pytorch-frame开源程序适用于 PyTorch 的表格深度学习库,一个模块化深度学习框架,用于在异构表格数据上构建神经网络模型。
一、软件介绍
文末提供程序和源码下载
pytorch-frame开源程序适用于 PyTorch 的表格深度学习库,一个模块化深度学习框架,用于在异构表格数据上构建神经网络模型。
PyTorch Frame 是 PyTorch 的深度学习扩展,专为具有不同列类型(包括数字、分类、时间、文本和图像)的异构表格数据而设计。它为实现现有和未来的方法提供了一个模块化框架。该库包含来自最先进模型、用户友好的小批量加载器、基准测试数据集和自定义数据集成接口的方法。
二、Library Highlights 库亮点
PyTorch Frame builds directly upon PyTorch, ensuring a smooth transition for existing PyTorch users. Key features include:
PyTorch Frame 直接基于 PyTorch 构建,确保现有 PyTorch 用户能够顺利过渡。主要功能包括:
- Diverse column types: PyTorch Frame supports learning across various column types:
numerical,categorical,multicategorical,text_embedded,text_tokenized,timestamp,image_embedded, andembedding. See here for the detailed tutorial.
多种列类型:PyTorch Frame 支持跨各种列类型学习:numerical、categoricalmulticategoricaltext_embeddedtext_tokenizedtimestampimage_embeddedembedding和 。有关详细教程,请参阅此处。 - Modular model design: Enables modular deep learning model implementations, promoting reusability, clear coding, and experimentation flexibility. Further details in the architecture overview.
模块化模型设计:支持模块化深度学习模型实施,促进可重用性、清晰的编码和实验灵活性。有关更多详细信息,请参阅 体系结构概述. - Models Implements many state-of-the-art deep tabular models as well as strong GBDTs (XGBoost, CatBoost, and LightGBM) with hyper-parameter tuning.
模型 实现许多最先进的深度表格模型以及具有超参数优化的强大 GBDT(XGBoost、CatBoost 和 LightGBM)。 - Datasets: Comes with a collection of readily-usable tabular datasets. Also supports custom datasets to solve your own problem. We benchmark deep tabular models against GBDTs.
