网络原理8 - HTTP协议1
我们在前面的文章讲过,应用层的协议(自定义协议)是需要我们程序员自己定义的,在之前我们已经认识的应用层协议有xml、json……这里我们要回过头来介绍HTTP协议(我们后端开发程序员主要通过这个协议来构造HTTP服务器)。
HTTP是什么
HTTP协议,全称“超文本传输协议”,是一种应用非常广泛的应用层协议。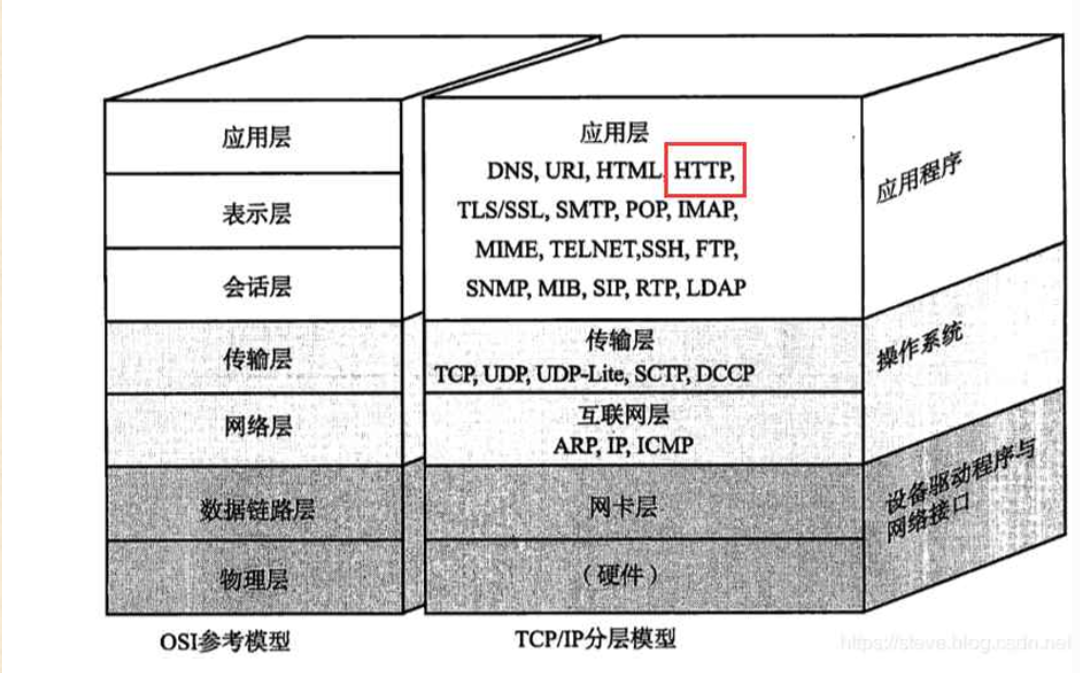
什么是文本、富文本、超文本?
文本:字符串(能在UTF8、GBK、ASCLL码表上找到的合法字符)
超文本:不仅仅是字符串,还可以携带图片、视频、音频、特殊格式啥的、HTML等等
富文本:典型例子:word文档 。
HTTP诞生于1991年,已经发展为如今最主流使用的一种应用层协议了。 
最新的HTTP3版本也在完善推出中。
HTTP协议是基于传输层的TCP协议实现的(1.0、1.1、2.0版本均使用TCP协议,HTTP 3则是基于UDP实现的)。尽管已经过去了二十多年,目前HTTP主流的版本仍然是HTTP1.1。
HTTP协议最主要的应用场景,就是网站,浏览器和服务器之间进行传输数据。客户端(手机、PC)和服务器之间的数据交互,也可能是HTTP。
举个例子: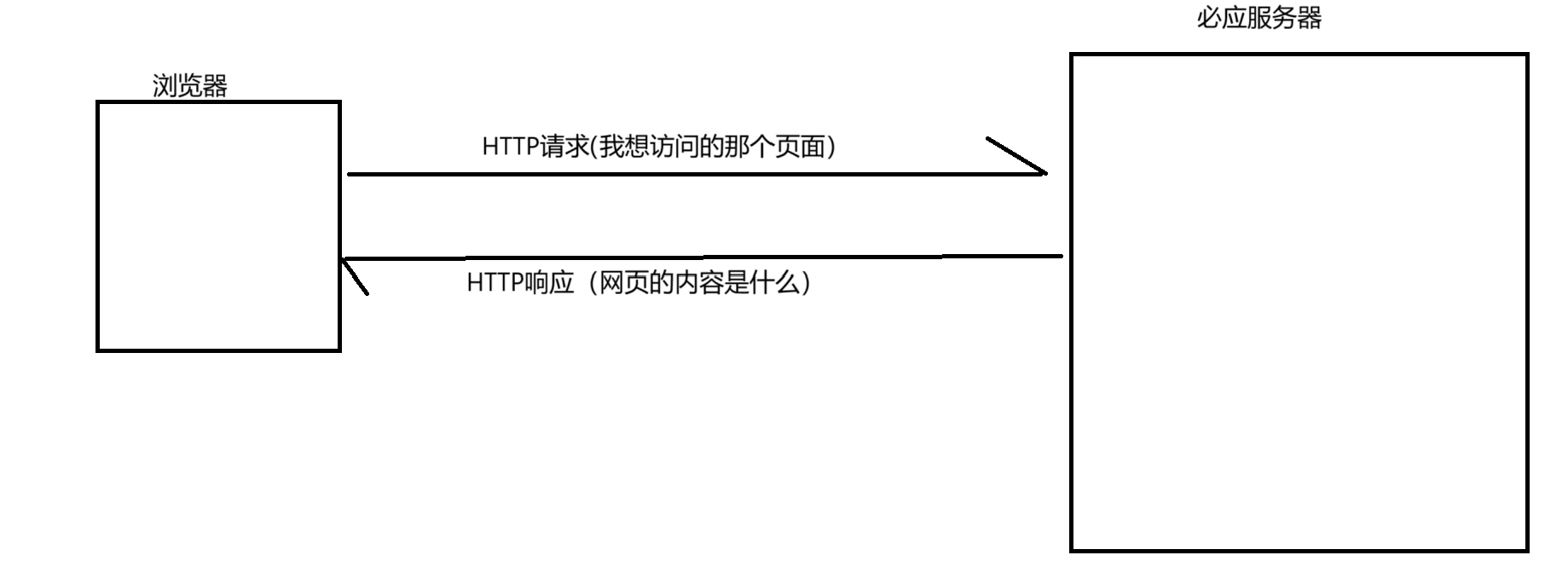
当我们在浏览器中输入“必应搜索”的网址(URL)的时候,浏览器就会给百度服务器发送一个HTTP请求,百度服务器就会返回一个HTTP响应。
这个响应结果被浏览器进行解析之后,就展示成我们所看到的页面内容(这个过程中,浏览器可能给服务器发送了多个HTTP请求,服务器也会对应返回多个响应,这些响应里卖弄就包含了页面HTML,CSS,JavaScript,图片,字体等等信息)
理解“应用层协议”
前面我们已经研究了TCP/IP,知道了数据能从客户端进程,经过路径的选择,跨网络传输到服务器端进程(通过IP地址和端口号)。
但是仅仅只是把数据从A送到B就行了吗?
