四大LLM 微调开源工具包深度解析
引言:为何需要正确的微调策略
面对大量工具、技术和宣传,制定正确的微调策略至关重要。精心的微调方法可以带来显著效益:
- 缩短模型开发时间 60–80%
- 减少计算需求 40–70%
- 赋予领域专家迭代自由,无需等待机器学习工程师
过去需要庞大基础设施预算和全职 ML 团队的任务,现在可以通过可靠的开源工具在相对普通的硬件上完成。这意味着生产级的 LLM 微调不仅可能,而且实用。
企业现实环境的挑战 (Enterprise Reality Check)
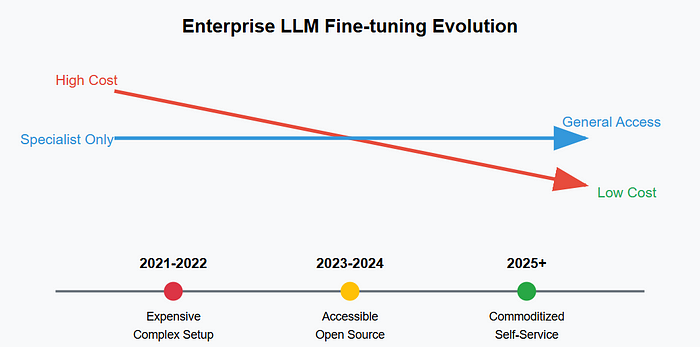
大多数企业面临的实际情况:
- 计算资源有限:通常是 16–32GB 显存的 GPU,而非学术界的大型集群。
- 高风险领域:金融、医疗、法律等领域需要模型理解合规性要求和细微的专业词汇。
- 快速迭代周期:业务团队无法等待数月,需要以天为单位的更新。
因此,微调不再是“锦上添花”,而是成为了竞争优势。正确实施微调能让企业行动更快、保持灵活,并将模型定制化应用于最关键的业务环节。开源框架使得这一优势比以往任何时候都更容易获得。
文章接下来将介绍四个经过实战检验、对企业友好的开源工具包,它们正帮助团队从“应该尝试微调”转向“每周都能发布改进”。
1. Unsloth: 内存效率的颠覆者
核心价值: 显著降低显存占用,提升训练速度。
适用场景: 基础设施预算有限(例如 GPU 显存限制在 24GB),但需要处理大量数据(如法律团队每天处理 10,000+ 份监管文件)并微调大型模型(如 13B 参数)。
Unsloth 解决了这个痛点。
# 导入所需库
from unsloth import FastLanguageModel
import torch
from datasets import Dataset
import json# 为监管文件分析设置生产级配置的函数
def setup_compliance_model():# 使用 Unsloth 的 FastLanguageModel 加载预训练模型# 支持 4bit 量化加载,大幅降低显存占用model, tokenizer = FastLanguageModel.from_pretrained(model_name="unsloth/llama-2-13b-bnb-4bit", # 指定要加载的模型,这里是经过 Unsloth 优化的 Llama-2 13B 4bit 量化版max_seq_length=4096, # 设置最大序列长度,以适应较长的文档dtype=None, # 数据类型,None 表示让 Unsloth 自动选择load_in_4bit=True, # 明确启用 4bit 量化加载device_map="auto" # 自动将模型分片加载到可用设备(GPU/CPU))# 配置 PEFT (Parameter-Efficient Fine-Tuning) 的 LoRA (Low-Rank Adaptation)# LoRA 是一种高效微调技术,只训练少量适配器参数model = FastLanguageModel.get_peft_model(model,r=32, # LoRA 的秩 (rank),较高的秩能捕捉更复杂的模式,适用于复杂的监管语言# 指定要应用 LoRA 适配器的目标模块(通常是注意力层)target_modules=["q_proj", "k_proj", "v_proj", "o_proj", # 注意力权重矩阵"gate_proj", "up_proj", "down_proj" # FFN (Feed-Forward Network) 层],lora_alpha=32, # LoRA 缩放因子,通常设为 r 或 2*rlora_dropout=0.1, # LoRA 层的 Dropout 比例,防止过拟合法律术语bias="none", # 是否训练偏置项,"none" 表示不训练,节省参数use_gradient_checkpointing=True, # 启用梯度检查点,用计算时间换取显存,进一步优化内存)return model, tokenizer # 返回配置好的模型和分词器# 企业级数据预处理流程函数
def prepare_regulatory_dataset(documents_path):# 从 jsonl 文件加载原始数据with open(documents_path, 'r') as f:raw_data = [json.loads(line) for line in f] # 逐行读取 json 对象# 将原始数据格式化为指令微调所需的格式formatted_data = []for item in raw_data:formatted_data.append({# 构建指令,要求模型分析文档"instruction": f"Analyze this regulatory document for compliance requirements: {item['document']}",# 模型的期望输出"output": item['analysis']})# 使用 Hugging Face Datasets 库将格式化后的列表转换为 Dataset 对象return Dataset.from_list(formatted_data)关键优势:
- 高效内存利用: 可以在单张企业级 GPU 上微调 13B 参数模型。
- 训练速度快: 通常比传统设置快 3–5 倍。
- 降低基础设施需求: 最多可减少 80% 的硬件需求,使企业级微调更易实现。
2. DeepSpeed: 实现大规模分布式训练
核心价值: 实现大规模分布式训练,支持超大模型。
适用场景: 需要在多 GPU 集群(本地或云端)上训练非常大的模型(如 70B 参数),或处理跨多语言、多业务单元的复杂训练任务(如客户服务模型)。
DeepSpeed 的分布式训练能力在这种情况下至关重要。
# 导入所需库
import deepspeed
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from torch.utils.data import DistributedSampler # 用于分布式训练的数据采样器
