Redis分布式缓存(RDB、AOF、主从同步)
文章目录
- 1. Redis持久化
- 1.1 RDB快照
- 1.2 AOF日志
- 1.2.1 AOF的三种回写策略:
- 1.2.2 AOF重写机制
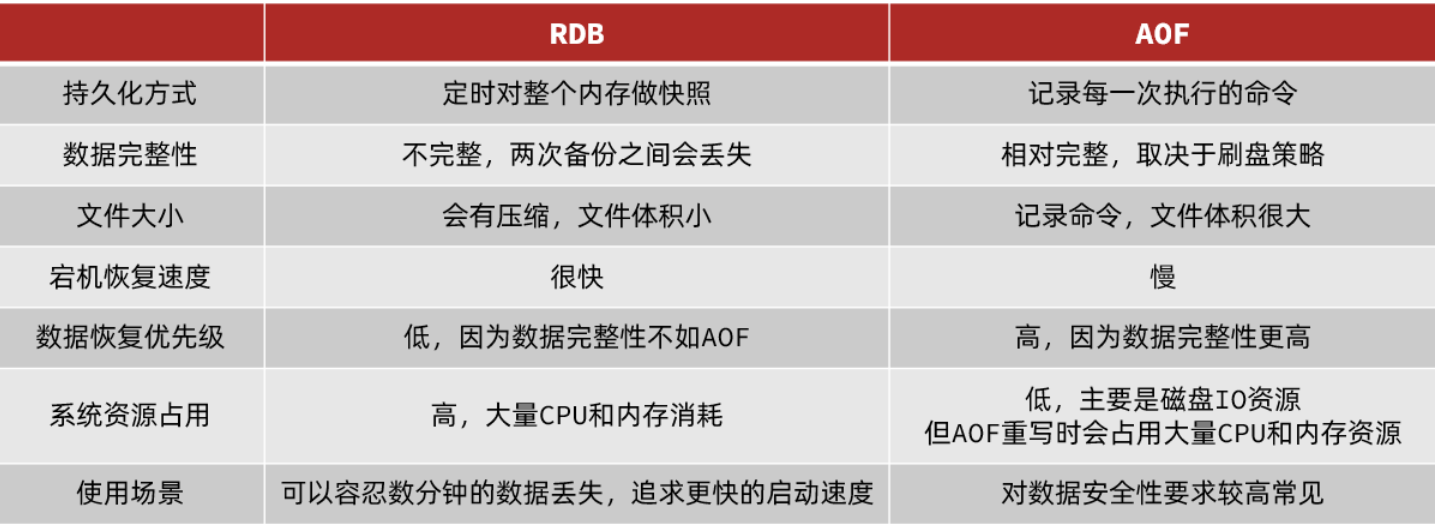
- 1.3 RDB和AOF对比
- 1.4 混合持久化
- 2.Redis主从复制
- 2.1第一次同步
- 2.2 命令传播
- 2.3 增量复制
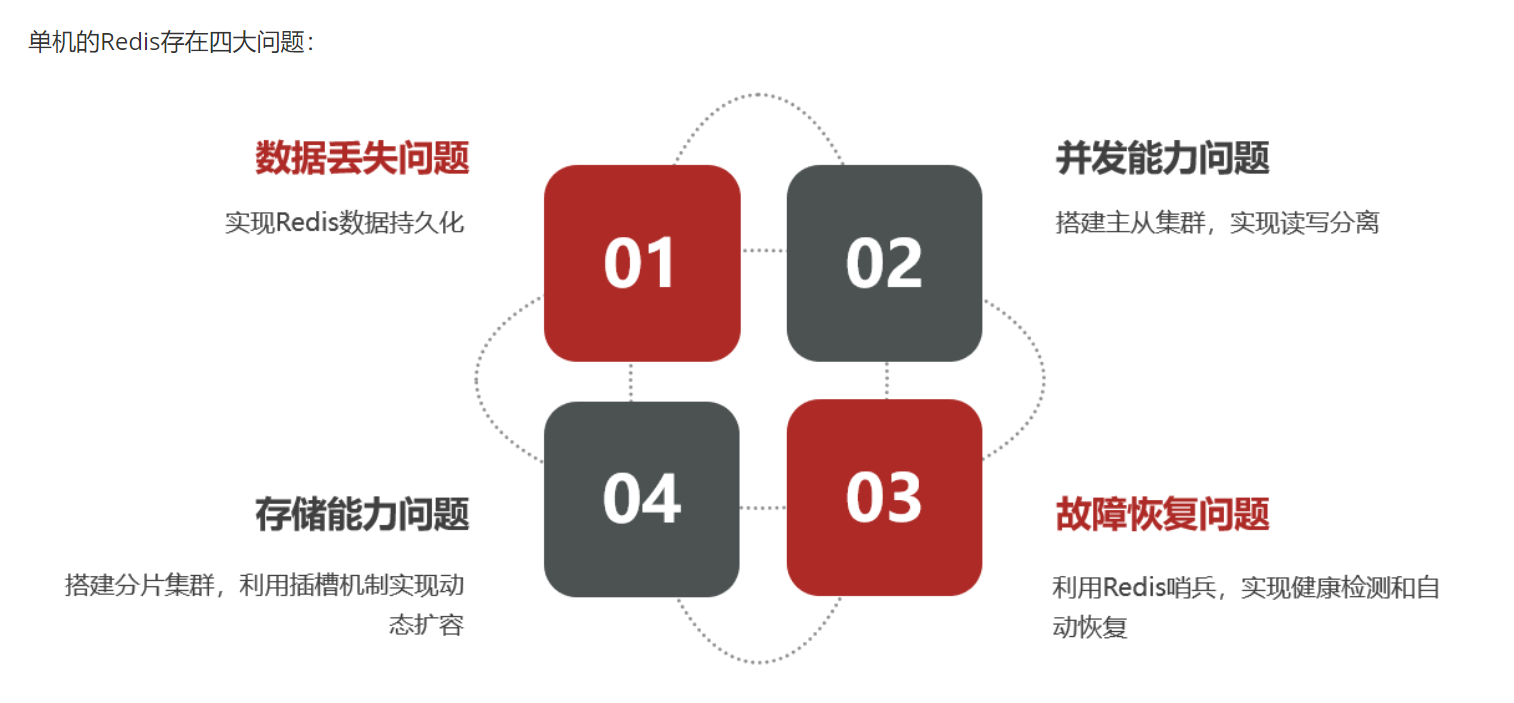
我们分布式缓存就是要解决这四个问题。
1. Redis持久化
实现Redis数据持久化有三种方式
- RDB快照:将数据写入磁盘
- AOF日志:将命令追加到文件里
- 混合持久化:混合RDB和AOF的优点
1.1 RDB快照
RDB快照又叫做Redis数据快照,简单来说就是,将数据记录到磁盘中,当Redis发生故障重启后,可以根据快照文件进行数据回复。
由于RDB保存的是全部数据,手动保存所需时间可能比较久,会阻塞线程。因此我们通常使用bgsave即创建一个子线程去进行数据备份。
