Linux学习笔记之深入理解进程调度
进程切换
在写这篇文章之前向大家推荐一个视频,对于进程有很大的帮助,作者通过动画的方式生动地展示了进程的切换。
【进程–计算机科学最成功的理念】 https://www.bilibili.com/video/BV1kaynYmExy/?share_source=copy_web&vd_source=30ac2ef4ed8665e24e2c8949122836e1
1.为什么要切换进程
现在计算机上会同时运行多个程序,例如我现在打开的QQ浏览器网易云音乐等,电脑在同一时间内运行了多个程序,进程之间具有独立性一个应用只能解决自己的问题,就需要切换进程,不同进程之间处理不同的问题,共同使用CPU资源。
2.进程切换的原理
假如一所学校之中有一个同学因为发生了重大交通事故,导致躺在病床上,不能上学。那么他家长就可以向学校申请暂停学业,明年再来上学,这一学期不来上学在家养伤就行了,明年开学时,家长向学校提交暂停学业报告,学校通知学生再来上学。整个流程如下。
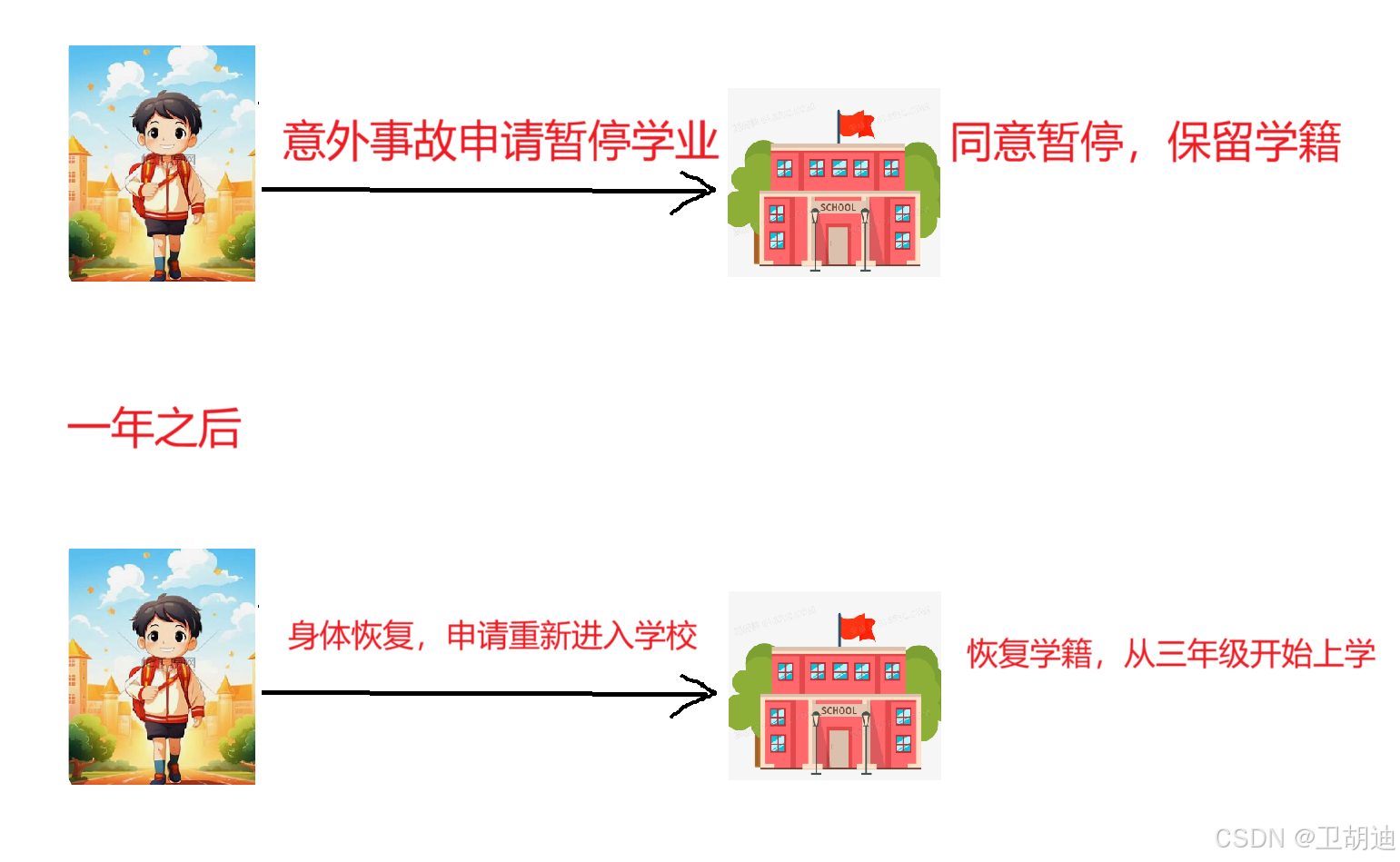
在这个过程中家长不可以突然不上学又不跟学校说明情况,那样等一年之后小明恢复身体在来学校上学,学校说你已经多日不上学并且怎么都联系不上,学校就有可能将小明学籍开除了。因此向学校说明情况需要保留学籍是十分重要的。
进程切换亦是如此。CPU由通用寄存器,指令计数器PC指针等构成,怎么来表示一个程序执行到哪个指令接下来要怎么做。
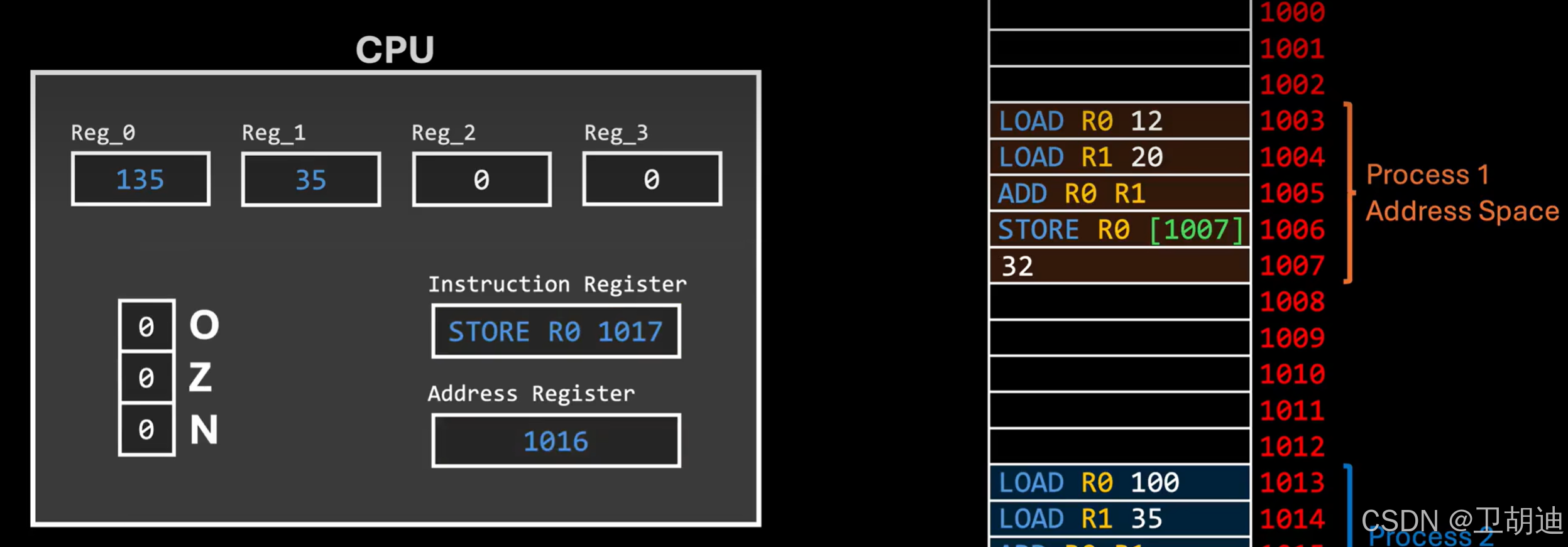
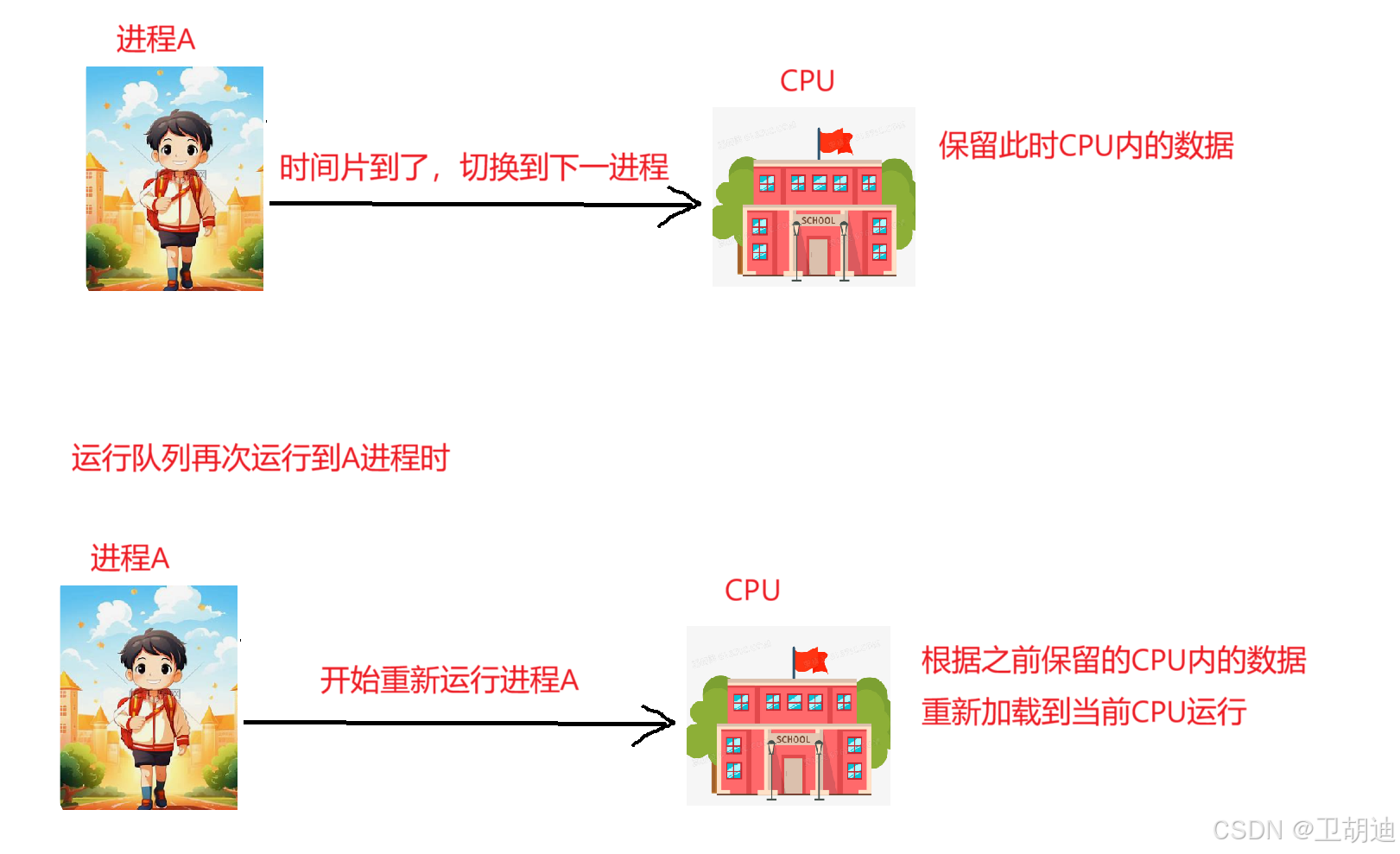