import os# 创建企业级 DeepSpeed 配置的函数
def create_deepspeed_config():# 返回一个包含 DeepSpeed 配置参数的字典return {"fp16": { # 混合精度训练配置"enabled": True, # 启用 FP16"loss_scale": 0, # 动态损失缩放 (0 表示自动)"loss_scale_window": 1000, # 动态损失缩放窗口大小"hysteresis": 2, # 动态损失缩放延迟"min_loss_scale": 1 # 最小损失缩放值},"zero_optimization": { # ZeRO (Zero Redundancy Optimizer) 优化配置"stage": 3, # 使用 ZeRO Stage 3 (最高级别的优化,划分模型参数、梯度和优化器状态)"offload_optimizer": { # 优化器状态卸载配置"device": "cpu", # 将优化器状态卸载到 CPU 内存"pin_memory": True # 使用 Pinned Memory 加速数据传输},"offload_param": { # 模型参数卸载配置 (Stage 3 特有)"device": "cpu", # 将未使用的模型参数卸载到 CPU"pin_memory": True},"overlap_comm": True, # 启用计算和通信重叠,提高效率"contiguous_gradients": True, # 使用连续的梯度内存,可能提高通信效率"sub_group_size": 1e9, # ZeRO Stage 3 参数,用于参数划分组的大小"reduce_bucket_size": 1e6, # 梯度 AllReduce 操作的桶大小"stage3_prefetch_bucket_size": 1e6, # Stage 3 预取数据的桶大小"stage3_param_persistence_threshold": 1e6 # Stage 3 参数持久性阈值},"optimizer": { # 优化器配置"type": "AdamW", # 使用 AdamW 优化器"params": {"lr": 2e-5, # 学习率"betas": [0.9, 0.95], # AdamW beta 参数"eps": 1e-8, # AdamW epsilon 参数"weight_decay": 0.1 # 权重衰减}},"scheduler": { # 学习率调度器配置"type": "WarmupLR", # 使用带有 Warmup 的学习率调度器"params": {"warmup_min_lr": 0, # Warmup 期间的最小学习率"warmup_max_lr": 2e-5, # Warmup 结束时的最大学习率 (等于优化器学习率)"warmup_num_steps": 1000 # Warmup 的步数}},"train_micro_batch_size_per_gpu": 1, # 每个 GPU 上的 Micro Batch Size"gradient_accumulation_steps": 16, # 梯度累积步数 (Effective Batch Size = micro_batch * num_gpus * accumulation_steps)"gradient_clipping": 1.0, # 梯度裁剪阈值,防止梯度爆炸"wall_clock_breakdown": True # 是否记录各阶段的时间开销}# 多 GPU 训练设置函数
def initialize_distributed_training(model, local_rank):# 设置当前进程使用的 GPU 设备torch.cuda.set_device(local_rank)# 初始化 DeepSpeed 分布式环境deepspeed.init_distributed()# 使用 DeepSpeed 初始化模型、优化器、数据加载器和学习率调度器# DeepSpeed 会根据配置文件自动包装模型和优化器model_engine, optimizer, train_loader, lr_scheduler = deepspeed.initialize(model=model, # 原始的 PyTorch 模型config=create_deepspeed_config(), # DeepSpeed 配置文件model_parameters=model.parameters(), # 需要优化的模型参数training_data=train_dataset, # 训练数据集 (需要提前定义好 train_dataset)collate_fn=data_collator # 数据整理函数 (需要提前定义好 data_collator))# 返回 DeepSpeed 处理过的引擎、优化器、加载器和调度器return model_engine, optimizer, train_loader, lr_scheduler# 带有企业级监控和检查点功能的训练函数
def train_with_monitoring(model_engine, train_loader):# 设置模型为训练模式model_engine.train()# 遍历训练数据加载器for step, batch in enumerate(train_loader):# 将数据移动到当前 GPU (DeepSpeed engine 通常会自动处理)# batch = {k: v.to(model_engine.local_rank) for k, v in batch.items()} # 可能需要根据具体 dataloader 调整# 前向传播计算损失 (DeepSpeed engine 的调用方式)loss = model_engine(batch) # 假设模型输入就是 batch# 反向传播计算梯度 (DeepSpeed engine 的调用方式)model_engine.backward(loss)# 执行优化器步骤 (DeepSpeed