【Cross-Language Binary-Source Code Matching with Intermediate Representations】
Cross-Language Binary-Source Code Matching with Intermediate Representations
- 《基于中间表示的跨语言二进制-源代码匹配》
- Yi Gui1, Yao Wan1∗, Hongyu Zhang2, Huifang Huang3, Yulei Sui4, Guandong Xu4, Zhiyuan Shao1, Hai Jin1
- Huazhong University of Science and Technology, Wuhan, China
摘要
二进制-源代码匹配在恶意软件检测、逆向工程和漏洞评估等许多安全与软件工程相关任务中起着重要作用。目前,已有若干方法通过在公共向量空间中联合学习二进制代码和源代码的嵌入来解决二进制-源代码匹配问题。尽管已有大量研究,但现有方法主要针对单一编程语言编写的二进制代码和源代码的匹配。然而在实际场景中,软件应用程序常为满足不同需求和计算平台而采用不同编程语言编写。跨编程语言的二进制-源代码匹配在维护多语言、多平台应用时带来了额外挑战。
为此,本文首次提出跨语言二进制-源代码匹配问题,并针对这一新问题构建了新的数据集。我们提出一种基于Transformer的神经网络方法XLIR,通过学习二进制代码和源代码的中间表示来解决该问题。为验证XLIR的有效性,我们在自建数据集上针对跨语言二进制-源代码匹配和跨语言源代码-源代码匹配两项任务进行了全面实验。实验结果与分析表明,所提出的基于中间表示的XLIR方法在两项任务中均显著优于其他最先进模型。
一、引言
二进制-源代码匹配旨在衡量二进制代码与源代码之间的相似性,在恶意软件检测[1]、漏洞搜索[2]和逆向工程[3][4]等众多安全与软件工程相关任务中发挥着重要作用。一方面,给定一个二进制代码片段,检索相似的源代码片段可为逆向工程提供参考;另一方面,给定一个存在漏洞的源代码,检查其对应的二进制形式是否包含在某个二进制文件中,有助于进行漏洞评估与检测。
现有工作与局限
二进制-源代码匹配的核心技术是跨两种模态(即二进制和源代码)的语义相似性计算。据我们所知,当前大多数方法主要关注单一模态内的匹配,例如源代码-源代码匹配[5]或二进制-二进制匹配[6]。近年来,已有一些研究探讨二进制-源代码匹配问题:Yuan等人[7]和Miyani等人[3]分别针对开源软件重用检测和二进制源代码溯源展开研究;Yu等人[8]则从函数级别研究了二进制与源代码的跨模态匹配。这些方法均通过提取源代码和二进制代码的语义特征,利用两个编码器网络将其表示为隐藏向量,并设计相似性约束(如三元组损失函数)联合学习这两个编码器。
尽管二进制-源代码匹配已取得一定进展,但现有工作均仅针对同一编程语言编写的程序。然而,检测不同编程语言的二进制-源代码克隆在学术界尚未取得显著进展。实际场景中,软件应用常为适应不同平台而采用不同编程语言开发,因此跨语言二进制-源代码克隆检测具有重要现实意义。例如,当发现某个二进制代码存在漏洞时,需要检索所有可能编程语言的相关源代码片段,以更全面地评估漏洞。为此,本文首次提出跨语言二进制-源代码匹配问题。
核心思路
二进制-源代码匹配的关键挑战在于弥合高级编程语言与低级机器码之间的语义鸿沟(即使二者文本形式差异显著)。现有方法试图通过端到端方式对齐二进制与源代码的语义嵌入。在编译器中,中间表示(IR)被设计为支持多种前端编程语言(如C、Java)和后端架构(如ARM、MIPS)。中间表示通常独立于编程语言和计算机架构,通过共享相似的词汇表和语法结构,可显著缩小二进制与源代码之间的语义差距。
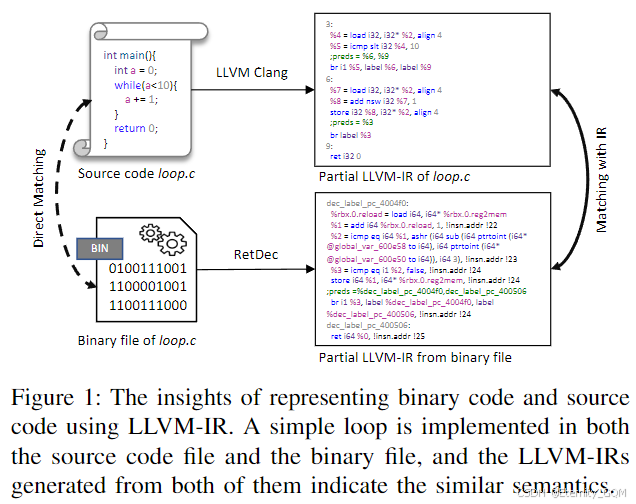
如图1所示,一段源代码片段和二进制代码片段及其对应的LLVM-IR表明:通过编译器工具(如LLVM Clang¹和RetDec²)可将源代码和二进制代码转换为LLVM-IR。在该示例中,源代码文件和二进制文件均实现了一个while循环,尽管文本形式难以直接看出语义相似性,但二者的LLVM-IR(右侧部分)均体现了循环片段的语义。这表明,中间表示有助于统一多语言、多架构的源代码与二进制代码的表示。
解决方案与贡献
受上述思路启发,本文提出XLIR——一种基于Transformer的跨语言二进制-源代码匹配方法,利用中间表示(IR)解决问题。具体而言:
- 代码转换:将二进制代码和源代码解析为中间表示(本文采用广泛应用于编译器优化、程序分析的LLVM-IR),其可从多种高级语言(如C/C++、Java)及低级机器码转换而来。
