卡方检验(χ²检验)
卡方分布(Chi-Squared Distribution)
(1)专业解释
定义
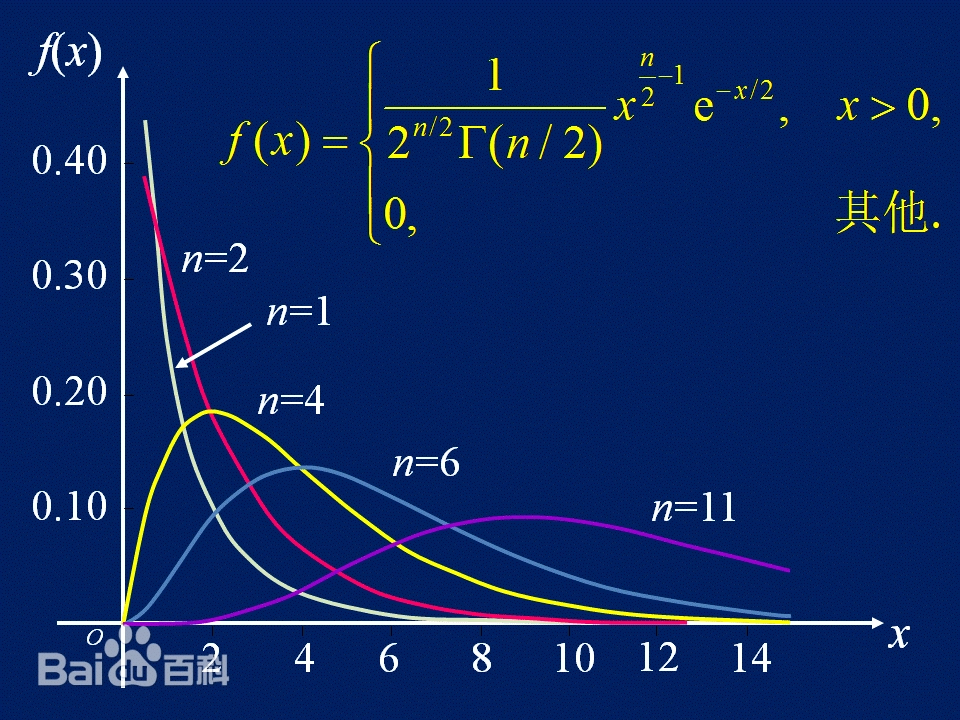
卡方分布(Chi-square distribution)是概率论和统计学中的一种连续概率分布,记作 χ 2 ( k ) \chi^2(k) χ2(k),其中 k k k 是自由度。
百度解释:
若n个相互独立的随机变量ξ₁,ξ₂,…,ξn ,均服从标准正态分布(也称独立同分布于标准正态分布),则这n个服从标准正态分布的随机变量的平方和构成一新的随机变量,其分布规律称为卡方分布(chi-square distribution)。卡方分布是一种常见的概率分布。
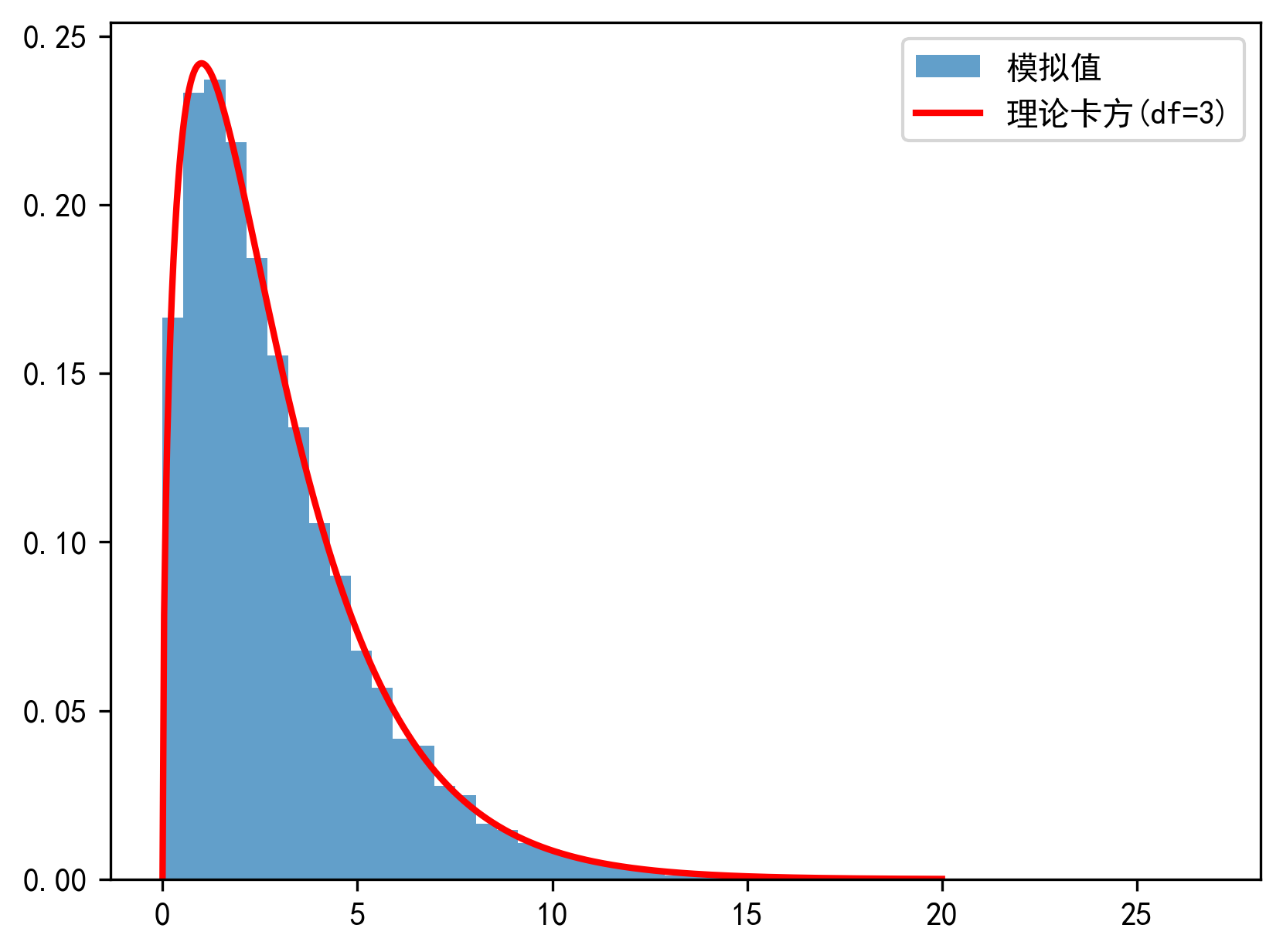
代码模拟
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import chi2
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置黑体作为默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示异常
# 设置随机种子保证可重复性
np.random.seed(42) # 模拟自由度为3的卡方分布
def simulate_chi_square(n_samples):z1 = np.random.randn(n_samples) # 1万个标准正态随机数z2 = np.random.randn(n_samples)z3 = np.random.randn(n_samples)return z1**2 + z2**2 + z3**2 # 平方和x_values = simulate_chi_square(10000)# 绘制直方图 vs 理论曲线
