笔记 操作系统复习
一、操作系统概述
操作系统的定义:
特权指令、处理器的状态以及程序状态字
操作系统结构
二、进程与线程
多道程序与并发执行
资源共享性、失去了封闭性和可再现性、相互制约性。
进程
进程是能和其他程序并行执行的程序段在某数据集合上的一次运行过程,是系统资源分配和调度的一个独立单位。
基本进程状态:
- 就绪 Ready
- 运行 Running
- 阻塞 Blocked / 等待 Waiting
进程实体由三部分组成,分别为程序、数据和进程控制块PCB。
线程
线程是进程中的一个实体,是比进程更小的能独立运行的基本单位,不独立拥有资源。
进程是资源的拥有者,有独立地址空间,不是处理器调度基本单位。线程不独立拥有资源,只有TCB和堆栈,共享地址空间,是处理器调度基本单位。
多线程
三、同步与互斥
进程互斥
并发原理
消费者和生产者问题
生产者将数据转入缓冲区(buffer),消费者进程从缓冲区(buffer)中提取数据,
两个进程交叉访问共享变量时产生错误,并发进程中与共享变量有关的程序段称为临界区,一次只允许一个进程使用的资源称为临界资源。进程中访问临界资源的那段代码称为临界区。
互斥(Mutual Exclusion)
一个进程在临界区中执行时,不让另一个进程进入相关的临界区执行,就不会造成与时间有关的错误。不允许两个以上共享共有资源或变量的进程同时进入临界区执行的性质称为互斥。
临界区管理应有三个要求:
- 互斥性
- 进展性
- 有限等待性
信号量与PV操作
在多个相互合作的进程之间使用简单的信号来协调控制,一个进程检测到某个信号后,就被强迫停止在一个特定的地方,直到他收到一个专门的信号为止才能继续执行,这个信号就称为信号量。
进程同步
进程同步的引入 生产者消费者问题中,消费者从一个空的缓冲区中提取数据
进程通信
进程通信的类型
- 共享存储器系统:相互通信的进程共享某些数据结构或存储区域
- 消息传递系统:进程间的数据交换以消息为单位
- 管道通信:用管道连接一个读进程和一个写进程以实现进程之间通信的一种共享文件,发送进程向管道输入数据,接受进程从管道接受数据,形成通信。
进程通信的有关问题
缓冲问题
并行性问题
死锁
死锁的必要条件
- 互斥条件
- 部分分配条件
- 不可抢占条件
- 循环等待条件
荷兰计算机科学家 Dijkstra 于1965年提出了一个信号量和PV操作的同步机构。在 P、V 操作中会用到进程控制原语,其中 P 操作用到了阻塞原语,在 V 操作中用到了 唤醒原语。
四、处理机调度
处理器调度层次
作业调度
根据进程控制块中的信息,按照某种原则从外存的后备队列中选取一个或几个进程调入内存,并创建进程和分配必要的资源,然后再将新创建的进程插入就绪队列。
中级调度
负责内外存之间的进程对换,以解决内存紧张的问题,即他将内存中处于等待状态的某些进程调到外存对换区以腾出内存空间,再将内存对换区中已具备运行条件的进程重新调入内存准备运行。
短程调度
短程调度也成为低级调度或进程调度,所调度的对象是进程。它决定就绪队列中哪个进程或线程将获得处理器,并将处理器分配给该进程或者线程。
进程调度的功能:
- 保护当前正在执行进程的现场,将程序状态寄存器、指令计数器及所有通用寄存的内容放到特定单元保留起来。
- 查询、登记和更新进程控制块 PCB 中的相应表项,从就绪进程中选择一个并把 CPU 分配给他。
- 回复被调度到的进程的原来现场。
进程调度分为剥夺式与非剥夺式。
单处理机调度算法
处理机调度功能与标准
调度算法准则:
- 资源利用率
- 平衡资源
- 响应时间
- 周转时期:一个进程从提交到完成之间的时间间隔称为周转时间,这是批处理系统衡量调度性能的一个重要指标。
- 吞吐量:每个单位时间完成的进程数。
- 公平性
常用调度算法
-
先来先服务调度
也称先进先出或严格排队方案,即先请求处理器的进程先分配到处理器,直到该进程运行结束或者发生等待。
-
时间片轮转法
每个进程被分配一个时间段,称为时间片,即允许该进程在该时间段中运行。如果在时间片结束时该进程还在运行,则将剥夺CPU并分配给另一个进程。如果时间片无限延长,那么时间片轮转法就会退化成先来先服务调度算法。
-
最短进程优先
最短进程优先策略是一种非抢占的策略,原则是选择所需处理时间最短的进程占有CPU运行,最短进程优先算法客服了 FCFS 偏爱长进程的缺点,易于实现。但其需要预先知道进程所需CPU时间,且忽略了进程等待时间。
-
优先级调度
每个进程被赋予一个优先级,允许优先级最高的可运行进程运行。
为了防止高优先级进程无休止地运行下去,调度程序可能在每个时钟终端降低进程的优先级,如果这一行为导致该进程的优先级低于次高优先级的进程,则进行进程切换。另一种方法是给每个进程赋予一个允许运行的最大时间片,当用完这个时间片时次高优先级的进程便会获得运行机会。
-
多级反馈队列轮换法
五、内存管理
存储管理的功能
目前许多计算机把存储器分为三级:外存、主存和缓存。
存储管理具有四个功能,分别是存储空间的分配和回收、地址变换与重定位、存储共享与保护、主存扩充。
存储分配的几种形式与重定位
直接存储分配方式
静态存储分配方式:在将作业装入内存时才确定他们在内存中的位置,运行时固定不变
动态存储分配方式:不一次性将程序全部装入主存,而是根据执行需要动态装入和回首,也可动态申请存储空间
重定位
覆盖与交换
分区存储管理
虚拟内存
为了解决程序大于内存的问题,早期所采取了一种方法,将程序分割成多个片段,称为覆盖(overlay)。程序开始执行时,将覆盖管理模块装入内存,改管理模块立即装入并运行覆盖0。执行完成后,覆盖0通知管理模块装入覆盖1,或者占用覆盖0上方的位置,或者占用覆盖0(如果没有空间)。