数据集:附带一组易于使用的表格数据集。还支持自定义数据集来解决您自己的问题。我们将深度表格模型与 GBDT 进行基准测试。 - PyTorch integration: Integrates effortlessly with other PyTorch libraries, facilitating end-to-end training of PyTorch Frame with downstream PyTorch models. For example, by integrating with PyG, a PyTorch library for GNNs, we can perform deep learning over relational databases. Learn more in RelBench and example code.
PyTorch 集成:轻松与其他 PyTorch 库集成,促进 PyTorch Frame 与下游 PyTorch 模型的端到端训练。例如,通过与 PyG(一个用于 GNN 的 PyTorch 库)集成,我们可以对关系数据库执行深度学习。在 RelBench 和示例代码中了解更多信息。
三、Architecture Overview 架构概述
Models in PyTorch Frame follow a modular design of FeatureEncoder, TableConv, and Decoder, as shown in the figure below:
PyTorch Frame 中的模型遵循 FeatureEncoder 、 、 TableConv 和 Decoder 的模块化设计,如下图所示:
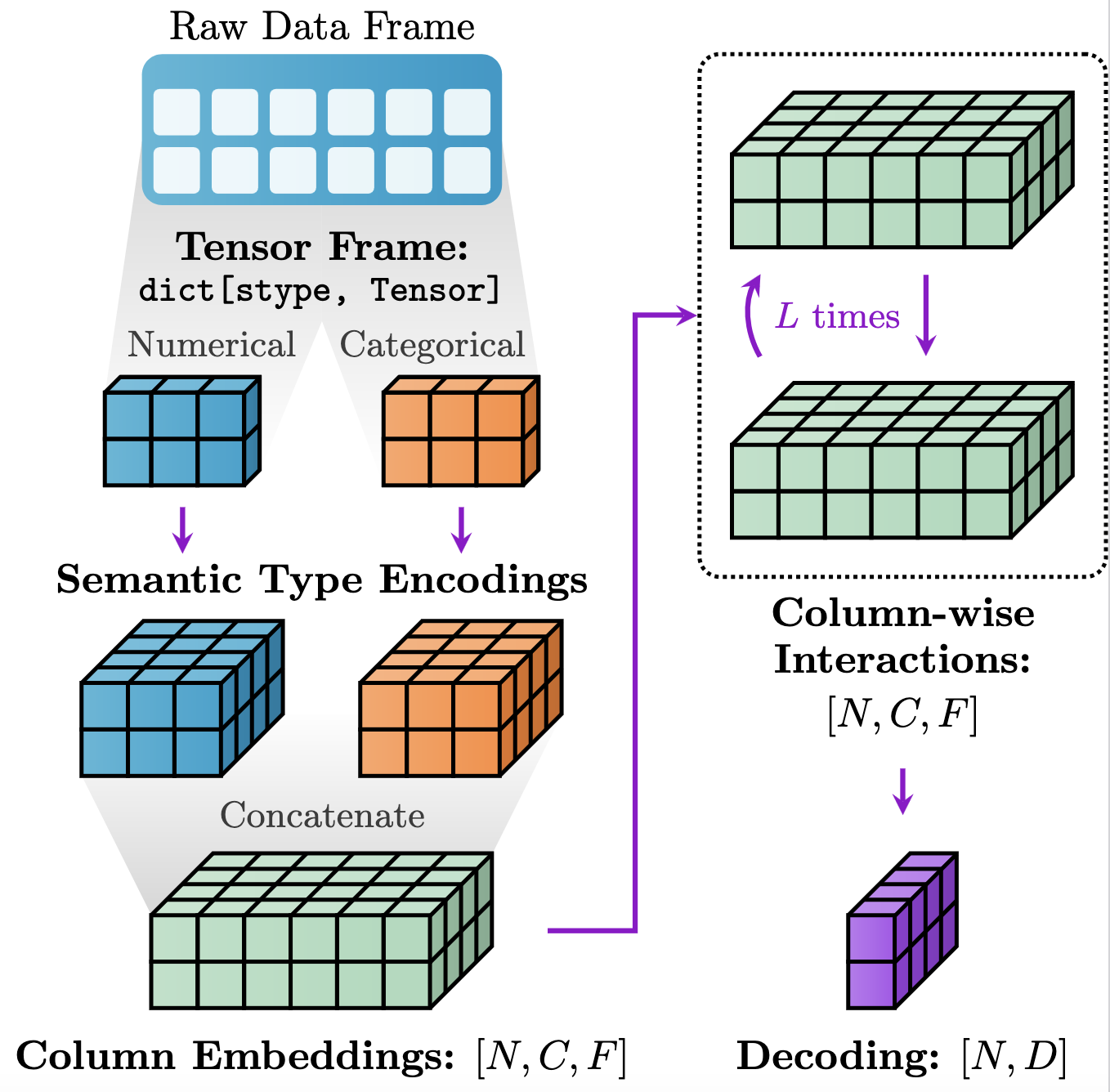
In essence, this modular setup empowers users to effortlessly experiment with myriad architectures:
从本质上讲,这种模块化设置使用户能够毫不费力地尝试各种架构:
Materializationhandles converting the raw pandasDataFrameinto aTensorFramethat is amenable to Pytorch-based training and modeling.
Materialization处理将原始 pandas 转换为TensorFrame适合基于 Pytorch 的训练和建模的 pandasDataFrame。FeatureEncoderencodesTensorFrameinto hidden column embeddings of size[batch_size, num_cols, channels].
FeatureEncoder编码TensorFrame为 size[batch_size, num_cols, channels]的隐藏列嵌入向量。TableConvmodels column-wise interactions over the hidden embeddings.
TableConv对隐藏嵌入的逐列交互进行建模。Decodergenerates embedding/prediction per row.
Decoder每行生成嵌入/预测。
四、Quick Tour 快速浏览
In this quick tour, we showcase the ease of creating and training a deep tabular model with only a few lines of code.
