deepbayes: VI回顾和GMM近似推断

系列文章
- deepbayes lecture1: 贝叶斯框架
- deepbayes lecture2: 变分推断
- deepbayes lecture3:隐变量模型
回顾
在真正用实际例子复习VI之前,我们先回顾一下一些公式
L ( q ( θ ) ) = ∫ q ( θ ) log p ( x , θ ) q ( θ ) d θ = ∫ q ( θ ) log p ( x ∣ θ ) p ( θ ) q ( θ ) d θ = = ∫ q ( θ ) log p ( x ∣ θ ) d θ + ∫ q ( θ ) log p ( θ ) q ( θ ) d θ = = E a ( θ ) log p ( x ∣ θ ) − K L ( q ( θ ) ∣ ∣ p ( θ ) ) \mathcal{L}(q(\theta))=\int q(\theta)\log\frac{p(x,\theta)}{q(\theta)}d\theta=\int q(\theta)\log\frac{p(x\mid\theta)p(\theta)}{q(\theta)}d\theta=\\ =\int q(\theta)\log p(x\mid\theta)d\theta+\int q(\theta)\log\frac{p(\theta)}{q(\theta)}d\theta=\\ =\mathbb{E}_{a(\theta)}\log p(x\mid\theta)-K L(q(\theta)||\,p(\theta)) L(q(θ))=∫q(θ)logq(θ)p(x,θ)dθ=∫q(θ)logq(θ)p(x∣θ)p(θ)dθ==∫q(θ)logp(x∣θ)dθ+∫q(θ)logq(θ)p(θ)dθ==Ea(θ)logp(x∣θ)−KL(q(θ)∣∣p(θ))
其中第一项是数据项,第二项是正则化项
如果使用mean field variational inference,则应有
p ( θ ∣ x ) ≈ q ( θ ) = ∏ j = 1 m q j ( θ j ) p(\theta\mid x)\approx q(\theta)=\prod_{j=1}^{m}q_{j}\left(\theta_{j}\right) p(θ∣x)≈q(θ)=j=1∏mqj(θj)
Mean field的更新公式更新过程如下:
初始化:
q ( θ ) = Π j = 1 m q j ( θ j ) q(\theta)=\Pi_{j=1}^{m}\,q_{j}\,(\theta_{j}) q(θ)=Πj=1mqj(θj)
循环迭代直到ELBO收敛
-
更新 q 1 , ⋅ ⋅ ⋅ , q m ; q1,\cdot\cdot\cdot,q_{m}; q1,⋅⋅⋅,qm;
-
q j ( θ j ) = 1 Z j exp ( E q i ≠ j log p ( x , θ ) ) q_{j}\left(\theta_{j}\right)=\frac{1}{Z_{j}}\exp\left(\mathbb{E}_{q_{i\neq j}}\log p(x,\theta)\right) qj(θj)=Zj1exp(Eqi=jlogp(x,θ))
-
计算ELBO L ( q ( θ ) ) {\mathcal{L}}(q(\theta)) L(q(θ))
-
如果使用parametric variational inference, 则应有
p ( θ ∣ x ) ≈ q ( θ ) = q ( θ ∣ λ ) p(\theta\mid x)\approx q(\theta)=q(\theta\mid\lambda) p(θ∣x)≈q(θ)=q(θ∣λ)
近似贝叶斯推断:Gaussian Mixture Model聚类
聚类问题与高斯混合模型
聚类问题旨在将一组对象划分成 K 个簇 (clusters),使得同一簇内的对象尽可能相似,不同簇内的对象尽可能不同。