当A进程结束时,应当保留CPU里的数据,否则切换到B进城的时候,B进程一定会使用CPU,会修改CPU里的数据,当运行队列再次运转到A进程的时候,它会找不到原来的数据,使用错误的数据,就会产生错误。进程切换时就要保留对应进程的上下文数据
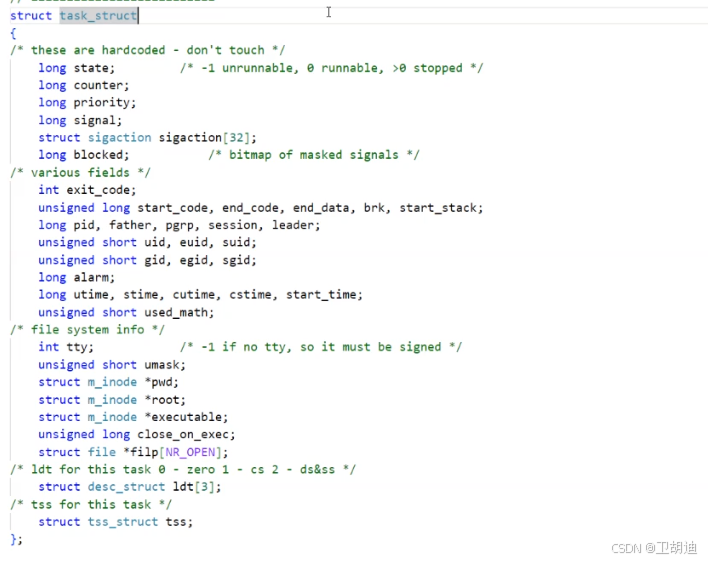
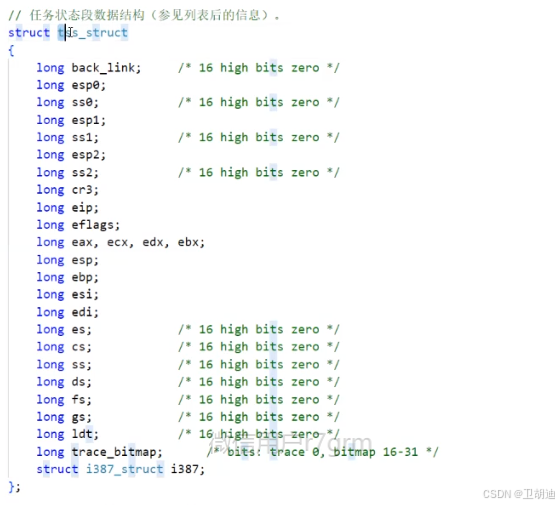
在较为旧的Linux内核中保留的CPU内的数据,就存在task_struct里,如下源码。其中的tSS就是CPU中的各种寄存器
3.进程切换的调度
3.1进程组织方式
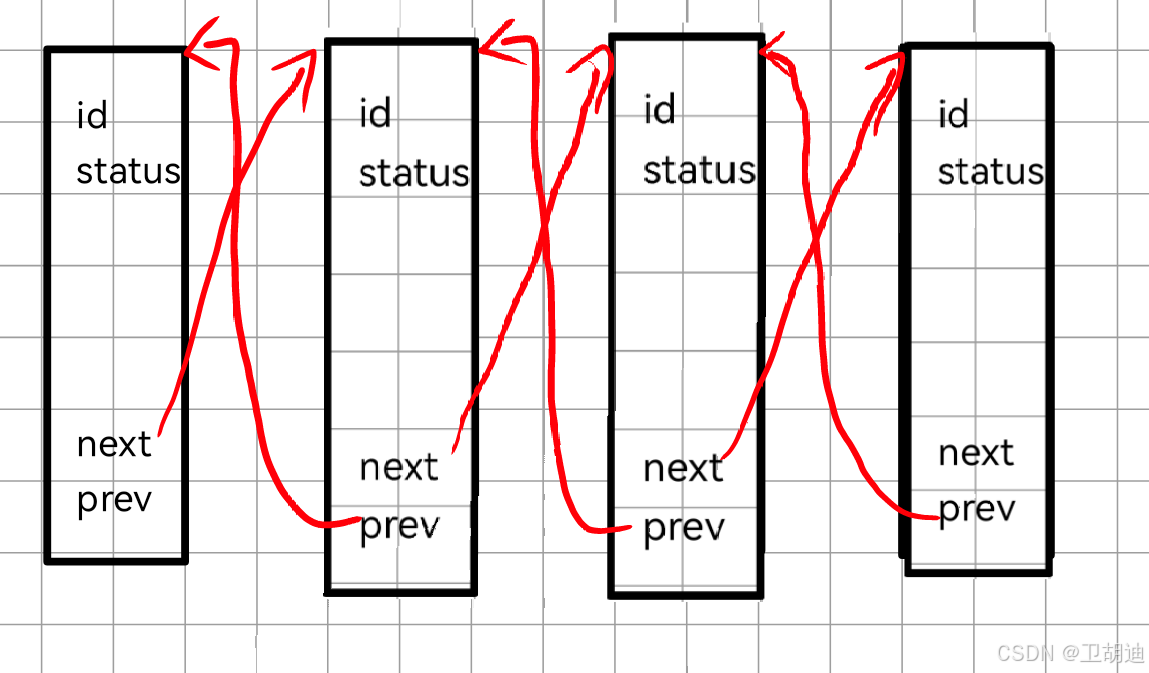
==一个进程可能既在就绪队列中等待 CPU 调度,又在某个资源等待队列中等待资源。==进程的状态只能有一个,但是可以在多个task_struct队列中,这是因为Linux内核中采用了双链表的形式,但与我们数据结构学的双链表有所不同,Linux使用数据和连接分离的双链表。