金仓数据库主备集群故障自动转移技术解析
一、什么是故障自动转移?
当主数据库(Primary)突发故障时,守护进程repmgrd自动将备库(Standby)提升为新主库并接管服务,全程无需人工干预,保障业务连续性。
二、自动转移流程详解
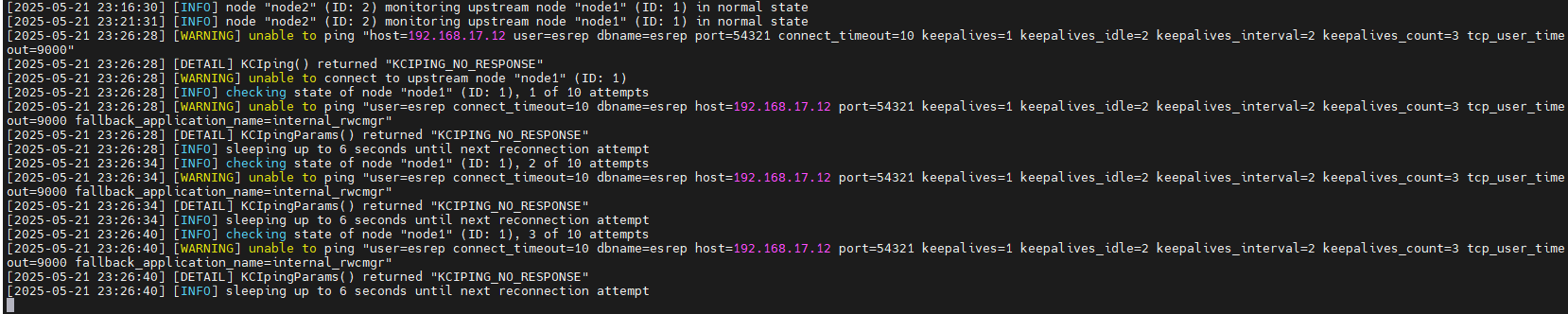
阶段1:重连试探(防误判机制)
- 触发条件:备库守护进程检测到主库连接异常
- 试探策略:
- 每间隔
reconnect_interval秒尝试重连 - 最多尝试
reconnect_attempts次(例:6秒×10次=1分钟)
- 每间隔
- 结果分支:
✅ 重连成功 → 恢复监控状态
❌ 重连失败 → 进入准备流程
📌 设计价值:有效规避网络抖动导致的误切换
日志参考:
阶段2:集群状态预同步(竞选前统一战场)
- 关闭备库数据同步通道
- 若开启
standby_disconnect_on_failover参数:- 向walreceiver进程发送终止信号(SIGTERM)
- 临时调整
wal_retrieve_retry_interval阻止自动重新接收wal日志
- 若开启
- 协调多备库状态
- 等待其他备库关闭walreceiver(最长30秒)
- 识别见证节点(Witness)
- 检查是否配置见证节点 → 直接影响竞选规则
日志参考:

阶段3:民主竞选新主库(数据一致性优先)
竞选资格预筛选
| 同步模式 | 参选条件(任一不满足即淘汰) | 目标 |
|---|---|---|
| all/sync | 原主库故障前状态为streaming+sync | 确保数据一致性 |
| quorum | 原主库故障前状态为streaming+quorum | 确保数据一致性 |