engine 的调用方式)model_engine.step()# 企业级日志记录if step % 100 == 0: # 每 100 步记录一次print(f"Step {step}, Loss: {loss.item():.4f}")# 假设有一个 log_metrics 函数用于将指标发送到企业监控系统 (如 W&B, MLflow, Prometheus)log_metrics({'training_loss': loss.item(), # 记录训练损失'learning_rate': model_engine.get_lr()[0], # 记录当前学习率'gpu_memory_usage': torch.cuda.max_memory_allocated() / 1024**3 # 记录 GPU 峰值显存使用 (GB)})# 保存检查点以实现容错if step % 1000 == 0: # 每 1000 步保存一次检查点# DeepSpeed 提供了方便的保存检查点接口# 第一个参数是保存目录,第二个参数是标识符 (可以是步数)model_engine.save_checkpoint('./checkpoints', step) # 注意:这里需要确保 './checkpoints' 目录存在关键特性:
- 专为企业级分布式训练设计: 支持训练 175B+ 参数的模型。
- 内置检查点 (Checkpointing): 对于长时间训练任务至关重要,可恢复中断的训练。
- CPU 卸载 (Offloading): 可将优化器状态、梯度甚至部分模型参数卸载到 CPU,大幅减少 GPU 显存占用(最高可达 90%)。
- 智能内存优化: 使大规模训练变得可行。
注意:
- ⚠️ 跨多节点运行时,网络带宽是主要瓶颈。
- ⚠️ 需要仔细规划和监控检查点存储(每个检查点可能需要 100GB+)。
3. Axolotl: 配置驱动的简洁性
核心价值: 通过 YAML 配置文件驱动微调,简化操作,提高可重复性,便于非技术人员使用和治理。
适用场景: 数据科学团队需要让业务用户能够无需编写代码就能实验不同的微调方法,同时保持治理和可复现性。
Axolotl 基于 YAML 的配置系统使其易于上手:
# config/customer_support_model.yml# 基础模型和类型配置
base_model: microsoft/DialoGPT-large # 指定基础模型
model_type: AutoModelForCausalLM # 指定模型类型 (Hugging Face AutoClass)
tokenizer_type: AutoTokenizer # 指定分词器类型 (Hugging Face AutoClass)# 企业安全与合规性设置
trust_remote_code: false # 禁止执行模型仓库中的自定义代码 (安全考虑)
use_auth_token: true # 使用认证 token (访问私有模型仓库时需要)# 资源管理配置
load_in_8bit: true # 启用 8bit 量化加载
load_in_4bit: false # 不启用 4bit 量化 (与 8bit 互斥)
gradient_checkpointing: true # 启用梯度检查点,节省显存# 数据配置
datasets:- path: ./data/customer_conversations.jsonl # 数据集路径 1type: completion # 数据格式类型 (如 completion, alpaca, sharegpt 等)field: text # completion 类型下包含文本的字段名- path: ./data/escalation_scenarios.jsonl # 数据集路径 2type: completionfield: conversation # 第二个数据集中包含文本的字段名# 模型架构适配器配置 (使用 LoRA)
adapter: lora # 指定使用 LoRA 适配器
lora_r: 64 # LoRA 的秩 (rank)
lora_alpha: 32 # LoRA 缩放因子
lora_dropout: 0.1 # LoRA Dropout 比例
lora_target_modules: # 指定应用 LoRA 的目标模块- q_proj- k_proj- v_proj- o_proj- fc_in- fc_out# 训练参数配置
sequence_len: 2048 # 训练时的序列长度
micro_batch_size: 4 # 单个 GPU 上的 Micro Batch Size
gradient_accumulation_steps: 8 # 梯度累积步数
num_epochs: 5 # 训练的总轮数
optimizer: adamw_bnb_8bit # 优化器类型 (如 adamw_torch, adamw_bnb_8bit)
lr_scheduler: cosine # 学习率调度器类型 (如 linear, cosine)
learning_rate: 0.0001 # 学习率
weight_decay: 0.01 # 权重衰减# 企业级监控与保存配置
logging_steps: 50 # 每隔多少步记录一次日志
eval_steps: 500 # 每隔多少步进行一次评估
save_steps: 1000 # 每隔多少步保存一次模型检查点
output_dir: ./models/customer_support_v2 # 模型和训练输出的保存目录# 评估配置 (用于生成样本)
eval_table_size: 5 # 生成评估表格时使用的样本数量
eval_table_max_new_tokens: 128 # 评估时生成的最大新 Token 数量
Axolotl 的优势在于其抽象层。下面的 Python 代码展示了如何在企业流程中包装 Axolotl。
# 导入所需库
import yaml
import subprocess # 用于执行命令行命令
import logging
from pathlib import Path # 用于处理文件路径# 定义一个企业级 Axolotl 流程的类
