安全编程期末复习34(红色重点向下兼容)
目录
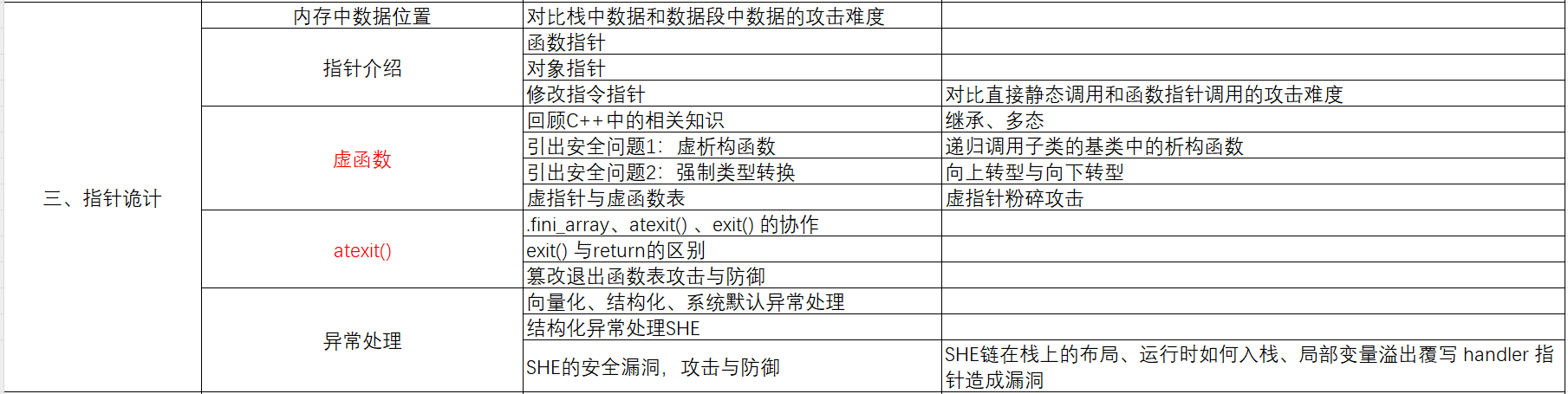
三、指针诡计
(1)内存中数据位置
对比栈中数据和数据段中数据的攻击难度
(2)指针介绍
函数指针
对象指针
修改指令指针
对比直接静态调用和函数指针调用的攻击难度
(3)虚函数
编辑
1.回顾 C++ 中的继承、多态
2.引出安全问题 1:虚析构函数(递归调用子类的基类中的析构函数)
3.引出安全问题 2:强制类型转换(向上转型与向下转型 )
4.虚指针与虚函数表(虚指针粉碎攻击的基础 )
(4)atexit()
.fini_array、atexit() 、exit() 的协作
编辑
exit() 与return的区别
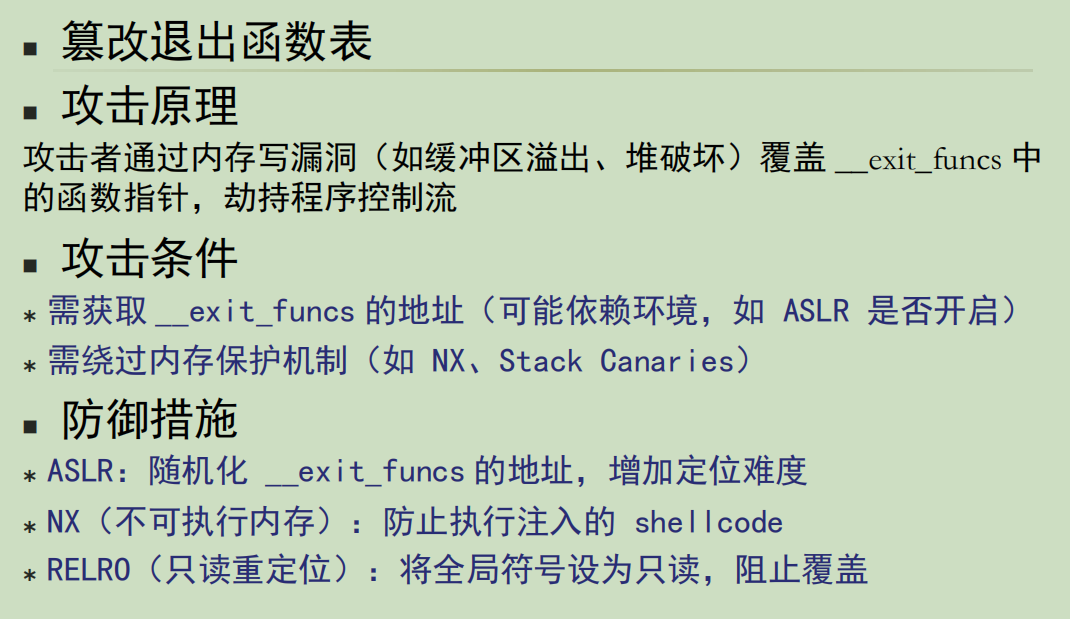
篡改退出函数表攻击与防御
(5)异常处理
向量化、结构化、系统默认异常处理
结构化异常处理SEH
SHE的安全漏洞,攻击与防御(SHE链在栈上的布局、运行时如何入栈、局部变量溢出覆写 handler 指针造成漏洞)
四、动态内存
(1)C内存管理的缺陷
1. 初始化缺陷
2. 未检查返回值
3. 无效指针解引用
4. 释放后访问
5. 双重释放
(2)C++内存管理(重点)
(3)C++内存管理的缺陷
一、内存分配失败检查
二、内存管理函数正确配对
三、多次释放内存
四、释放函数抛异常
(4)内存管理
unlink攻击
一、unlink 攻击的本质
二、如何绕过内存保护?
三、为什么难以检测?
(5)缓解策略
三、指针诡计
(1)内存中数据位置
对比栈中数据和数据段中数据的攻击难度

攻击难度综合对比
| 对比项 | 栈数据攻击 | 数据段数据攻击 |
|---|---|---|
| 防护机制复杂度 | 高(ASLR、Stack Canary、DEP) | 中(内存访问控制、只读保护) |
| 漏洞利用门槛 | 需精准控制内存地址和数据长度 | 需找到全局数据的修改入口 |
| 代码执行能力 | 可直接或间接执行代码(ROP) | 通常仅篡改数据,需结合其他攻击 |
| 现代系统下难度 | 高(防护机制完善) | 中(依赖特定漏洞场景) |
| 典型场景 | 缓冲区溢出漏洞利用 | 全局变量越界修改、常量篡改 |
一般来说,栈中数据的攻击难度相对较高
(2)指针介绍
函数指针
核心定义:函数指针是 指向函数入口地址的指针变量 ,可存储函数地址、动态调用函数,让程序能根据运行时状态决定执行哪个函数,实现 “行为动态化”。
// 定义函数指针类型:指向 “返回 int、参数为 int” 的函数
typedef int (*FuncPtr)(int); int add(int a) { return a + 5; } //add函数
int sub(int a) { return a - 5; } //sub函数int main() {FuncPtr ptr = add;// 函数指针指向 addprintf("%d\n", ptr(3));// 等价于 add(3),输出 8ptr = sub;// 函数指针切换到指向 subprintf("%d\n", ptr(3));// 等价于 sub(3),输出 -2
}
int (*FuncPtr)(int):
(*FuncPtr):这里的*表明FuncPtr是一个指针。
(int):意味着该指针所指向的函数带有一个int类型的参数。
int ...:说明这个函数的返回值类型为int。
对象指针
核心定义:对象指针是 指向对象(类实例)的指针 ,存储对象在内存中的起始地址,用于访问对象的成员(属性、方法),是面向对象编程(如 C++、Java)中操作对象的基础方式。
class Person {
public:int age;void show() { cout << "Age: " << age << endl; }