举个例子:
我们在某宝上下单了一台笔记本电脑,卖家[客户端]通过顺丰快递[传输+路径选择]送到我们这里[服务器]就完了吗?
当然不是啦,买家(我们)还需要对产品进行使用,使用完之后,再对卖家进行评分。
我们把数据从A端传送到B端,TCP/IP解决的是顺丰的功能(运输),而两端还需要大队数据进行加工处理或者解析使用。所以在应用层中还需要一层协议,不关心通信的细节,关心的是应用细节。
这层协议就叫做应用层协议。而应用程序是会有不同的业务场景的,所以应用层协议是有不同种类的,其中最经典的协议之一就是我们接下来要讲的HTTP协议了。
在我们刚举的例子中,顺丰快递相当于TCP/IP的功能,那么买回来的笔记本附带的说明就可以理解成用户应用层协议(指导用户如何使用应用的功能)。
HTTP协议的工作流程
在上文中,我们举了浏览器和必应的例子,我们在浏览器中输入必应的网址,此时浏览器就会给对应服务器发送一个HTTP请求,对方服务器接收到请求,经过处理就会返回一个HTTP响应(也就是我们所看到的必应搜索页面)。 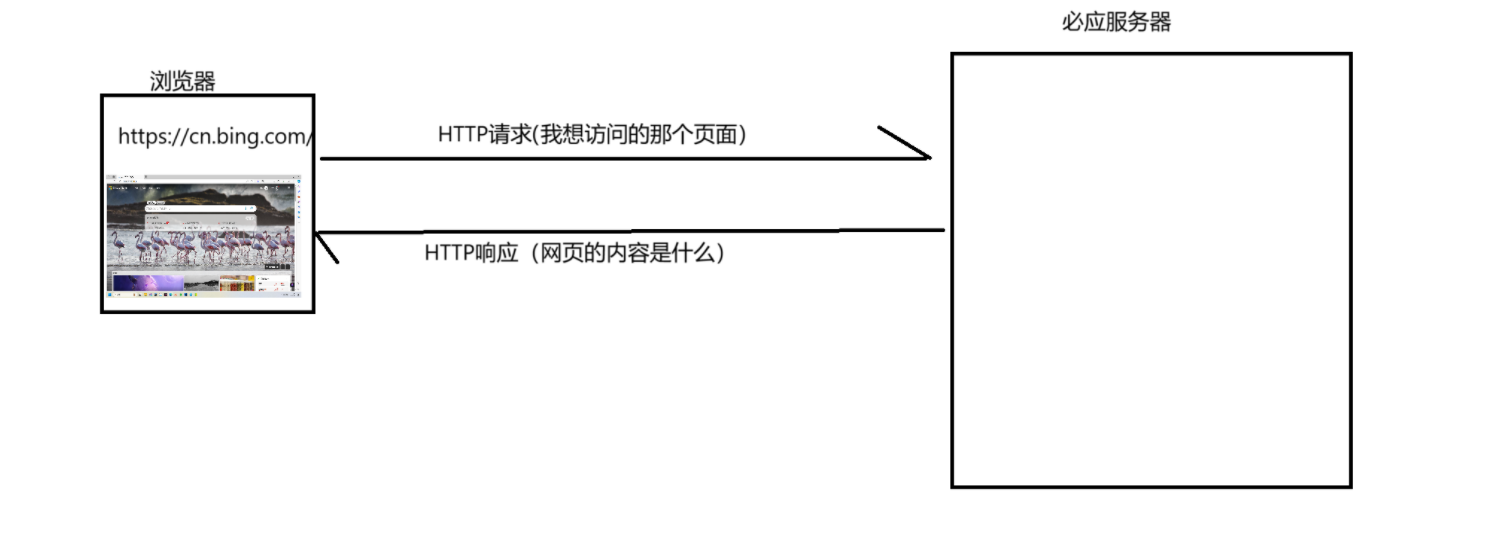