class EnterpriseAxolotlPipeline:def __init__(self, config_dir="./configs"):# 初始化配置目录和日志记录器self.config_dir = Path(config_dir)self.logger = logging.getLogger(__name__)# 配置基本的日志记录 (可以根据企业需求配置更复杂的日志系统)logging.basicConfig(level=logging.INFO)def validate_config(self, config_path):"""根据企业策略验证配置文件"""with open(config_path) as f:config = yaml.safe_load(f) # 加载 YAML 配置# 企业级验证检查示例# 检查是否启用了 trust_remote_code (通常在企业环境中不允许)if config.get('trust_remote_code', False):raise ValueError("trust_remote_code not allowed in enterprise environment")# 检查是否配置了认证 token (访问私有仓库可能需要)if not config.get('use_auth_token'):self.logger.warning("Authentication token not configured")# (可以添加更多基于企业策略的验证逻辑)return config # 返回验证通过的配置字典def launch_training(self, config_name):"""启动带有企业监控的训练"""config_path = self.config_dir / f"{config_name}.yml" # 构建配置文件的完整路径# 在启动前进行验证try:config = self.validate_config(config_path)except ValueError as e:self.logger.error(f"Configuration validation failed for {config_path}: {e}")return False # 验证失败则不启动训练self.logger.info(f"Launching Axolotl training with config: {config_path}")# 构建执行 Axolotl 训练的命令行命令# 使用 accelerate launch 启动,这是 Hugging Face 的分布式训练启动器cmd = ["accelerate", "launch", "-m", "axolotl.cli.train", # 指定运行 axolotl 训练脚本str(config_path) # 传入配置文件路径作为参数]# 启动子进程执行命令,并捕获标准输出和标准错误流process = subprocess.Popen(cmd,stdout=subprocess.PIPE, # 捕获标准输出stderr=subprocess.STDOUT, # 将标准错误重定向到标准输出universal_newlines=True # 将输出按文本行处理)# 将 Axolotl 的输出日志实时流式传输到企业监控/日志系统for line in process.stdout:self.logger.info(line.strip()) # 打印日志并移除首尾空白# 等待子进程结束process.wait()# 检查训练是否成功结束 (返回码为 0 表示成功)if process.returncode == 0:self.logger.info(f"Axolotl training completed successfully for {config_name}.")return Trueelse:self.logger.error(f"Axolotl training failed for {config_name} with return code {process.returncode}.")return Falsedef evaluate_model(self, config_name):"""运行企业模型评估"""config_path = self.config_dir / f"{config_name}.yml" # 构建配置文件路径self.logger.info(f"Launching Axolotl inference/evaluation with config: {config_path}")# 构建执行 Axolotl 推理/评估的命令行命令cmd = ["accelerate", "launch", "-m", "axolotl.cli.inference", # 指定运行 axolotl 推理脚本str(config_path) # 传入配置文件路径]# 执行评估命令,并捕获输出result = subprocess.run(cmd, capture_output=True, text=True)# 记录评估结果 (可以根据需要解析 result.stdout 和 result.stderr)self.logger.info(f"Evaluation stdout for {config_name}:\n{result.stdout}")if result.stderr:self.logger.warning(f"Evaluation stderr for {config_name}:\n{result.stderr}")return result # 返回包含执行结果的对象关键优势:
- “配置即代码” (Configuration-as-Code): 便于版本控制、治理和复现。
- 赋能非技术用户: 允许他们在安全可控的范围内调整训练设置。
- 灵活性: 技术团队仍然可以在需要时进行深度定制。
- 跨部门一致性: 无需让每个产品经理都学习 PyTorch,即可实现标准化的流程。实验和合规性的双赢。
4. LLaMA Factory: 多功能瑞士军刀
