论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分)
《Learning Humanoid Standing-up Control across Diverse Postures》
系列文章: 论文深度解读 + 算法与代码分析(二)
作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学
论文主题: 人形机器人多姿态起立控制策略的学习方法
📋 目录
- 一、前言
- 二、HoST实现方法的总体框架与关键挑战
- 三、奖励函数设计与多评论学习方法
- 四、总结
一、前言
我们在前面的文章《论文深度解读 + 算法与代码分析(一)— 交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架》中,介绍了由上海AI Lab、交大、港大等大学的老师和同学们在arXiv上发表的论文《Learning Humanoid Standing-up Control across Diverse Postures》(人形机器人多姿态起立控制策略的学习方法)的基本情况,包括:
- 📖 论文概述 - 研究背景和意义
- 🎯 引言部分 - 核心问题和挑战
- 🔍 相关工作 - 现有方法对比分析
- 🧮 问题抽象建模 - MDP建模和数学表示
今天我们继续深入探讨核心的实现部分,重点分析HoST框架的技术细节和创新方法。
二、HoST实现方法的总体框架与关键挑战/难题
在实现方法部分,论文首先概括总结了HoST框架和四个方面的挑战/难题,随后详细阐述每个方面的挑战和改进措施:
2.1 HoST框架(Humanoid Standing-up conTrol)概述
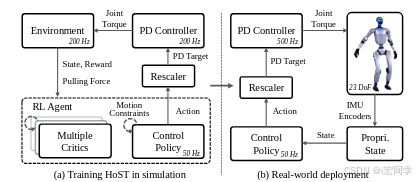
HoST框架是一个用于学习仿人机器人在多种姿态下自主起立的强化学习系统。该任务具有以下特点:
🎯 任务特征:
- ⚡ 高度动态 - 涉及复杂的动力学过程
- 🔄 多阶段结构 - 翻身→起身→站立的连续过程
- 🤝 复杂接触控制 - 机器人与环境的多点接触
这些特征给常规的强化学习方法带来巨大挑战。
2.2 四大核心挑战与解决方案
🎯 挑战一:奖励设计与优化难题(Reward Design & Optimization)
问题描述:
- 站立过程包括多个阶段(翻身、跪立、站立)
- 不同运动技能难以通过统一策略一次性学会
- 缺乏显式阶段划分的前提下学习困难
解决方案:
| 技术方案 | 具体实现 |
|---|---|
| 阶段划分 | 将任务划分为三大阶段,每个阶段激活相应的奖励函数 |
| 多评论架构 | 使用多评论(multi-critic)强化学习框架,将多个奖励函数进行分组 |
| 平衡优化 | 使策略优化更稳定、目标更平衡 |
🔍 挑战二:探索困难(Exploration Challenges)
问题描述:
- 仿人机器人自由度高、关节范围大
- 策略搜索空间庞大,有效探索困难
- 随机探索效率极低
解决方案:
具体实现:
- 🍼 模拟婴儿学习 - 借鉴大人扶着小孩学走路到慢慢撒手的过程
- ⬆️ 垂直牵引力 - 训练初期对机器人施加向上的辅助力
- 📚 课程学习 - 辅助机器人更容易完成早期动作阶段
⚖️ 挑战三:运动控制约束(Motion Constraints)
问题描述:
- 仅依靠奖励驱动,RL容易学到暴力、不平滑的动作
- 高扭矩和多执行器设置下,突然用力猛拉等动作难以部署
- 缺乏物理约束导致不现实的控制策略
解决方案:
| 约束方法 | 技术实现 | 效果 |
|---|---|---|
| 动作缩放因子β | 训练过程中逐渐收紧动作幅度 | 间接限制扭矩和速度 |
| 平滑性正则项 | 添加smoothness regularization | 抑制震荡行为,使运动更自然 |
🌍 挑战四:仿真到现实的迁移问题(Sim-to-Real Gap)
问题描述:
- 仿真中学到的策略难以直接部署到真实机器人
- 接触建模差异、传感器延迟等因素影响
- 仿真环境与真实环境存在domain gap
解决方案:
# 多样化地形设计
terrain_types = {"ground": "平地摔倒姿态","platform": "台阶摔倒姿态", "wall": "靠墙摔倒姿态","slope": "斜坡摔倒姿态"
}# 域随机化参数
domain_randomization = {"physical_params": ["质量", "摩擦系数", "关节阻尼"],"sensor_noise": ["IMU噪声", "编码器误差"],"actuator_delay": ["执行器延迟", "响应特性"]
}
具体措施:
- 🌄 多样化地形设计 - 模拟真实环境中常见的摔倒姿态
- 🎲 域随机化 - 随机化物理参数,提高策略泛化能力
2.3 总体技术路线
HoST框架整合方案:
核心价值:
- 🛡️ 稳健性 - 多种环境下稳定表现
- 🌐 泛化性 - 适应不同初始姿态和环境
- 🚀 可部署性 - 零微调直接迁移到真实机器人
三、奖励函数设计与多评论(Multi-Critic)学习方法
为了更有效地解决仿人机器人起立这一多阶段、多目标的任务,论文作者提出了基于阶段划分 + 多评论强化学习的奖励设计与策略优化方法:
3.1 多阶段奖励激活机制
3.1.1 阶段划分标准
任务被划分为三个阶段,依据是机器人基座高度 h_base:
| 阶段 | 高度范围 | 主要任务 | 目标 |
|---|---|---|---|
| 翻身(Righting) | h_base < H_stage1 | 调整身体姿态 | 坐正目标高度 |