传统的双链表如下图数据和连接模块放在一起。
struct task_struct
{
pid_t pid;
int status;
struct task_struct * next;
struct task_struct * prev;
}
然而在Linux中采用数据与连接模块分离的方式如下代码。
struct link
{
struct link * next;
struct link * prev;
}
struct task_struct
{
pid_t pid;
int status;
struct link run_queue;
}
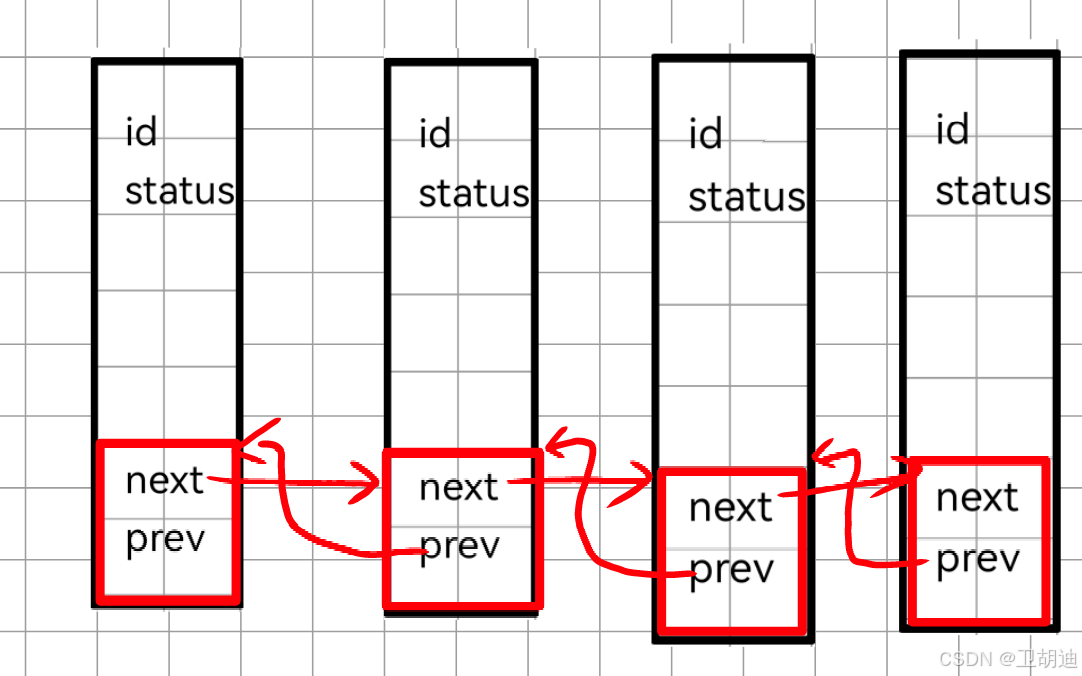