# 900秒内,如果至少有1个key被修改,则执行bgsave , 如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
RDB在执行快照时,数据能修改吗?
可以,RDB中bgsave采用的是Write-on-Copy技术,主线程会fork一个子线程并复制主线程的页表,当主线程进行读操作时,会根据页表的映射关系读取到磁盘中的数据。当主进程执行写操作时,会创建一个数据副本,子进程会把数据副本也写入磁盘。
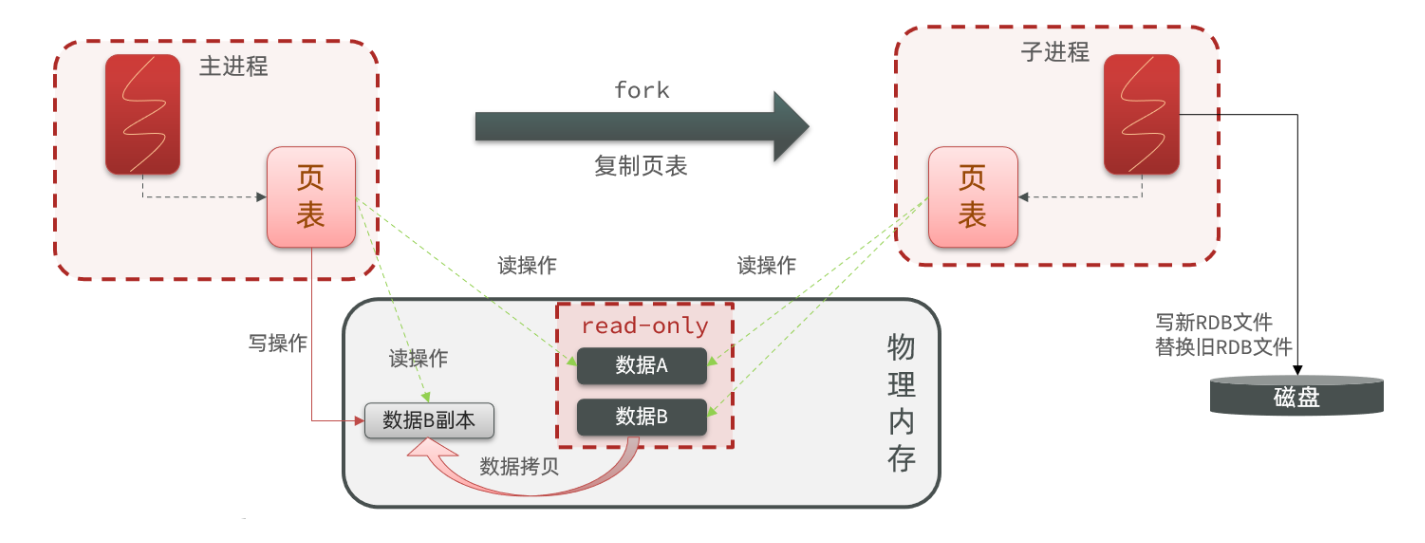
小结:
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并异步写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
RDB会在什么时候执行?save 60 1000代表什么含义?
- 默认是服务停止时
- 执行save和bgsave
- 代表60秒内至少执行1000次修改则触发RDB
RDB的缺点?
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
1.2 AOF日志
AOF日志是Redis在执行完命令后会把每一个命令都追加到一个文件里,当Redis重启后,可以根据文件里面的命令进行数据的恢复。
