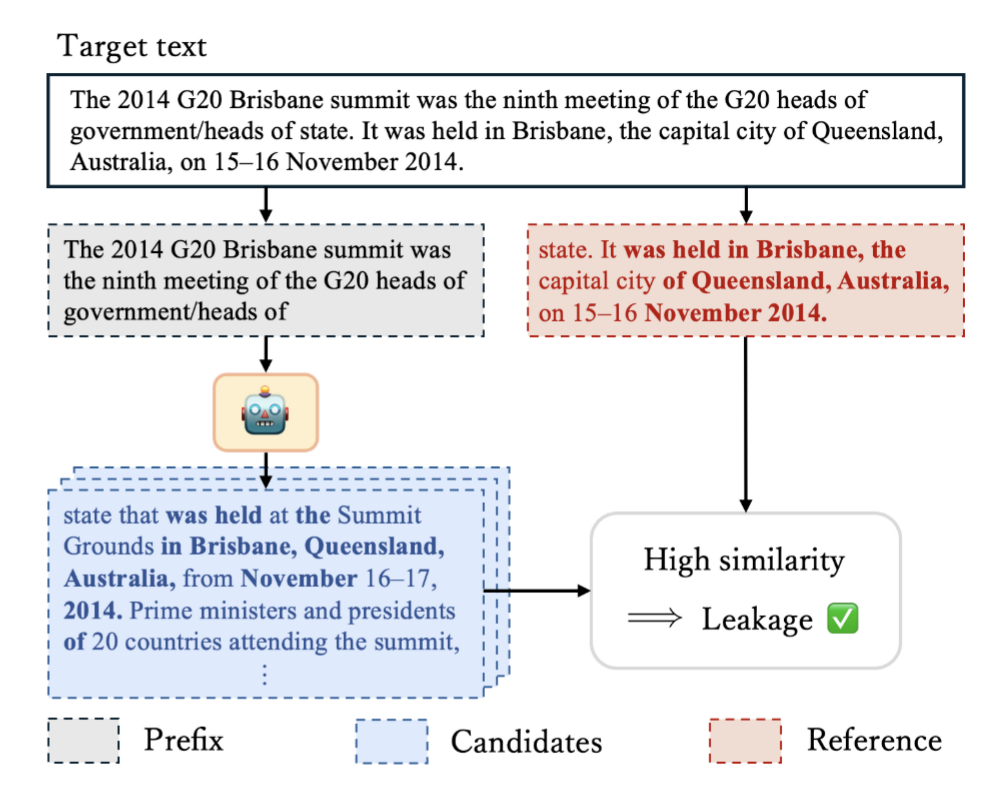
SaMIA进行成员推理的案例,其中最上面的内容是待检测的目标文本,灰色的部分是前缀,红色的部分是参考段,蓝色的部分是候选文本组成的集合,依赖于候选文本和参考段进行相似度的计算
整个方法逻辑上可分四个核心步骤,我们可以配合公式一步步拆开:
第一步:将目标文本切分为前缀与参考段
设目标文本为一个由 个词组成的序列:
作者将其分成两部分:
-
前缀部分(输入给模型):
-
参考文本(用于与生成结果比对):
第二步:采样生成多个候选文本
作者将 作为目标大模型的输入提示,输入给语言模型 ,令其生成个候选续写内容:
这些 就是作者拿来和参考部分做 n-gram 比较的“备选答案”。
第三步:计算表层相似度(ROUGE-N)
作者使用广泛应用于文本生成评价的 ROUGE-N 分数度量模型生成内容与参考文本之间的 n-gram 重合程度,具体计算公式如下:
其中表示参考文本中的n-gram,分子代表匹配的n-gram次数,分母则是参考文本中总的n-gram 数量。
⚡ 例如在使用 ROUGE-1(unigram)时,代表的是生成本中出现了多少“词汇”也出现在了参考段中。这个值越高,暗示生成内容越接近已知参考内容。
第四步:平均所有候选文本的 ROUGE-N 分数,判断是否泄露
最终作者计算所有候选生成文本与参考文本之间 ROUGE 分数的平均值:
接着进行一个简单的比较判断:
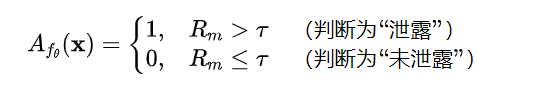
其中是作者根据开发集设置的阈值,用于分辨生成结果是否“过于接近原文”,即模型是否“记住”了参考文本。
若明显高于正常随机生成的相似度值,那说明模型在生成中重现了大量原文结构——被判定为泄露。
可选增强(加入信息压缩指标)
生成文本中若存在“重复、生硬”的生成(如机械性复述),是模型“死记硬背”的信号。还可以利用数据压缩(如 zlib)来辅助判断生成文本的信息冗余度:
提升后的评分机制为:
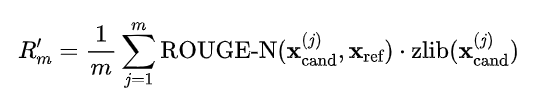
若 ,则同样判断为泄露。这个组合策略在实验中被称为 SaMIA*zlib,是本研究中最具表现力的配置。