在这个快速导览中,我们展示了仅使用几行代码创建和训练深度表格模型的便利性。
Build and train your own deep tabular model
构建和训练您自己的深度表格模型
As an example, we implement a simple ExampleTransformer following the modular architecture of Pytorch Frame. In the example below:
例如,我们按照 Pytorch Frame 的模块化架构实现了一个简单的 ExampleTransformer 。在下面的示例中:
self.encodermaps an inputTensorFrameto an embedding of size[batch_size, num_cols, channels].
self.encoder将 inputTensorFrame映射到 size[batch_size, num_cols, channels]的嵌入向量。self.convsiteratively transforms the embedding of size[batch_size, num_cols, channels]into an embedding of the same size.
self.convs迭代地将 size[batch_size, num_cols, channels]的嵌入转换为相同大小的嵌入。self.decoderpools the embedding of size[batch_size, num_cols, channels]into[batch_size, out_channels].
self.decoder将 size[batch_size, num_cols, channels]的嵌入池化到[batch_size, out_channels]中。
from torch import Tensor
from torch.nn import Linear, Module, ModuleListfrom torch_frame import TensorFrame, stype
from torch_frame.nn.conv import TabTransformerConv
from torch_frame.nn.encoder import (EmbeddingEncoder,LinearEncoder,StypeWiseFeatureEncoder,
)class ExampleTransformer(Module):def __init__(self,channels, out_channels, num_layers, num_heads,col_stats, col_names_dict,):super().__init__()self.encoder = StypeWiseFeatureEncoder(out_channels=channels,col_stats=col_stats,col_names_dict=col_names_dict,stype_encoder_dict={stype.categorical: EmbeddingEncoder(),stype.numerical: LinearEncoder()},)self.convs = ModuleList([TabTransformerConv(channels=channels,num_heads=num_heads,) for _ in range(num_layers)])self.decoder = Linear(channels, out_channels)def forward(self, tf: TensorFrame) -> Tensor:x, _ = self.encoder(tf)for conv in self.convs:x = conv(x)out = self.decoder(x.mean(dim=1))return out
To prepare the data, we can quickly instantiate a pre-defined dataset and create a PyTorch-compatible data loader as follows:
为了准备数据,我们可以快速实例化预定义的数据集并创建与 PyTorch 兼容的数据加载器,如下所示:
from torch_frame.datasets import Yandex
from torch_frame.data import DataLoaderdataset = Yandex(root='/tmp/adult', name='adult')
dataset.materialize()
train_dataset = dataset[:0.8]
train_loader = DataLoader(train_dataset.tensor_frame, batch_size=128,shuffle=True)
Then, we just follow the standard PyTorch training procedure to optimize the model parameters. That's it!
然后,我们只需按照标准的 PyTorch 训练过程来优化模型参数。就是这样!
import torch
import torch.nn.functional as Fdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ExampleTransformer(channels=32,out_channels=dataset.num_classes,num_layers=2,num_heads=8,col_stats=train_dataset.col_stats,col_names_dict=train_dataset.tensor_frame.col_names_dict,
).to(device)optimizer = torch.optim.Adam(model.parameters())for epoch in range(50):for tf in train_loader:tf = tf.to(device)pred = model.forward(tf)loss = F.cross_entropy(pred, tf.y)optimizer.zero_grad()loss.backward()
五、Implemented Deep Tabular Models实现的深度表格模型
We list currently supported deep tabular models:
我们列出了当前支持的深度表格模型:
- Trompt from Chen et al.: Trompt: Towards a Better Deep Neural Network for Tabular Data (ICML 2023) [Example]
Chen 等人的 Trompt:Trompt:为表格数据提供更好的深度神经网络 (ICML 2023) [示例] - FTTransformer from Gorishniy et al.: Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) [Example]
来自 Gorishniy 等人的 FTTransformer:重新审视表格数据的深度学习模型 (NeurIPS 2021) [示例] - ResNet from Gorishniy et al.: Revisiting Deep Learning Models for Tabular Data (NeurIPS 2021) [Example]
Gorishniy 等人的 ResNet:重新审视表格数据的深度学习模型 (NeurIPS 2021) [示例] - TabNet from Arık et al.: TabNet: Attentive Interpretable Tabular Learning (AAAI 2021) [Example]
来自 Arık 等人的 TabNet:TabNet:专注可解释表格学习 (AAAI 2021) [示例] - ExcelFormer from Chen et al.: ExcelFormer: A Neural Network Surpassing GBDTs on Tabular Data [Example]
来自 Chen 等人的 ExcelFormer:ExcelFormer:在表格数据上超越 GBDT 的神经网络 [示例] - TabTransformer from Huang et al.: TabTransformer: Tabular Data Modeling Using Contextual Embeddings [Example]
来自 Huang 等人的 TabTransformer:TabTransformer:使用上下文嵌入的表格数据建模 [示例]
In addition, we implemented XGBoost, CatBoost, and LightGBM examples with hyperparameter-tuning using Optuna for users who'd like to compare their model performance with GBDTs.