高斯混合模型是一种常用的概率模型,用于解决聚类问题。它假设每个簇都服从一个高斯分布,并且整个数据集可以看作是由 K 个高斯分布混合而成。
具体来说:
- 我们有一个数据集 X = { x i } i = 1 N X = \{x_i\}_{i=1}^N X={xi}i=1N。
- 目标是将这些对象分组到 K 个簇中。
- GMM 包含 K 个高斯分量,每个分量都有一个概率 π = ( π 1 , . . . , π K ) \pi = (\pi_1, ..., \pi_K) π=(π1,...,πK)。
- 每个高斯分量都有自己的参数 μ k , λ k \mu_k, \lambda_k μk,λk。
- 每个对象都有一个潜在变量 z i ∈ { 0 , 1 } K z_i \in \{0, 1\}^K zi∈{0,1}K,表示它属于哪个簇 ( ∑ k = 1 K z i k = 1 \sum_{k=1}^K z_{ik} = 1 ∑k=1Kzik=1)。
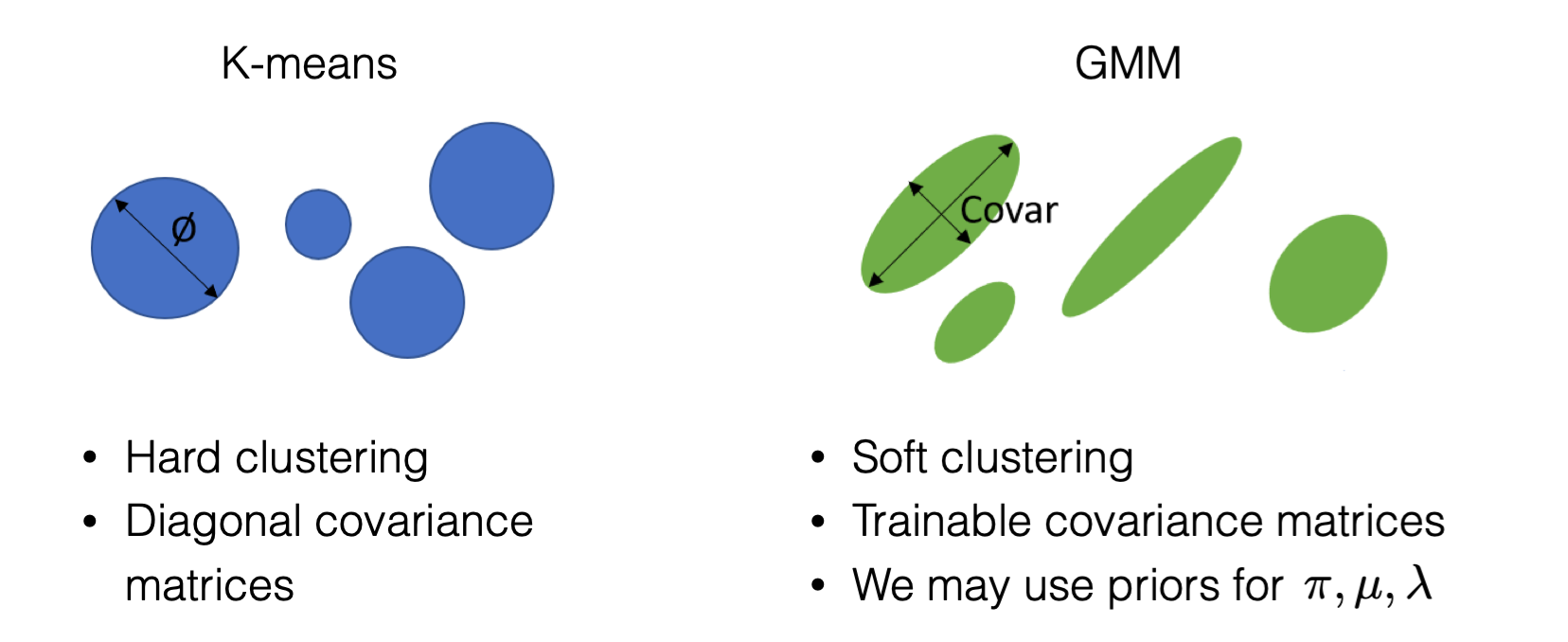
与传统的 K-means 算法相比,GMM 具有以下优点:
- 软聚类 (Soft clustering):GMM 不直接将每个对象分配到某个簇,而是给出每个对象属于每个簇的概率。
- 灵活的形状 (Flexible shapes):GMM 可以通过调整高斯分量的协方差矩阵来适应不同形状的簇。
- 先验知识 (Prior Knowledge):GMM 可以使用先验分布来约束参数,从而将先验知识融入到模型中。
GMM 的概率模型
GMM 的基本概率模型可以表示为:
p ( X , Z ∣ π , μ , λ ) = ∏ i = 1 N p ( z i ∣ π ) p ( x i ∣ z i , μ , λ ) = ∏ i = 1 N ∏ k = 1 K [ π k N ( x i ∣ μ k , λ k − 1 ) ] z i k p(X, Z | \pi, \mu, \lambda) = \prod_{i=1}^N p(z_i | \pi)p(x_i | z_i, \mu, \lambda) = \prod_{i=1}^N \prod_{k=1}^K [\pi_k N(x_i | \mu_k, \lambda_k^{-1})]^{z_{ik}} p(X,Z∣π,μ,λ)=∏i=1Np(zi∣π)p(xi∣zi,μ,λ)=∏i=1N∏k=1K[πkN(xi∣μk,λk−1)]zik
我们的目标是训练这个模型,即找到潜在变量的后验分布以及参数的最优值。
推断方法
不同的推断方法适用于不同的情况,主要取决于我们是对参数还是潜在变量感兴趣,以及是否满足共轭性 (conjugacy) 。 这里的共轭性是指:如果先验分布和似然函数是共轭的,那么后验分布与先验分布具有相同的函数形式。
- 只对参数感兴趣: 使用最大似然估计 (Maximum likelihood)
- 只对潜在变量感兴趣:
- 满足共轭性:Full Bayesian inference
- 满足条件共轭性: Mean field variational inference
- 不满足共轭性: Parametric variational inference
- 对参数和潜在变量都感兴趣:使用 EM 算法。
EM 算法 (Expectation-Maximization algorithm) 是一种迭代算法,用于求解包含潜在变量的概率模型的参数估计问题。 它通过交替执行以下两个步骤来进行迭代:
- E 步 (Expectation step):计算潜在变量的后验分布。
- M 步 (Maximization step):根据潜在变量的后验分布,最大化似然函数,更新模型参数。
问题一:基本的 GMM (basic GMM)
让我们从一个基本的问题开始:如何训练一个 GMM 模型?
- 检查似然函数和先验分布是否共轭 (conjugate)。
- 在这种情况下,似然函数和先验是共轭的。