}; int main() {// 创建对象指针,指向堆上的 Person 对象Person* p = new Person(); p->age = 20; // 访问对象成员(属性)p->show(); // 访问对象成员(方法),输出 Age: 20delete p; // 释放对象return 0;
}
Person* p = ...:声明了一个名为
p的指针变量,其类型为Person*。把
new Person()返回的地址赋给指针p,这样p就指向了堆上的Person对象。
修改指令指针
本质:指令指针(比如 x86 架构里的
EIP/RIP寄存器 )存储的是 CPU 下一条要执行指令的内存地址。“修改指令指针” 就是通过代码(比如汇编指令、特殊的跳转 / 调用逻辑 )去改变这个地址,让程序流程跳转到其他位置执行。
对比直接静态调用和函数指针调用的攻击难度
| 对比维度 | 直接静态调用(如 func()) | 函数指针调用(如 ptr()) |
|---|---|---|
| 执行流确定性 | 编译时固定地址,执行流清晰可控 | 运行时动态决定目标地址,执行流灵活 |
| 攻击篡改点 | 需直接修改代码段(难度极高,代码段通常只读) | 篡改函数指针变量(栈 / 堆内存,相对容易) |
| 防护机制影响 | ASLR 对静态地址保护弱(代码段地址可预测) | ASLR 直接打乱指针指向,需额外信息泄露配合 |
| 典型攻击路径 | 需突破代码段只读保护(如内核漏洞提权) | 栈溢出 / 堆溢出篡改指针值,指向恶意代码 |
| 攻击难度总结 | 极高(修改只读内存 + 执行流固定) | 中等(篡改动态指针 + 依赖内存漏 |
直接静态调用攻击难度更高,因其编译时绑定函数地址,调用关系固定,需突破 ASLR、DEP 等系统防护及编译器保护(如 Canary)才能篡改;而函数指针调用为动态绑定,攻击者可通过修改指针指向的内存地址(如栈、数据段中的指针值)重定向调用目标,无需绕过代码段随机化保护,攻击难度相对较低。
(3)虚函数

1.回顾 C++ 中的继承、多态
继承:子类(派生类 )可以继承父类(基类 )的成员变量、成员函数,实现代码复用。比如
class Dog : public Animal,Dog能继承Animal的eat()、sleep()等函数。多态:核心靠虚函数实现,分为 静态多态(函数重载 ) 和 动态多态(运行时多态 ) 。动态多态的关键是:基类定义虚函数(加
virtual关键字 ),子类重写(override ) 该函数;程序运行时,通过基类指针 / 引用指向子类对象,调用虚函数时会动态绑定(根据对象实际类型,调用对应的子类实现 )。
//示例:
class Animal {
public:virtual void speak() { cout << "Animal speaks" << endl; }
};//Dog 类通过 public 继承 Animal 类,获得了 Animal 中 speak 虚函数等成员(继承父类属性、方法的能力 )
class Dog : public Animal {
public:void speak() override { cout << "Dog barks" << endl; }
};int main() {Animal *animal = new Dog(); animal->speak(); // 输出 Dog barks,动态多态体现delete animal;return 0;
}
继承:
Dog继承Animal类,复用父类结构并可扩展;多态:父类
Animal声明虚函数speak,子类Dog重写后,通过父类指针animal指向子类对象Dog,运行时自动调用Dog的speak,实现 “同一调用、不同行为” 的动态多态效果 。
2.引出安全问题 1:虚析构函数(递归调用子类的基类中的析构函数)
问题根源:如果基类析构函数不是虚函数,用基类指针
delete子类对象时,可能只调用基类析构,不调用子类析构 → 子类里动态分配的资源(如堆内存 )无法释放,导致内存泄漏。解决方法:基类把析构函数声明为
