聊一聊 - 如何像开源项目一样,去设计一个组件
文章目录
- 前言
- 1. 简介
- 2. 设计思路
- 2.1 目录文件划分
- 2.2 软件设计思路
- 2.2.1 识别并隔离变化
- 2.2.2 接受面向对象
- 2.2.3 定义好错误码
- 2.2.4 统一错误处理机制
- 2.2.5 版本管理
- 3 README文档设计思路
- 4. 结语
前言
之前做过一些能够支持多平台的通用组件开发。整体上来说反响还不错,这里和大家简单说一下如何去像开源组件一样,设计一个支持多平台的通用组件。
之所以说像开源组件一样,是因为工作多年后发现很多公司内部写的组件都远不如一些开源组件好用。特别是在一些大公司内,人多了之后如何及时有效的沟通常常决定了我们的工作效率和团队配合契合度(试想一下上午问的问题,下午3点才给答复),而这个问题又困惑着很多人和团队。
我一直对觉得这个问题没有好的解决方案然后摊摊手说就只能这样的情况感到很疑惑,这个问题真的没有解决方案吗?人家github上一个组件几百个公司去用也能做到很高效,为啥我们这一个公司内用都磕磕绊绊的呢,为啥我们不能学习一下github上别人是如何高效的维护起一个组件的呢?
带着这种想法在后续的项目和组件开发过程中我一直在学习github上好的项目是怎么进行维护的,以及我们在实际的项目中应该怎么做,几年下来也算是有一点点心得吧,这里和大家分享一下。
1. 简介
现在你收到了一个任务,需要去开发一个公司内部通用的通讯协议组件,我们将这个组件叫做CBB吧。
这个组件简单来说主要有以下功能
- 组件要按照CBB协议文档支持配对和消息发送接收,以及组件内成员管理
- 组件要适配不同的发送链路,例如UART、Socket、有线网络、433MHz无线等
- 组件分成从机和主机,一台设备上的主机可能会通过不同的链路和不同的从机通讯,一台设备可能既是从机又是主机
- 组件要能够运行在不同的硬件平台和不同操作系统的设备上,且要能够实现快速的移植。
围绕着上述功能实现,我们来看下要如何去展开软件设计与实现。
2. 设计思路
2.1 目录文件划分
就像我们看一本书会先看下目录有哪些内容,然后心里有个大概的了解再去决定看哪一章的哪个细节一样。
别人看我们的组件代码实现时或者说看我们的项目代码实现时,也是先看我们的目录划分是怎么样的,通过目录对我们的代码结构有了个初步的了解之后再去熟悉某个目录下的功能点是怎么样的。
好的代码如同好的书一样,让人看起来是一目了然且赏心悦目的,只有这样才能吸引别人读下去,所以为了能够让我们设计的软件更容易理解和维护以及吸引到更多的人去阅读,我们一定要先把软件的目录结构设计好。
在最初我们可能并不知道要如何划分软件的目录结构。此时可以按照如下的方式去思考
-
思考软件包含了哪些功能,哪些功能可以单独划分为一个模块,这个模块有没有相似的。有的话将其划分到同一个目录中,无的话将其按照模块类型单独划分到一个目录中
-
忘记自己所设计的目录结构,以旁观者的角度去看下自己所设计的目录结构,看看能不能快速的理解,如果不能快速的理解那么就回想下你第一时间觉得这个a文件夹中应该放的是什么?然后实际上放的是什么?如果不对就进行修改和拆分整合等。直到能做到一眼就能看出来这个是干啥的。
-
要有README,一般情况下开源的项目中都会有这么个项目说明文件,反而是公司里面很多人在开发过程中从来不写README,导致团队配合起来很难,很多事情都需要电话或者当面沟通找人解释,关键大公司内有时候已读不回也很正常。所以README这个文件一定要有,而且要尽可能的写的详细一些。如果是在线的README那么更好,这样可以防止出现本地的README不能及时更新的问题
cbb/├── cbb_api.h (对外提供的头文件)├── cbb_config.h (cbb的配置文件)├── cbb_def.h(cbb的结构体、宏定义)├──cbb_main.c(对外提供头文件的实现)├── port目录/ (移植代码所在的目录)├── master目录/ (主机核心业务)├── slave目录/ (从机核心业务)├── info目录/ (cbb在ram中的数据相关操作)├── flash目录/ (cbb在flash中的数据相关操作)├── domain目录/(cbb基础领域的处理)├── demo目录(为cbb编写的使用demo)└── README.md(说明文档)
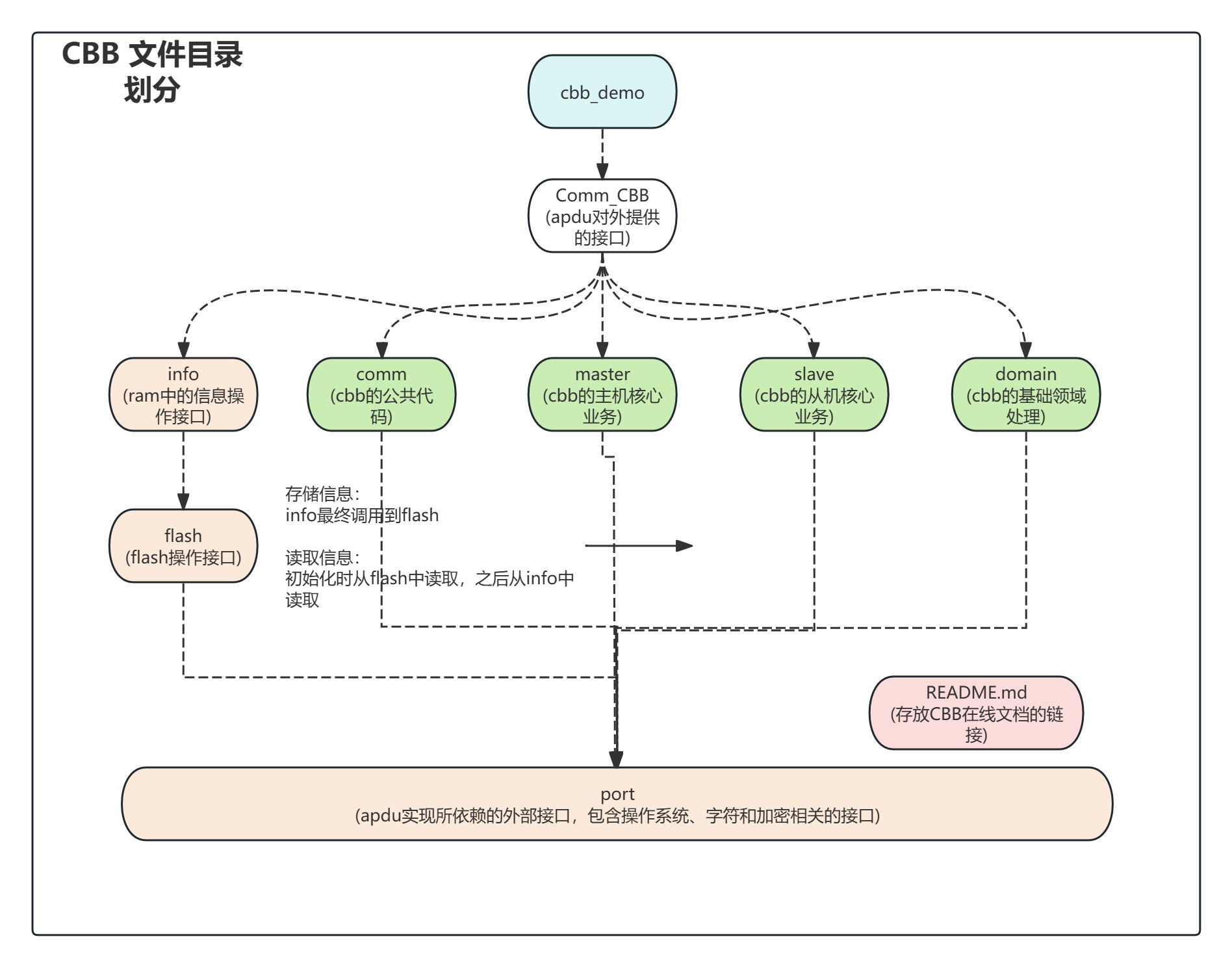