- E 步:推导 p ( Z ∣ X , π , μ , λ ) p(Z | X, \pi, \mu, \lambda) p(Z∣X,π,μ,λ)。 在这个步骤中, π , μ , λ \pi, \mu, \lambda π,μ,λ 的值是固定的。
-
在贝叶斯框架下,后验概率正比于似然函数与先验概率的乘积:
p ( Z ∣ X ) ∝ p ( X , Z ) = ∏ i = 1 N ∏ k = 1 K [ π k N ( x i ∣ μ k , λ k − 1 ) ] z i k p(Z | X) \propto p(X, Z) = \prod_{i=1}^N \prod_{k=1}^K [\pi_k N(x_i | \mu_k, \lambda_k^{-1})]^{z_{ik}} p(Z∣X)∝p(X,Z)=∏i=1N∏k=1K[πkN(xi∣μk,λk−1)]zik
-
因此,可以将后验概率写成如下形式:
p ( z i k = 1 ∣ X ) ∝ π k N ( x i ∣ μ k , λ k − 1 ) p(z_{ik} = 1 | X) \propto \pi_k N(x_i | \mu_k, \lambda_k^{-1}) p(zik=1∣X)∝πkN(xi∣μk,λk−1)
-
为了保证概率和为 1, 需要进行归一化:
p ( z i k = 1 ∣ X ) = π k N ( x i ∣ μ k , λ k − 1 ) ∑ j = 1 K π j N ( x i ∣ μ j , λ j − 1 ) p(z_{ik} = 1 | X) = \frac{\pi_k N(x_i | \mu_k, \lambda_k^{-1})}{\sum_{j=1}^K \pi_j N(x_i | \mu_j, \lambda_j^{-1})} p(zik=1∣X)=∑j=1KπjN(xi∣μj,λj−1)πkN(xi∣μk,λk−1)
-
最终的后验概率为:
p ( Z ∣ X ) = ∏ i = 1 N ∏ k = 1 K [ π k N ( x i ∣ μ k , λ k − 1 ) ∑ j = 1 K π j N ( x i ∣ μ j , λ j − 1 ) ] z i k p(Z | X) = \prod_{i=1}^N \prod_{k=1}^K [\frac{\pi_k N(x_i | \mu_k, \lambda_k^{-1})}{\sum_{j=1}^K \pi_j N(x_i | \mu_j, \lambda_j^{-1})}]^{z_{ik}} p(Z∣X)=∏i=1N∏k=1K[∑j=1KπjN(xi∣μj,λj−1)πkN(xi∣μk,λk−1)]zik
- **M 步:计算 π , μ , λ \pi, \mu, \lambda π,μ,λ 的最优值。**通过最大化 E [ p ( Z ∣ X , π , μ , λ ) log p ( X , Z ∣ π , μ , λ ) ] E[p(Z|X,π,μ,λ) \log p(X, Z|π, μ, λ) ] E[p(Z∣X,π,μ,λ)logp(X,Z∣π,μ,λ)] 计算, 其中 Z Z Z 的后验分布在这一步是固定的。
-
首先,将目标函数重写为 π , μ , λ \pi, \mu, \lambda π,μ,λ 的函数:
E [ p ( Z ∣ X ) log p ( X , Z ) ] = E [ p ( Z ∣ X ) ∑ i = 1 N ∑ k = 1 K z i k [ log π k + log N ( x i ∣ μ k , λ k − 1 ) ] ] E[p(Z|X) \log p(X, Z)] = E[p(Z|X) \sum_{i=1}^N \sum_{k=1}^K z_{ik} [\log \pi_k + \log N(x_i | \mu_k, \lambda_k^{-1})]] E[p(Z∣X)logp(X,Z)]=E[p(Z∣X)∑i=1N∑k=1Kzik[logπk+logN(xi∣μk,λk−1)]]