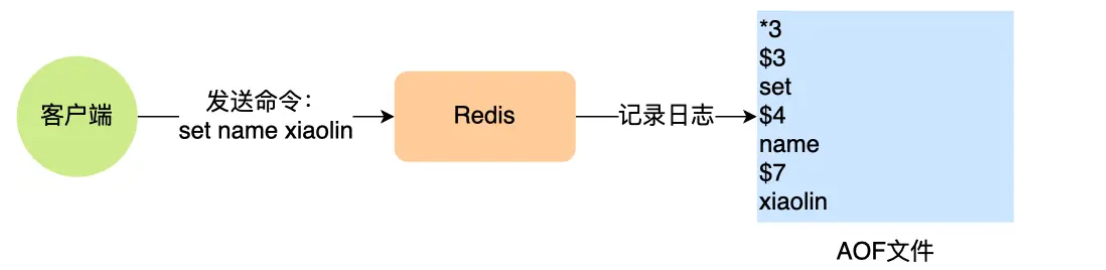
1.2.1 AOF的三种回写策略:
- Always:即每执行一个命令就将该命令写入AOF文件
- Everysce:每执行完一个命令,将该命令存入缓冲区,每隔1秒就将缓冲区里的命令一起写入AOF文件
- No:每执行完一个命令,将该命令存入缓冲区,再由操作系统决定何时将命令写入AOF文件

1.2.2 AOF重写机制
当AOF文件过大时会触发重写机制,简单来说就是会读取数据库中的键值对数据,然后将每个键值对用一条命令记录到AOF文件中,将重复的命令合成为一个命令,全部完成后,再将新的AOF文件替换掉旧的AOF文件,比如

原本是三个命令,修改了两次num但是实际起作用的只有最后一次修改,并且由于两次执行的都是set操作,因此可以合并为mset。
重写的过程:主进程创建重写AOF的子进程,父子进程共享物理内存,重写子进程对这个内存为只读,重写子进程会读取数据库里的所有键值对,将每个键值对转化为一条命令。再将命令记录到重写日志(新的AOF日志)
与此同时==主进程依然可以进行正常命令处理。但是这时有个新问题:如果主进程进行了key-value的修改,那主进程和子进程的内存数据不一样了怎么办?