采用上述的方式也可以将进程连接起来看起来似乎与第一种没有太大的区别.但假如我们再加一个struct_link就会神奇的发现,它以另一种顺序组织了起来可以是wait_queen
struct link
{
struct link * next;
struct link * prev;
}
struct task_struct
{
pid_t pid;
int status;
struct link run_queue;
struct link wait_queue;
}
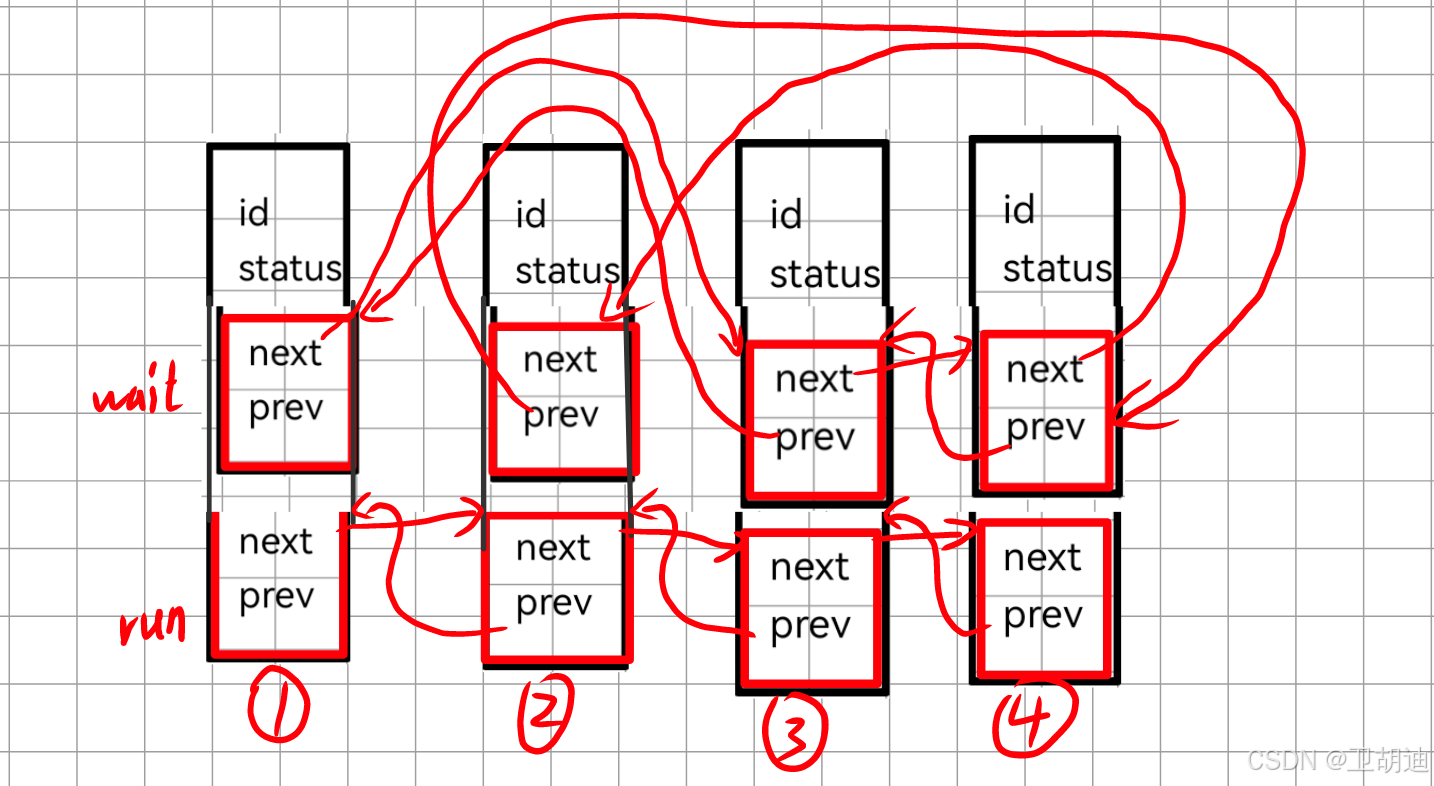
struct link run_queue;
struct link wait_queue;
此时运行队列的顺序是1 2 3 4,等待队列的运行顺序是1 3 4 2.同一个进程和数据就可以放在不同的队列之中了.解决了一个进程同时在两个不同队列中的难题.