= ∑ i = 1 N ∑ k = 1 K γ i k [ log π k + 1 2 log λ k − 1 2 ( x i − μ k ) 2 λ k ] + C = \sum_{i=1}^N \sum_{k=1}^K \gamma_{ik} [\log \pi_k + \frac{1}{2} \log \lambda_k - \frac{1}{2}(x_i - \mu_k)^2 \lambda_k] + C =∑i=1N∑k=1Kγik[logπk+21logλk−21(xi−μk)2λk]+C
其中 γ i k = p ( z i k = 1 ∣ X ) \gamma_{ik} = p(z_{ik} = 1 | X) γik=p(zik=1∣X)
-
由于 π \pi π 受限于 simplex (即 π k \pi_k πk 的和为 1),我们需要使用拉格朗日乘子法求解。 首先,将 π k \pi_k πk 参数化为 η k = log π k \eta_k = \log \pi_k ηk=logπk,然后构造拉格朗日函数。
L ( η , ψ ) = ∑ i = 1 N ∑ k = 1 K γ i k η k − ψ ( ∑ k = 1 K exp η k − 1 ) L(\eta, \psi) = \sum_{i=1}^N \sum_{k=1}^K \gamma_{ik} \eta_k - \psi (\sum_{k=1}^K \exp \eta_k - 1) L(η,ψ)=∑i=1N∑k=1Kγikηk−ψ(∑k=1Kexpηk−1)
-
分别对 η k \eta_k ηk 和 ψ \psi ψ 求导并令其等于 0, 最终得到:
π k = ∑ i = 1 N γ i k N \pi_k = \frac{\sum_{i=1}^N \gamma_{ik}}{N} πk=N∑i=1Nγik
-
接下来,分别对 μ k \mu_k μk 和 λ k \lambda_k λk 求导,得到:
μ k = ∑ i = 1 N γ i k x i ∑ i = 1 N γ i k \mu_k = \frac{\sum_{i=1}^N \gamma_{ik} x_i}{\sum_{i=1}^N \gamma_{ik}} μk=∑i=1Nγik∑i=1Nγikxi
λ k = ∑ i = 1 N γ i k ∑ i = 1 N γ i k ( x i − μ k ) 2 \lambda_k = \frac{\sum_{i=1}^N \gamma_{ik}}{\sum_{i=1}^N \gamma_{ik} (x_i - \mu_k)^2} λk=∑i=1Nγik(xi−μk)2∑i=1Nγik
问题二:给 π \pi π添加先验分布
问题2引入了对 π \pi π 添加先验分布的情况。
-
概率模型: p ( X , Z , π ∣ μ , λ ) = p ( π ) ∏ i = 1 N [ p ( z i ∣ π ) p ( x i ∣ z i , μ , λ ) ] = D i r ( π ∣ α ) ∏ i = 1 N ∏ k = 1 K [ π k N ( x i ∣ μ k , λ k − 1 ) ] z i k p(X, Z, \pi|\mu, \lambda) = p(\pi) \prod_{i=1}^N [p(z_i|\pi)p(x_i|z_i, \mu, \lambda)] = Dir(\pi|\alpha) \prod_{i=1}^N \prod_{k=1}^K [\pi_kN(x_i|\mu_k, \lambda_k^{-1})]^{z_{ik}} p(X,Z,π∣μ,λ)=p(π)∏i=1N[p(zi∣π)p(xi∣zi,μ,λ)]=Dir(π∣α)∏i=1N∏k=1K[πkN(xi∣μk,λk−1)]zik
-
如何训练?:使用EM算法 + 在E-step中使用Mean field VI.