这里Redis设置了AOF重写缓冲区==,当Redis执行完一个命令后,它会同时将这个命令写入[AOF缓冲区]和[AOF重写缓冲区]
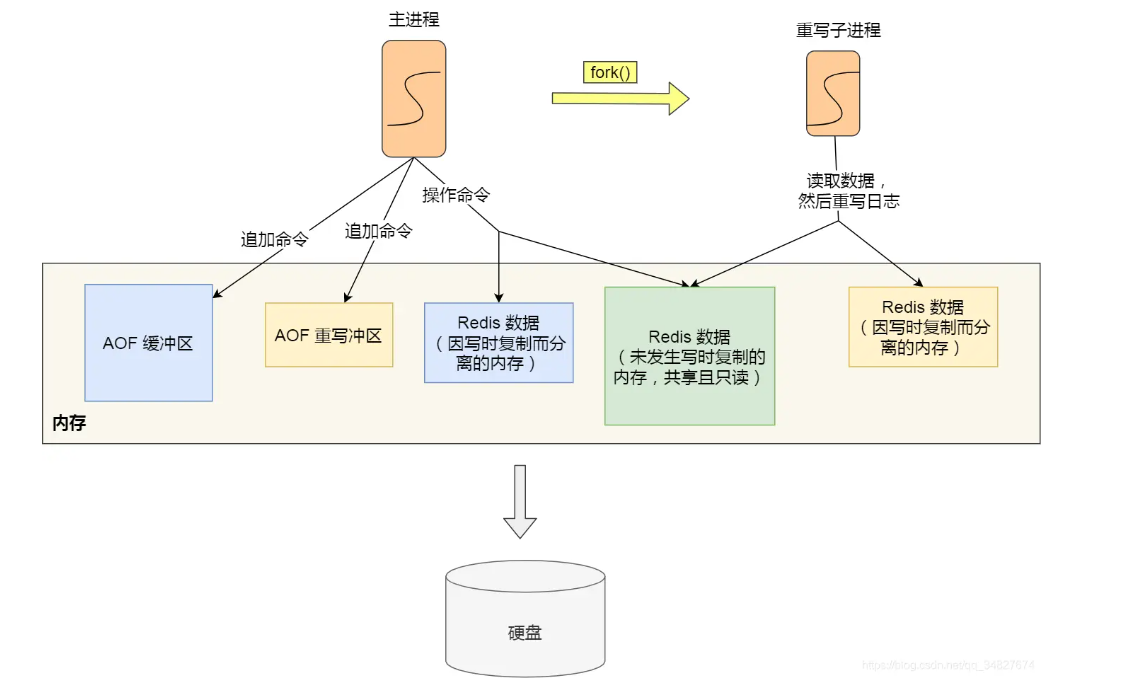
当子进程执行完重写操作后,会向主进程发送一条信号,主进程收到信号后会调用信号处理函数,作用是:将AOF重写缓冲区的所有内容追加到新的AOF文件中,将新的AOF文件覆盖现在的AOF文件。
1.3 RDB和AOF对比
1.4 混合持久化
即结合了RDB与AOF的优点:AOF前半部分是RDB格式的全量数据,后半部分是AOF格式。
缺点:可读性差,兼容性差。
2.Redis主从复制
如果我们将数据只存到一个Redis服务器当中,如果该Redis宕机,就会造成严重后果。因此我们将数据存到多个服务器中,其中把数据同步到其他服务器采用的就是Redis主从复制。
2.1第一次同步
主从服务器的第一次同步可以分为三个阶段:
- 第一阶段是建立连接、协商同步
- 第二阶段是主服务器同步数据给从服务器
- 第三阶段主服务器发送新写操作命令给从服务器
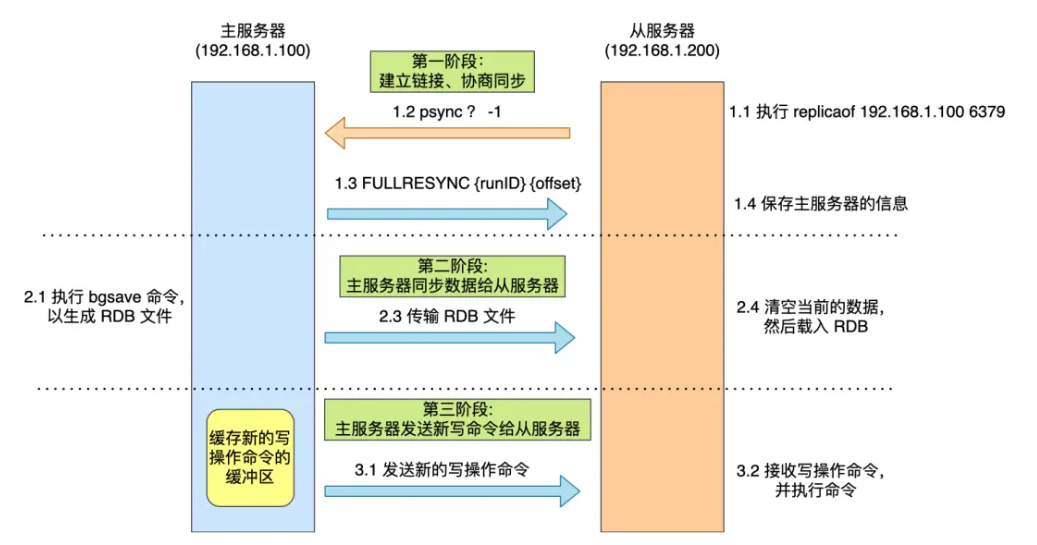
第一阶段:建立连接,协商同步