virtual(虚析构函数 )。这样,delete基类指针指向的子类对象时,会从子类析构开始,自动向上(基类 )递归调用析构 ,保证子类、基类资源都释放。
// 错误示例:基类无虚析构
class Base {
public:~Base() { cout << "Base destructor" << endl; }
};
class Derived : public Base {int *data;
public:Derived() : data(new int(10)) {}~Derived() { delete data; cout << "Derived destructor" << endl; }
};
// main 中:
Base *obj = new Derived();
delete obj;
// 输出:Base destructor → 子类Derived 的析构没被调用 → data 内存泄漏// 正确示例:基类加虚析构virtual
class Base {
public:virtual ~Base() { cout << "Base destructor" << endl; }
};
// delete obj 时,先调用子类Derived 析构(释放 data ),再调用父类Base 析构 → 无泄漏
虚析构函数(总结):
加 virtual 确保删除子类对象时,先调用子类析构、再调用父类析构
防止因父类指针指向子类对象,析构时漏掉子类资源释放(内存泄漏)
3.引出安全问题 2:强制类型转换(向上转型与向下转型 )
#include <iostream>//引入输入输出流库:用于使用 cout、endl 等输入输出相关功能
using namespace std; //使用 std 命名空间:避免重复写 std::(如 std::cout → cout)//定义抽象基类 Animal(动物)
class Animal {
public://纯虚函数:=0 表示无函数体,强制子类必须实现该接口//包含纯虚函数的类是「抽象类」,不能直接实例化对象//const 修饰:表明该成员函数不会修改对象的成员变量(只读)virtual int getAge() const = 0; //虚析构函数://加 virtual 确保删除子类对象时,先调用子类析构、再调用父类析构//防止因父类指针指向子类对象,析构时漏掉子类资源释放(内存泄漏)virtual ~Animal() {}
};//定义 Dog 类:公有继承 Animal,是 Animal 的具体子类
class Dog : public Animal {
private:int age;//私有成员:子类自身的数据(年龄)public://构造函数:初始化 age 成员//语法:构造函数名(参数) : 成员初始化列表(参数) {}Dog(int a) : age(a) {} //重写(override)父类的纯虚函数://必须和父类函数签名(返回值、参数、const)完全一致//实现后,Dog 类成为「具体类」,可实例化对象//多态的关键:父类指针/引用调用时,会自动调用子类重写的版本int getAge() const override { return age; }
};//定义打印年龄的函数:参数是 Animal 的 const 引用
//这里利用「多态」:传入子类对象(如 Dog)时,会调用子类的 getAge
void printAge(const Animal& animal) { //输出动物年龄:通过多态调用实际子类(如 Dog)的 getAgecout << "Age: " << animal.getAge() << endl; //类型安全:编译器保证 animal 是 Animal 或其子类Dog对象,调用接口安全
}//程序入口函数