整体来看,SaMIA 的设计朴素但极具启发性,它避开了“读取神经网络黑箱”的技术瓶颈,转而通过“观察模型说了什么”,倒推出“它曾见过什么”。这种策略尤其适用于如 ChatGPT、Claude 这类无法查询概率或训练集的闭源系统,也为未来模型合规审查与数据保护提供了一种可行、兼容性强的思路。
接下来的部分我们将展示:SaMIA 在多个开源大模型中的实验结果表现,它如何在不同文本长度、采样数量、判定阈值等设置下实现与传统MIA“看齐甚至超越”的效果。👇
“你生成的样子暴露了你”——SaMIA实测表现优于传统方法?
作者在四个公开开源的大语言模型上对 SaMIA 展开了系统的实证验证,包括 GPT-J-6B、OPT-6.7B、Pythia-6.9B 与 LLaMA-2-7B,它们都是当前学术界广泛认可并可访问其训练数据的中小型模型。
作者选用了 WikiMIA 数据集,作为标准评测基准。WikiMIA 是一个包含 Wikipedia 事件页面的集合,其中:
-
📅 2017 年前的页面为“泄露文本”(曾用于模型训练)
-
📅 2023 年后的页面为“未泄露”(模型未见过)
文本按长度分为 32、64、128 和 256 四个区段,对每种长度都进行拆分、采样与检测,严格对比。
本轮实验中作者关注两个关键指标:
-
AUC(Area Under Curve):判断模型判别能力的综合指标,值越接近 1 越好;
-
TPR@10%FPR:在保持误报率为10%的情况下,真正检出的“泄露”比例,常用于模型部署评估。
Table 1 & Table 2:站上大舞台,SaMIA对比传统方法稳稳不怂
首先亮相的是两张总结性表格,Table 1 和 Table 2,可以说是 SaMIA 实验效果的“成绩单”。
Table 1 展示了四种主流大模型(GPT-J-6B、OPT-6.7B、Pythia-6.9B、LLaMA-2-7B)在进行泄露文本检测时,不同方法的整体表现,包括 AUC 分数与在固定 10% 假阳性率下的 TPR(True Positive Rate)。
而 Table 2 则进一步细化到文本长度维度,分析在不同长度下(32, 64, 128, 256词)的表现变化。