- 特征嵌入:采用基于Transformer的神经网络对LLVM-IR进行嵌入,首先在大规模外部LLVM-IR语料库上通过掩码语言模型预训练(类似CodeBERT[19]和OSCAR[20]),再将嵌入映射到公共空间并利用三元组损失联合学习。
- 数据集构建:针对跨语言二进制-源代码匹配领域缺乏公开数据集的问题,本文基于现有跨语言源代码匹配数据集构建了新的评估数据集。
实验结果表明,XLIR在跨语言二进制-源代码匹配和跨语言源代码-源代码匹配任务中均显著优于现有先进模型。例如,在Java二进制代码与C源代码的匹配中,相比 state-of-the-art工具B2SFinder,XLIR的精确率、召回率和F1值分别从0.35、0.41、0.38提升至0.68、0.55、0.61。
主要贡献如下:
- 新问题定义:首次提出跨语言二进制-源代码匹配问题,填补了多语言、多平台软件维护中的研究空白。
- 新方法与技术:利用中间表示(LLVM-IR)弥合二进制与源代码的语义鸿沟,提出基于Transformer的IR-BERT预训练模型,有效提升跨模态匹配精度。
- 全面实验验证:构建首个跨语言二进制-源代码匹配数据集,在两项任务上验证了XLIR的有效性,为后续研究提供了基准。
二、研究动机
在本节中,我们首先介绍跨语言代码克隆检测任务,然后将其扩展到跨语言二进制-源代码匹配任务。我们还将展示跨语言二进制-源代码匹配的两个实际应用场景。
A. 跨语言代码克隆检测
检测代码克隆在软件维护和重构中至关重要。现有研究主要集中于识别单一编程语言的代码克隆。然而,随着多语言平台的兴起(应用程序常为满足不同需求和计算平台而使用不同编程语言开发),跨语言代码克隆检测变得日益重要。例如,在软件协同开发中,当Java开发者修改某代码片段时,需要将变更同步到C开发者编写的对应代码片段;当开发者在某语言的代码片段中发现漏洞时,也需要在其他语言中定位对应的代码片段。跨语言代码克隆检测的核心在于:尽管源代码片段以不同编程语言编写且文本形式差异显著,但可能共享相似语义。
B. 跨语言二进制-源代码匹配
本文将跨语言代码克隆检测(即跨语言源代码-源代码匹配)扩展至跨语言二进制-源代码匹配。我们通过两个实际场景说明该任务的动机,如图2所示:
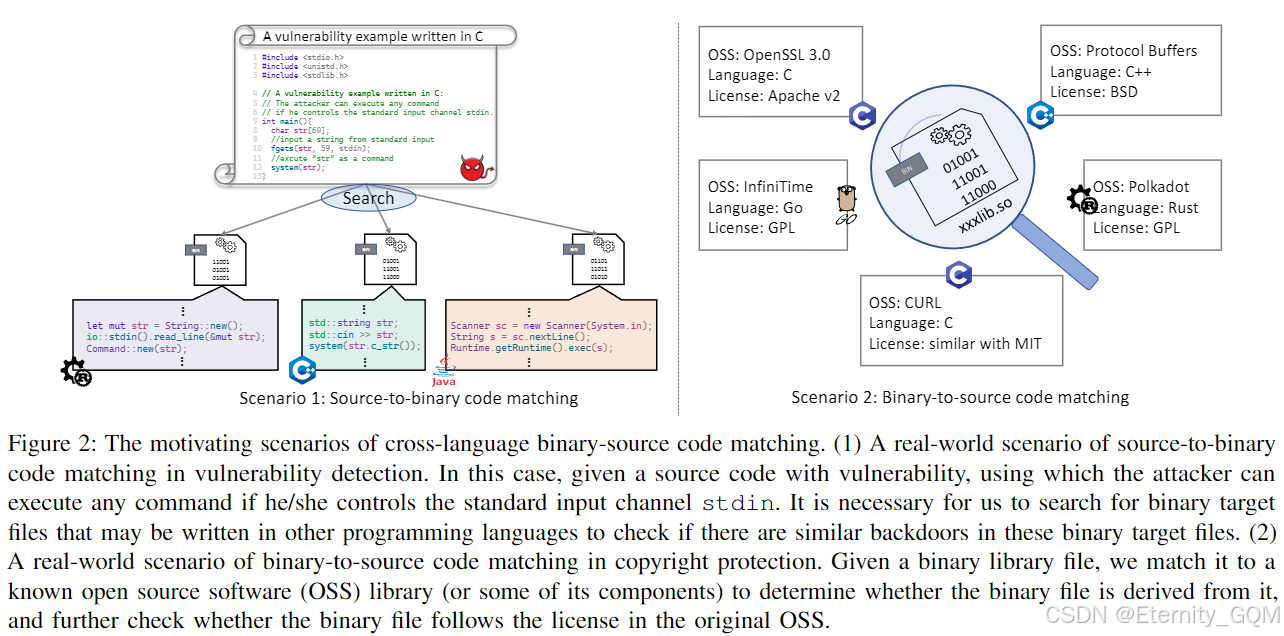
场景1:漏洞检测中的源代码-二进制代码匹配
如图2(1)所示,给定一段用C语言编写的漏洞源代码(程序从标准输入流接受字符串并作为命令执行),若攻击者控制输入流,可在目标机器上执行任意命令。此类漏洞的本质是程序直接将输入作为命令执行,而这种简单实现的后门模式可能存在于其他语言编写的二进制文件中。若能将漏洞源代码直接与二进制代码匹配,便可在现有二进制文件中发现此类漏洞模式。
场景2:版权保护中的二进制-源代码匹配
软件开发中引入不同语言的开源软件(OSS)库非常普遍,而不同OSS库可能采用不同开源协议(如GPL、Apache、BSD、MIT等)。例如,GPL协议要求修改后的代码必须遵循GPL协议。如图2(2)所示,给定一个二进制库文件,若能确定其源自哪个OSS库(或组件),便可检查其是否遵循原库协议,这对版权保护具有重要意义。在此类场景中,跨语言二进制-源代码匹配可发挥关键作用。
直接匹配由机器指令组成的二进制文件与源代码文件需要专业知识和技能,通常非常复杂,因此亟需一种端到端的解决方案。
三、预备知识
A. 中间表示(IR)
中间表示(Intermediate Representation, IR)是程序的一种定义明确、结构规范的表示形式,具有简洁的语法规则,供编译器在将源代码转换为目标代码时使用。现代编译器首先解析源代码,将其转换为IR,然后从IR生成目标代码。这一中间层具有双向独立性,即IR既独立于源代码,也独立于目标机器,同时保留程序的语义。因此,IR构成了我们跨语言匹配方法的基础。本文采用LLVM-IR,这是LLVM架构[9]首次提出的一种特定类型的IR。LLVM-IR不仅包含源代码的语义,还采用静态单赋值(Static Single Assignment, SSA)形式[10],其中每个局部变量仅被赋值一次。
LLVM最初为C和C++设计,其语言无关的设计催生了多种前端(如C#、Rust)。常用编程语言编写的源代码可轻松编译为LLVM-IR,二进制文件也可通过工具反编译为LLVM-IR。我们将源代码和二进制文件均转换为LLVM-IR,然后通过编码器处理以获得潜在向量。计算向量之间的相似性后,即可检测源代码-源代码、源代码-二进制或二进制-源代码克隆。通过这种方式,我们能够实现通用的端到端代码克隆检测方法。
B. 代码嵌入
代码嵌入(Code Embedding),又称代码表示学习,旨在将程序的语义保留到分布式向量中,是当前基于深度学习的程序分析的核心。据我们所知,根据所表示的代码特征,当前代码嵌入可分为四类:标记序列、抽象语法树(AST)、中间表示(IR)和代码图。基于文本标记表示代码是自然的选择,这些标记反映了代码的词法信息。为表示代码的结构信息,多项研究[11]-[13]提出使用结构神经网络(如TreeLSTM和GGNN)表示AST和代码图(如控制流图和数据流图)。近年来,一些研究[16]-[18]提出使用IR表示代码的低级信息。
