Verilog:流水线乘法器
模块介绍:16位有符号数 流水线乘法器
目录
一、流水线乘法器
1. 端口定义
2. 设计思路
二、verilog 代码
三、仿真波形
四、写在最后
参考文章:
1. 第十七课——用FPGA实现定点数的乘法
2.「Verilog学习笔记」流水线乘法器
一、流水线乘法器
1. 端口定义
| 端口名称 | 方向 | 位宽 | 描述 |
|---|---|---|---|
| clk | input | 1 | 系统时钟信号,用于同步所有流水线操作 |
| rst_n | input | 1 | 异步复位信号,低电平有效 |
| mul_in_valid | input | 1 | 输入数据有效标志,高电平表示当前输入的乘数和被乘数有效 |
| mul_a | input | 16 | 16位有符号被乘数(补码形式) |
| mul_b | input | 16 | 16位有符号乘数(补码形式) |
| mul_out_valid | output | 1 | 输出结果有效标志,高电平表示乘法结果有效 |
| mul_out | output | 32 | 32位有符号乘法结果(补码形式) |
2. 设计思路
乘法器采用部分积"两两累加"的加法树结构,通过五级流水线实现,最后一级为输出级:
-
第一级:加法树第一级,将生成部分积并进行初步两两相加
-
第二级:加法树第二级,第一级结果两两相加
-
第三级:加法树第三级,第二级结果两两相加
-
第四级:加法树第四级,完成最终累加
-
第五级(输出级):处理符号位并输出补码结果
二、verilog 代码
`timescale 1ns/1ns
// 乘法器 16位有符数 流水线结构
module multi_16bit_sign_pipe(input clk , input rst_n ,input mul_in_valid ,input [15:0] mul_a ,input [15:0] mul_b ,output reg mul_out_valid ,output reg [31:0] mul_out
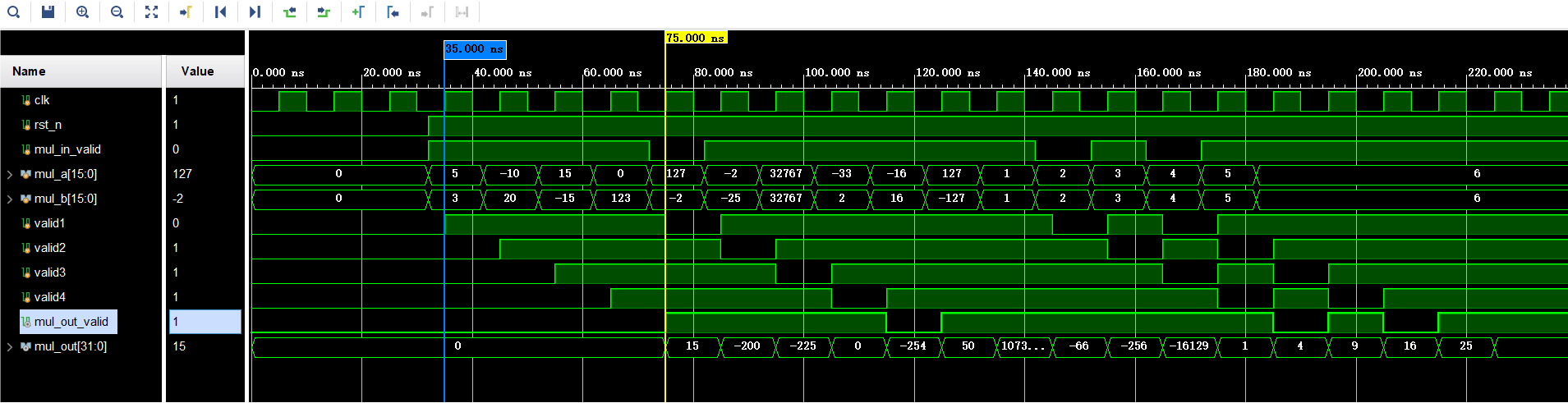
); reg [30:0] sum01, sum23, sum45, sum67, sum89, sum1011, sum1213, sum14; //第一级加法寄存器reg [30:0] sum0_3, sum4_7, sum8_11, sum12_14; //第二级加法寄存器reg [30:0] sum0_7, sum8_14; //第三级加法寄存器reg [30:0] sum; //第四级加法寄存器reg sign1, sign2, sign3, sign4; //符号位寄存器reg valid1, valid2, valid3, valid4; //输入有效号寄存器wire sign0 = mul_a[15] ^ mul_b[15]; //符号计算wire [14:0] unsign_mul_a = mul_a[15] ? (~mul_a[14:0]+1) : mul_a[14:0]; //补码(数值位)转原码wire [14:0] unsign_mul_b = mul_b[15] ? (~mul_b[14:0]+1) : mul_b[14:0]; wire [29:0] p0, p1, p2, p3 ,p4, p5, p6, p7, p8, p9, p10 ,p11, p12, p13, p14; //部分积 partial_productassign p0 = unsign_mul_b[0] ? {15'b0, unsign_mul_a} : 0 ; assign p1 = unsign_mul_b[1] ? {14'b0, unsign_mul_a, 1'b0} : 0 ; assign p2 = unsign_mul_b[2] ? {13'b0, unsign_mul_a, 2'b0} : 0 ; assign p3 = unsign_mul_b[3] ? {12'b0, unsign_mul_a, 3'b0} : 0 ; assign p4 = unsign_mul_b[4] ? {11'b0, unsign_mul_a, 4'b0} : 0 ; assign p5 = unsign_mul_b[5] ? {10'b0, unsign_mul_a, 5'b0} : 0 ; assign p6 = unsign_mul_b[6] ? { 9'b0, unsign_mul_a, 6'b0} : 0 ; assign p7 = unsign_mul_b[7] ? { 8'b0, unsign_mul_a, 7'b0} : 0 ; assign p8 = unsign_mul_b[8] ? { 7'b0, unsign_mul_a, 8'b0} : 0 ; assign p9 = unsign_mul_b[9] ? { 6'b0, unsign_mul_a, 9'b0} : 0 ; assign p10 = unsign_mul_b[10] ? { 5'b0, unsign_mul_a, 10'b0} : 0 ; assign p11 = unsign_mul_b[11] ? { 4'b0, unsign_mul_a, 11'b0} : 0 ; assign p12 = unsign_mul_b[12] ? { 3'b0, unsign_mul_a, 12'b0} : 0 ; assign p13 = unsign_mul_b[13] ? { 2'b0, unsign_mul_a, 13'b0} : 0 ; assign p14 = unsign_mul_b[14] ? { 1'b0, unsign_mul_a, 14'b0} : 0 ; always @ (posedge clk or negedge rst_n) begin if (!rst_n) begin //复位全级寄存器valid1 <= 0; sign1 <= 0; sum01 <= 0; sum23 <= 0; sum45 <= 0; sum67 <= 0; sum89 <= 0; sum1011 <= 0; sum1213 <= 0; sum14 <= 0; //第一级寄存器valid2 <= 0; sign2 <= 0; sum0_3 <= 0; sum4_7 <= 0; sum8_11 <= 0; sum12_14 <= 0; //第二级寄存器valid3 <= 0; sign3 <= 0; sum0_7 <= 0; sum8_14 <= 0; //第三级寄存器valid4 <= 0; sign4 <= 0; sum <= 0; //第四级寄存器mul_out_valid <= 0; mul_out <= 0; //第五级寄存器end else begin //第一级流水线valid1 <= mul_in_valid;sign1 <= sign0;sum01 <= p0 + p1; sum23 <= p2 + p3; sum45 <= p4 + p5; sum67 <= p6 + p7; sum89 <= p8 + p9; sum1011 <= p10 + p11; sum1213 <= p12 + p13; sum14 <= p14;//第二级流水线valid2 <= valid1; sign2 <= sign1;sum0_3 <= sum01 + sum23; sum4_7 <= sum45 + sum67; sum8_11 <= sum89 + sum1011; sum12_14 <= sum1213 + sum14; //第三级级流水线valid3 <= valid2;sign3 <= sign2;sum0_7 <= sum0_3 + sum4_7; sum8_14 <= sum8_11 + sum12_14; //第四级流水线valid4 <= valid3;sign4 <= sign3;sum <= sum0_7 + sum8_14; //第五级流水线mul_out_valid <= valid4; mul_out <= sign4 ? {1'b1, ~sum+1} : {1'b0, sum}; //转补码endend endmodule三、仿真波形
tb 文件如下:
`timescale 1ns/1ps