2.2 软件设计思路
软件设计的好坏和我们对于需求的理解息息相关,这里的理解不仅仅是要去实现当前规划的基本功能。还要考虑组件未来的使用场景,进行提前布局使其更加容易维护。
例如需要思考是否要支持多操作系统和多平台,如果是的话那么我们要识别不同的操作系统和平台其接口是不一样的,为了能够让别人更容易移植最好我们使用组件将用到的接口给抽象出来,组件内部的实现就去使用抽象出来接口,由使用方去进行实现等。
总结下来有几点比较常用的好用的方法。
2.2.1 识别并隔离变化
对于软件维护来说,控制变更的影响至关重要,而为了能够让别人更方便的使用我们的组件,我们就要隔离平台和操作系统不同所带来的变更。常用的隔离变化的方式有抽象接口和注册机制
注册机制
一些独属于该对象的动态变化的内容我们可以通过注册回调的方式去进行实现,例如消息的接收,不同的对象是不同的链路。
注册机制,先定义注册的回调函数接口//发送接收链路回调typedef uint16_t (*msgRxTxCb_t)(uint8_t *buf, uint16_t len);//读写flash回调typedef CbbRet_E (*flashCb_t)(uint8_t addr, CBB_FLASH_INFO_E type, void* data, uint8_t len);//用于检测cbb收到了哪些消息(ACK会用到)typedef void (*detectRecvCb_t)(CbbObj_S* cbb, uint8_t addr, uint16_t domainId, uint16_t cmdId);//cbb事件通知回调typedef void (*cbbEventCb_t)(CbbObj_S* cbb, CbbEvent_S* data); ``````c制定接口,通过接口去填充对象的回调函数/*** @method Cbb_SetRxTxCb* 注册CBB的消息链路。** @param {CbbObj_S*} cbb CBB对象。* @param {msgRxTxCb_t} rx 接收消息回调函数。* @param {msgRxTxCb_t} tx 发送消息回调函数。** @return {CbbRet_E} 返回操作结果,成功返回CBB_RET_OK,否则返回错误码。*/CbbRet_E Cbb_SetRxTxCb(CbbObj_S* cbb, msgRxTxCb_t rx, msgRxTxCb_t tx);/*** @method Cbb_SetFlashCb* 注册flash读写的接口。** @param {CbbObj_S*} cbb CBB对象。* @param {flashCb_t} write 写入flash的回调函数。* @param {flashCb_t} read 读取flash的回调函数。** @return {CbbRet_E} 返回操作结果,成功返回CBB_RET_OK,否则返回错误码。*/CbbRet_E Cbb_SetFlashCb(CbbObj_S* cbb, flashCb_t write, flashCb_t read);
抽象接口
一些不同对象都会使用到的通用接口(不属于单独某个对象独有的),更适合采用抽象接口的方式。而实现抽象接口可以使用#define 也可以使用函数实现的方式
#define方式
/****************************************************//**************** 内存和标准库相关操作 ****************//****************************************************//*** @brief 从堆中申请内存* 该函数就是普通的内存申请* * @param {size} 申请的字节大小** @return {void *} 申请内存的地址*/#define Cbb_Malloc(size) Plat_Os_Malloc(size)/*** @brief 释放通过Cbb_Malloc 申请的内存* * @param {x} 释放的地址** @return {void} 无*/#define Cbb_Free(x) do { if ((x) != NULL) { Plat_Os_Free((x)); (x) = NULL;} } while(0)
接口定义方式