C. 问题形式化
我们正式定义跨语言二进制-源代码匹配问题。需要注意的是,作为初步研究,本文将范围限定为文件级的跨语言二进制代码和源代码匹配。设 S ( l u ) = { s 1 ( l u ) , s 2 ( l u ) , … , s n ( l u ) } S^{(l_{u})} = \{s_{1}^{(l_{u})}, s_{2}^{(l_{u})}, \dots, s_{n}^{(l_{u})}\} S(lu)={s1(lu),s2(lu),…,sn(lu)}表示用编程语言 l u l_{u} lu编写的源代码文件集合, B ( l v ) = { b 1 ( l v ) , b 2 ( l v ) , … , b n ( l v ) } B^{(l_{v})} = \{b_{1}^{(l_{v})}, b_{2}^{(l_{v})}, \dots, b_{n}^{(l_{v})}\} B(lv)={b1(lv),b2(lv),…,bn(lv)}表示由 S ( l u ) S^{(l_{u})} S(lu)中语义等价的程序(用不同编程语言 l v l_{v} lv实现)编译而成的二进制文件集合。当 l u l_{u} lu和 l v l_{v} lv为同一编程语言时,该任务退化为文献[8]中研究的二进制-源代码匹配任务。给定成对的源代码文件及其对应的二进制文件,本文的目标是分别学习两者的嵌入,然后在公共空间中对齐这些嵌入。其核心思想是:真实配对的源代码和二进制代码的嵌入应相似,而非配对的源代码和二进制代码的嵌入应尽可能不同。
形式化地,给定源代码文件 s i ( l u ) s_{i}^{(l_{u})} si(lu)和二进制文件 b j ( l v ) b_{j}^{(l_{v})} bj(lv),它们的嵌入分别表示为 s i \mathbf{s}_{i} si和 b j \mathbf{b}_{j} bj。我们通过映射函数 ϕ \phi ϕ和 Φ \Phi Φ将源代码和二进制的嵌入映射到公共特征空间:
S → ϕ V S , B → Φ V B , J ( V S , V B ) \mathcal{S} \stackrel{\phi}{\to} V_{\mathcal{S}}, \quad \mathcal{B} \stackrel{\Phi}{\to} V_{\mathcal{B}}, \quad J(V_{\mathcal{S}}, V_{\mathcal{B}}) S→ϕVS,B→ΦVB,J(VS,VB)
其中, J ( ⋅ , ⋅ ) J(\cdot, \cdot) J(⋅,⋅)表示相似性函数(如余弦相似性),用于衡量 V S V_{\mathcal{S}} VS和 V B V_{\mathcal{B}} VB的匹配程度,以学习映射函数。
本文认为,源代码和二进制代码属于不同的特征空间,因此提出先将它们映射到更接近的IR特征空间。具体而言,我们可以将源代码和二进制代码均解析为IR,然后基于IR联合学习它们的嵌入。因此,公式(1)可重新表示为:
S → 解析器 S r → ϕ V S , B → 解析器 B r → Φ V B , J ( V S , V B ) \mathcal{S} \stackrel{\text{解析器}}{\to} \mathcal{S}_{r} \stackrel{\phi}{\to} V_{\mathcal{S}}, \quad \mathcal{B} \stackrel{\text{解析器}}{\to} \mathcal{B}_{r} \stackrel{\Phi}{\to} V_{\mathcal{B}}, \quad J(V_{\mathcal{S}}, V_{\mathcal{B}}) S→解析器Sr→ϕVS,B→解析器Br→ΦVB,J(VS,VB)
公式(1)和(2)表明,我们可以将源代码和二进制代码的匹配问题从原始文本表示转换为中间层的IR表示。
四、跨语言二进制-源代码匹配
在本节中,我们将介绍针对基于中间表示(IR)的跨语言二进制-源代码匹配任务设计的XLIR方法。
A. 整体架构
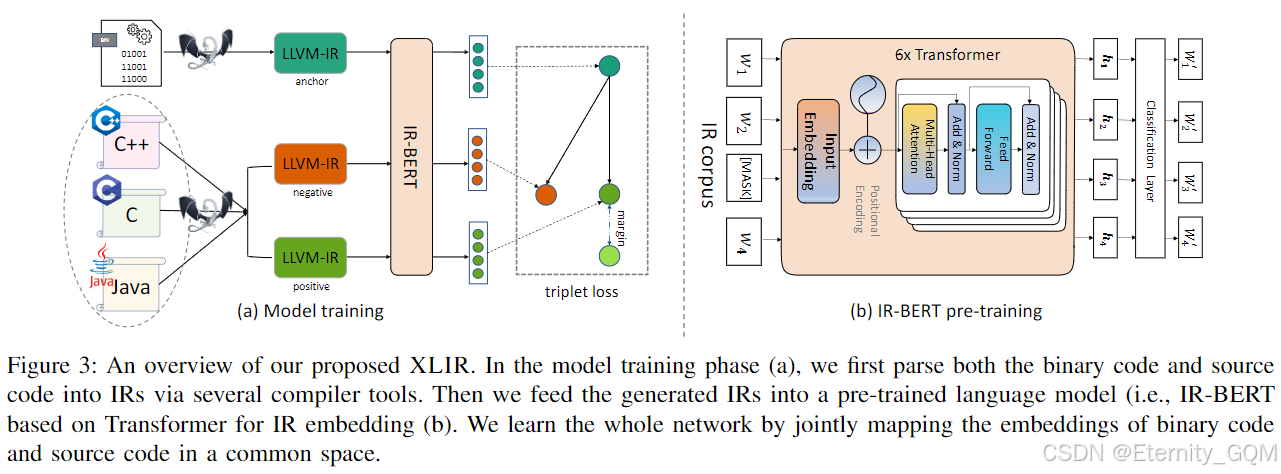
图3展示了我们提出的XLIR的整体架构。模型训练阶段包括以下三个步骤:
- 将源代码和二进制代码转换为IR(参见IV-B节):首先通过多个编译器工具(即LLVM Clang³和JLang⁴)将不同编程语言的二进制代码和源代码解析为IR。目前,我们支持C、C++和Java编程语言。