核心价值: 支持多种微调任务(文本、视觉、RLHF),功能全面。
适用场景: 需要一个统一系统处理多种模态的任务,例如产品团队需要同时处理基于文本的客户咨询和基于图像的产品支持请求。
LLaMA Factory 在这种多功能性方面表现出色。
下面的 Python 代码展示了如何用 LLaMA Factory 构建一个多模态支持系统(注意:原文代码块标记为 Ruby 是错误的,实际是 Python):
# 导入 LLaMA Factory 和其他所需库
# 注意: 实际导入可能需要根据 LLaMA Factory 的具体安装和版本调整
# from llamafactory import ChatModel # 假设 LLaMA Factory 提供 ChatModel 类
try:from llamafactory.chat import ChatModel # 更可能的位置
except ImportError:print("Warning: Failed to import ChatModel from llamafactory. Ensure LLaMA Factory is installed correctly.")# 定义一个 Mock 类以允许代码继续执行,实际使用时需要成功导入class ChatModel:def __init__(self, args): passdef chat(self, messages): return [{"role": "assistant", "content": "Mock response"}]import json
import torch
from typing import List, Dict, Any# 定义一个企业级多模态系统的类
class EnterpriseMultiModalSystem:def __init__(self, model_path: str):# 初始化模型路径和 ChatModel 实例self.model_path = model_path # 微调后的 LoRA 适配器路径self.chat_model = Noneself.initialize_model() # 调用初始化方法def initialize_model(self):"""初始化用于生产的多模态模型"""# 定义 LLaMA Factory ChatModel 的参数字典args = {"model_name": "llava-v1.5-13b", # 基础多模态模型名称 (例如 LLaVA)"adapter_name_or_path": self.model_path, # 加载微调后的 LoRA 适配器"template": "llava", # 对话模板,应与模型和微调方式匹配"finetuning_type": "lora", # 指定微调类型为 LoRA"quantization_bit": 4, # 使用 4-bit 量化 (如果需要)"use_unsloth": True, # 结合 Unsloth 进一步优化效率 (如果 LLaMA Factory 支持)# 可能还需要其他参数,如 device 等}# 实例化 ChatModelself.chat_model = ChatModel(args)print(f"Initialized ChatModel with args: {args}") # 打印初始化信息def process_customer_inquiry(self, text: str, image_path: str = None) -> Dict[str, Any]:"""处理包含可选图像的客户支持请求"""messages = [] # 初始化消息列表# 根据是否有图像路径,构建不同的用户消息内容if image_path:# LLaMA Factory (或 LLaVA 模板) 可能需要特定的格式来表示图像# 这里的 "<image>\n{text}" 是一个示例,具体格式需参考 LLaMA Factory 文档messages.append({"role": "user","content": f"<image>\n{text}", # 文本内容和图像占位符"image": image_path # 传递图像路径 (ChatModel 内部会处理加载)})else:# 如果没有图像,只包含文本内容messages.append({"role": "user","content": text})# 调用 ChatModel 的 chat 方法获取模型响应# 假设 chat 方法返回一个包含对话历史的列表,取最后一个助手的回答response = self.chat_model.chat(messages)assistant_response = response[-1]["content"] if response else "Error: No response generated"# 返回一个包含处理结果的字典return {"response": assistant_response, # 模型生成的响应文本"confidence": self._calculate_confidence(response), # 计算响应置信度 (需要自行实现)"requires_human_escalation": self._needs_escalation(response) # 判断是否需要人工介入 (需要自行实现)}def _calculate_confidence(self, response) -> float:"""计算响应置信度,用于企业决策"""# TODO: 根据模型输出或其他指标实现置信度评分逻辑# 这可以与现有的 MLOps 流程集成# print("Warning: _calculate_confidence not implemented.")return 0.85 # 返回一个占位符值def _needs_escalation(self, response) -> bool:"""根据企业业务逻辑判断是否需要人工介入"""# TODO: 实现判断是否需要上报的逻辑# 例如,基于置信度、检测到的敏感词、特定意图等# print("Warning: _needs_escalation not implemented.")# 示例:如果置信度低于某个阈值,则需要人工介入if self._calculate_confidence(response) < 0.7:return True# 示例:如果响应包含特定触发词# if "escalate" in response[-1].get("content", "").lower():# return Truereturn False # 返回一个占位符值LLaMA Factory 也支持 RLHF(基于人类反馈的强化学习)进行模型对齐。