3.1.1如何根据结构体某一类型数据访问其他成员
结构体内各个数据内存地址是固定的,遵循一套内存的对齐规则。如下代码。
#include<stdio.h>
struct A
{
int a;
int b;
};
int main()
{
struct A s1;
struct A s2;
printf("s1.a的地址%p,s1.b的地址%p,差值%p\n",&s1.a,&s1.b,&s1.b-&s1.a);
printf("s2.a的地址%p,s2.b的地址%p,差值%p\n",&s2.a,&s2.b,&s2.b-&s2.a);
return 0;
}

注意这里的值为1,是因为指针相减得到的是两个指针间的元素个数,指针类型为int,所以实际上位置偏差4字节。
由此便可得到如下代码。
(struct task_struct*) (&a - &((struct task_struct*)0->a))
(struct task_struct*)0->a表示假设0位置有个结构体对象,访问元素a,这里其实是合法的,因为我们没有修改该数据的值,只是访问数据。(&a - &((struct task_struct*)0->a))然后用a地址减去偏移量就是实际结构体的地址,最后在进行类型转换即可访问该结构体。
3.2为什么一个进程要同时在不同的队列之中
一个进程最终它的执行一定是由CPU来执行的,不可能由其他的硬件来完成.假如我们不采用一个进程在同时在两个队列之中的做法,如果进程A需要等待用户键盘输入,就把它放到键盘的等待队列之中,即将内存中运行队列的A进程移动到键盘的wait_queue中,此时用户输入完数据之后进程A要往下执行指令,但程序的指令必须由CPU来执行,代码块中的tSS存在也全是CPU的寄存器指令集,键盘是不可能帮助进程A执行程序的,此时就必须将进程a从键盘的等待队列中加载到内存的运行队列中由CPU来执行进程a的指令。由此倒不如直接将一个进程放在两个队列中省事,减少操作,进程A在等待队列中获得结果之后,直接将进程状态改变,移除对应wait_link即可
3.3进程如何调度
在进程真实的调度中实际上是保留两个运行队列的,一个是active活跃状态,一个是expired过期状态。
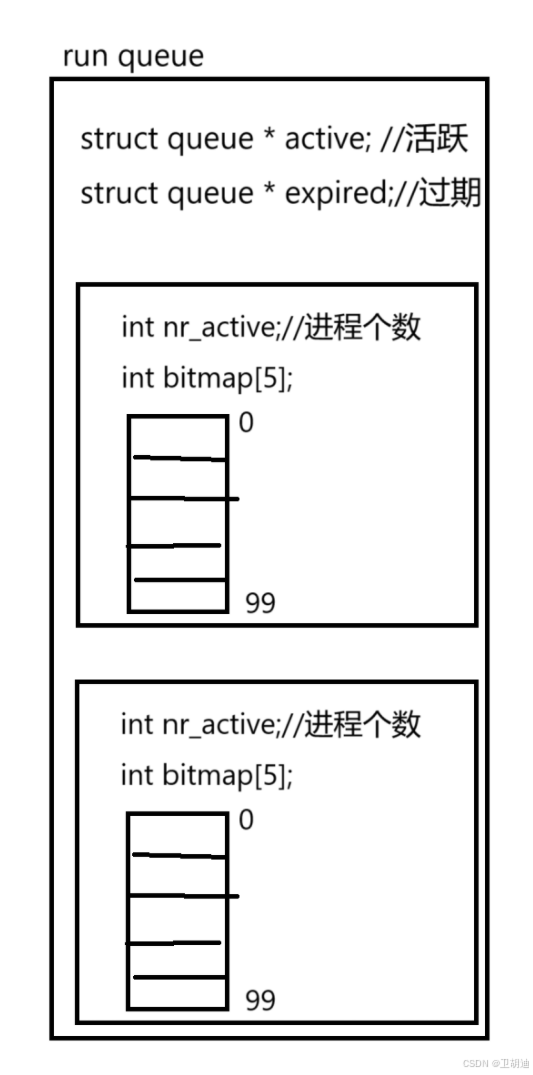
CPU调度有3种情况,第一个是进程a退出,第二个是有新的进程产生,第三个是进程a的时间片到了但是没有结束切换到下一个进程。对于第一个第三个情况对于CPU无伤大雅,问题是第二个情况。假设此时我们只有一个运行队列,当CPU执行进程a的时候,它不断产生新的进程并且把新进程的优先级调高,一直调到最高那么靠后的进程就永远不会被执行到。
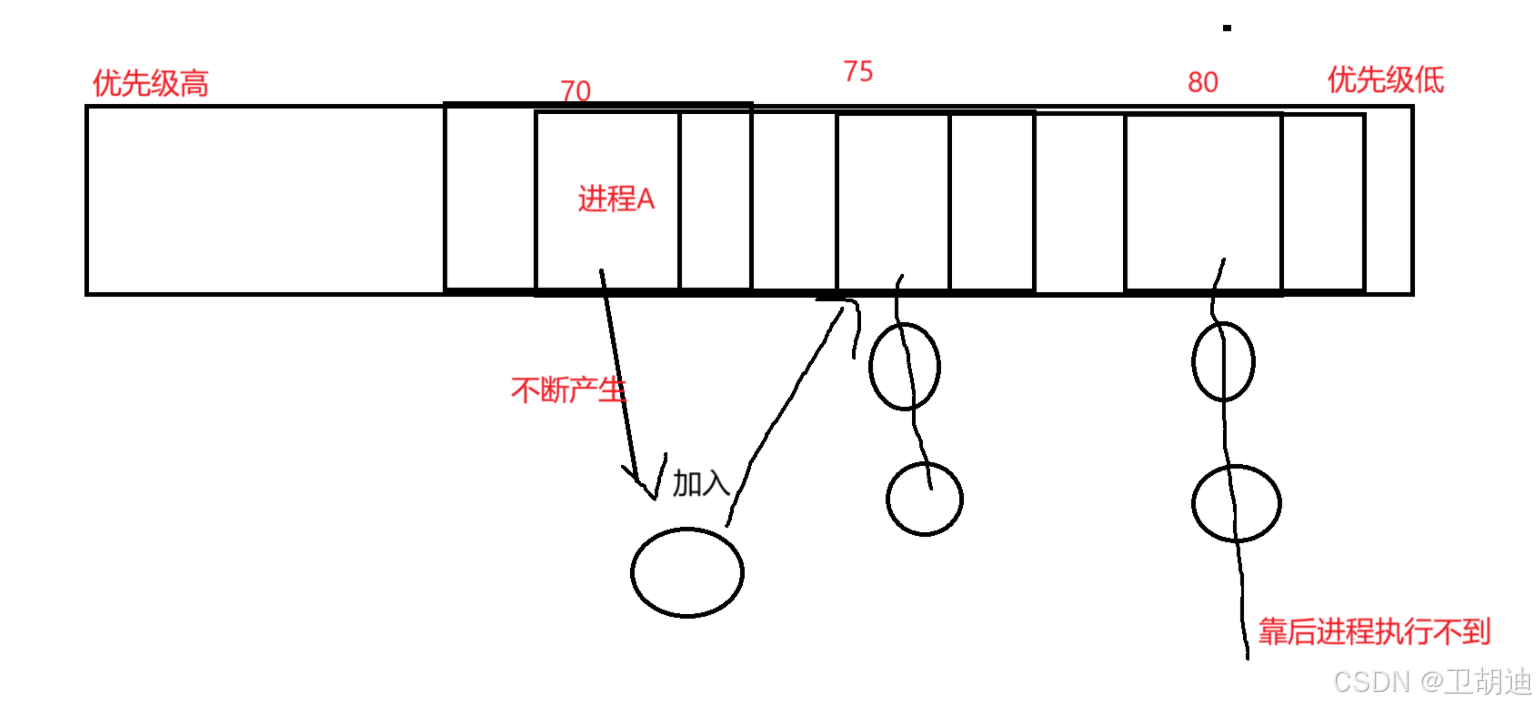
但是CPU要尽量的公平保证每个进程都要被执行到此时就会产生问题。于是便引入两个运行队列一个处于活跃状态一个处于过期状态,==当一个进程执行完之后把它加入到过期队列之中如果进程a产生新进程那么新的进程也加入到过期队列之中,==这样就可以保证当前活跃的运行队列他的进程数量是在不断减少的,是一定可以被执行完的。当活跃状态的运行队列中进程个数为零时,就将活跃队列指针与过期队列指针交换,此时在开始循环执行进程即可,这样保证了每个进程都尽可能公平的被调度