HTTP协议交互的过程,是非常经典的“一问一答”,事实上,当我们访问一个网站的时候,一般涉及不止一次HTTP请求/响应的交互过程。
HTTP协议格式
HTTP是超文本传输协议,但其仍然是一个文本格式协议,我们可以通过Fiddler进行抓包,分析HTTP请求/响应的细节。
抓包工具
Fiddler官网地址:Web 调试代理和故障排除工具 |琴师 (telerik.com)

 安装过程一路next即可。
安装过程一路next即可。
安装之后,在抓包之前还需要一个简单的设置:
将HTTPS里面的选项都勾选上,并且一定要下载认证证书 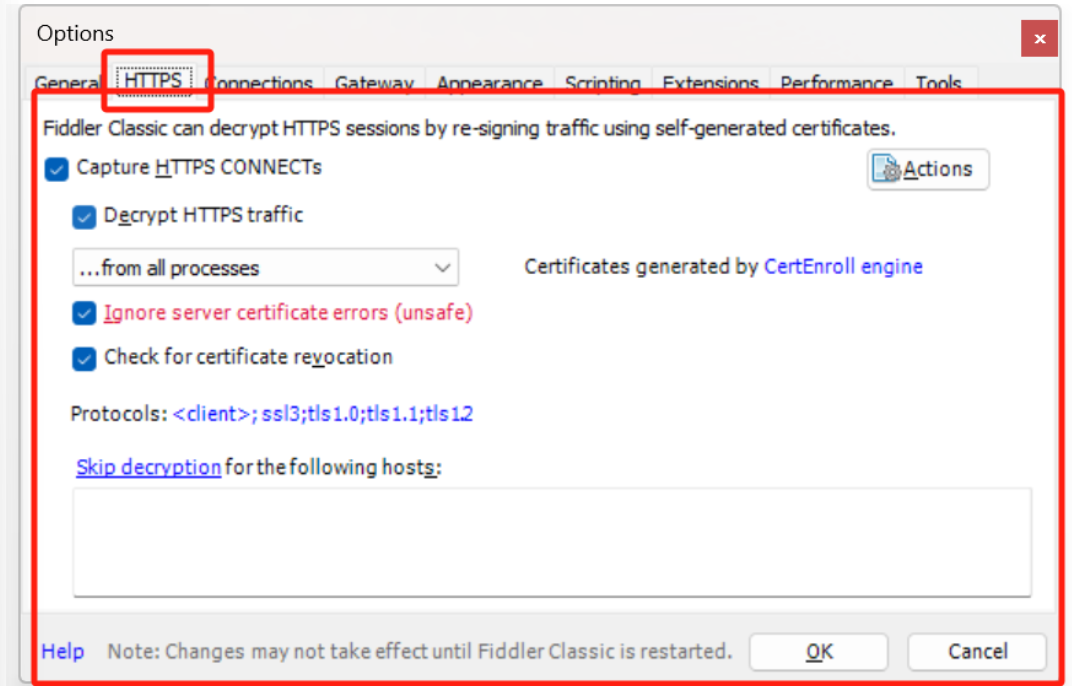
完成上面的操作,如果我们电脑本身还运行着其它代理程序,都要关闭,代理程序可能会有冲突。
原理
Fiddler相当于一个“代理”,浏览器在访问必应的时候,就会把HTTP请求线转发给Fiddler,Fiddler再把请求转发给必应服务器。当必应服务器放回数据的时候,Fiddler拿到返回数据,再把数据发送给浏览器。
