Loss Margin的原理与推导
为何要加入margin
在SVM时代,margin(间隔)被认为是泛化能力的保证。而在神经网络中最常使用的损失函数softmax交叉熵损失中并没有显式的引入间隔项。其中softmax损失函数推导过程中经过了一个smooth化,其可以在类间引入一定的间隔,但是这个间隔与特征幅度和最后一个内积层的权重幅度有关,这种间隔的大小主要是由网络自行调整的,并不是人为指定的。网络自行调整的间隔并不一定是最优的。实际上,为了减小损失函数的值,margin为0甚至margin为负才是神经网络自认为正确的优化方向。所以需要softmax loss的基础上人为的加入marign来拉大类间距离,保证“类间距离大于类内距离”,能够帮助模型学习到更加辨别的特征,同时加强模型的泛化能力。
推导过程:
优化目标:输出c个分数,使目标样本的分数比最大的非目标分数更大,对应的损失函数为:
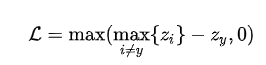
但是这样不仅难以优化,而且每次优化的分数过少,会使得网络收敛及其缓慢。下一步通过LogSumExp(max函数的smooth版本)取代max函数:
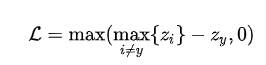
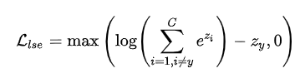
ReLU函数max(x,0)也有一个smooth版本,即softplus函数log(1+e^x), 继续替换之后得到:
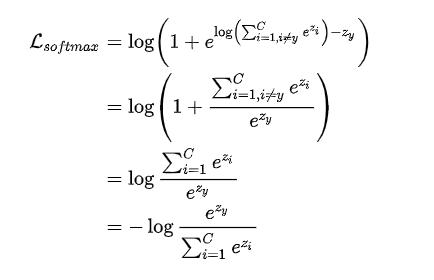
这就是大家所熟知的softmax交叉熵损失函数了,经过了两步的smooth化之后,就将一个难以收敛的函数逐步改造成为了softmax交叉熵损失函数,解决了原始的目标函数难以优化的问题。
但是只是这样会使得模型的泛化性能比较差(因为在训练集上让刚刚超过
就停止训练,测试集上很可能就不会超过),所以引入间隔m:
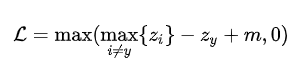
这个损失函数的含义是,使得目标分数比最大的非目标分数还要大m,从而提高模型的泛化性能。
但是这种smooth操作同时也带来了副作用:

也就是说 Softmax 交叉熵损失在输入的分数较小的情况下,并不能很好地近似目标函数。在使用 LSE(x) 对 max{z} 进行替换时, LSE(x) 将会远大于 max{z} ,不论 (目标函数)是不是最大的,都会产生巨大的损失。稍高的LSE(z)可以在类间引入一定的间隔,提升模型的泛化能力。但过大的间隔同样是不利于分类模型的,这样训练出来的模型必然结果不理想。
所以,z 的幅度既不能过大、也不能过小,过小会导致近对目标函数近似效果不佳的问题;过大则会使类间的间隔趋近于0,影响泛化性能。
所以控制z幅度的一种方法是将特征x和权重w全部归一化,这样就将z从特征与权重的内积变成了特征与权重的余弦,余弦的范围是[-1,1],所以z的幅度就大致定下来了。再通过一个尺度因子来拉长z的幅度,保证输入到softmax中的分数在一个合适的范围,这样通过控制z的取值范围同时也能够方便设置参数m(防止z过大使得m无法起到作用):
简单总结来说就是:将输入值控制到一个给定范围内,保证margin的数值和输入值的大小可比。
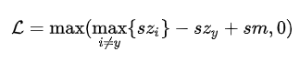
接下来同样通过smooth技巧,将损失函数转化为:
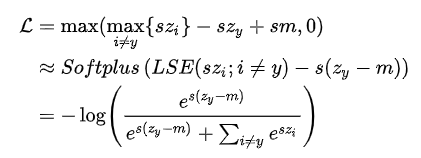 ‘
‘
其中m越大,就会强行要求目标样本与非目标样本分数拉开更大的差距。