int main() { Dog myDog(5);//创建 Dog 类对象myDog:传入年龄 5,调用 Dog(int a) 构造函数//调用 printAge 函数://myDog 是 Dog 类型,自动「向上转型」为 Animal&(父类引用)//触发多态:实际调用 Dog 的 getAge 函数//类型安全:编译器确保参数符合 Animal& 要求printAge(myDog); return 0; //程序正常结束
}一、什么是「向上转型」?
定义:
在继承体系中,将子类对象转换为父类类型(指针、引用或值)的过程,称为「向上转型」(Upcasting)。
本质:
子类对象 “is a” 父类对象(例如 Dog 是 Animal 的一种),因此可以被视为父类的实例。
代码示例中的向上转型:
printAge(myDog); // myDog 是 Dog 类型,传入 printAge(Animal&)这里发生了隐式向上转型:
myDog原本是Dog类型,但printAge的参数是const Animal&(父类引用)。编译器自动将
Dog对象转换为Animal&,使myDog可以被父类引用 “指向”。
向上转型(Upcasting ):子类对象隐式转换成基类类型(指针 / 引用 ),是安全的。因为子类 “is a” 基类(如 Dog 是 Animal ),转型后只能访问基类暴露的成员,不会越界。
示例:Animal *animal = new Dog();(天然支持,无需强制转换 )
向下转型(Downcasting ):基类指针 / 引用转换为子类类型,不安全 。因为基类指针可能实际指向基类对象,强行转成子类会访问子类独有的成员(基类对象内存里没有这些 ),导致未定义行为(程序崩溃、数据乱码等 )
| 转型方向 | 含义 | 安全性 | 实现方式 |
|---|---|---|---|
| 向上转型 | 子类 → 父类(指针 / 引用) | 安全(隐式转换即可) | 隐式转换(如 Animal* a = &dog;) |
| 向下转型 | 父类 → 子类(指针 / 引用) | 不安全(需手动检查) | dynamic_cast 或 static_cast |
4.虚指针与虚函数表(虚指针粉碎攻击的基础 )
- 虚函数表(vtable ):每个包含虚函数的类,编译器会生成一张 “虚函数表” ,存着该类所有虚函数的地址。子类重写虚函数时,会替换表中对应函数的地址。
- 虚指针(vptr ):每个对象(包含虚函数的类的实例 )里,编译器会隐式插入一个 “虚指针” ,指向所属类的虚函数表。程序运行时,通过
vptr找到vtable,再找到要调用的虚函数地址 → 实现动态多态。
class Animal {
public:virtual void speak() { ... }virtual void run() { ... }
};
// 编译器为 Animal 生成 vtable:[&Animal::speak, &Animal::run]class Dog : public Animal {
public:void speak() override { ... } // 重写 speak,vtable 中对应地址替换
};
// Dog 的 vtable:[&Dog::speak, &Animal::run]Animal *a = new Dog();
// a 的 vptr → Dog 的 vtable → 调用 speak 时找 Dog::speak 的地址
- 虚指针粉碎攻击:利用虚函数表、虚指针的内存布局,通过篡改
vptr或vtable内容 ,让程序调用恶意函数。比如:- 溢出漏洞覆盖对象的
vptr,使其指向攻击者构造的假vtable; - 假
vtable里存着恶意函数地址; - 后续调用虚函数时,程序会跳转到恶意函数执行,实现代码执行、提权等攻击。
- 溢出漏洞覆盖对象的
(4)atexit()

.fini_array、atexit() 、exit() 的协作

协作流程:程序退出时的执行顺序
当程序执行到
exit()(或main函数正常返回,底层也会触发exit()逻辑 ),会按以下步骤联动:步骤 1:
exit()启动退出流程调用
exit(status)后,glibc 会先处理 线程本地存储(TLS)的析构(比如线程相关资源释放 ),然后进入核心的 “退出处理” 环节:步骤 2:执行
atexit()注册的函数
exit()内部会遍历并逆序调用atexit()注册的函数(先进后出,类似栈 )。比如你多次调用atexit(handler1)、atexit(handler2),实际退出时会先执行handler2,再执行handler1,用于自定义资源清理(如关闭文件、释放堆内存 )。步骤 3:调用
.fini_array中的函数处理完
atexit注册的函数后,exit()会触发 动态库 / 程序自身的析构逻辑 ,也就是调用.fini_array段里存储的函数指针。这些函数通常由编译器自动插入(比如 C++ 全局对象的析构函数会被放到这 ),负责销毁全局对象、释放动态库占用的系统资源(如共享内存、文件描述符 )。步骤 4:最终调用
_exit()终止进程等
.fini_array里的函数执行完毕,exit()会调用 系统调用_exit(status),直接让进程终止,把退出状态status反馈给操作系统,至此程序彻底退出。
简单总结协作关系:
exit()是退出流程的 “总指挥”,触发后先执行atexit()注册的自定义清理,再执行.fini_array里的底层析构,最后用_exit()让进程消失,三者层层接力,保障程序退出时资源妥善收尾

// 定义一个全局的字符指针变量 glob,用于存储字符串的地址,初始未指向任何有效内容
char *glob; // 定义函数 test,无参数,返回值类型为 void(无返回值)
void test(void) { // 输出 glob 指针所指向的字符串内容,这里依赖 glob 指向有效字符串printf("%s", glob);
}// 程序入口函数 main,无参数,返回值类型为 int
int main(void) { // 调用 atexit 函数,注册 test 函数。atexit 的作用是:// 当 main 函数正常执行结束(return 退出或执行到末尾)时,会自动调用注册的 test 函数atexit(test); // 将字符串 "Exiting.\n" 的首地址赋值给全局指针 glob,使 glob 指向该字符串常量glob = "Exiting.\n"; // main 函数正常结束,此时会触发 atexit 注册的 test 函数执行return 0;
}补充说明代码执行流程和关键要点:
- 全局变量
glob:在整个程序运行期间都有效,test函数和main函数都能访问、修改它。这里main里给它赋值,test里用它打印内容。atexit函数作用:属于标准库函数(<stdlib.h>头文件,代码里没写,实际使用要包含),用来注册 “程序正常退出时要自动调用的函数” 。可以注册多个函数,按 注册顺序的逆序 执行(类似栈的 “后进先出”),这里只注册了test,所以程序退出时直接执行test。- 执行流程:
main里先注册test,再给glob赋值,然后main执行到return 0正常退出,触发atexit注册的test执行,test里通过glob打印出"Exiting.\n"。- 潜在问题:如果
main里没给glob赋值(比如注释掉glob = "Exiting.\n";),test执行时glob是野指针(未初始化指向有效内存),会导致未定义行为(程序可能崩溃、输出乱码等 )。
exit() 与return的区别

篡改退出函数表攻击与防御
(5)异常处理

向量化、结构化、系统默认异常处理

结构化异常处理SEH
一.SEH 基础概念
实现方式:
SEH 通过编译器支持的 try...catch...__finally 语法实现,用于处理函数或线程级别 的异常底层数据结构:
EXCEPTION_REGISTRATION 结构:每个线程维护一个异常处理链, 存储在栈中:struct _EXCEPTION_REGISTRATION {DWORD prev; // 指向前一个处理struct的指针(链式结构)DWORD handler; // 指向当前异常处理函数的指针 };二、SEH 工作流程(栈帧与异常处理)
栈帧初始化:编译器在函数开头生成代码,将异常处理结构压入栈,异常处理程序地址紧跟在局部变量之后,处于栈中较低地址
异常触发与处理:当异常发生时,系统从 fs:[0] 指向的链头开始遍历 SEH 链,逐个调用处理函数,直到某个函数处理异常
SHE的安全漏洞,攻击与防御(SHE链在栈上的布局、运行时如何入栈、局部变量溢出覆写 handler 指针造成漏洞)
三、SEH 安全漏洞(攻击核心考点)
栈溢出攻击
攻击原理:局部变量发生缓冲区溢出,覆盖相邻的 EXCEPTION_REGISTRATION 结构;修改 handler 指针为恶意代码地址,或伪造异常处理链
攻击步骤:
① 通过溢出覆盖 handler 字段为 Shellcode 地址
② 触发异常(除零、非法内存访问),系统调用被篡改的异常处理函数
③ 执行攻击代码(如提权、植入后门)四、防御措施
- 内存保护技术
- SEH 链/栈保护
- 代码加固
四、动态内存
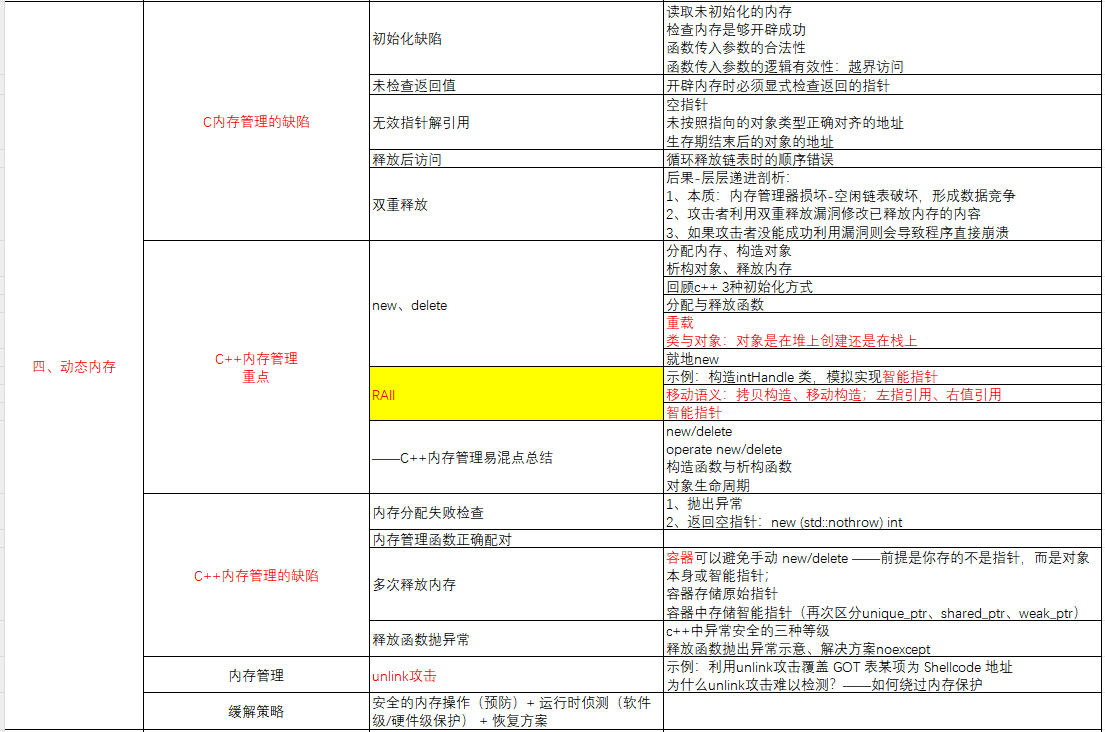
(1)C内存管理的缺陷

1. 初始化缺陷
- 问题本质:内存未正确初始化就使用,或参数校验缺失。
- 场景分类:
- 读取未初始化的内存:直接访问未赋值的栈变量、堆内存,导致数据随机(程序行为不可控,如计算结果错误 )。
- 检查内存是否开辟成功:用
malloc/new等分配内存后,未判断返回值是否为NULL,内存分配失败时后续操作会引发崩溃。 - 函数传入参数的合法性 / 逻辑有效性:函数入参未校验范围(如数组索引越界 ),可能破坏相邻内存、篡改关键数据,甚至引发代码执行流劫持(安全风险 )。
2. 未检查返回值
- 问题本质:内存分配(
malloc/new等 )、系统调用(如文件读写 )的返回值被忽略。 - 典型影响:假设内存分配失败却继续使用指针,会触发空指针解引用或无效内存操作,直接导致程序崩溃;系统调用失败时,后续依赖其结果的逻辑也会全盘出错。
- 所以,开辟内存时必须显式检查返回的指针
3. 无效指针解引用
- 问题本质:对无合法内存指向的指针操作(如
*p)。 - 场景分类:
- 空指针:指针未赋值(值为
NULL)就解引用,程序必崩溃。 - 未按照指向的对象类型正确对齐的地址:指针指向的地址不符合数据类型的内存对齐要求(如用
int*操作非 4 字节对齐地址 ),可能触发硬件异常(架构依赖 )、数据解析错误。 - 生存期结束后的对象的地址:访问已销毁对象的指针(如栈对象出作用域后仍用指针引用 ),会引发 “垂悬指针” 问题,破坏内存数据(覆盖其他变量 )。
- 空指针:指针未赋值(值为
4. 释放后访问
- 问题本质:内存释放(
free/delete)后,指针未置空且继续使用。 - 连锁反应:释放的内存可能被系统重新分配给其他变量,此时旧指针操作会篡改新数据(引发逻辑错误、数据混乱 );若涉及链表等结构,还可能因 “野指针” 破坏链表完整性(如循环释放顺序错误,导致链表节点重复释放或遗漏 )。
5. 双重释放
- 问题本质:同一内存被多次
free/delete,会破坏内存管理器的空闲链表结构(管理堆内存的核心机制 )。(本质:内存管理器损坏-空闲链表破坏,形成数据竞争) - 安全与运行影响:
- 攻击者利用双重释放漏洞修改已释放内存的内容
- 如果攻击者没能成功利用漏洞则会导致程序直接崩溃
(2)C++内存管理(重点)
(3)C++内存管理的缺陷

一、内存分配失败检查
C++ 里
new默认行为是 分配失败抛std::bad_alloc异常(需捕获处理,否则程序崩溃 );而new (std::nothrow)则会 返回空指针(需手动判空 )。示例对比:
// 方式1:抛异常 try {int* p = new int[10000000000]; // 分配失败时,抛出 std::bad_alloc 异常 } catch (const std::bad_alloc& e) {// 处理内存不足:如释放缓存、降级逻辑 }// 方式2:返回空指针(显式指定 nothrow) int* p = new (std::nothrow) int[10000000000]; if (p == nullptr) {// 手动处理分配失败 }二、内存管理函数正确配对
C++ 中
new/delete、new[]/delete[]需严格配对:
- 用
new分配单个对象,必须用delete释放;- 用
new[]分配数组,必须用delete[]释放。错误示例:
// 错误:new[] 配对 delete(未释放数组元素的析构函数) int* arr = new int[10]; delete arr; // 行为未定义!可能内存泄漏、析构不完整// 正确配对 delete[] arr;深层影响:
- 若类型是带析构函数的对象,错误配对会导致 析构函数不被调用(内存泄漏、资源未释放 );
- 极端情况触发 堆 corruption(破坏内存管理器的空闲链表 ),引发程序崩溃或安全漏洞。
三、多次释放内存
容器可以避免手动 new/delete ——前提是你存的不是指针,而是对象
1. 本身或只能指针
std::vector<int> objs; for (int i=0; i<5; i++) {objs.push_back(i); // 存对象,容器自动管理内存 } // 无需手动 delete,超出作用域自动析构、释放2. 容器存储原始指针
std::vector<int*> ptrs; for (int i=0; i<5; i++) {ptrs.push_back(new int(i)); } // 错误:手动释放后,容器内指针成“野指针” for (auto p : ptrs) {delete p; // 第一次释放 } // 再次操作野指针:UB!可能崩溃、篡改其他内存 for (auto p : ptrs) {*p = 100; // 二次释放/野指针访问,行为未定义 }3. 容器中存储智能指针
std::unique_ptr:独占所有权,容器内多个unique_ptr无法指向同一对象(避免重复释放 )。std::vector<std::unique_ptr<int>> ptrs; auto p = std::make_unique<int>(10); ptrs.push_back(std::move(p)); // p 已转移所有权,再次使用 p 会编译报错(避免重复释放)
std::shared_ptr:引用计数管理,引用计数归 0 时自动释放。auto sp = std::make_shared<int>(20); std::vector<std::shared_ptr<int>> ptrs; ptrs.push_back(sp); ptrs.push_back(sp); // 引用计数 +1 → 2 // 超出作用域时,引用计数归 0 才释放 → 不会重复释放
std::weak_ptr:不增加引用计数,需配合shared_ptr使用,本身不管理对象生命周期(无释放风险 )。四、释放函数抛异常
C++ 中,若
delete、析构函数等释放逻辑抛异常,可能导致 资源泄漏、异常传播失控(程序终止 )。异常安全(Exception Safety)的三个等级(从弱到强):
- 基本保证(Basic Guarantee):异常发生后,程序状态仍有效(但不一定是原状态 ),无资源泄漏。
- 强保证(Strong Guarantee):若操作抛异常,程序状态回退到操作前的状态(如事务回滚 )。
- 不抛异常保证(Noexcept Guarantee):操作保证不抛异常(用
noexcept修饰 )。问题示例(析构函数抛异常):
