重会python爬虫学习----1
几种请求方式
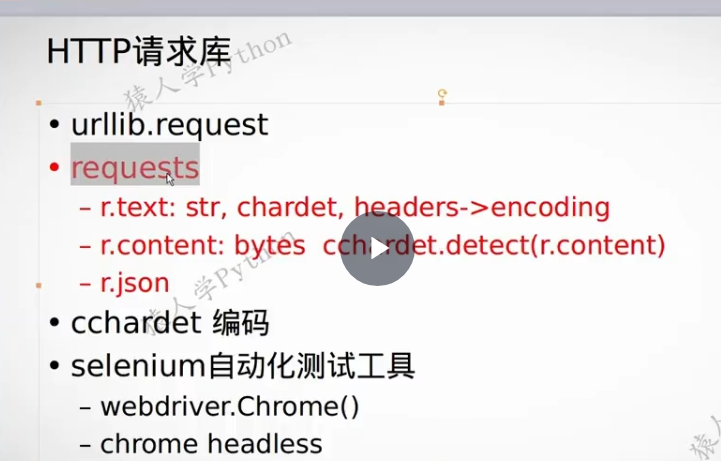
一些请求工具,技术栈
还有就是aiohttp这个。
进阶的就是用chrome断点调试javascript
还有就是用charles 和fiddle抓包分析了,
如何发现ajax加载url呢
1.就是用chrome浏览器f12调出开发者工具了
如net work
typr有 xhr,用筛选器是filter xhr
返回的结果又有哪些呢
json,xml,html
还有的就像是表现为瀑布流,实现是ajax.当你网页下拉到底部的时候,ajax加载下一页
还有就是js的解密了
我们打开网页加载的js----有下面的情况:压缩,打包,混淆
晦涩难懂,,pretty格式,但变量函数名难懂
我们要找到js加密的解密算法的代码——可以用charles抓包分析,也可以用chrome调试javascript.
对于技术的选择

异步并发,分布式爬虫
SEO(Search Engine Optimization)即搜索引擎优化,是一种通过优化网站结构、内容和代码,提高网站在搜索引擎自然搜索结果中排名的技术。对于新闻网站而言,SEO 的常见做法包括:
- 静态化 URL:将动态 URL 转换为包含关键词的静态 URL(如
https://news.example.com/2023/05/15/coronavirus-update.html) - 关键词优化:在 URL、标题和内容中合理分布关键词
- 元标签优化:优化 title、description 等 HTML 元标签
- 内容质量:提供有价值、原创的内容
清洗新闻 URL 的函数实现
针对你提到的新闻 URL 特点,我可以帮你实现一个清洗 URL 的函数,用于去除不必要的参数,避免重复抓取