当执行replicaof命令之后,从服务器向主服务器发送psync命令,表示要进行数据同步。里面包含两个参数 - runID:每个服务器启动时会自动创建一个随机的runID,它可以用来与主服务器的runID进行比较,判断是否相同,如果相同说明不是第一次进行数据同步了,要进行增量同步。如果不同说明是第一次同步,要进行增量同步。
- offset:用来标记复制的进度
接收到命令后主服务器会返回FULLRESYNC命令(执行全量同步),里面包含主服务器的runID,offset
第二阶段:主服务器同步数据给从服务器
主服务器会执行bgsave命令生成RDB文件,并发送给从服务器,从服务器收到后会先清空当前数据,然后再载入RDB文件。
此时主服务器依然可以正常执行命令,但是这期间进行的操作并没有记录到RDB文件中,怎么保持主从数据的一致呢?
为了保持主从数据的一致性,主服务器将在下面三个时间间隔里进行的写操作记录到replication buffer缓冲区中: - 主服务器生成RDB文件期间
- 主服务器发送RDB文件期间
- 从服务器加载RDB文件期间
第三阶段:主服务器发送新的写操作给从服务器
在从服务器将RDB文件载入后,会发送一个确认消息给主服务器,接着主服务器会把relication buffer缓冲区里的写操作命令发送给从服务器,从服务器开始执行来自主服务器的写操作命令。至此第一次同步结束,两者的数据一致。
2.2 命令传播
主从服务器第一次同步后双方就会简历一个TCP连接,后续的写操作可以通过这个连接来将命令传播给从服务器