还用一种方法(Fotheringham, 1961)称为虚拟内存(virtual memory)。虚拟内存的基本思想是:每个程序拥有自己的地址空间,这个控件被分割成多个块,每一块称作一页或页面(page)。每一页有连续的地址范围,这些页被映射到物理内存,但并不是所有的页必须在内存中才能运行程序。当程序引用到一部分在物理内存中的地址空间时,由硬件立刻执行必要的映射。当程序引用到一部分不在内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令。
页式存储管理
分区管理
页面置换算法
-
最优页面置换算法(Optimal Page Replacement, OPT)
在缺页中断发生时,有些页面在内存中,其中有一个页面将很快被访问,其他页面需要更久被访问,那么每个页面都可以用在该页面手册被访问前所要执行的指令数作为标记。最优页面置换算法规定应该置换标记最大的页面。
-
最近未使用页面置换算法(Not Recently Used, NRU)
-
先进先出页面置换算法(FIFO)
-
第二次机会页面置换算法(Second Chance Algorithm)
改进后的先进先出,基于页面一个 R 位来判断最近有没有使用过
-
最近最少使用页面置换算法(Least Recently Used, LRU)
淘汰最长时间未被使用的页面,理论上接近 OPT
-
时钟页面置换算法(Clock Algorithm)
六、File Systems
File Concept
There a many extension for the file, they have different meanings.
.bak -> backup file, .c -> C source program, .o -> object file(compiler output, not yet linked)
Four types of file
- Regular files: contain user infromation, like ASCII files and Binary files
- Directory files: are system file for maintaining the structure of the file system. A directory file is essentially an index table that maps file names to their corresponding inode numbers.
- Character special files: are related to I/O,
/dev/tty - Block special files: are used for model disks,
/dev/sda
Both character special files and block special files are used for I/O operations but in different ways.
There are two examples of binary files, an executable file and an archive
File system implementation
The most important issue in implementing file storage is keeping tarck of which disk blocks go with which file. The simplest allocation scheme is to store each file as a contiguous run of disk blocks. Thus on a disk with 1-KB blocks, a 50-KB file would be allocated 50 consecutive blocks. With 2-KB blocks, it would be allocated 25.
I-nodes
i-node(index-node), which lists the attributes and disk addresses of the file’blocks. GIven the i-node, it is then possible to find all the blocks of the file.
i-node structure (simplified)
| Field | Description |
|---|---|
| FIle type & permissions | |
| Owner UID / GID | |
| File size | |
| Timestamps | |
| Link count | Number of hard links to this i-node |
| Data block pointers | Pointers to the actual file content on disk |
Data block pointers are the most important part of the inode when it comes to accessing file content, each inode contains a set of pointers(address) to disk blocks where the file’s actual data is stored.