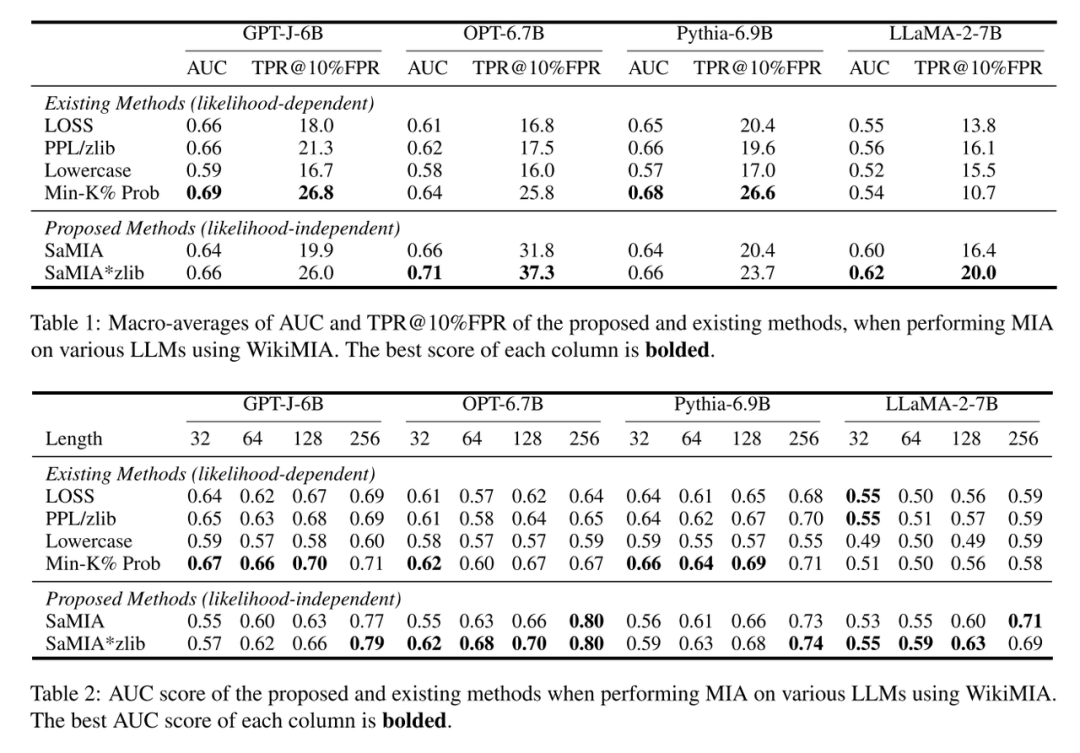
🔥从数据来看,SaMIA*zlib 凭借“不依赖模型概率”的特点,依然能打出超强结果:
-
OPT-6.7B上直接拿下全场最高 AUC 0.71,TPR 达 37.3%
-
即使是“轻量版”SaMIA(不加zlib),在Pythia、GPT-J上表现也与传统强方法持平甚至超越
-
文本越长,模型生成的“既视感”越强,AUC从0.55一路飙升到0.79
一句话总结:SaMIA 不是"勉强能用",而是“能打还能适配闭源模型”,堪称真正的通用解决方案!
ROUGE-1 还是 ROUGE-2?一测即知“谁更灵敏”
我们知道SaMIA判断模型是否见过某段文本,靠的是比对生成文本与真实后缀之间的 n-gram 相似度。那么该用哪种ROUGE指标最合适?这正是 Figure 2 想给出的答案。Figure展示的是在使用 ROUGE-1(unigram)和 ROUGE-2(bigram)做相似度指标时,SaMIA在不同文本长度下的AUC表现。
结论非常清晰: ROUGE-1(单个词匹配)在几乎所有模型和长度下,效果都显著优于 ROUGE-2。特别是长文本(如256词)时,表现差距更加明显!解释也很自然:单词级匹配更灵活,容错性更强,而 bigram 连续两个词同时匹配,本身在生成任务中就更不容易。
所以除非你想“为难”模型,默认 ROUGE-1 是最优选择!
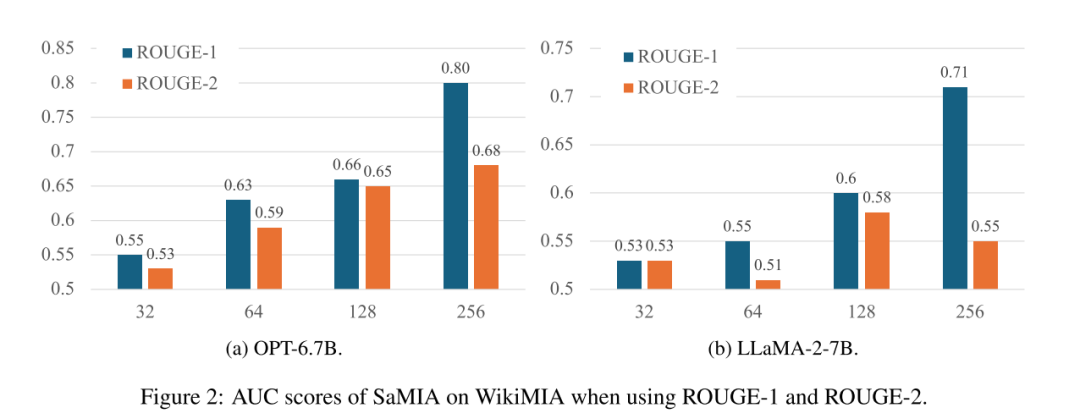
Table 3:召回还是精准更重要?答案是多记一点更重要
Table 3 对比的是使用 n-gram “召回率” 和 “精确率” 时,SaMIA 的检测能力(AUC)。 这里解释一下差别:
-
🔁 召回率(Recall):看的是目标文本中有多少词被模型生成“记起来”
-
🎯 精确率(Precision):看的是模型生成里有多少词正好是目标答案 实验发现:使用精确率时,性能几乎接近“随机猜测”(AUC ≈ 0.5),说明模型即使“胡说”,只要命中率高也不够;而召回率更好地反映了模型是不是在“大量复述”原文。
结论明确:靠谱的“既视感”不是精准复刻,而是“记得多”!