Mean Field VI 通过假设后验分布可以分解为独立的部分来简化推断,即 q ( Z , π ) = q ( Z ) q ( π ) q(Z, \pi) = q(Z)q(\pi) q(Z,π)=q(Z)q(π)。
问题
- 检查似然和先验是不是共轭?如果使用分解 q ( Z , π ) = q ( Z ) q ( π ) q(Z, \pi) = q(Z)q(\pi) q(Z,π)=q(Z)q(π),检查conditional conjugacy是否存在?
- E-step:写出 q ( Z ) q(Z) q(Z)和 q ( π ) q(\pi) q(π)的更新公式。
- M-step:通过最大化 E q ( Z , π ) log p ( X , Z , π ∣ μ , λ ) E_{q(Z,π)} \log p(X, Z, π|\mu, λ) Eq(Z,π)logp(X,Z,π∣μ,λ) 来计算 μ , λ \mu, \lambda μ,λ的最优值。
解答
-
检查共轭性:在这种情况下,似然和先验不是共轭的。 如果 Z Z Z固定,存在共轭。 如果 π \pi π固定,存在共轭。
-
E-step:计算 q ( Z ) q(Z) q(Z) 和 q ( π ) q(\pi) q(π) 的更新公式:
-
因为: p ( Z , π ∣ X , μ , λ ) ≈ q ( Z , π ) = q ( Z ) q ( π ) p(Ζ, π|Χ, μ, λ) ≈ q(Ζ, π) = q(Ζ)q(π) p(Z,π∣X,μ,λ)≈q(Z,π)=q(Z)q(π), 可以得出:
-
log q ( Z ) = E q ( π ) log p ( X , Z , π ) + C o n s t \log q(Z) = E_{q(\pi)} \log p(X, Z, \pi) + Const logq(Z)=Eq(π)logp(X,Z,π)+Const, 通过推导可以得出:
q ( Z ) = ∏ i = 1 N q ( z i ) q(Z) = \prod_{i=1}^N q(z_i) q(Z)=∏i=1Nq(zi), q ( z i ) = ∏ k = 1 K ρ i k z i k ∑ k = 1 K ρ i k q(z_i) = \frac{\prod_{k=1}^K \rho_{ik}^{z_{ik}}}{\sum_{k=1}^K \rho_{ik}} q(zi)=∑k=1Kρik∏k=1Kρikzik
-
log q ( π ) = E q ( Z ) log p ( X , Z , π ) + C o n s t \log q(\pi) = E_{q(Z)} \log p(X, Z, \pi) + Const logq(π)=Eq(Z)logp(X,Z,π)+Const, 通过推导可以得出:
q ( π ) = D i r ( π ∣ α ′ ) q(\pi) = Dir(\pi|\alpha') q(π)=Dir(π∣α′), 其中 α k ′ = α k + ∑ i = 1 N E q ( Z ) z i k \alpha_k' = \alpha_k + \sum_{i=1}^N E_{q(Z)} z_{ik} αk′=αk+∑i=1NEq(Z)zik
-
-
-
M-step:计算 μ , λ \mu, \lambda μ,λ 的最优值: μ \mu μ和 λ \lambda λ的公式和之前一样。
总结
近似贝叶斯推断为我们提供了一种处理复杂概率模型的有效方法。 通过合理地选择近似方法,我们可以将先验知识融入到模型中,并获得更好的推断结果。
Reference
- deepbayes day1 seminar: Approximate inference