此外,我们还使用 Optuna 为 XGBoost CatBoost LightGBM 希望将其模型性能与 GBDTs .
Benchmark 基准
We benchmark recent tabular deep learning models against GBDTs over diverse public datasets with different sizes and task types.
我们在具有不同大小和任务类型的各种公有数据集上将最近的表格深度学习模型与 GBDT 进行基准测试。
The following chart shows the performance of various models on small regression datasets, where the row represents the model names and the column represents dataset indices (we have 13 datasets here). For more results on classification and larger datasets, please check the benchmark documentation.
下图显示了各种模型在小型回归数据集上的性能,其中行表示模型名称,列表示数据集索引(我们这里有 13 个数据集)。有关分类和更大数据集的更多结果,请查看基准测试文档。
| Model Name 型号名称 | dataset_0 | dataset_1 | dataset_2 | dataset_3 | dataset_4 | dataset_5 | dataset_6 | dataset_7 | dataset_8 | dataset_9 | dataset_10 | dataset_11 | dataset_12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| XGBoost | 0.250±0.000 0.250±0.000 元 | 0.038±0.000 0.038±0.000 元 | 0.187±0.000 0,187±0.000 元 | 0.475±0.000 0.475±0.000 元 | 0.328±0.000 0,328±0.000 元 | 0.401±0.000 0.401±0.000 元 | 0.249±0.000 | 0.363±0.000 | 0.904±0.000 | 0.056±0.000 | 0.820±0.000 | 0.857±0.000 | 0.418±0.000 |
| CatBoost 猫加速 | 0.265±0.000 0.265±0.000 元 | 0.062±0.000 0,062±0.000 元 | 0.128±0.000 0.128±0.000 元 | 0.336±0.000 0,336±0.000 元 | 0.346±0.000 0.346±0.000 元 | 0.443±0.000 0.443±0.000 元 | 0.375±0.000 | 0.273±0.000 | 0.881±0.000 | 0.040±0.000 | 0.756±0.000 | 0.876±0.000 | 0.439±0.000 |
| LightGBM | 0.253±0.000 0,253±0.000 元 | 0.054±0.000 0,054±0.000 元 | 0.112±0.000 0.112±0.000 元 | 0.302±0.000 0.302±0.000 元 | 0.325±0.000 0.325±0.000 元 | 0.384±0.000 0.384±0.000 元 | 0.295±0.000 | 0.272±0.000 | 0.877±0.000 | 0.011±0.000 | 0.702±0.000 | 0.863±0.000 | 0.395±0.000 |
| Trompt Trompt (错视) | 0.261±0.003 0.261±0.003 元 | 0.015±0.005 | 0.118±0.001 | 0.262±0.001 | 0.323±0.001 0.323±0.001 元 | 0.418±0.003 0.418±0.003 元 | 0.329±0.009 | 0.312±0.002 | OOM | 0.008±0.001 | 0.779±0.006 | 0.874±0.004 | 0.424±0.005 |
| ResNet ResNet 公司 | 0.288±0.006 0.288±0.006 元 | 0.018±0.003 | 0.124±0.001 | 0.268±0.001 | 0.335±0.001 0.335±0.001 元 | 0.434±0.004 0.434±0.004 元 | 0.325±0.012 | 0.324±0.004 | 0.895±0.005 | 0.036±0.002 | 0.794±0.006 | 0.875±0.004 | 0.468±0.004 |
| FTTransformerBucket | 0.325±0.008 0,325±0.008 元 | 0.096±0.005 | 0.360±0.354 0.360±0.354 元 | 0.284±0.005 0.284±0.005 元 | 0.342±0.004 0.342±0.004 元 | 0.441±0.003 0.441±0.003 元 | 0.345±0.007 | 0.339±0.003 | OOM | 0.105±0.011 | 0.807±0.010 | 0.885±0.008 | 0.468±0.006 |
| ExcelFormer | 0.262±0.004 | 0.099±0.003 0.099±0.003 元 | 0.128±0.000 0.128±0.000 元 | 0.264±0.003 0.264±0.003 元 | 0.331±0.003 | 0.411±0.005 | 0.298±0.012 | 0.308±0.007 | OOM | 0.011±0.001 | 0.785±0.011 | 0.890±0.003 | 0.431±0.006 |