plt.hist(x_values, # 输入的模拟数据数组(1万个X值),包含1万个自由度为3的卡方分布随机数bins=50, # 将数据范围分成50个柱子density=True, # 归一化为概率密度(面积总和=1),每个柱子的高度 = 该区间样本数 / (总样本数 × 柱子宽度), 可直接与理论概率密度曲线比较alpha=0.7, # 设置透明度(0=全透明,1=不透明)label='模拟值' # 图例标签
)xx = np.linspace(0, 20, 500)# 生成X轴坐标点
plt.plot(xx, # X轴坐标chi2.pdf(xx, df=3), # Y轴:自由度为3的卡方分布概率密度'r-', # 红色实线样式lw=2, # 线宽为2label='理论卡方(df=3)' # 图例标签
)
plt.legend()
plt.savefig('plot.png', dpi=300, bbox_inches='tight')
plt.show()
数学表达
如果 Z 1 , Z 2 , … , Z k Z_1, Z_2, \ldots, Z_k Z1,Z2,…,Zk 是 k k k 个独立的标准正态随机变量(即 Z i ∼ N ( 0 , 1 ) Z_i \sim N(0,1) Zi∼N(0,1)),那么它们的平方和:
Q = Z 1 2 + Z 2 2 + ⋯ + Z k 2 Q = Z_1^2 + Z_2^2 + \cdots + Z_k^2 Q=Z12+Z22+⋯+Zk2
服从自由度为 k k k 的卡方分布,即 Q ∼ χ 2 ( k ) Q \sim \chi^2(k) Q∼χ2(k)。
概率密度函数
卡方分布的概率密度函数为:
f ( x ; k ) = 1 2 k / 2 Γ ( k / 2 ) x k / 2 − 1 e − x / 2 , x ≥ 0 f(x; k) = \frac{1}{2^{k/2}\Gamma(k/2)} x^{k/2-1} e^{-x/2}, \quad x \geq 0 f(x;k)=2k/2Γ(k/2)1xk/2−1e−x/2,x≥0