- 基于Transformer的IR嵌入(参见IV-C节):为了表示生成的IR,我们将其输入到预训练的基于Transformer的语言模型(即IR-BERT)中进行IR嵌入。我们遵循CodeBERT[19]和OSCAR[20]的方法,在大规模IR语料库上预训练一个掩码语言模型,这两种模型分别是在代码语料库和IR语料库上预训练的模型。
- 模型学习(参见IV-D节):为了关联成对的二进制代码和源代码的嵌入,我们首先将它们映射到一个公共特征空间,并联合学习它们的相关性。
模型训练完成后,在代码匹配阶段,使用余弦相似度来衡量二进制代码和源代码之间的语义相似度。当匹配分数大于预定义的阈值时,表明跨语言的二进制代码和源代码匹配成功。
B. 将源代码和二进制代码转换为IR
在跨语言场景中,我们选择C、C++和Java作为源编程语言,因为这些成熟的过程式语言的解析器已经得到了很好的发展。此外,我们还选择LLVM-IR作为中间表示,原因如下:
(1)LLVM-IR与源语言无关,这使得具有相同语义的不同编程语言将保持相似的IR结构;
(2)LLVM-IR也与目标架构无关,并且在实践中从LLVM-IR转换为任何与目标相关的汇编代码都很容易;
(3)LLVM-IR得到了社区的广泛认可,这可以简化代码转换,例如反编译、优化和语义提取。
为了严谨起见,为了避免在编译过程中函数和变量名等字符串信息泄露到二进制文件中,我们在编译时向编译器传递“-s”参数以剥离所有调试信息。
在训练数据准备阶段,我们利用各种工具将不同的程序表示转换为LLVM-IR。该过程适用于程序的两种主要表示形式:源代码和二进制代码。对于源代码,我们使用LLVM Clang¹将C和C++代码编译为LLVM-IR,这是LLVM社区官方支持的。我们使用Jlang⁴和Polyglot⁵将Java代码翻译为LLVM-IR。对于二进制代码,我们使用RetDec反编译器²将未混淆的二进制文件转换为LLVM-IR。混淆是指故意创建难以理解的源代码或二进制代码的行为,混淆代码中的语义信息被认为更难提取,但这种形式的代码范围有限。
需要注意的是,LLVM-IR有两种表示形式,它们持有完全相同的语义信息。位码(bitcode)格式专门为机器处理而设计,例如代码转换和自动优化。机器IR(MIR)格式是人类可读的,已广泛用于程序调试和分析。为了提高效率,我们使用位码格式作为代码嵌入的IR通用表示。
C. 基于Transformer的LLVM-IR嵌入
我们采用Transformer[21]进行LLVM-IR嵌入。Transformer基于自注意力机制,已成为源代码嵌入的流行模型。如图3(b)所示,Transformer模型由K层块组成,这些块可以将一系列指令编码为不同级别的上下文表示: H k = [ h 1 k , h 2 k , … , h n k ] H^{k} = [h_{1}^{k}, h_{2}^{k}, \dots, h_{n}^{k}] Hk=[h1k,h2k,…,hnk],其中 k k k表示第 k k k层。对于每一层,层表示 H k H^{k} Hk由第k层的Transformer块计算得到: H k = Transformer k ( H k − 1 ) H^{k} = \text{Transformer}_{k}(H^{k-1}) Hk=Transformerk(Hk−1), k ∈ { 1 , 2 , … , K } k \in \{1, 2, \dots, K\} k∈{1,2,…,K}。
在每个Transformer块中,多个自注意力头用于聚合前一层的输出向量。一般的注意力机制可以表示为使用查询向量Q和键向量K对值向量V进行加权求和:
Att ( Q , K , V ) = softmax ( Q K T d model ) ⋅ V \text{Att}(Q, K, V) = \text{softmax}\left(\frac{QK^{T}}{\sqrt{d_{\text{model}}}}\right) \cdot V Att(Q,K,V)=softmax(dmodelQKT)⋅V
其中, d model d_{\text{model}} dmodel表示每个隐藏表示的维度。对于自注意力,Q、K和V是前一个隐藏表示通过不同线性函数的映射,即 Q = H l − 1 W Q l Q = H^{l-1}W_{Q}^{l} Q=Hl−1WQl, K = H l − 1 W K l K = H^{l-1}W_{K}^{l} K=Hl−1WKl, V = H l − 1 W V l V = H^{l-1}W_{V}^{l} V=Hl−1WVl。最后,编码器产生最终的上下文表示 H L = [ h 1 L , … , h n L ] H^{L} = [h_{1}^{L}, \dots, h_{n}^{L}] HL=[h1L,…,hnL],该表示从最后一个Transformer块获得。