因此,Fiddler就能清楚浏览器和必应服务器之间的交互的数据细节。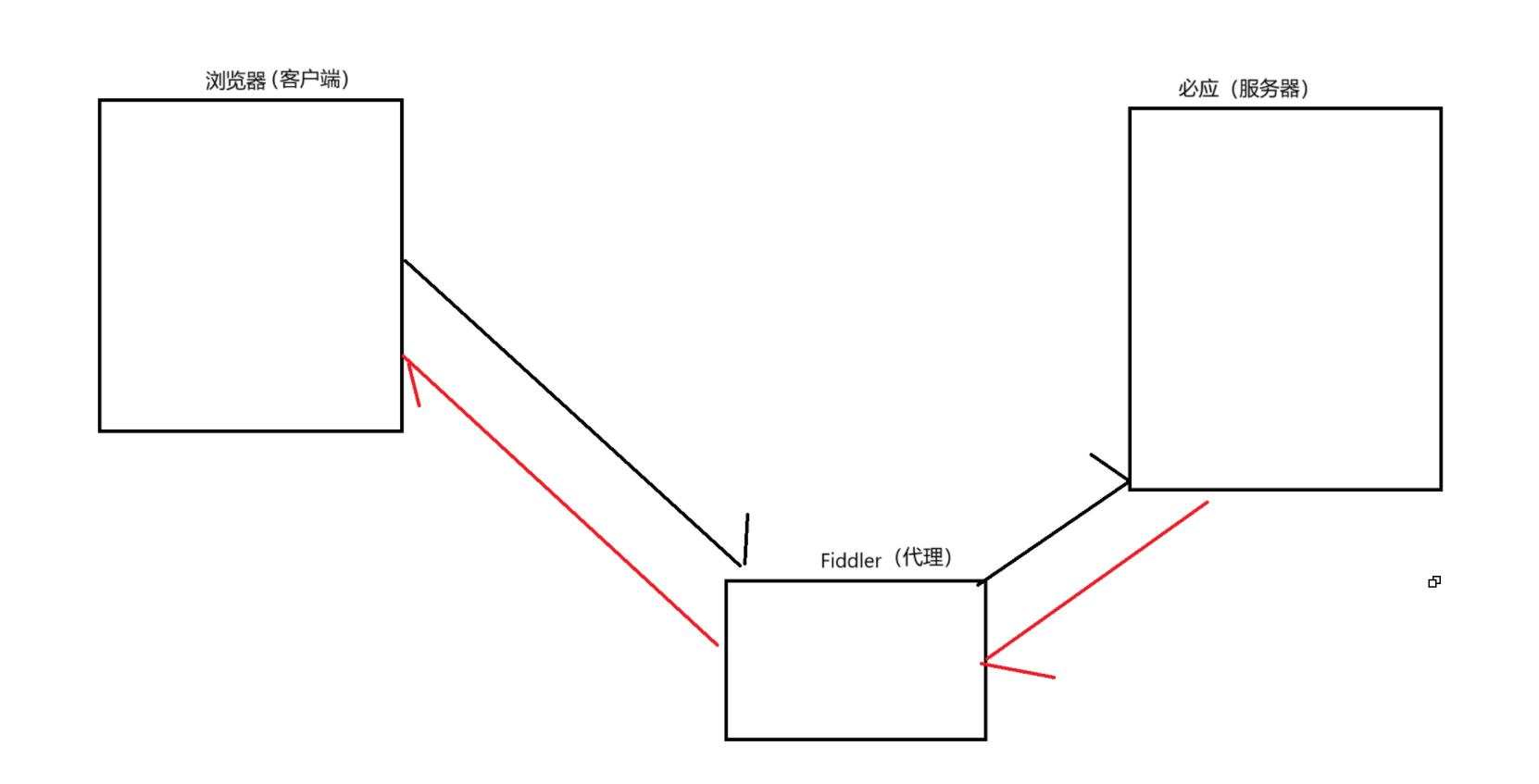
注意:这个代理,是一个程序,而不是像路由器、交换机那样的设备,是工作再应用层的,它可以配置在客户端上也可以配置在服务器上,上述的转发,都是站在应用层角度上的。
使用
如果我们上述的安装配置过程是ok的,此时我们就可以看到fiddler,能抓到很多的HTTP和HTTPS数据包 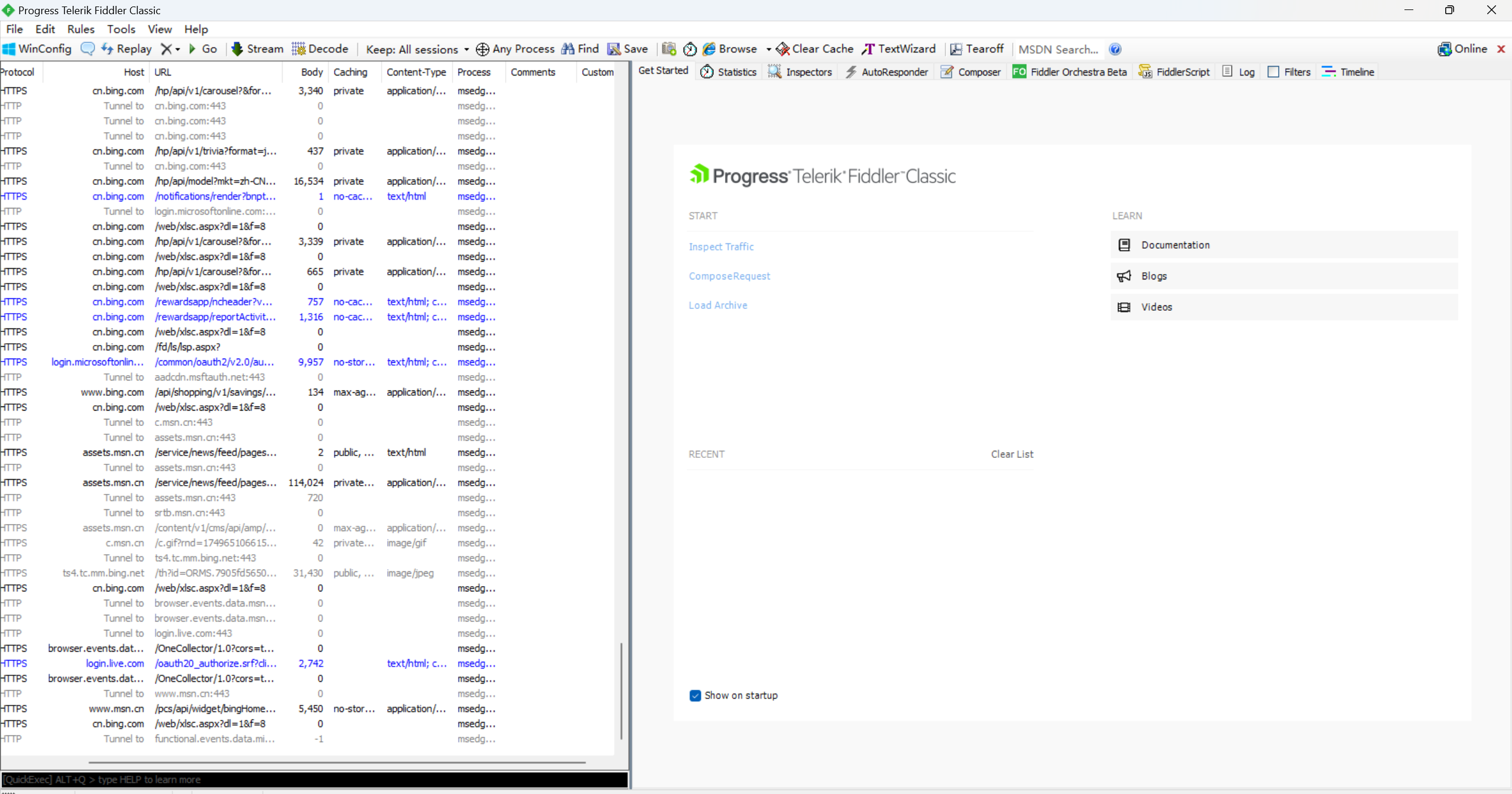
左侧窗口显示了所有的HTTP请求/响应,我们可以选中某个查看详细。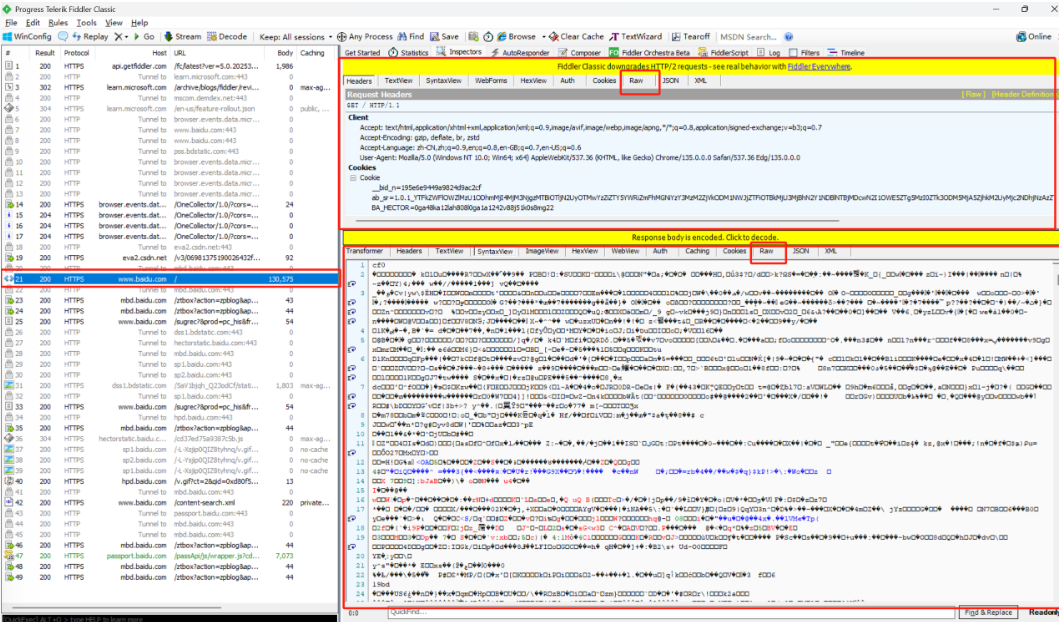 右侧上方是HTTP请求的报文内容(切换到Raw标签也可以看到详细的数据格式)
右侧上方是HTTP请求的报文内容(切换到Raw标签也可以看到详细的数据格式)
右侧下方是HTTP响应的报文内容(切换到Raw标签也可以看到详细的数据格式)