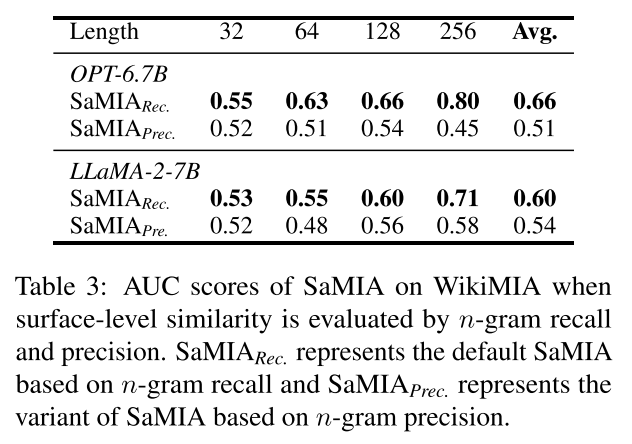
Table 4:生成几次够了?答案是5次就差不多
Table 4 探讨的是 SaMIA 的另一个核心超参——生成候选样本文本数量(sampling size)。

从表中我们可以看到,随着生成样本数从1增加到10,模型的判断准确性(AUC)也逐步上升,但提升在样本数量到达5后趋于平稳:
-
OPT-6.7B 从初始 0.61 提升至 0.66 后基本不动了
-
LLaMA-2-7B 也是 0.59 起步,爬到约 0.60 就封顶
所以结论是:适度采样最优,建议 5 到 10 个生成样本为佳,既能保证性能,又能减少计算成本。
Figure 3:采样越多,效果越好——但也别贪多
这张图就是 Table 4 的可视化扩展版,显示的是在不同文本长度组中,SaMIA 的AUC随采样次数上升的趋势。可以说是形象演绎“小样本提升,大样本收益递减”的原则。
🧠 趋势很清楚:少量样本时(1~3个)性能差异大,提升明显;超过5个后进入“平稳期”,多生成意义不大。
这为实用落地提供关键建议:别拼命调参采100个,5个就能看到模型有没有泄露!
Figure 4:提示词给多了,反而不好用了?
Figure 4 探索的是另一个很关键因素——Prefix长度的设置。默认我们选一半作为提示词(前缀),剩下一半作为参考,但也可以尝试只给25%、或多给75%来“喂模型”。
图中结果非常有趣:
-
给太少(25%):模型信息不足,续写内容与原文差距大 → AUC显著下降
-
给太多(75%):虽然模型上下文很长,但“参考文本太短”可对比信息不足 → 表现也下降!