其中:
- k k k 是自由度参数
- Γ ( ⋅ ) \Gamma(\cdot) Γ(⋅) 是伽马函数
- x ≥ 0 x \geq 0 x≥0(卡方分布只取非负值)
重要性质
- 均值: E [ X ] = k E[X] = k E[X]=k
- 方差: V a r [ X ] = 2 k Var[X] = 2k Var[X]=2k
- 偏度: 8 / k \sqrt{8/k} 8/k
- 峰度: 12 / k 12/k 12/k
可加性
如果 X 1 ∼ χ 2 ( k 1 ) X_1 \sim \chi^2(k_1) X1∼χ2(k1) 和 X 2 ∼ χ 2 ( k 2 ) X_2 \sim \chi^2(k_2) X2∼χ2(k2) 且相互独立,则:
X 1 + X 2 ∼ χ 2 ( k 1 + k 2 ) X_1 + X_2 \sim \chi^2(k_1 + k_2) X1+X2∼χ2(k1+k2)
看不懂?
(2)费曼学习法解释
1、用简单的话说
想象这个场景:
第一次实验:
- 你有5个学生的标准化成绩:-1.2, 0.8, -0.5, 1.1, 0.3
- 平方后:1.44, 0.64, 0.25, 1.21, 0.09
- 求和:3.63(这是一个具体数字)
第二次实验:
- 又来了5个学生:0.7, -1.8, 0.2, -0.1, 1.4
- 平方后:0.49, 3.24, 0.04, 0.01, 1.96
- 求和:5.74(又是一个具体数字)
第三次、第四次…
如果你重复这个过程无数次,每次都:
- 随机抽取5个标准正态分布的数
- 平方
- 求和
你会得到无数个不同的和:3.63, 5.74, 2.18, 7.92, 1.45…,这些和的集合,它们的分布规律,就是卡方分布!
标准化就是把任何分布的数据转换成平均数为0,标准差为1的形式。

2、直观理解
-
为什么要平方?
- 平方消除了正负号,让所有数都变成正数
- 平方让极端值(很高或很低的分数)变得更加突出
-
自由度是什么?