当我们需要详细查看请求和响应数据的时候,也可以通过View in Notepad来通过记事本打开。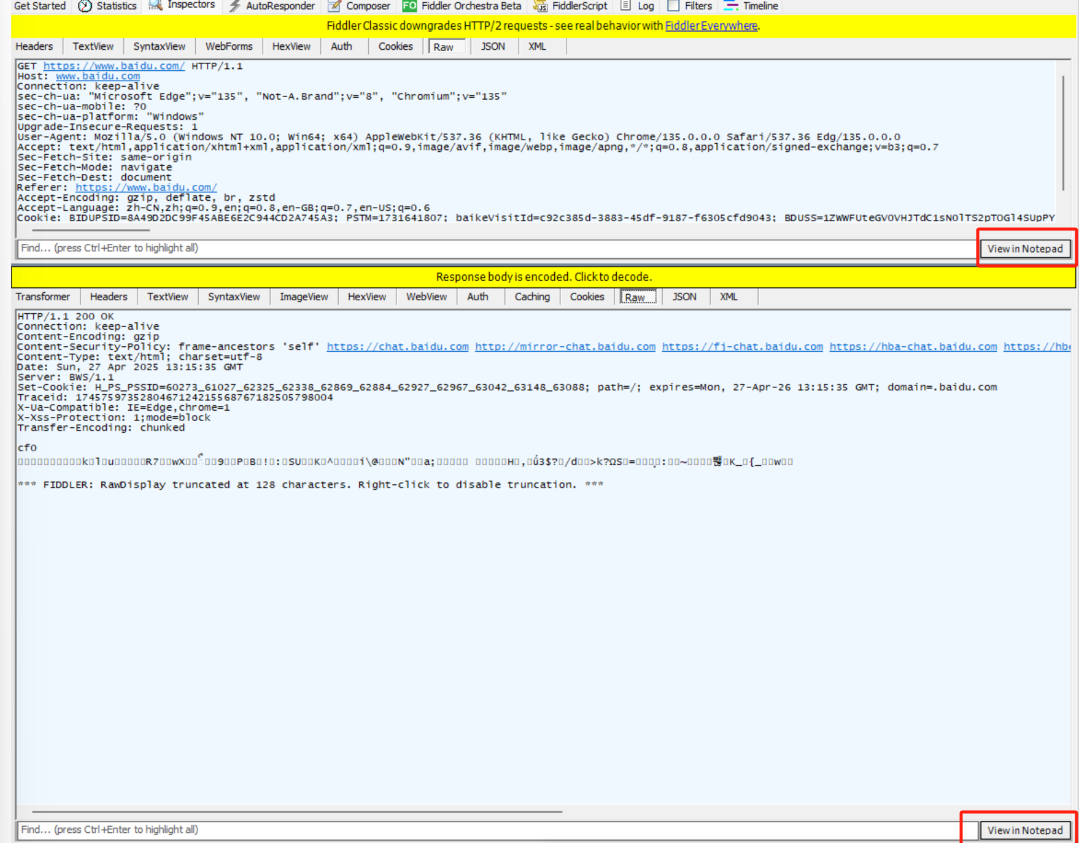
当我们想要重新抓包时,可以crtl+a全选左侧抓包结果,然后del清除所有被选中的结果。此时,我们系统上有任何一个程序(不一定是浏览器)此时使用了HTTP/HTTPS协议,此时,都能被fiddler给获取到。
打开一个网站的时候,其实浏览器和服务器之间进行的HTTP交互不是只有一次,而是通常有很多次,第一次交互是拿到这个页面的HTML,HTML还会依赖其它的CSS和JS图片等等,HTML被浏览器加载之后,又会触发一些其它的HTTP请求,获取到CSS、JS等等,当执行到JS的时候,JS里面的代码可能又要触发很多的HTTP请求。
字体为蓝色的表示返回的是一个HTML,往往是访问一个网站的入口请求,我们就以必应来看一下抓包的结果。
抓包结果
我们先将右侧HTTP请求的内容,在记事本打开,出现的是下面的结果。 但是,我们把下面的响应使用记事本打开的时候却发现是乱码:
但是,我们把下面的响应使用记事本打开的时候却发现是乱码: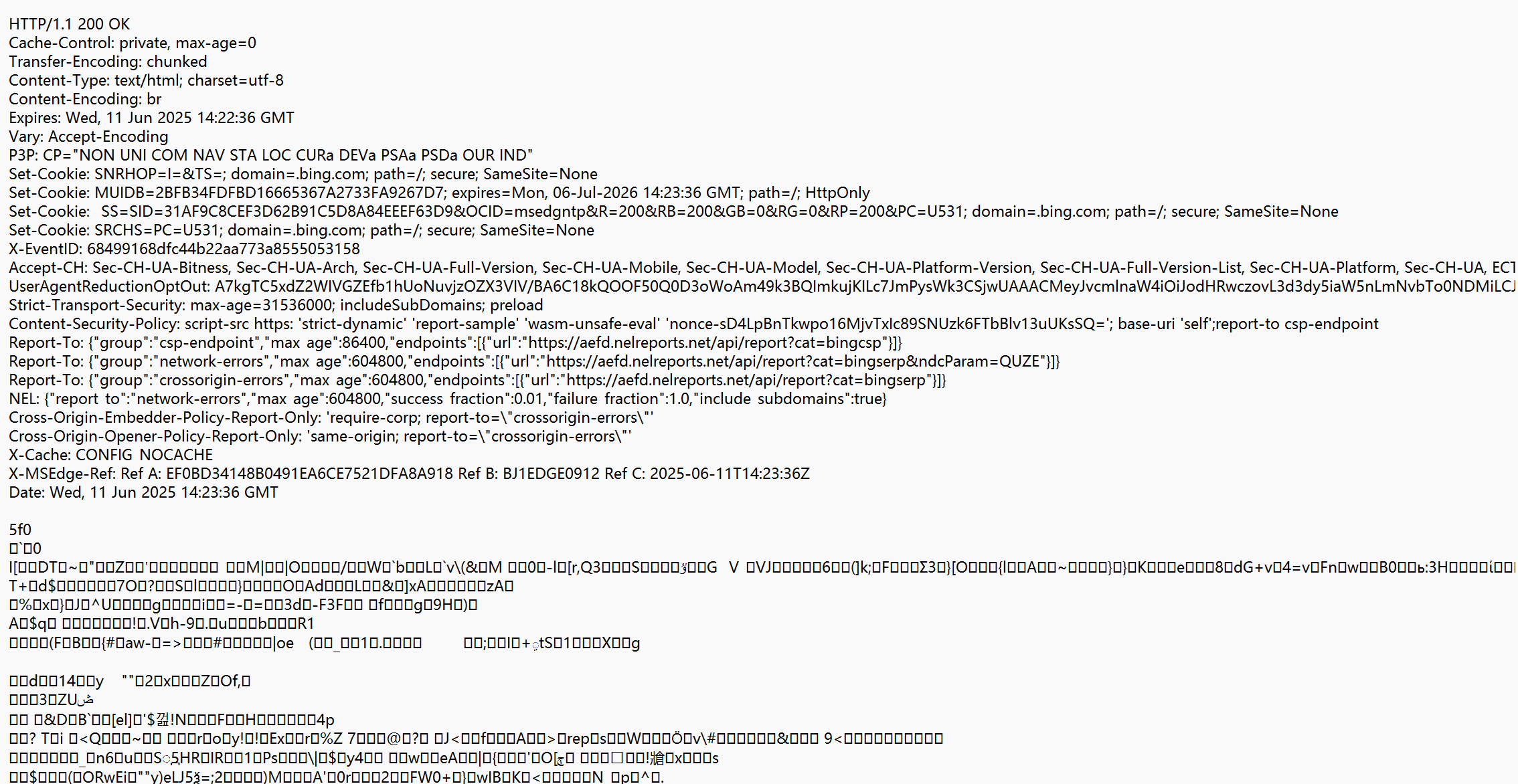