IR-BERT的预训练:遵循[20],我们首先在大规模外部LLVM-IR语料库上预训练一个掩码语言模型,称为IR-BERT,然后将参数迁移到我们的模型中。给定一个LLVM-IR语料库,每个LLVM-IR首先使用字节对编码(BPE[22])标记为一系列标记。在预训练之前,我们首先将两个段的连接作为输入,定义为 c 1 = { w 1 , w 2 , … , w n } c_{1} = \{w_{1}, w_{2}, \dots, w_{n}\} c1={w1,w2,…,wn}和 c 2 = { u 1 , u 2 , … , u m } c_{2} = \{u_{1}, u_{2}, \dots, u_{m}\} c2={u1,u2,…,um},其中n和m分别表示两个段的长度。这两个段始终通过特殊的分隔符标记[SEP]连接。每个序列的第一个和最后一个标记始终分别用特殊的分类标记[CLS]和结束标记[EOS]填充。然后将连接后的句子作为输入馈送到Transformer编码器中。在掩码语言建模中,输入句子的标记被随机采样并替换为特殊标记[MASK]。实际上,我们均匀选择15%的输入标记进行可能的替换。在选定的标记中,80%被替换为[MASK],10%保持不变,剩下的10%被随机替换为词汇表中的选定标记[23]。在不影响一般性的情况下,我们采用[20]中的预训练模型,该模型可以视为IR-BERT的一个变体。
D. 模型学习
我们通过将二进制代码和源代码的嵌入映射到公共空间并施加相似性约束来学习XLIR。其核心思想是,如果二进制代码和源代码具有相似的语义,它们的嵌入应该彼此接近。设三元组 ⟨ b , s + , s − ⟩ \langle b, s^{+}, s^{-} \rangle ⟨b,s+,s−⟩表示一个训练实例,其中对于二进制代码b, s + s^{+} s+表示编译对应的源代码(也称为正样本或锚点), s − s^{-} s−表示从所有源代码文件集合中随机选择的负代码片段。在对 ⟨ b , s + , s − ⟩ \langle b, s^{+}, s^{-} \rangle ⟨b,s+,s−⟩三元组集合进行训练时,XLIR预测 ⟨ b , s + ⟩ \langle b, s^{+} \rangle ⟨b,s+⟩和 ⟨ b , s − ⟩ \langle b, s^{-} \rangle ⟨b,s−⟩对的余弦相似度,并最小化排序损失[24]如下:
L = ∑ ⟨ b , s + , s − ⟩ ∈ D max ( 0 , α − sim ( b , s + ) + sim ( b , s − ) ) \mathcal{L} = \sum_{\langle b, s^{+}, s^{-} \rangle \in \mathcal{D}} \max\left(0, \alpha - \text{sim}(b, s^{+}) + \text{sim}(b, s^{-})\right) L=⟨b,s+,s−⟩∈D∑max(0,α−sim(b,s+)+sim(b,s−))
其中, D \mathcal{D} D表示训练数据集, sim \text{sim} sim表示二进制代码和源代码之间的相似度得分, α \alpha α是一个小的常数间隔。 b b b、 s + s^{+} s+和 s − s^{-} s−分别是 b b b、 s + s^{+} s+和 s − s^{-} s−的嵌入。在本文中,我们采用余弦相似函数,并默认将 α \alpha α设置为0.06。
E. 代码匹配
在推理阶段,给定一个二进制代码b和一组源代码文件 S S S,对于每个源代码文件 s ∈ S s \in S s∈S,我们首先将二进制代码和源代码文件输入到我们的训练模型中,获得它们对应的嵌入,分别表示为 b b b和 s s s。然后,我们计算 b b b和 s s s之间的匹配分数如下:
sim ( b , s ) = cos ( b , s ) = b T s ∥ b ∥ ∥ s ∥ \text{sim}(b, s) = \cos(b, s) = \frac{b^{T}s}{\|b\| \|s\|} sim(b,s)=cos(b,s)=∥b∥∥s∥bTs
其中, b b b和 s s s分别是二进制代码和源代码的向量。如果匹配分数大于阈值,我们认为该对二进制代码和源代码匹配,否则不匹配。通常,80%被用作代码克隆检测的相似性阈值。在我们的实验中,除非另有说明,否则使用该值作为默认值。我们还在第VI节中评估了阈值的影响。
五、实验设置
A. 研究问题
我们通过实验回答以下研究问题:
- RQ1:我们提出的XLIR在跨语言二进制-源代码匹配中是否有效?
- RQ2:XLIR在单语言二进制-源代码匹配中的效果如何?
- RQ3:基于IR的方法能否有效扩展至跨语言源代码-源代码功能克隆检测?
- RQ4:XLIR的主要影响因素有哪些?