3.3.1 nr_active作用
nr_active表示当前运行队列的进程个数,每次在时间片结束,或者进程退出时都维护他,以便于后序判断该运行队列是否没有进程,否则每次都遍历一遍耗费时间。
3.3.2 int bit_map [5]作用
这其实是充当位图的用途,(不了解位图可以看这篇博客,这里就不过多赘述了。https://blog.csdn.net/2301_79964905/article/details/141185627?spm=1001.2014.3001.5501)。
在Linux系统的运行队列中,task_struct* queue[140]队列的大小为140,前100位是系统进程使用,要首先调用系统的进程,后40位是用户使用进程的位置,这也是为什么NICE值在[-20,19]的原因。
假如下标1位置有进程,就将第二个比特位设置为1,如下图。
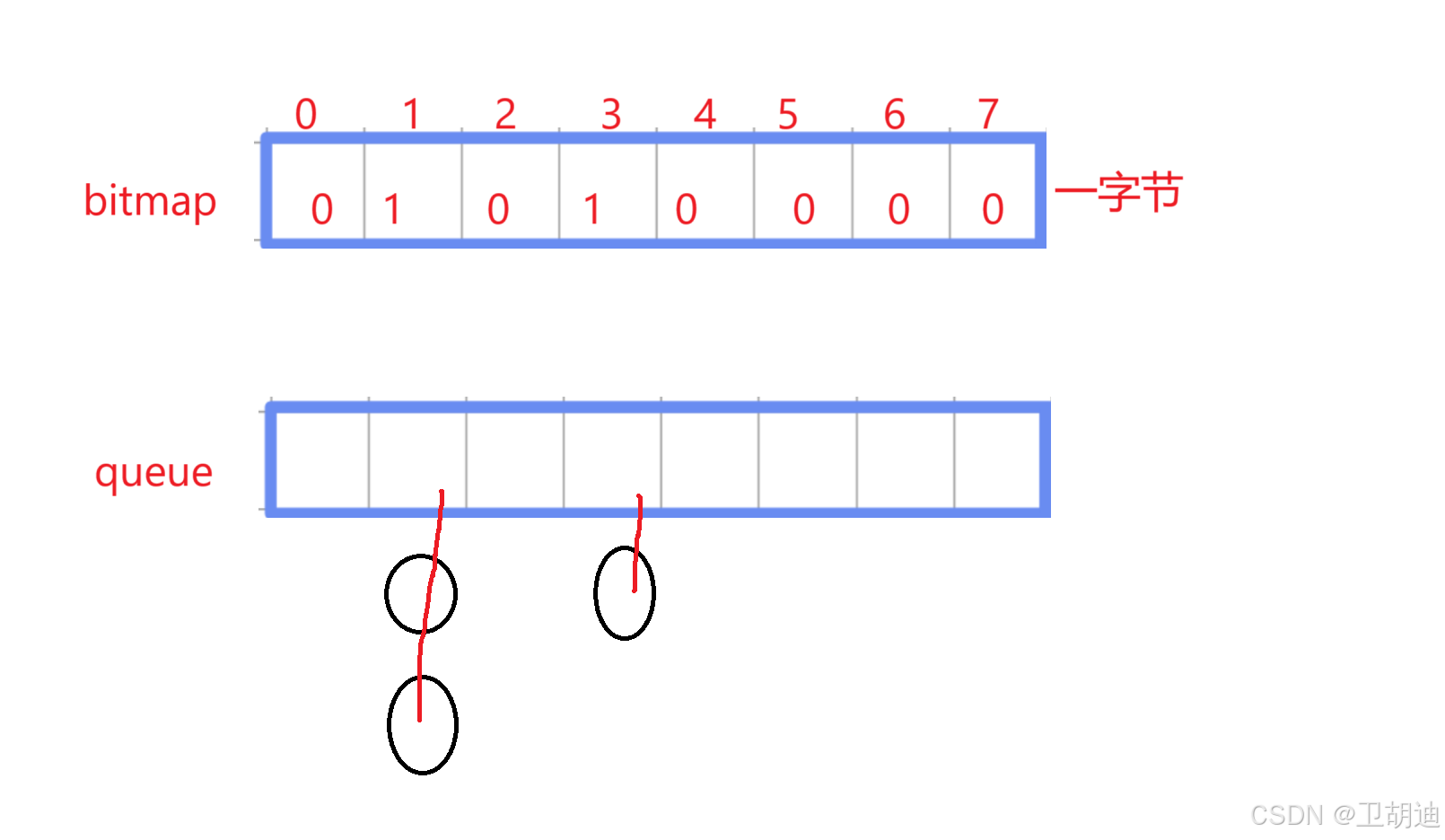
int类型位32位,5个160位恰好超过140个下标。那么再次遍历时便可借助bitmap一次检查32位。
for(int i=0; i<5; i++)
{
if(bitmap[i]==0)
continue;
else
{
//说明有为1的比特位即有进程
for(int j=0; j<32; j++)
{
if(bitmap[i*32+j]==0)
continue;
else
{
...........
//
}
}
}
}