/****************************************************//****************** 定时器相关接口定义 *****************//****************************************************/#define CbbOsTimerEntry_t OsTimerEntry_t#define CbbOsTimer_S voidCbbOsTimer_S* Cbb_Os_Timer_Create(CbbOsTimerEntry_t entry, void* args, uint32_t ms);int32_t Cbb_Os_Timer_Start(CbbOsTimer_S* timer);int32_t Cbb_Os_Timer_Destroy(CbbOsTimer_S* timer);/****************************************************//****************** 定时器相关接口实现 *****************//****************************************************/CbbOsTimer_S* Cbb_Os_Timer_Create(CbbOsTimerEntry_t entry, void* args, uint32_t ms){return (void *)Plat_Os_Timer_Create(entry, args, ms, OS_TIMER_REPEAT);}int32_t Cbb_Os_Timer_Start(CbbOsTimer_S* timer){CBB_RETURN_VALUE_IF_FAIL(Plat_Os_Timer_Start((PlatOsTimer_S*)timer) == RET_OK, -1);return 0;}int32_t Cbb_Os_Timer_Destroy(CbbOsTimer_S* timer){CBB_RETURN_VALUE_IF_FAIL(Plat_Os_Timer_Destroy((PlatOsTimer_S*)timer) == RET_OK, -1);return 0;}2.2.2 接受面向对象
为啥我说要接受使用面向对象呢,因为我在工作中发现很多做嵌入式开发的同事对如何使用面向对象和软件设计模式了解的比较少,当了解的比较少时就会比较抗拒去使用。
我以该协议为例子,我们要使用在一台设备上构建3台主机,3台主机分别使用蓝牙、串口、有线网络与对应的从机进行通讯。如果我们使用传统的面向结构的开发那么就会非常困难,可能我们要写3份代码,不然隔离会很难做,即使做出来了3个主机之间可能还是会有很强的耦合。
但如果我们使用面向对象的方式去思考的话,不同的主机就是不同的对象,我们就创建出来3个对象就行了,至于链路不同那就是创建对象时把各自消息收发的链路注册进去就行了。
我个人觉得使用面向的好处有。
- 减少代码的复用,因为要保持使用面向对象的开发方式,所以会把一切都看成对象并围绕着去进行实现。而这种以对象划分模块的方式会大大减少代码的复用。
- 减少全局变量和静态变量的使用。在多线程中全局变量和静态变量经常会引入不可重入导致的问题。而面向对象的开发方式会帮我们尽量规避掉全局变量的使用。因为对象可能会有很多个,但是全局变量和静态局部变量只能有一个和对象很难对应上(就一个葡萄,给谁吃呢),所以一般都不会使用全局变量
2.2.3 定义好错误码
在工作中,大家可能经常碰到没有统一的错误码的情况。A函数返回的是-1、-2、-3,B函数返回的是1、2、3。即使返回的是相同的值,不同的函数可能代表的意义也不一样。所以错误码就逐渐变成了一种摆设。这种方式给我们后续的维护会带来很大的困扰,所以在构建项目之处我么就要构建好属于我们的错误码。
/****************************************************/
/****************** 错误码 *****************/
/****************************************************/