- 就是你加了多少个平方数
- 如果你有5个独立的标准正态变量,自由度就是5
-
形状特点:
- 总是从0开始(因为平方数不能为负)
- 右偏分布(有长长的右尾巴)
- 随着自由度增加,分布越来越像正态分布
3、生活中的例子
想象你在测量一个圆桌的"不圆程度":
- 你在桌边随机选择几个点
- 测量每个点到理想圆心的偏差
- 把这些偏差平方后加起来
- 这个总偏差就大致服从卡方分布
(3)实际应用
1. 拟合优度检验
检验观察数据是否符合理论分布:
χ 2 = ∑ i = 1 k ( O i − E i ) 2 E i \chi^2 = \sum_{i=1}^{k} \frac{(O_i - E_i)^2}{E_i} χ2=i=1∑kEi(Oi−Ei)2
其中 O i O_i Oi 是观察频数, E i E_i Ei 是期望频数。
2. 独立性检验
检验两个分类变量是否独立,使用相同的公式结构。
3. 方差检验
检验样本方差是否等于某个假设值。
(4)与其他分布的关系
- 与正态分布:当自由度很大时, χ 2 ( k ) \chi^2(k) χ2(k) 近似正态分布 N ( k , 2 k ) N(k, 2k) N(k,2k)
- 与伽马分布: χ 2 ( k ) = Gamma ( k / 2 , 2 ) \chi^2(k) = \text{Gamma}(k/2, 2) χ2(k)=Gamma(k/2,2)
- 与t分布和F分布:都基于卡方分布构建
(5)总结
卡方分布本质上是"标准正态变量平方和"的分布。它在统计检验中极其重要,特别是用于检验数据的拟合程度和变量间的独立性。记住:平方让一切变正,求和让分布右偏,自由度决定分布形状!
自由度(degrees of freedom, df)
🌟 自由度 = 独立随机变量的个数 = 能自由变化的数据维度
以卡方分布为例,它的定义是:
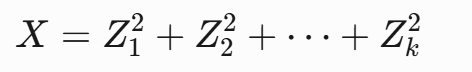
其中 Z i是独立的标准正态变量 → 自由度就是 k。
对比不同自由度的形态
x = np.linspace(0, 20, 500)