class Risky { public:~Risky() {throw std::runtime_error("析构抛异常!"); } };void func() {Risky obj; // 离开作用域时,析构抛异常 → 若未捕获,程序终止 }解决方案(用
noexcept限制):class Safe { public:~Safe() noexcept { // 显式声明不抛异常// 确保释放逻辑不会抛异常(如用错误码处理)} };关键思路:
释放操作(析构、
delete等 )应尽可能保证 不抛异常(用noexcept修饰 )。若必须处理异常,需在释放逻辑内部捕获,避免异常传播到外层引发程序崩溃或资源泄漏。
(4)内存管理

unlink攻击
一、unlink 攻击的本质
在 C 语言堆内存管理中,双向链表 是管理空闲块的核心结构(如
glibc的堆实现 )。当释放内存时,系统会通过unlink操作(本质是链表节点删除逻辑 ),将空闲块合并到链表中。简化的
unlink伪代码逻辑(早年堆实现)// 双向链表节点结构(简化) struct chunk {struct chunk *prev; // 前驱节点指针struct chunk *next; // 后继节点指针 };// unlink 操作:从链表中删除当前 chunk void unlink(struct chunk *victim) {struct chunk *prev = victim->prev;struct chunk *next = victim->next;prev->next = next; // 前驱节点的 next 指向后继节点next->prev = prev; // 后继节点的 prev 指向前驱节点 }攻击利用点:若攻击者能控制
victim的prev/next指针,就能通过unlink操作 篡改任意内存地址 。比如:
- 让
prev指向GOT表中某个函数的地址(如free函数的GOT项 ),让next指向Shellcode地址;- 执行
unlink时,prev->next = next会被解释为:*(GOT表地址) = Shellcode地址,直接覆盖函数跳转地址,实现 “劫持程序执行流”。二、如何绕过内存保护?
早年系统 / 编译器的 内存保护机制不完善,给
unlink攻击留了漏洞:
绕过栈不可执行(NX)
- 传统
NX(Non-Executable )保护禁止栈内存执行代码,但unlink攻击目标是 覆盖GOT表 / 函数指针,让程序跳转到堆区 / 数据区的Shellcode(若堆区可执行,或通过mprotect等函数修改内存权限,就能执行 )。绕过堆 cookie/Canary
- 堆
Cookie主要保护栈,而unlink攻击聚焦堆链表结构。只要控制chunk的prev/next指针,就能绕过堆 Cookie 直接篡改关键地址。绕过 ASLR(地址空间随机化)
- 早期 ASLR 对全局偏移表(
GOT)、库函数地址随机化不完全,攻击者可通过信息泄漏(如读取已知地址的内存 ),精准定位GOT表项,让unlink攻击的prev指针指向确定地址。三、为什么难以检测?
行为 “合法性” 混淆
unlink本身是 堆内存管理的正常操作(合并空闲块的必要逻辑 ),攻击利用的是 “指针被恶意控制” 的漏洞。检测工具很难区分:是正常内存管理的unlink,还是被篡改指针后的恶意unlink。内存操作的 “间接性”
攻击不直接修改GOT表,而是通过unlink的指针操作 间接覆盖。传统基于 “直接写GOT表” 的检测规则,无法识别这种 “绕路” 篡改。依赖旧版库 / 编译器漏洞
现代glibc已修复unlink逻辑(如引入safe_unlink,校验prev/next指针的合法性 ),但老旧系统 / 未及时更新的程序仍可能受攻击。检测工具需适配不同版本库的逻辑,增加了复杂度。
(5)缓解策略

- 释放内存后将指针置空
- 一致的内存管理约定
- 内存地址随机化
- phkmalloc
- OpenBSD
- 安全的内存管理器
- 静态分析、运行时检查工具