typedef enum{CBB_RET_OK,CBB_RET_FAIL,CBB_RET_NO_MSG,CBB_RET_CRC_FAIL,CBB_RET_PROTO_FAIL,CBB_RET_BAD_PARAMS,CBB_RET_MALLOC_FAIL,CBB_RET_ENCRY_FAIL,CBB_RET_UNVALID_ADDR,CBB_RET_DEV_UNEXIST,CBB_RET_DOMAIN_NOT_SUP,CBB_RET_DEV_FULL,CBB_RET_SLAVE_NUMBER_MAX,
}CbbRet_E;
2.2.4 统一错误处理机制
问题描述
一般情况下为了能够预防空指针以及长度对不齐等导致的踩内存现象,我们一般都会先对函数的入参进行有效性判断。
这样做是不错,但是没有一个完善统一的错误处理机制时就会带来一系列问题。例如
-
大量的if else 占据了过多的篇幅,导致读者关注不到业务重点
// 传统方式 - 参数检查淹没业务逻辑 int process_data(DataPacket* packet) {if (!packet) {LOG_ERROR("process_data: null pointer");return -1;}if (packet->length > MAX_SIZE) {LOG_ERROR("process_data: invalid length %d", packet->length);return -2;}// 实际业务逻辑开始(被淹没在检查中)parse_json(packet->data); // 嵌套更多检查// ... 真实业务代码不到总行数的20% } -
处理错误信息时,直接打印函数名,有时候拷贝别的函数的打印,结果连打印的函数名也没修改
// 不同开发者编写的错误处理 void funcA() {if (ptr == NULL) {printf("Error: null pointer in funcA\n"); // 包含函数名} }void funcB() {if (size <= 0) {printf("Invalid size\n"); // 缺少关键定位信息} }void funcC() { // 复制funcA但忘记修改函数名if (buffer_overflow) {printf("Error: null pointer in funcA\n"); // 错误的函数名!} } -
错误处理不统一,有的打印的错误信息很全包含函数名,出现问题的位置和详细信息,有的则只有rval = %d这样的
// 开发者A:完整错误信息(理想情况) int load_config(const char* path) {if (!path) {// 包含文件、函数、行号、错误码和描述fprintf(stderr, "[ERROR][%s:%s:%d] ERR_NULL(0x1001): Config path is null\n", __FILE__, __FUNCTION__, __LINE__);return 0x1001; // 统一错误码}return 0; }// 开发者B:不完整错误信息(常见问题) int parse_json(const char* json_str) {if (!json_parser) {// 只有简单返回码,无任何定位信息printf("rval = %d\n", -1); // 问题1:无法定位错误位置return -1; // 问题2:错误码未标准化}if (strlen(json_str) > MAX_JSON_LEN) {// 部分信息但格式不一致printf("[ERR] JSON too long at line %d\n", 123); // 问题3:硬编码行号return -2; // 问题4:随意使用错误码}return 0; }
问题解决思路
我们定义三个宏:
CBB_RETURN_IF_FAIL(p): 如果条件p为假,则打印错误信息并直接返回(无返回值)。
CBB_RETURN_VALUE_IF_FAIL(p, value): 如果条件p为假,则打印错误信息并返回指定的值。
CBB_GOTO_EXIT_IF_FAIL(p, val): 如果条件p为假,则设置错误码iRet为val,打印错误信息,并跳转到EXIT标签处。