for df in [1, 3, 5, 10]:plt.plot(x, chi2.pdf(x, df), label=f'df={df}')
plt.legend()
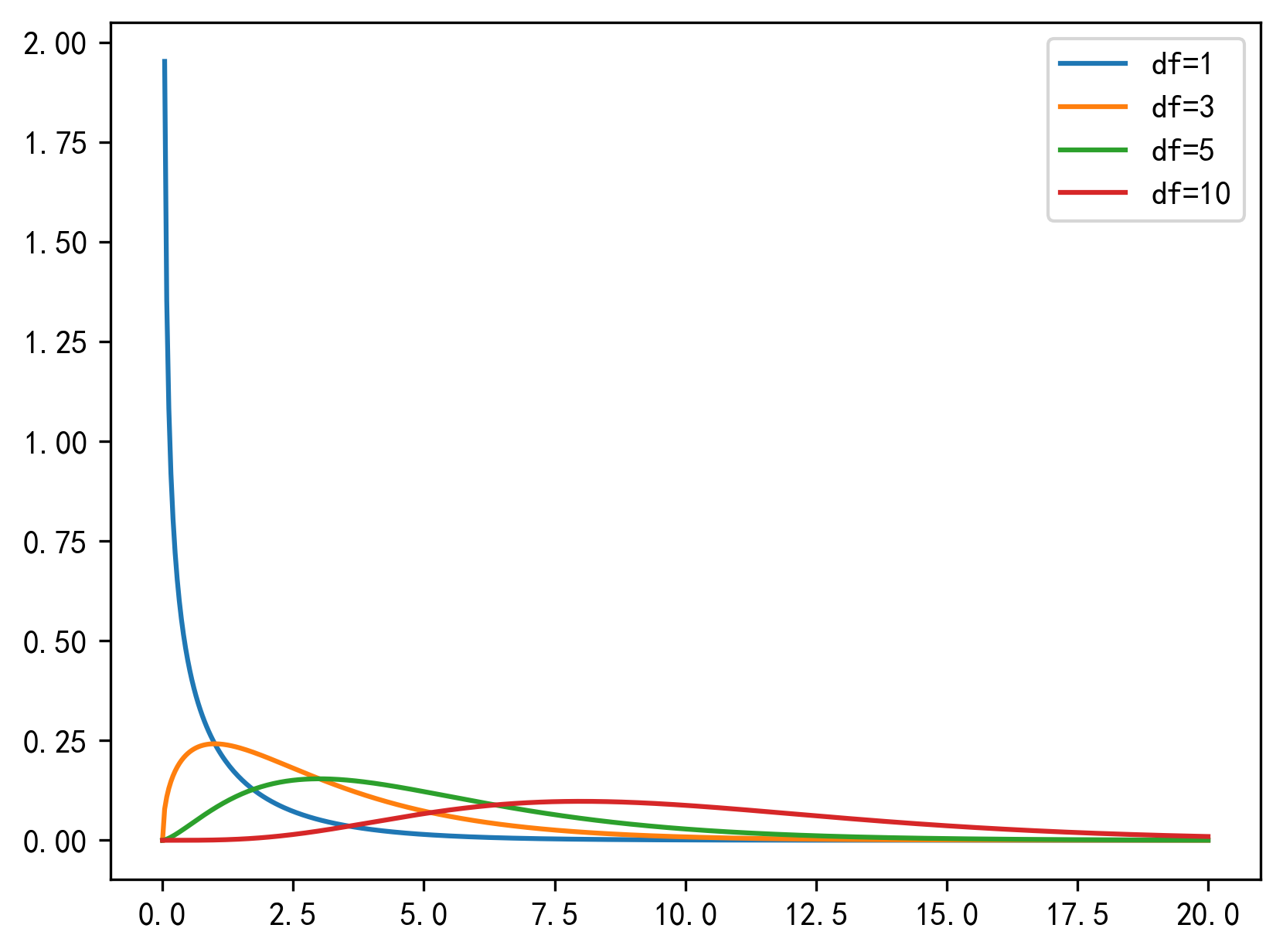
观察现象
- df=1:极右偏(因为单个Z²容易接近0)
- df增大:逐渐对称(中心极限定理作用)
- 自由度本质控制曲线的「形状参数」
物理实验理解
假设你有3个传感器测量同一物理量:
- 如果无约束:每个传感器可自由波动 → df=3
- 如果已知均值:只有2个传感器能自由变化 → df=2
- 这就是自由度的「信息约束」本质!
进一步理解
第一步:从「自由变量」角度理解
想象你在玩一个数字填空游戏:
场景1:给你3个空格 _ _ _,可以随便填数字 → 自由度=3
(比如填 5, 8, 2)
场景2:追加规则「三个数平均值必须是5」 → 自由度=2
此时如果你填 4 和 6,第三个数必须是 5(因为 (4+6+5)/3=5)
这就是自由度的本质:
👉 每增加一个约束条件,就减少一个自由变化的变量
第二步:用「传感器实验」具象化
回到3个温度传感器的例子:
无约束时:
传感器1测到 23℃
传感器2测到 25℃
传感器3测到 27℃
完全自由,自由度=3
已知均值25℃后:
如果传感器1测到 24℃,传感器2测到 26℃
那么传感器3必须测到 25℃(因为 (24+26+25)/3=25)
只有两个传感器能自由变化,自由度=2
第三步:数学视角验证
对于样本方差的计算:
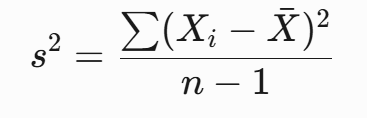
- 分母用 n-1 而不是 n,就是因为用样本均值X-估计真实均值时,消耗了1个自由度。
- 相当于只有 n-1 个数据可以自由变化
🎯 自由度的核心规律
| 场景 | 约束条件 | 自由度 |
|---|---|---|
| 单纯测量 | 数据 | 无 n |
| 计算样本方差 | 需用\bar{X} | n-1 |
| 线性回归 | 需估计斜率和截距 | n-2 |
下次遇到自由度时,问自己两个问题:
- 这个统计方法用到了哪些估计量?(如均值、方差)
- 每个估计量消耗了多少自由度?