2.3 增量复制
当主从服务器之间的连接断开后再次重新连接,同步数据的过程叫增量复制
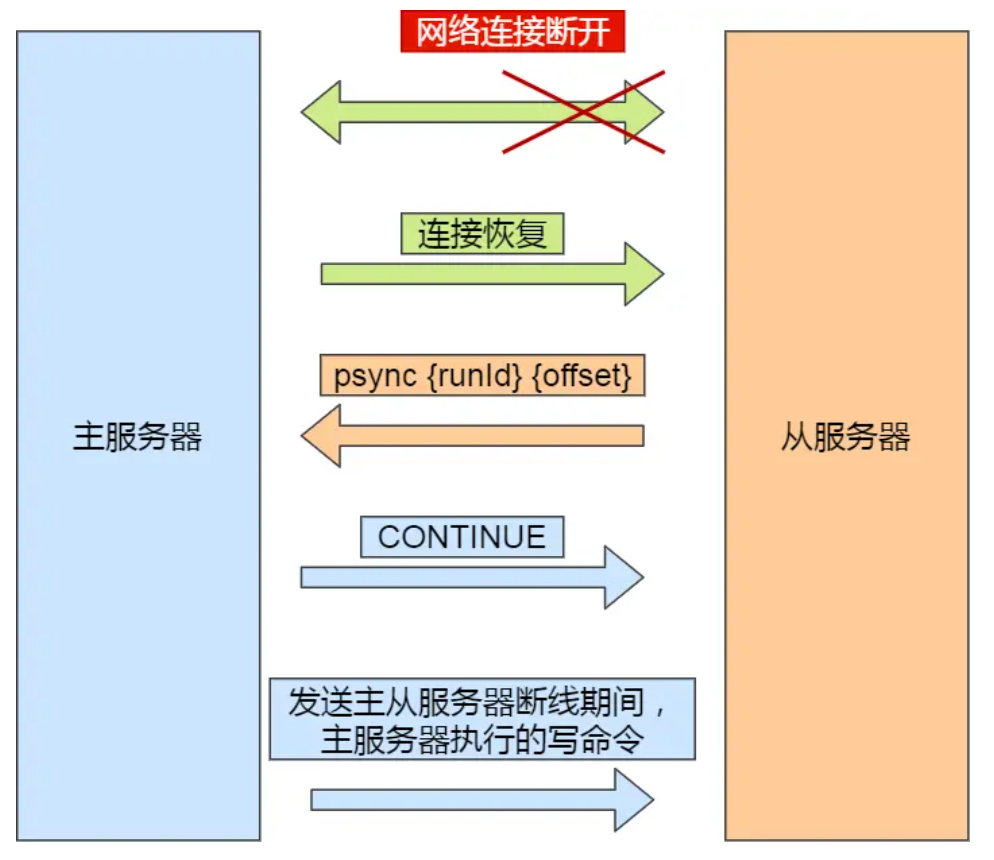
这里也主要有三个步骤
- 从服务器向主服务器发送psync命令
- 主服务器收到命令判断runID一致后返回CONTINUE命令告诉从服务器使用增量同步的方式
- 主服务器将断开期间主服务器执行的写命令发送给从服务器,从服务器再执行
其中
repl_backlog_buffer,和offset起到关键作用
repl_backlog_buffer:环形缓冲区,用于主从服务器断开连接后从中找到差异的数据
offset:标记缓冲区的进度,从服务器的offset标记自己到哪了,主服务器标记自己在哪里。
那repl_backlog_buffer里的内容是什么时候写入的呢?
在主服务器进行命令传播时,也会将命令存入repl_backlog_buffer,因此这个缓冲区里存放着最近的命令。
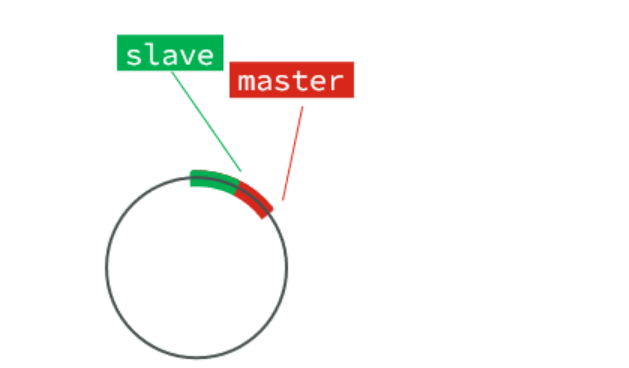
主服务器和从服务器之间的差,就是增量同步的数据
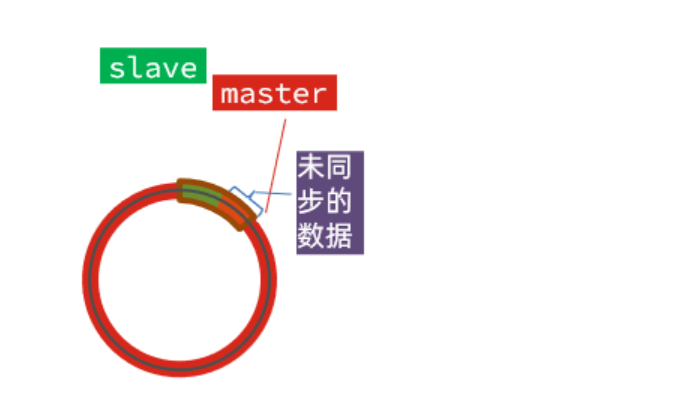
但是如果,主从服务器之间差的太多,已经将从服务器未同步的数据覆盖掉了,那接下来将使用全量同步的方式。