#define CBB_RETURN_IF_FAIL(p) \if (!(p)) { \CBB_DERROR("%s:%d condition(" #p ") failed!\n", __FUNCTION__, __LINE__); \return; \}#define CBB_RETURN_VALUE_IF_FAIL(p, value) \if (!(p)) { \CBB_DERROR("%s:%d condition(" #p ") failed!\n", __FUNCTION__, __LINE__); \return (value); \}#define CBB_GOTO_EXIT_IF_FAIL(p, val) \if (!(p)) { \iRet = val; \CBB_DERROR("%s:%d condition(" #p ") failed!\r\n", __FUNCTION__, __LINE__); \goto EXIT; \
}
示例代码
// 示例函数1:使用CBB_RETURN_IF_FAIL
void process_cbb_header(CBB_Packet* packet) {CBB_RETURN_IF_FAIL(packet != NULL);CBB_RETURN_IF_FAIL(packet->length > 0);printf("Processing CBB header...\n");// 实际处理逻辑
}// 示例函数2:使用CBB_RETURN_VALUE_IF_FAIL
int calculate_cbb_checksum(CBB_Packet* packet) {CBB_RETURN_VALUE_IF_FAIL(packet != NULL, -1);CBB_RETURN_VALUE_IF_FAIL(packet->data != NULL, -2);printf("Calculating checksum...\n");return 0; // 简化返回
}错误信息输出
=== Scenario 1: Null pointer detection ===
[CBB_ERROR] process_cbb_header:15 condition(packet != NULL) failed!=== Scenario 2: Invalid data pointer ===
[CBB_ERROR] calculate_cbb_checksum:24 condition(packet->data != NULL) failed!
Return value: -2
2.2.5 版本管理
对于一个组件来说,使用组件的人需要知道自己当前组件的版本。以用来区别使用版本和当前版本是否一致,并判断是否需要更新到最新版本。一般情况下我们采用 版本号 + 日期的方式。
- 版本号:用来说明大的改动
- 日期:用来描述小的改动
/****************************************************/
/****************** 版本信息 *****************/
/****************************************************/
#define CBB_VERSION "V1.0.0"//CBB前期改动比较频繁,大家移植完成后可能也不清楚自己当期所使用的版本日期信息,
//因此这里增加个VERSION_DATE,大家每次合并了主线代码后,最好把版本日期也合并上去
//这样就能根据在线文档中的修改记录去查询,有哪些功能没有合并,是否需要合并了
#define CBB_VERSION_DATE "20250519"
3 README文档设计思路
会专门写一篇博客去说明,敬请期待
4. 结语
说实话写的时候感觉这篇文章写的有点乱,因为是趁工作空闲时写的,所以有些断断续续的,本来写到一半想放弃了,感觉可能也不会有啥人看,自己也写的云里雾里的,但是最终还是坚持写了下来,希望能够对读者有一些帮助。
之前写东西时也出现过很多次这种情况,写的时候感觉写的啥啊,后面再回头看觉得还是多少有一些意义的,也当作是记录下部分自己当前的软件开发思想吧。
我一直觉得好的软件不应该是高深莫测的,而应该是简单易懂的。就像真正理解一个事物的人总能用通俗的语言去帮助别人理解一样,代码的好坏本身也是对自身所作业务的理解的体现。
好的代码往往更容易维护,因为开发者在做每一个改动时都在思考这次改动背后的动机以及未来的趋势,并及时的调整软件的各种细节和架构。
而杂乱无章的代码则大都是因为各种原因,为了凑合完成当前的工作,长期进行的胡乱拼凑。