[!NOTE]
The main reason is to balance performance and scalability. File systems are designed to work efficiently with both small and very large files.
例题 Consider the organization of a UNIX file as represented by the i-node. Assume that there are 10 direct block pointers, and a singly, doubly, and triply indirect pointer in each i-node. Further, assume that the system block size and the disk sector size are both 4K.
-
Please describe the structure of i-nodes and data blocks;
An i-node contains metadata about a file and pointers to the data blocks where the file’s content is stored.
-
Assume the size of one data block is 4KB, the disk address is represented as 4 byte unsigned intergers, what is the maximum size of the file that the file system can create?
The data block is 4KB and each pointer need 4 bytes, so 1 block can store 4096 ÷ 4 = 1024 4096 \div 4 = 1024 4096÷4=1024 pointers
Pointer type Blocks accessible File size Direct (10) 10 blocks 10 \times 4KB = 40KB Single Indirect 1024 blocks 1K \times 4KB = 4MB Double Indirect 1024 2 1024^2 10242 blocks 1M \times 4KB = 4GB Trible Indirect 1024 3 1024^3 10243 blocks 1T \times 4KB = 4TB The total max file size = 4TB 4GB 4MB 40KB
-
If the disk block pointer is 32 bits, with 8 bits to identify the physical disk and 24 bits to identify the pysical block, then
a. What is the maximum file size supported by this system?
32-bit block pointer = 8 bits (disk ID) + 24 bits (block number), max blocks per partition = 2^24, and the block size is 4KB. So the max file size limited by blocks in partition is 2^24 \times 2^12 = 2^36 bytes = 64GB
b. What is the maximum file system partition supported by this system?
c. Assuming no infromation other than that the file i-node is already in main memory, how many disk accesses are required to access the byte in position 4321281?
七、输入/输出
通常将处理器和主存以外的设备成为外部设备或 I/O 设备。
I/O 硬件原理
I/O 设备
IO 设备大致可以分为两类:块设备(block device)和字符设备(character device)。块设备把信息存储在固定大小的块中,每个块有自己的地址。所有传输都以一个或多个连续的块为单位。块设备的基本特征是每个块都能独立于其他块的读写。磁盘、蓝光光盘和USB盘是最常见的块设备。字符设备以字符为单位发送或接收一个字符流,而不考虑任何块结构。字符设备是不可寻址的,也没有任何寻道操作。打印机、鼠标、网络接口都是字符设备。