这个情况是因为当前响应的数据被进行压缩了。在网络传输中,宽带是一个比较贵的硬件资源,为了节省宽带,就可以把响应进行压缩(一般是对响应进行压缩,请求不太需要)。
我们可以点击下图中的这个按钮进行解压缩: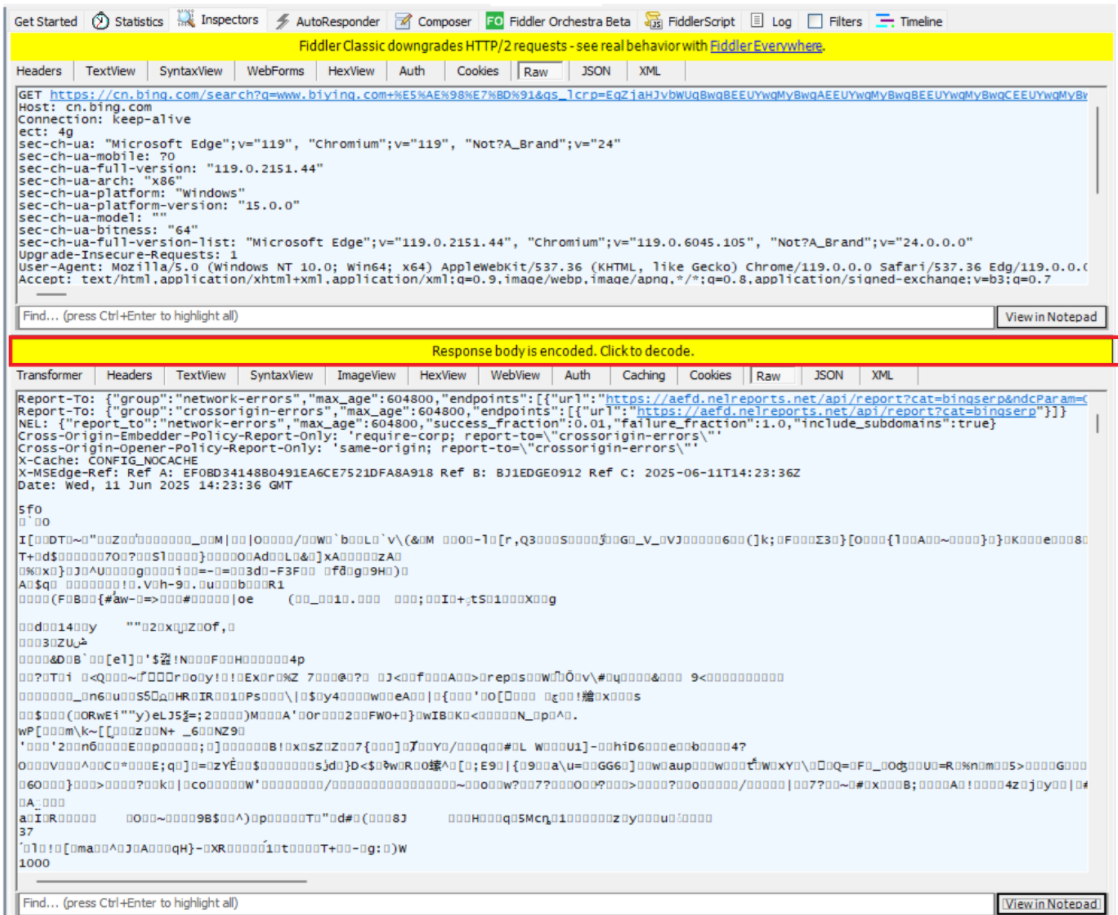 完成解压缩的结果:
完成解压缩的结果: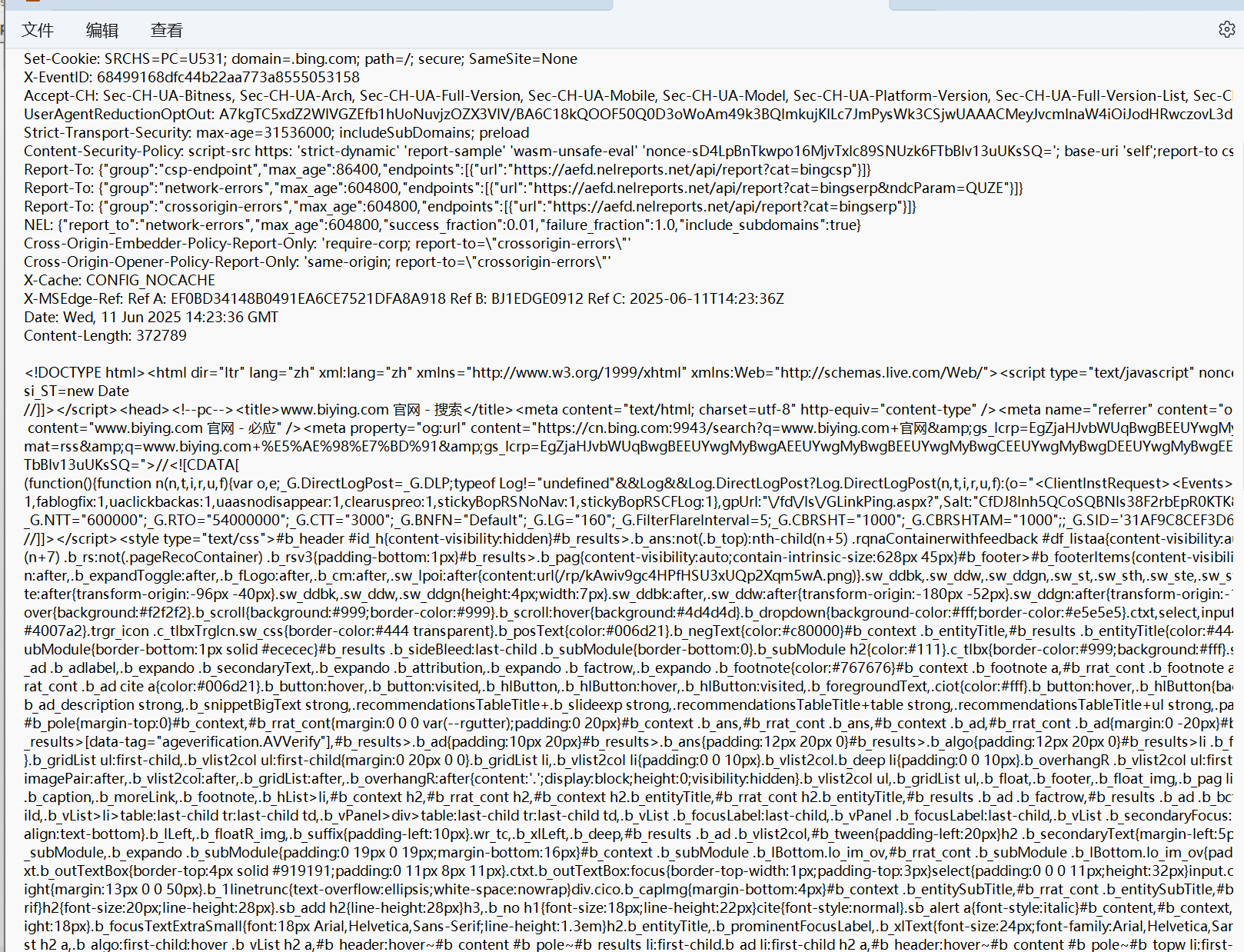
HTTP请求的基本格式
此处以必应的搜索页面为例子:
HTTP请求包含四部分:
1、首行 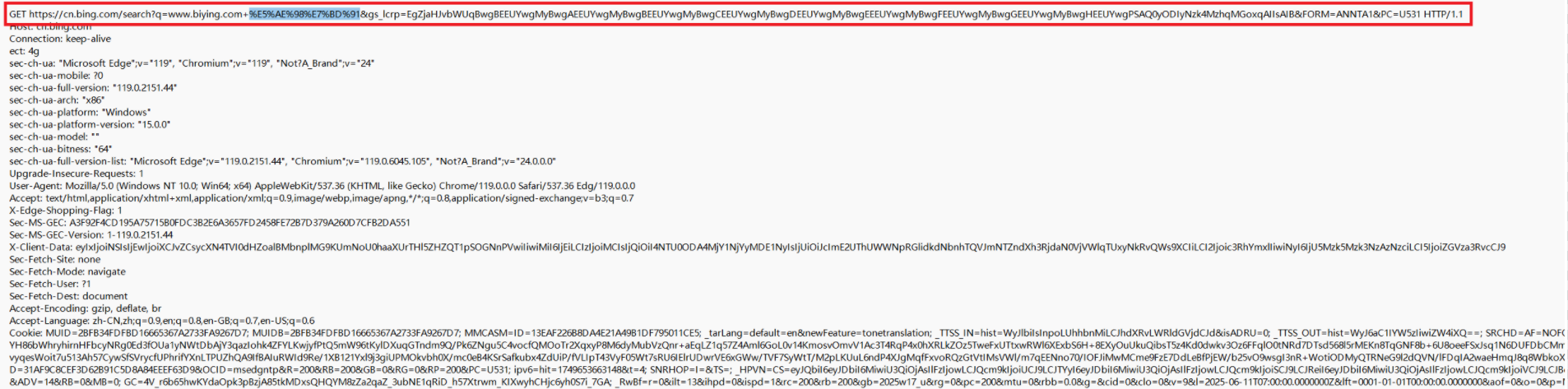
首行包含了3个部分:[方法]+[URL]+[HTTP版本号],三个部分使用空格进行分隔
GET为方法,https://www.bying.com/……为URL(由于我们当前必应的搜索页面存在着许多图片因此URL中的查询字符串很长,这个会在下篇URL介绍中讲到),HTTP/1.1位为本号。
2、请求头(Header)