# RLHF 集成,用于企业价值对齐的函数
def setup_rlhf_training():"""配置 RLHF 以对齐企业价值观"""# 定义 RLHF 阶段的配置字典 (通常作为 LLaMA Factory 的参数或配置文件内容)rlhf_config = {"model_name": "llama2-7b-chat", # 用于 RLHF 的基础模型"dataset": "enterprise_preference_data", # 包含偏好数据的数据集名称或路径 (例如,标注好的“好”/“坏”响应对)"template": "llama2", # 对话模板"finetuning_type": "lora", # RLHF 阶段通常也使用 PEFT 方法"stage": "ppo", # 指定 RLHF 阶段为 PPO (Proximal Policy Optimization)"reward_model": "./models/enterprise_reward_model", # 预训练好的奖励模型路径 (用于评价生成的好坏)"ppo_epochs": 1, # PPO 训练的轮数"ppo_buffer_size": 512, # PPO 经验缓冲区大小"ppo_batch_size": 64, # PPO Minibatch 大小"ppo_target": 6.0, # KL 散度惩罚的目标值 (控制与参考模型的偏离程度)"ppo_whiten_rewards": True, # 是否对奖励进行白化 (标准化)"ref_model": "base_model", # 用于计算 KL 散度的参考模型 (可以是原始基础模型)"output_dir": "./saves/llama2-enterprise-aligned", # RLHF 训练后模型的保存目录# 可能还需要学习率、优化器等其他 PPO 相关参数}return rlhf_config # 返回配置字典 (实际使用时,这个字典会传给 LLaMA Factory 的训练脚本/函数)RLHF 的配置也可以通过 YAML 文件管理:
# config/rlhf_alignment.yml# 企业价值对齐的 RLHF 配置
model_name: llama2-13b-chat # 用于 RLHF 的基础模型
dataset: company_policies_preference # 包含公司政策偏好的数据集
template: llama2 # 对话模板# RLHF 阶段与模型设置
stage: ppo # 指定 PPO 阶段
reward_model: ./models/company_values_reward_model # 公司价值观奖励模型路径
finetuning_type: lora # 在 PPO 阶段也使用 LoRA# PPO 超参数,针对企业对齐进行调整
ppo_epochs: 2 # PPO 训练轮数
ppo_buffer_size: 1024 # 经验缓冲区大小
ppo_batch_size: 128 # Minibatch 大小
ppo_target: 6.0 # KL 目标值
ppo_whiten_rewards: true # 奖励白化# 生成时的企业约束
max_new_tokens: 512 # 控制生成长度
temperature: 0.7 # 控制随机性
top_p: 0.9 # 控制核心词汇采样# 合规性与安全设置
# (这些可能是 LLaMA Factory 推理时或自定义的参数)
safety_filter: enabled # 是否启用安全过滤器
content_policy_check: true # 是否进行内容策略检查
output_dir: ./models/enterprise_aligned_assistant # 对齐后模型的保存目录
关键优势:
- 多功能性: 支持文本和视觉微调,是多模态客户支持系统的理想选择。
- 集成 RLHF: 允许在训练过程中就将模型与公司政策和语调对齐,而不仅仅是部署后调整。
监控和可视化
一个用于监控和可视化的 Python 代码片段示例:
# 企业监控集成示例
import time # 导入 time 模块
import wandb # Weights & Biases (实验跟踪)
import mlflow # MLflow (ML 生命周期管理)
from prometheus_client import Counter, Histogram # Prometheus 客户端 (监控指标)
# 假设 training_function 是你要包装的实际训练函数
# from your_training_module import training_function# 定义用于企业监控的 Prometheus 指标
# Counter: 只增不减的计数器
training_jobs_total = Counter('llm_training_jobs_total', # 指标名称'Total training jobs started' # 指标描述
)
# Histogram: 直方图,用于统计分布,如响应时间、请求大小等
training_duration = Histogram('llm_training_duration_seconds', # 指标名称'Training duration in seconds' # 指标描述# buckets=(...) # 可以自定义桶的边界
)
gpu_utilization = Histogram('gpu_utilization_percent', # 指标名称'GPU utilization during training' # 指标描述