举个例子:
- t检验:用样本均值 → 消耗1个自由度 → df=n-1 卡
- 方拟合优度检验:用样本比例 → 消耗1个自由度 → df=k-1
卡方检验(χ²检验)
卡方检验(χ²检验)是一种基于卡方分布的统计方法,主要用于分析分类变量之间的关联性或差异性。以下是其基础用法的核心要点:
1. 主要用途
- 拟合优度检验:检验样本分布是否符合理论分布(如掷骰子是否公平)。
- 独立性检验:判断两个分类变量是否独立(如吸烟与肺癌是否相关)。
- 同质性检验:比较多个组别的分布是否相同(如不同教育水平的投票倾向)。
2. 适用条件
- 数据类型:分类变量(频数数据)。
- 样本量要求:
- 每个单元格的期望频数 ≥5(若未满足,可合并类别或使用Fisher精确检验)。
- 总样本量一般建议 ≥30。
3. 基本步骤
- 建立假设:
- 原假设(H₀):变量间独立或无差异。
- 备择假设(H₁):变量间不独立或存在差异。
- 计算卡方统计量:
χ 2 = ∑ ( O i − E i ) 2 E i \chi^2 = \sum \frac{(O_i - E_i)^2}{E_i} χ2=∑Ei(Oi−Ei)2
- O i O_i Oi:观测频数
- E i E_i Ei :期望频数(基于H₀计算)。
- 确定临界值:
- 根据自由度(df)和显著性水平(如α=0.05)查卡方分布表。
- 独立性检验:df = (行数-1) × (列数-1)。
- 根据自由度(df)和显著性水平(如α=0.05)查卡方分布表。
- 做出决策:
- 若χ²统计量 > 临界值,拒绝H₀。
4. 实例演示
场景:检验性别(男/女)与是否喜欢某产品(是/否)是否独立。
| 喜欢 | 不喜欢 | 总计 | |
|---|---|---|---|
| 男 | 30 | 20 | 50 |
| 女 | 25 | 35 | 60 |
| 总计 | 55 | 55 | 110 |
- 期望频数计算(以“男性喜欢”为例):
[
E_{\text{男,喜欢}} = \frac{50 \times 55}{110} = 25
] - 卡方统计量:
[
\chi^2 = \frac{(30-25)^2}{25} + \frac{(20-25)^2}{25} + \frac{(25-30)^2}{30} + \frac{(35-30)^2}{30} \approx 3.33
] - 自由度:df = (2-1)(2-1) = 1,临界值(α=0.05)为3.84。
- 结论:3.33 < 3.84,不拒绝H₀,即性别与产品偏好无显著关联。
5. 注意事项
- 小样本修正:若存在期望频数 <5,可使用Yates连续性校正(仅2×2列联表)。
- 效应量补充:报告Phi系数、Cramer’s V等以衡量关联强度。
- 不适用于连续数据:若需检验连续变量,考虑分箱或改用其他方法。
6. 软件实现
- Python:
scipy.stats.chi2_contingency(observed_table) - R:
chisq.test(matrix) - Excel:
CHISQ.TEST(observed_range, expected_range)
通过以上步骤,可规范地完成卡方检验并解释结果。实际应用中需结合研究问题和数据特性选择合适的方法。
案例1:拟合优度检验(Goodness-of-Fit Test)
目的:检验样本数据是否符合某个理论分布(如均匀分布、正态分布、二项分布等)。
适用场景:
- 检验骰子是否公平(各面概率是否均为1/6)。
- 检验某地区出生性别比是否符合1:1。
- 检验某产品的销量是否符合预期的市场份额分布。
具体例子:检验骰子是否公平
假设:掷骰子60次,观察各面出现的次数,检验骰子是否均匀(各面概率=1/6)。
数据:
| 骰子面 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| 观测频数(O) | 8 | 12 | 9 | 11 | 10 | 10 |
步骤:
- 建立假设:
- H₀(原假设):骰子公平,各面概率=1/6。
- H₁(备择假设):骰子不公平,至少有一面概率≠1/6。
- 计算期望频数(E):
- 理论期望频数 = 总次数 × 理论概率 = 60 × (1/6) = 10(每面)。
- 计算卡方统计量:
[
\chi^2 = \sum \frac{(O_i - E_i)^2}{E_i} = \frac{(8-10)^2}{10} + \frac{(12-10)^2}{10} + \cdots + \frac{(10-10)^2}{10} = 1.0
] - 查卡方分布表:
- 自由度(df)= 类别数 - 1 = 6 - 1 = 5。
- 临界值(α=0.05)= 11.07。
- 结论:
- 1.0 < 11.07,不拒绝H₀,即骰子可能是公平的。
案例2:独立性检验(Test of Independence)
目的:判断两个分类变量是否独立(无关联)。
适用场景:
- 吸烟与肺癌是否相关?