module tb_multi_16bit_sign_pipe;reg clk;reg rst_n;reg mul_in_valid;reg signed [15:0] mul_a; reg signed [15:0] mul_b;wire mul_out_valid;wire [31:0] mul_out; // 实例化被测模块multi_16bit_sign_pipe uut (.clk (clk),.rst_n (rst_n),.mul_in_valid (mul_in_valid),.mul_a (mul_a),.mul_b (mul_b),.mul_out_valid (mul_out_valid),.mul_out (mul_out)); // 10ns时钟生成initial beginclk = 0;forever #5 clk = ~clk; // 5ns高低电平,周期10nsend// 测试序列(连续输入10个测试数据,测试流水线乘法器)initial begin// 复位阶段rst_n = 0;mul_in_valid = 1'b0;mul_a = 0;mul_b = 0;#32; // 复位rst_n = 1;// 测试用例1: 5 x 3 = 15mul_in_valid = 1'b1;mul_a = 5;mul_b = 3;#10; // 测试用例2: -10 x 20 = -200mul_a = -10;mul_b = 20;#10;// 测试用例3: 15 x -15 = -225mul_a = 15;mul_b = -15;#10;// 测试用例4: 0 x 123 = 0mul_a = 0;mul_b = 123;#10;// 测试用例5: 120 x -2 = -254-----------------插入一个输入无效数据mul_in_valid = 1'b0;mul_a = 127;mul_b = -2;#10;mul_in_valid = 1'b1;// 测试用例6: -2 x -25 = 50mul_a = -2;mul_b = -25;#10;// 测试用例7: 32767(最大值) x 32767 = 1073676289mul_a = 32767;mul_b = 32767;#10;// 测试用例8: -33 x 2 = -66mul_a = -33;mul_b = 2;#10;// 测试用例9: -16 x 16 = -256mul_a = -16;mul_b = 16;#10;// 测试用例10: 127 x -127 = -16129mul_a = 127;mul_b = -127;#10;// 测试用例11: 1 x 1 = 1mul_a = 1;mul_b = 1;#10;// 测试用例12: 2 x 2 = 4-----------------插入一个输入无效数据mul_in_valid = 1'b0;mul_a = 2;mul_b = 2;#10;mul_in_valid = 1'b1;// 测试用例13: 3 x 3 = 9mul_a = 3;mul_b = 3;#10;// 测试用例14: 4 x 4 =16-----------------插入一个输入无效数据mul_in_valid = 1'b0;mul_a = 4;mul_b = 4;#10;mul_in_valid = 1'b1;// 测试用例15: 5 x 5 = 25mul_a = 5;mul_b = 5;#10;// 测试用例16: 6 x 6 = 36mul_a = 6;mul_b = 6;#10;#70;$finish;endendmodule可以看到乘法计算结果正确,输入有效数据在时钟上升沿触发后,经过4个时钟周期输出有效运算结果(数据实际上在第5个时钟周期上升沿才会被下一级模块捕获,数据到下一级就是5个时钟周期延时),这里我把每一级的有效信号寄存器添加到波形中了,以便观察。
四、写在最后
设计的这个乘法器用的是最基本的部分积累加方法实现,不过缺点是16位数据相乘就有16个部分积所以当数据位数越大,加法树就越复杂,流水线计数也越多。体现到电路中就是:面积大、功耗高、计算延迟高。
所以为了实现快速的计算以及更加简单电路结构需要采用更好的算法与加法树结构,例如使用booth、booth2对乘数进行编码可以减少部分积数量,采用Wallace树结构可以减少中间计算结果数量(这两个方法后面有时间就整理一下),此外还有很多算法和结构都可以实现更优的乘法器设计。