| async | 主备LSN日志差距小于lsn_lag_threshold值 | 控制数据延迟在安全范围内 |
多节点竞选逻辑(存活节点间PK)
- 存活节点检测
- 通过libkci连接测试统计:
visible_nodes(当前可见节点数)nodes_with_primary_still_visible(2秒内见过主库的节点数)
- 通过libkci连接测试统计:
- 四维竞选权重排序:
1. LSN日志位置 → 取最大值(数据最接近主库) 2. Catchup状态 → 必须为True(已完成日志追赶) 3. Priority优先级 → 取配置最高值 4. Node_ID → 取最小值(最终仲裁) - 集群存活校验(关键容灾规则)
集群类型 切换条件公式 物理意义 无见证节点 visible_nodes > total_nodes/2必须存活超过半数节点(2节点集群例外) 含见证节点 (见证节点可见的存活节点+1) ≥ (总节点+1)/2支持超半数节点宕机场景切换 ✅
🔍 技术深潜:见证节点突破传统集群半数存活限制,提升极端故障下的可用性
阶段4:安全升主(服务接管)
- 网络可达验证
- Ping
trusted_servers网关列表(至少1个成功)
- Ping
- 原主库隔离
- 尝试远程执行
kbha -A stopdb强制停止旧主库(防脑裂)
- 尝试远程执行
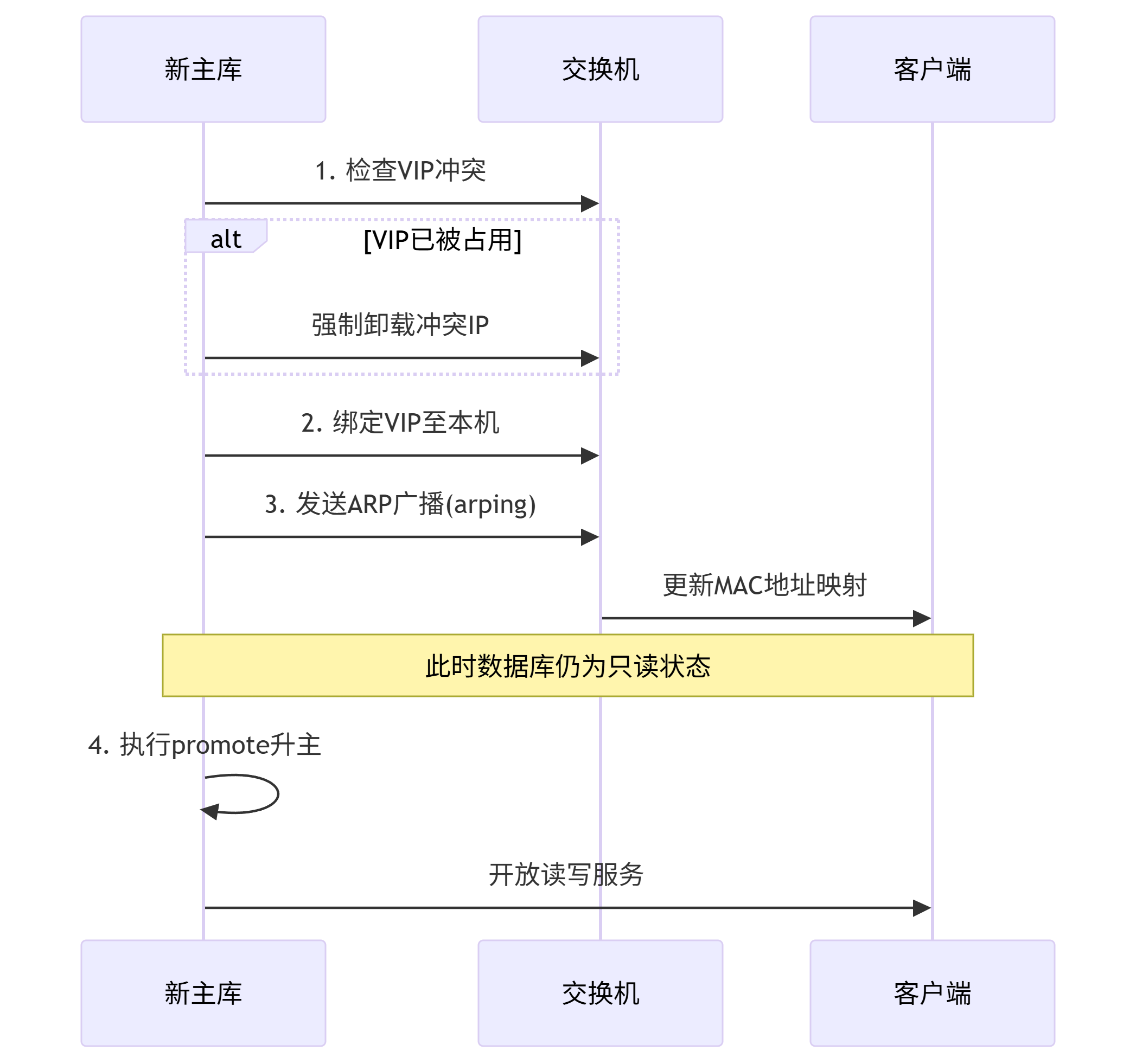
- VIP挂载(服务无缝转移)
- 检查IP冲突 → 卸载冲突IP(若原主机服务器可达) → 绑定VIP到新主库
- 执行ARP广播更新(
arping)
- 正式升主
- 执行
promote命令激活主库身份 - 触发
checkpoint持久化数据
- 执行
⚠️ 短暂只读窗口:VIP挂载完成到升主操作期间,业务请求可能遇到只读状态(秒级)