- 性别与投票偏好是否有关?
- 教育水平与职业选择是否独立?
具体例子:检验吸烟与肺癌是否相关
数据(2×2列联表):
| 患肺癌 | 未患肺癌 | 总计 | |
|---|---|---|---|
| 吸烟 | 30 | 20 | 50 |
| 不吸烟 | 10 | 40 | 50 |
| 总计 | 40 | 60 | 100 |
步骤:
- 建立假设:
- H₀:吸烟与肺癌无关(独立)。
- H₁:吸烟与肺癌相关。
- 计算期望频数(E):
- 吸烟且患肺癌的期望频数 = (行总计 × 列总计) / 总样本量 = (50×40)/100 = 20。
- 其他单元格类似计算:
- 吸烟未患肺癌:50×60/100 = 30
- 不吸烟患肺癌:50×40/100 = 20
- 不吸烟未患肺癌:50×60/100 = 30
- 计算卡方统计量:
[
\chi^2 = \sum \frac{(O-E)^2}{E} = \frac{(30-20)^2}{20} + \frac{(20-30)^2}{30} + \frac{(10-20)^2}{20} + \frac{(40-30)^2}{30} \approx 16.67
] - 查卡方分布表:
- 自由度(df)= (行数-1) × (列数-1) = (2-1)(2-1) = 1。
- 临界值(α=0.05)= 3.84。
- 结论:
- 16.67 > 3.84,拒绝H₀,即吸烟与肺癌显著相关。
案例3:同质性检验(Test of Homogeneity)
目的:比较多个组别的分布是否相同(检验“比例”是否一致)。
适用场景:
- 不同教育水平(高中、本科、硕士)的投票倾向是否相同?
- 不同地区(A、B、C)的产品偏好是否一致?
具体例子:检验不同教育水平的投票倾向
数据(3×3列联表):
| 支持A党 | 支持B党 | 支持C党 | 总计 | |
|---|---|---|---|---|
| 高中 | 20 | 30 | 10 | 60 |
| 本科 | 25 | 35 | 20 | 80 |
| 硕士 | 15 | 25 | 20 | 60 |
| 总计 | 60 | 90 | 50 | 200 |
步骤:
- 建立假设:
- H₀:不同教育水平的投票倾向相同(分布同质)。
- H₁:至少有一个教育水平的投票倾向不同。
- 计算期望频数(E):
- 高中支持A党的期望频数 = (高中总计 × A党总计) / 总样本量 = 60×60/200 = 18。
- 其他单元格类似计算(如本科支持B党:80×90/200=36)。
- 计算卡方统计量:
[
\chi^2 = \sum \frac{(O-E)^2}{E} = \frac{(20-18)^2}{18} + \frac{(30-27)^2}{27} + \cdots + \frac{(20-15)^2}{15} \approx 6.25
] - 查卡方分布表:
- 自由度(df)= (行数-1) × (列数-1) = (3-1)(3-1) = 4。
- 临界值(α=0.05)= 9.49。
- 结论:
- 6.25 < 9.49,不拒绝H₀,即不同教育水平的投票倾向可能相同。
总结对比
| 检验类型 | 目的 | 数据格式 | 假设示例 |
|---|---|---|---|
| 拟合优度 | 样本是否符合理论分布? | 单变量频数 | 骰子是否公平? |
| 独立性检验 | 两个分类变量是否独立? | 列联表(R×C) | 吸烟与肺癌是否相关? |
| 同质性检验 | 多个组别的分布是否相同? | 列联表(组别×分类) | 不同教育水平的投票倾向是否一致? |
通过具体例子和计算步骤,可以更清晰地理解这三种卡方检验的区别和应用场景。