| FTTransformer | 0.335±0.010 0.335±0.010 元 | 0.161±0.022 0,161±0.022 元 | 0.140±0.002 | 0.277±0.004 | 0.335±0.003 0.335±0.003 元 | 0.445±0.003 0,445±0.003 元 | 0.361±0.018 | 0.345±0.005 | OOM | 0.106±0.012 | 0.826±0.005 | 0.896±0.007 | 0.461±0.003 |
| TabNet 标签网 | 0.279±0.003 0.279±0.003 元 | 0.224±0.016 0.224±0.016 元 | 0.141±0.010 0.141±0.010 元 | 0.275±0.002 0.275±0.002 元 | 0.348±0.003 0,348±0.003 元 | 0.451±0.007 0.451±0.007 元 | 0.355±0.030 | 0.332±0.004 | 0.992±0.182 | 0.015±0.002 | 0.805±0.014 | 0.885±0.013 | 0.544±0.011 |
| TabTransformer TabTransformer (标签变压器) | 0.624±0.003 | 0.229±0.003 | 0.369±0.005 0.369±0.005 元 | 0.340±0.004 | 0.388±0.002 | 0.539±0.003 0.539±0.003 元 | 0.619±0.005 | 0.351±0.001 | 0.893±0.005 | 0.431±0.001 | 0.819±0.002 | 0.886±0.005 | 0.545±0.004 |
We see that some recent deep tabular models were able to achieve competitive model performance to strong GBDTs (despite being 5--100 times slower to train). Making deep tabular models even more performant with less compute is a fruitful direction for future research.
我们看到,一些最近的深度表格模型能够实现与强 GBDT 相比有竞争力的模型性能(尽管训练速度慢了 5--100 倍)。以更少的计算量使深度表格模型的性能更高,是未来研究的一个富有成效的方向。
We also benchmark different text encoders on a real-world tabular dataset (Wine Reviews) with one text column. The following table shows the performance:
我们还在具有一个文本列的真实表格数据集 ( Wine Reviews) 上对不同的文本编码器进行基准测试。性能如下表所示:
| Test Acc 测试账户 | Method 方法 | Model Name 型号名称 | Source 源 |
|---|---|---|---|
| 0.7926 | Pre-trained 预训练 | sentence-transformers/all-distilroberta-v1 (125M # params) sentence-transformers/all-distilroberta-v1(125M# 参数) | Hugging Face 拥抱脸 |
| 0.7998 | Pre-trained 预训练 | embed-english-v3.0 (dimension size: 1024) embed-english-v3.0(维度大小:1024) | Cohere 凝聚 |
| 0.8102 | Pre-trained 预训练 | text-embedding-ada-002 (dimension size: 1536) text-embedding-ada-002(维度大小:1536) | OpenAI 开放人工智能 |
| 0.8147 | Pre-trained 预训练 | voyage-01 (dimension size: 1024) voyage-01 (尺寸: 1024) | Voyage AI AI Travel |
| 0.8203 | Pre-trained 预训练 | intfloat/e5-mistral-7b-instruct (7B # params) intfloat/e5-mistral-7b-instruct (7B # 参数) | Hugging Face 拥抱脸 |
| 0.8230 | LoRA Finetune LoRA 微调 | DistilBERT (66M # params) DistilBERT (66M # 参数) | Hugging Face 拥抱脸 |
The benchmark script for Hugging Face text encoders is in this file and for the rest of text encoders is in this file.
Hugging Face 文本编码器的基准脚本位于此文件中,其余文本编码器的基准脚本位于此文件中。
Installation 安装
PyTorch Frame is available for Python 3.9 to Python 3.13.
PyTorch Frame 适用于 Python 3.9 到 Python 3.13。
<span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><span style="color:#1f2328"><span style="color:var(--fgColor-default, var(--color-fg-default))"><span style="background-color:var(--bgColor-muted, var(--color-canvas-subtle))"><code>pip install pytorch-frame
</code></span></span></span></span>六、软件下载
夸克网盘分享
本文信息来源于GitHub作者地址:https://github.com/pyg-team/pytorch-frame