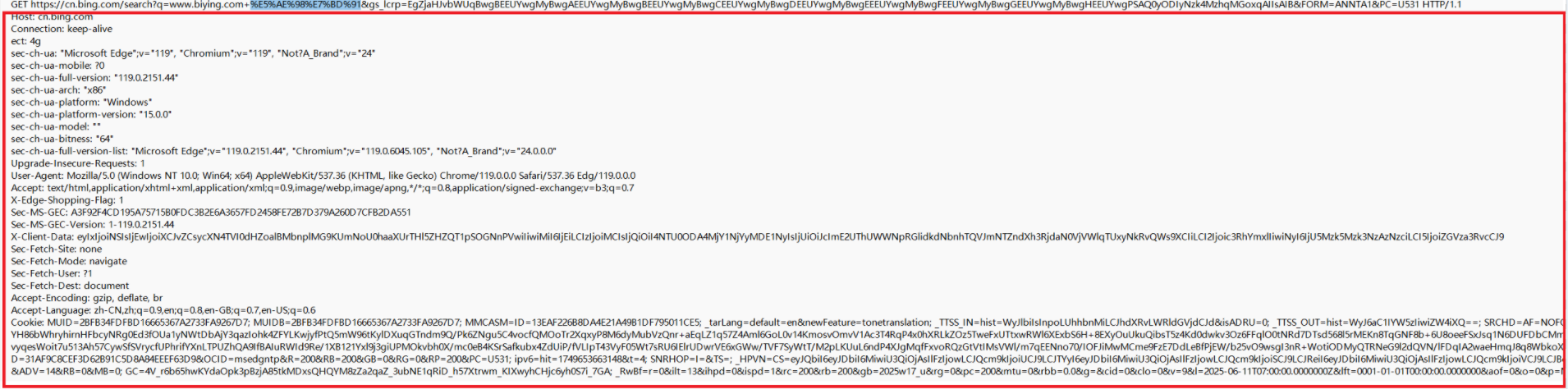
从第二行到最后都是请求头(当前请求没有正文)。里面是类似TCP报头/IP报头,包含一些重要的属性信息,以文本的方式进行组织。
请求头中包含了许多键值对,每个键值对占一行,键和值之间使用:+ 空格进行分隔。
此处的键值对都有哪些,有什么含义,都是HTTP协议所规定的。
3、空行
请求头下面会有一个空行表示请求头的结束标记。
4、正文(body)
HTTP的载荷部分。有的HTTP请求有body,有的没有body。
HTTP响应的基本格式
1、首行 
首行也是包含三个部分:[版本号]+[状态码]+[状态码描述],3个部分时间使用空格进行分割。
HTTP/1.1为版本号,200为状态码,OK为状态码描述。
2、响应头(Header)
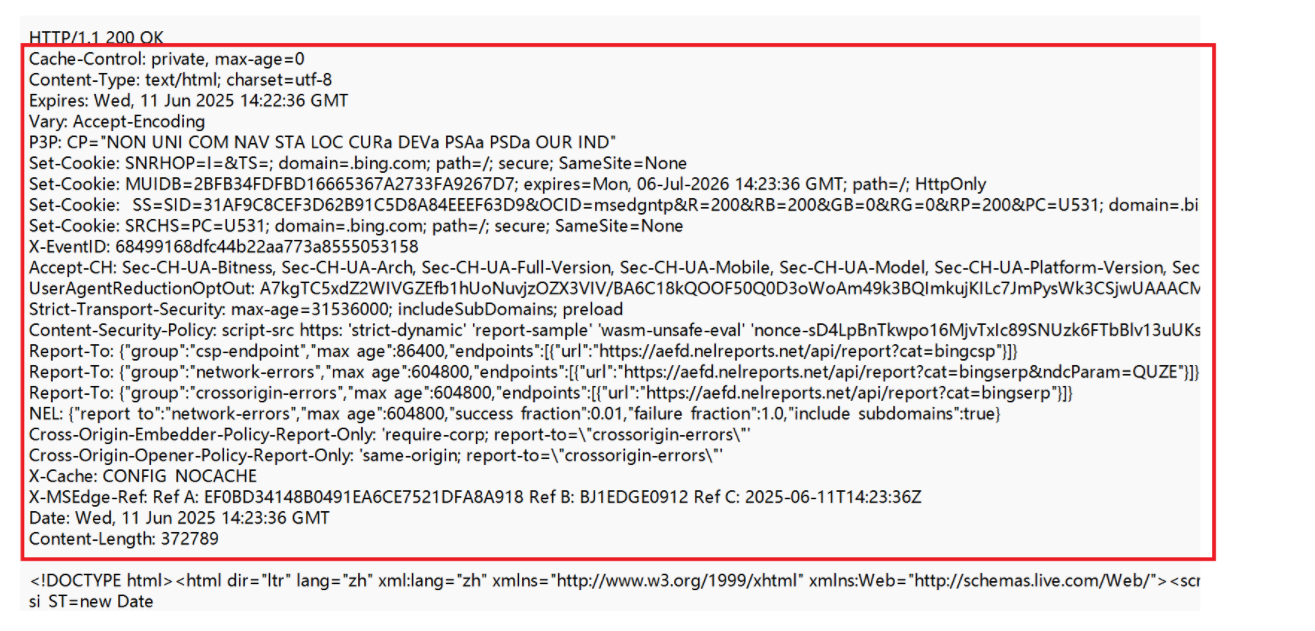
和请求头一样表示一些属性,用冒号分割键值对,魅族属性之间用\n进行分隔。
3、空行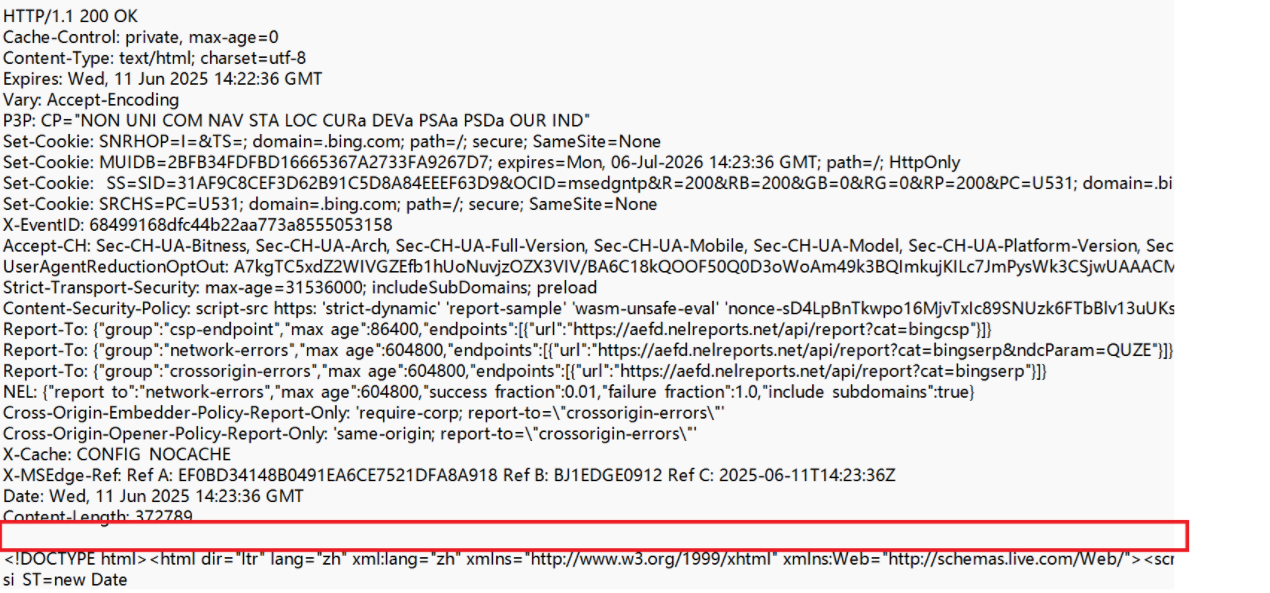