)# 定义一个装饰器函数,用于包装训练函数并添加监控逻辑
def enterprise_training_wrapper(training_function):# 定义内部包装函数def wrapper(*args, **kwargs):# 训练任务开始,计数器加一training_jobs_total.inc()start_time = time.time() # 记录开始时间# 初始化实验跟踪工具try:mlflow.start_run() # 开始一个新的 MLflow Runwandb.init(project="enterprise-llm-finetuning") # 初始化 W&B 项目# (可能需要配置 W&B API Key 等环境变量)print("Initialized MLflow and W&B tracking.")except Exception as track_e:print(f"Warning: Failed to initialize tracking tools: {track_e}")# 即使跟踪工具初始化失败,也应继续执行训练try:# 调用原始的训练函数print(f"Starting training function: {training_function.__name__}")result = training_function(*args, **kwargs)print(f"Training function {training_function.__name__} completed.")# 训练成功,记录指标duration = time.time() - start_timetraining_duration.observe(duration) # 记录训练时长到直方图# (这里需要实际获取 GPU 利用率的方法,是示例性的)# gpu_utilization.observe(get_average_gpu_utilization(...))try:mlflow.log_metric("training_success", 1) # 记录成功状态到 MLflowmlflow.log_metric("training_duration_seconds", duration) # 记录时长到 MLflowwandb.log({"training_success": 1, "training_duration_seconds": duration}) # 记录到 W&Bexcept Exception as log_e:print(f"Warning: Failed to log success metrics: {log_e}")return result # 返回原始训练函数的结果except Exception as e:# 训练失败print(f"Training function {training_function.__name__} failed: {e}")try:mlflow.log_metric("training_success", 0) # 记录失败状态到 MLflowwandb.log({"training_success": 0}) # 记录失败状态到 W&Bexcept Exception as log_fail_e:print(f"Warning: Failed to log failure metrics: {log_fail_e}")raise e # 将原始异常重新抛出finally:# 无论成功或失败,都结束跟踪try:mlflow.end_run() # 结束 MLflow Runwandb.finish() # 结束 W&B Runprint("Finalized MLflow and W&B tracking.")except Exception as final_e:print(f"Warning: Failed to finalize tracking tools: {final_e}")return wrapper # 返回包装后的函数# 使用示例:
# @enterprise_training_wrapper
# def my_actual_training_job(config):
# print("Running the actual training logic...")
# time.sleep(5) # 模拟训练过程
# # ... 实际的训练代码 ...
# if config.get("simulate_failure"):
# raise ValueError("Simulated training failure")
# print("Actual training logic finished.")
# return {"final_loss": 0.1}
#
# if __name__ == "__main__":
# # 运行包装后的训练函数
# try:
# results = my_actual_training_job({"simulate_failure": False})
# print(f"Training result: {results}")
# except Exception as e:
# print(f"Caught training exception: {e}")
#
# try:
# my_actual_training_job({"simulate_failure": True})
# except Exception as e:
# print(f"Caught training exception: {e}")一点安全与合规性考量:
- 数据治理: 实施适当的数据血缘追踪。
- 模型版本控制: 使用 MLflow 或类似工具进行模型生命周期管理。
- 访问控制: 与企业 IAM (身份与访问管理) 集成。
- 审计追踪: 为所有训练活动记录审计日志以满足合规要求。
结论
希望这个介绍能帮助读者了解可用的工具以及如何在自己的微调工作流中利用它们。关键问题不是是否采用这些方法,而是多快能将它们集成到现有开发流程中。