I/O 系统组成
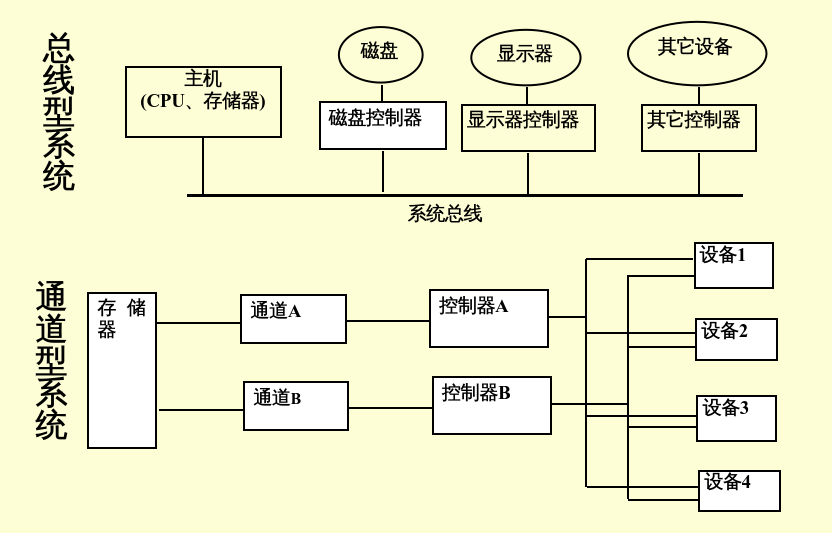
I/O 系统由 I/O 设备、设备控制器、通道和 I/O 统一接口组成。
I/O 设备:用于完成数据的输入输出
设备控制器:用于控制对应的 I/O 设备
通道:用于数据传输(总线型或通道型)
I/O 统一接口:为不同设备的使用提供统一的接口
磁盘存储器的管理
基本概念
想象你有一块机械硬盘(比如/dev/sda),它的数据组织就像一摞光盘叠在一起(柱面),每张光盘被划分为一圈圈的同心圆轨道(磁道),每个轨道又被切成披萨一样的扇形块(扇区)。具体来说:
- 磁道(Track):像CD唱片上的音轨,是磁盘旋转时磁头画出的圆形轨迹,用
fdisk -l看到的"heads"参数部分相关(现代硬盘是逻辑磁头) - 柱面(Cylinder):所有盘片的同一半径磁道组成的立体柱体,早期分区对齐柱面(
fdisk的柱面单位显示),现在SSD时代已弱化这个概念 - 扇区(Sector):磁盘最小物理存储单元(传统512字节,现代4K),用
blockdev --getbsz /dev/sda可查,文件系统簇(cluster)通常由多个扇区组成
磁盘访问的三个时间构成(再次确认)
- Seek Time(寻道时间):磁头从当前磁道移动到目标磁道所需时间(已知每相邻磁道10ms)
- Rotational Latency(旋转延迟):目标扇区旋转到磁头下所需的时间
- Transfer Time(传输时间/记录读写时间):从磁道中将目标扇区的内容读/写到内存所需的时间
磁盘调度
磁盘调度包括移动调度与旋转调度,分别针对减少寻道时间和旋转时间,移动调度根据用户作业发出的磁盘 IO 请求的柱面位置,来决定请求执行顺序的调度。其目的是尽可能地减少移动臂的移动距离,常用的算法有以下几种
- 先来先服务算法:根据进程请求访问磁盘的先后顺序进行调度,而不管进程的优先级。
- 最短寻道时间优先算法:以磁头移动距离大小作为优先的因素,磁道距离磁头当前位置越近越优先。
- 扫描算法:Scan 又称电梯调度,不仅考虑申请者要求磁头移动方向,又要考虑磁头移动距离,而且是方向一致,其次才是距离最短
- 循环扫描法:C-Scan 规定磁头单向移动,将各磁道是做一个环形缓冲区结构,最大磁道号和最小磁道号构成循环
- 多队列多步扫描法
例题 设某单面磁盘旋转速度为每分钟7200转。每个磁道有100个扇区,相邻磁道间的平均移动时间为10ms。磁道号请求队列为60、50、190、20、150,假设当前磁头在磁道号100且移动方向由小到大方向,对请求队列中的每个磁道需读取1个随机分布的扇区。则在下列情况下读完这5个扇区总共需要多少时间?要求给出计算过程。
扇区在盘面上是环形排列的,因为是随机位置,所以平均延迟 = 半圈 = 0.5 转
由于每个磁道有100个扇区,因此读写一个扇区的记录读写时间 = 1 转 / 100
旋转延迟 + 读写时间 = 60 × 1000 7200 × 0.5 + 60 × 1000 7200 × 1 100 = 51 12 旋转延迟 + 读写时间 = \frac{60 \times 1000}{7200} \times 0.5 + \frac{60 \times 1000}{7200} \times \frac{1}{100} = \frac{51}{12} 旋转延迟+读写时间=720060×1000×0.5+720060×1000×1001=1251
-
FCFS(先来先服务);
寻道距离 = 40 + 10 + 140 + 170 + 130 = 490 寻道距离 = 40 + 10 + 140 + 170 + 130 =490 寻道距离=40+10+140+170+130=490
总时间为 4900 + 5 × 51 12 ≈ 4921.25 m s 总时间为\ 4900 + 5 \times \frac{51}{12} \approx 4921.25ms 总时间为 4900+5×1251≈4921.25ms
-
SSTF(最短寻道时间优先);
寻道距离 = 260
-
SCAN(电梯调度)。
寻道距离 = 260
磁盘冗余阵列
RAID(Redundant Array of Independent Disks)是一种把多块硬盘组合成一个逻辑存储单元的技术,其目的是将多块硬盘组合称一个逻辑存储单元的技术,主要目的是为了提高性能(并行读写)和增强可靠性。RAID 有不同方法,以数字编号代表
- RAID 0:数据拆分成快,交替写入多块硬盘
- RAID 1:镜像,数据完全复制到另一块磁盘
- RAID 5:分布式校验,数据+校验信息分散存储在三块及以上磁盘
- RAID 6:双校验,类似于 RAID 5 但有两份校验信息,允许坏两块盘