遇到空行则表示Header部分结束
4、正文(Body)
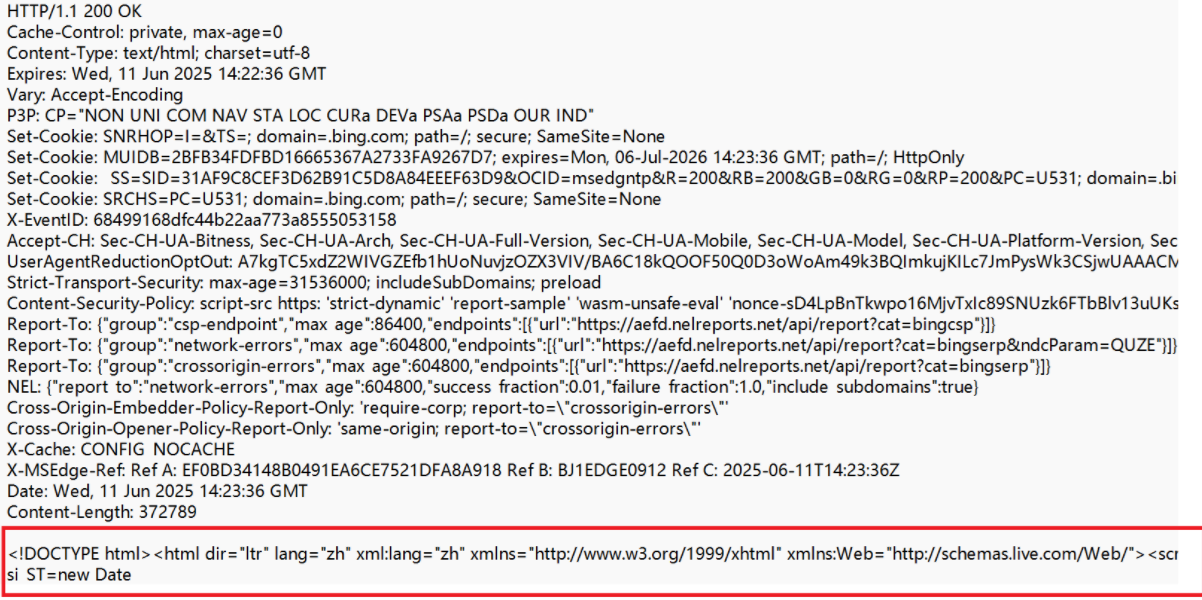 空行后面的内容都是Body,Body允许为空字符串。如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度,如果服务器返回了一个HTML页面,那么HTML页面内容就是在Body中。
空行后面的内容都是Body,Body允许为空字符串。如果Body存在,则在Header中会有一个Content-Length属性来标识Body的长度,如果服务器返回了一个HTML页面,那么HTML页面内容就是在Body中。
协议格式总结
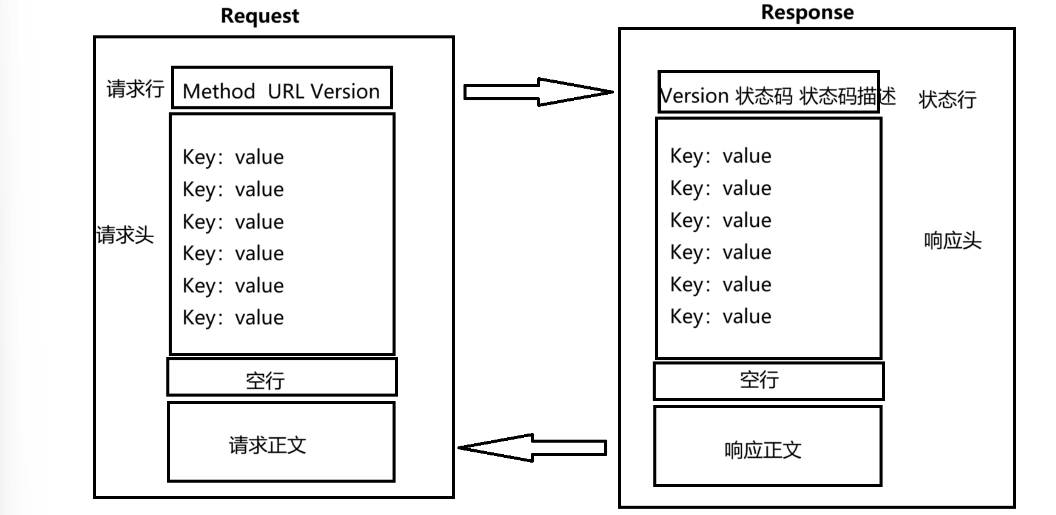
那为什么HTTP报文中要存在“空行”?
HTTP协议中,并没有具体规定报头部分的键值对有多少个,空行就相当于是“报头的结束标志”,或者说空行是“报头和正文之间的分隔符”。HTTP在传输层是依赖TCP协议的,TCP是面向字节流的,如果没有这个空行,就会出现“粘包问题”。