B. 评估任务与数据集
-
跨语言源代码-源代码匹配
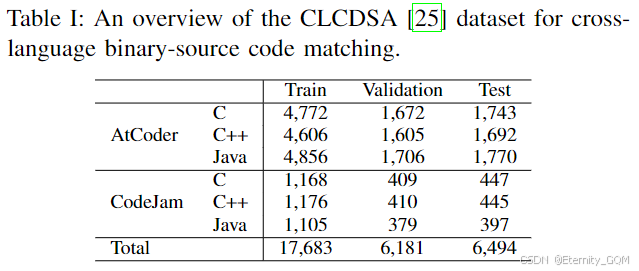
该任务旨在检测不同编程语言的源代码克隆,此前已在[25]中研究。CLCDSA数据集⁶由四种编程语言(C++、C#、Java、Python)的代码片段组成,收集自两个在线评测平台(AtCoder⁷和Google CodeJam⁸)。数据集中每个编程问题对应多种语言的解决方案。为验证XLIR在跨语言源代码匹配中的有效性,我们选择C、C++和Java作为目标语言。由于方法依赖IR,我们过滤掉无法成功编译的文件,并按6:2:2的比例划分训练集、验证集和测试集。表I展示了过滤后数据集的统计信息。
-
跨语言二进制-源代码匹配
目前缺乏公开数据集评估跨语言二进制-源代码匹配。为此,我们基于CLCDSA数据集构建新数据集:将一种语言的源代码编译为二进制文件,另一种语言的源代码保持不变。具体而言,使用不同编译器(GCC、LLVM Clang)、优化选项(-O0、-O1、-O2、-O3)和平台(x86-32、x86-64、arm-32、arm-64)将每个源文件编译为32个目标文件。在单语言场景下,实验主要基于POJ-104数据集²⁶(包含约50,000个C/C++程序),并补充在线平台数据,每个问题对应约500个解决方案。 -
预训练数据集
我们在独立的大规模IR语料库上预训练IR-BERT,采用[20]使用的数据集,包含从GitHub获取的11个开源软件(Linux-vmlinux、Linux-modules、GCC、MPlayer等)。使用LLVM Clang以-O0优化级别将这些软件编译为LLVM-IR,最终得到855,792个函数的48,023,781条LLVM-IR指令。
C. 基线方法
我们在两项任务(跨语言二进制-源代码匹配、跨语言源代码-源代码匹配)上评估XLIR,并与以下先进基线对比:
-
跨语言二进制-源代码匹配
- BinPro³:提取二进制和源代码的函数调用图(FCG),使用匈牙利算法²⁷进行二分匹配。
- B2SFinder⁷:从字符串、整数、控制流三个维度提取七类特征,采用加权匹配算法。
- XLIR (LSTM):XLIR的变体,使用LSTM²⁸编码IR。
-
跨语言源代码-源代码匹配
- LICCA²⁹:基于代码的语法和语义特征检测跨语言克隆,支持Java、C、JavaScript等语言。
- XLIR (LSTM):同上,适配源代码匹配任务。
D. 评估指标
采用信息检索和文本匹配中常用的召回率(Recall)、精确率(Precision)、F1值。对于查询代码片段(源或二进制),真实克隆为正样本,非克隆为负样本。设 T p T_p Tp为正确检测的正样本数, F p F_p Fp为误检的负样本数, F n F_n Fn为漏检的正样本数,则:
P = T p T p + F p , R = T p T p + F n , F 1 = 2 ⋅ P ⋅ R P + R P = \frac{T_p}{T_p + F_p}, \quad R = \frac{T_p}{T_p + F_n}, \quad F1 = 2 \cdot \frac{P \cdot R}{P + R} P=Tp+FpTp,R=Tp+FnTp,F1=2⋅P+RP⋅R
E. 实现细节
XLIR基于PyTorch 1.9实现,LLVM-IR编码器采用Transformer架构,参数设置与BERT²³一致。掩码策略为随机选择15%的IR指令,其中80%替换为[MASK],10%替换为随机字符,10%保持不变。隐藏层维度和词嵌入维度设为256。预训练阶段从大规模IR语料库生成词典,微调时未识别字符替换为⟨UNK⟩。
实验在配备4块32GB Tesla V100 GPU的Linux服务器上进行,采用ADM优化器分布式训练,学习率1e-3, dropout率0.4防止过拟合。
六、实验结果与分析
A. RQ1:中间表示在跨语言二进制-源代码匹配中的有效性
为验证模型性能,我们在基于CLCDSA构建的数据集上开展实验。表II展示了C/C++二进制文件与Java源代码、Java二进制文件与C/C++源代码的匹配结果。可见,XLIR能够有效检测跨语言二进制-源代码克隆:在C/C++二进制与Java源代码匹配任务中,精确率、召回率和F1值分别达0.73、0.59和0.65;Java二进制与C源代码匹配中,三项指标为0.68、0.55和0.61。尽管C/C++与Java的源代码和二进制文件差异显著,但实验结果表明,通过转换为LLVM-IR,模型能够捕捉到语义相似性。这归因于源代码和二进制文件转换为LLVM-IR时语义信息的等价保留。