所以最佳方案:还是维持“50%前缀 + 50%参考”这种黄金比例,保持上下文信息量和可比价值“双平衡”。
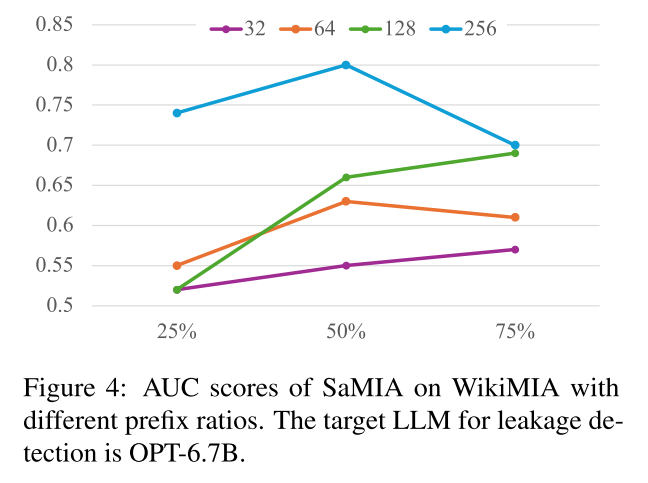
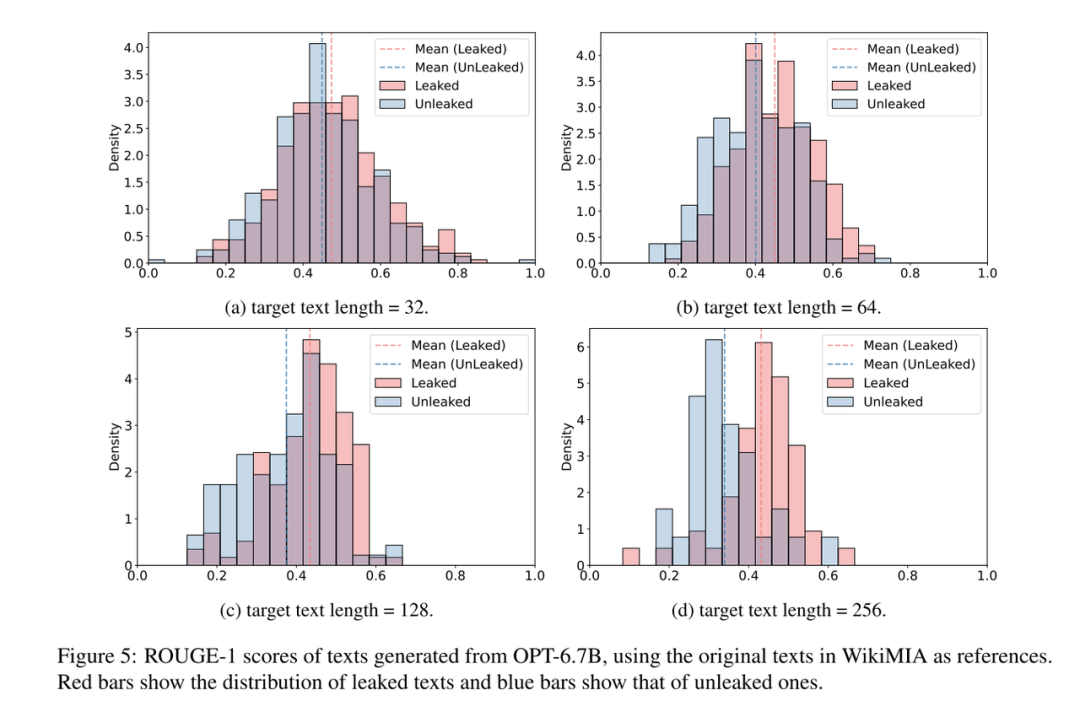
Figure 5:文本越长,模型越容易暴露它记过谁
最后登场的是 Figure 5,这组图展示了 ROUGE-1 相似度分布在“泄露文本”和“未泄露文本”之间的差距,并随着文本长度的增长而扩大。
图里可以看到:
-
当文本较短(32词),泄露与非泄露的相似度差异不大,有一定重叠
-
但随着文本长度增加到256词,两者之间的“距离”明显打开,泄露文本拥有显著更高的ROUGE分数
这说明:越长的文本含有越丰富的上下文“锚点”,能帮助语言模型更准确地联想并复现“学过的内容”,显著提升SaMIA检测准确性。
换句话说:短文靠猜,长文靠记,模型离谱不离谱,一试长文知分晓!
从采样样本数,到 n-gram 指标选择,再到 prefix 控制与目标文本长度,每一部分实验内容都精准诠释了 SaMIA 方法的原理与边界。既科学也实用,真正做到了理论落地,豹变成真!
总结
从传统的概率推理到SaMIA的“只问输出不问缘由”,这项研究告诉我们一个朴素却极具现实意义的道理:当模型越强大、语言越流畅,它也可能越像一个“背书熟练”的考生,在你不经意间复述出它曾背过的一切。
SaMIA 不仅是一种创新的检测工具,更像是一面镜子,提醒我们——模型记住的不只是知识,还有我们未曾授权的痕迹。
它打破了传统对概率和损失的依赖,凭借“输出行为”就能反推出模型“是否见过你”,这不仅解决了在闭源模型上的MIA困境,也为未来的模型安全治理、隐私保护、版权合规提供了有力武器。
更重要的是,它让我们开始思考一个技术之外的问题——当AI越来越像我们,是不是也应该学会忘记?