B. RQ2:中间表示在单语言二进制-源代码匹配中的有效性
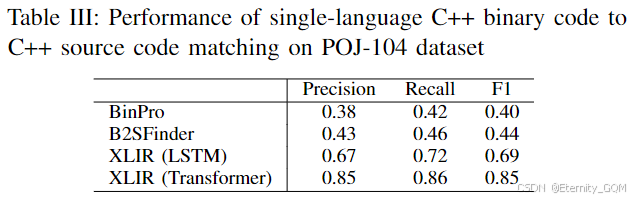
由于CLCDSA数据集筛选后仅约3万源文件,规模较小,我们将实验扩展至单语言数据集POJ-104,进一步验证XLIR在二进制-源代码匹配中的性能。表III显示,在C++二进制与C++源代码匹配任务中,XLIR显著优于所有基线:F1值达0.85,较BinPro和B2SFinder分别提升0.42和0.41,表明方法在单语言场景下同样有效。
C. RQ3:跨语言源代码-源代码匹配的扩展评估
我们在C、C++、Java间开展代码克隆检测,结果见表IV。当相似性阈值设为80%时,无论采用Transformer还是LSTM编码器,XLIR性能均大幅超越LICCA。其中,XLIR平均精确率0.81,召回率0.77,F1值0.73,表明其能有效检测跨语言功能克隆。此外,C与C++的相似性高于它们与Java的相似性,这与三者语法亲近度一致。

D. RQ4:主要因素的影响
我们分别研究预训练、Transformer编码器、编译选项和相似性阈值对XLIR的影响:
-
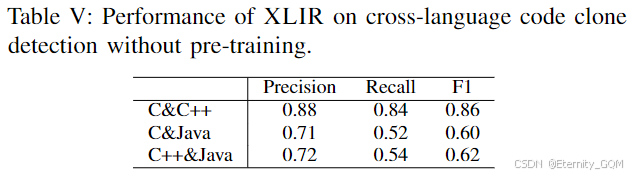
预训练的影响:在无预训练的跨语言代码克隆检测实验中(表V),精确率、召回率和F1值较有预训练时平均下降0.04、0.03和0.03,表明大规模外部语料预训练能有效提升模型泛化能力。
-
Transformer编码器的贡献:对比LSTM编码器(表II、III、IV),Transformer在三项任务的所有指标上均显著更优,这归因于其在处理长序列LLVM-IR时的自注意力机制优势。
-
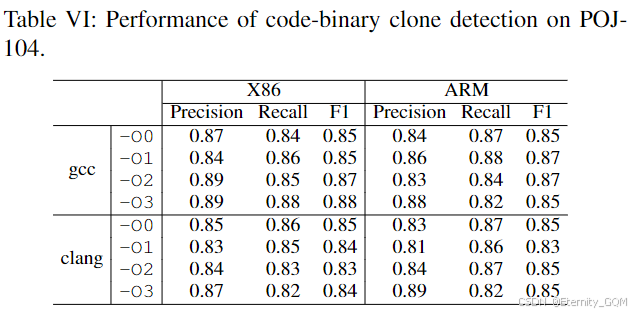
编译选项的影响:在POJ-104数据集上使用不同编译选项(优化级别、平台)的实验表明(表VI),XLIR在各类二进制文件中均保持高性能,精确率、召回率和F1值均值约0.85,方差极小(0.0002-0.0006),证明方法对编译差异具有鲁棒性。
-
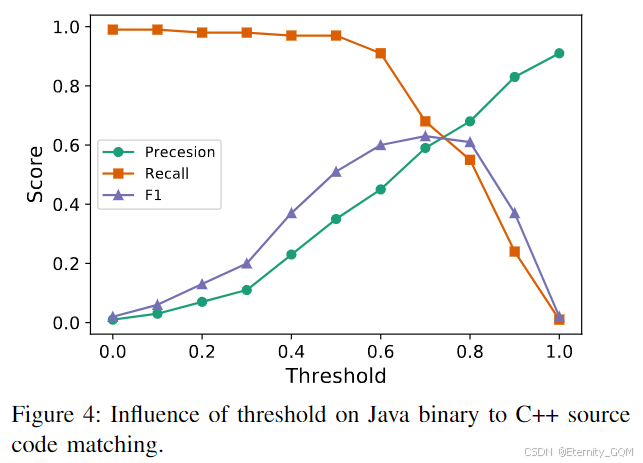
阈值的影响:在Java二进制-C++源代码匹配中调整阈值(图4)发现,阈值从0.5升至0.98时,精确率显著上升而召回率快速下降。阈值在0.7-0.8间时,精确率与召回率达到平衡,因此本文默认阈值设为0.8。
七、讨论
A. 案例分析
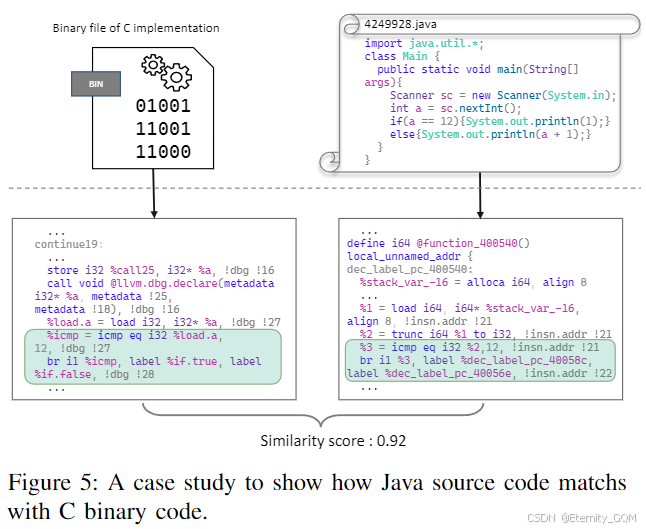
图5展示了一个C语言二进制文件与Java源代码匹配的真实案例。图中上半部分的两张图片分别为编程竞赛网站AtCoder上同一问题(ABC011/A)的C语言二进制文件和Java源代码。问题要求:若输入值(n)等于12,则输出(n+1),否则输出1。图5下半部分的两段代码片段分别从二进制目标文件反编译得到的LLVM-IR和Java源代码编译得到的LLVM-IR中提取。可以看到,这两段LLVM-IR代码片段具有等价的语义,均包含一个基于输入值(n)是否等于12的条件分支(为节省篇幅,省略了前置输入指令和后置输出相关指令)。该案例表明,我们的方法之所以有效,关键在于转换为LLVM-IR后程序的语义信息被等价保留。
B. XLIR的优势
XLIR具有以下两点优势:
- 语义保留更完整:与以往主要提取二进制目标文件中的代码字面量和源代码特定特征的方法不同,我们将源代码和二进制目标文件转换为语义等价的LLVM-IR进行匹配,相比手动选择特征的方式,可大幅减少程序语义信息的丢失。
- 端到端自动化:我们的方法是一种端到端的二进制-源代码和源代码-源代码匹配方案,用户无需掌握复杂的逆向工程技能即可使用该工具,显著提高了代码克隆检测的效率,对软件安全相关任务具有重要实用价值。
C. 有效性威胁与局限性
-
有效性威胁:
- 本文方法要求用于克隆检测的源代码必须是可编译的,二进制目标文件必须能反编译为LLVM-IR。在少数场景中,可能存在无法编译的不完整或语法错误代码片段,但仍需进行检测。
- 解析严重混淆且无法反编译的二进制目标文件一直是逆向工程中的难题,本文未对此展开研究。我们使用的RetDec工具在大多数情况下能够将二进制目标文件反编译为LLVM-IR,但对极端混淆代码可能失效。
-
局限性:
- 目前方法仅支持具有静态LLVM编译器的编程语言。尽管许多语言(如C/C++、Rust、Java等)可通过LLVM轻松编译,但仍有部分常用语言不支持(如Python因动态特性仅支持JIT形式的LLVM编译器,只能在运行时转换为LLVM-IR)。随着LLVM在编译器优化中的潜力不断释放,我们相信会有越来越多的编程语言支持静态编译至LLVM-IR。
八、相关工作
A. 深度学习在源代码中的应用
近年来,深度学习在源代码建模领域的应用日益受到关注,旨在构建智能工具以提高软件开发人员的效率。代码嵌入是一项基础任务,可支持代码搜索[31][32]、代码摘要生成[33]-[35]、代码补全[36]-[39]和代码克隆检测[5][40]-[42]等多种下游任务。据调研,当前方法主要从四个维度表示源代码:序列代码标记、抽象语法树(AST)、代码图和中间表示(IR)。
- 标记序列:与自然语言处理类似,将程序语义表示为标记序列是最直接的方式。通常通过空格或驼峰命名法(如SortList、intArray)将程序分割为顺序标记。
- 抽象语法树与代码图:为表示程序的结构化语法信息,部分研究使用树或图形式的AST,如TreeCNN[11]、Tree-LSTM[12]和GGNN[13]。另一种思路是将AST序列化为指令列表,以便采用序列学习方法[33][43]。此外,数据流图[15]和控制流图[14]通过突出执行路径和变量变化,进一步丰富了程序表示。
- 中间表示:近期研究开始采用IR表示程序,因其独立于编程语言和平台[16]-[18]。得益于自然语言处理中的预训练技术[44],Feng等人[19]预训练了CodeBERT模型,用于编程语-自然语言的双峰任务,在代码搜索和摘要生成中表现优异。Guo等人[15]提出GraphCodeBERT,通过融入数据流信息进一步提升了预训练效果。
B. 代码克隆检测
检测相似代码(克隆)是软件工程(如代码重用、漏洞检测)中的基础任务。代码克隆通常分为四类:Type-1、Type-2、Type-3和Type-4。
- 传统方法:CCFinder[45]从代码中提取标记序列并规范化,用于检测Type-1和Type-2克隆;NICAD[46]通过“美化打印”和动态聚类两步法过滤噪声,检测近似克隆;Deckard[47]基于AST和局部敏感哈希(LSH)实现高效聚类,适用于Type-3克隆;SourcererCC[48]通过捕捉跨代码的标记相似性,支持大规模代码克隆检测。
- 深度学习方法:White等人[49]提出DLC,结合代码词法和语法信息,使用循环神经网络(RNN)进行表示;Wei等人[50]通过TreeLSTM在AST上建模语法结构;Zhang等人[40]将AST分解为语句级子树,利用双向循环网络提取特征;Zhao等人[5]结合数据流和控制流,提出代码表示的深度学习框架;Wu等人[41]从社交网络分析视角引入控制流图的中心性分析,提升匹配效率。
C. 跨语言源代码分析
随着迁移学习的发展,跨编程语言的知识迁移成为新兴研究方向。
- 跨语言漏洞定位:Xia等人[51]基于语言翻译技术,通过不同自然语言的注释对源代码文件排序,实现跨语言漏洞定位。
- 程序翻译与克隆检测:Chen等人[12]提出树到树神经网络,用于程序跨语言转换;Bui等人[52]设计双边编码器模型,分别编码不同语言的AST结构;Nafi等人[25]基于语法特征和API文档,实现跨语言源代码克隆检测;Gu等人[54]提出DeepAM,从单语言项目中自动挖掘跨语言API映射。
- 本文定位:与现有跨语言源代码分析不同,本文首次研究跨语言二进制-源代码匹配,填补了跨模态、跨语言代码分析的空白。
九、结论与未来工作
在本研究中,我们首次定义了跨语言二进制-源代码匹配问题,并提出了一种基于Transformer和程序中间表示(IR)的新方法XLIR。我们在构建的跨语言数据集上对跨语言二进制-源代码匹配和跨语言源代码-源代码匹配两项任务进行了全面实验。实验结果和分析表明,XLIR显著优于其他最先进的模型。例如,在Java二进制代码与C源代码的匹配中,与B2SFinder相比,XLIR的召回率、精确率和F1值分别从0.41、0.35和0.38提升至0.55、0.68和0.61。
鉴于跨语言二进制-源代码匹配问题的挑战性,XLIR仍有很大的改进空间。在未来的工作中,我们将设计更有效的机制来进一步提高代码匹配的准确性。我们还计划将我们的方法扩展到支持更小的克隆检测粒度,例如单个函数或代码片段的克隆检测。
成果公开:本文所有实验已集成到开源工具包NATURALCC[55]中,相关数据集和源代码可在https://github.com/CGCL-codes/naturalcc获取。