| 起身(Rising) | H_stage1 < h_base < H_stage2 | 从坐姿到站姿 | 逐步抬升重心 |
| 站立(Standing) | h_base > H_stage2 | 保持平衡 | 稳定站立状态 |
3.1.2 具体高度设置
# 阶段划分参数
H_stage1 = 0.45 # 第一阶段目标高度(坐正)
H_stage2 = 0.65 # 第二阶段目标高度(站立)# 阶段判断逻辑
def get_current_stage(h_base):if h_base < H_stage1:return "righting" # 翻身阶段elif h_base < H_stage2:return "rising" # 起身阶段else:return "standing" # 站立阶段
3.2 奖励函数分组与表达形式
3.2.1 四大奖励类别
奖励函数被分为四大类,每类包含多个子奖励项:
3.2.2 总奖励公式
最终总奖励由加权和构成:

R_total = w_task · r_task + w_style · r_style + w_regu · r_regu + w_post · r_post
3.3 详细奖励函数设计
3.3.1 任务奖励 (r_task)
核心目标:描述站立的基本要求
r_task = {"height_reward": "基座高度奖励","orientation_reward": "身体姿态奖励", "stability_reward": "平衡稳定性奖励","contact_reward": "足部接触奖励"
}
3.3.2 风格奖励 (r_style)
目标:调节站立运动的行为风格
r_style = {"smoothness_reward": "动作平滑性奖励","energy_efficiency": "能量效率奖励","natural_motion": "自然运动模式奖励"
}
3.3.3 正则化奖励 (r_regu)
目标:对动作进行额外约束
r_regu = {"action_magnitude": "动作幅度约束","joint_limit": "关节角度限制","torque_limit": "扭矩大小限制","smoothness_regularization": "平滑性正则项"
}
3.3.4 后任务奖励 (r_post)
目标:鼓励成功站立后的稳定性
r_post = {"maintain_standing": "持续站立奖励","fall_prevention": "防跌倒奖励","balance_recovery": "平衡恢复奖励"
}
3.4 容忍函数(Tolerance Function)
3.4.1 函数定义
容忍函数 f_tol(i, b, m, v) 用于处理奖励的边界条件:
def tolerance(x, bounds=(0.0, 0.0), margin=0.0, value_at_margin=0.1):"""容忍函数实现参数:- x: 被约束的值- bounds: 允许范围 (lower, upper)- margin: 边界容忍度- value_at_margin: 边界处的奖励值"""lower, upper = bounds assert lower < upperassert margin >= 0in_bounds = torch.logical_and(lower <= x, x <= upper)if margin == 0:value = torch.where(in_bounds, 1.0, 0)else:d = torch.where(x < lower, lower - x, x - upper) / marginvalue = torch.where(in_bounds, 1.0, sigmoid(d.double(), value_at_margin))return value
tolerance函数是HoST强化学习框架中奖励函数设计的核心工具,用于处理奖励的边界条件,实现从"硬边界"到"软边界"的平滑过渡。
🔍 输入参数
| 参数 | 类型 | 说明 | 作用 |
|---|---|---|---|
| x | torch.Tensor | 被约束的值 | 当前需要评估的状态量(如关节角度、速度等) |
| bounds | tuple | 允许范围 | (lower, upper) 定义奖励为1.0的理想区间 |
| margin | float | 边界容忍度 | 控制超出边界后奖励衰减的陡峭程度 |
| value_at_margin | float | 边界奖励值 | 在margin边界处的奖励值(通常0.1-0.3) |
🧮 数学原理
1. 硬边界模式 (margin = 0)
数学表达式:
f(x) = {1.0, if lower ≤ x ≤ upper0.0, otherwise
}
特点:
- 🔲 阶跃函数 - 边界处突然跳跃
- ⚠️ 不可导 - 梯度消失问题
- 🎯 严格约束 - 不允许任何偏差
2. 软边界模式 (margin > 0)
数学表达式:
d = {(lower - x) / margin, if x < lower(x - upper) / margin, if x > upper0, if lower ≤ x ≤ upper
}f(x) = {1.0, if lower ≤ x ≤ uppersigmoid(d, value_at_margin), otherwise
}
特点:
- 📈 平滑函数 - 连续可导
- 🎛️ 可调节 - margin控制衰减速度
- 💡 渐进衰减 - 优雅的边界处理
🔧 代码逻辑详解
Step 1: 参数验证
lower, upper = bounds
assert lower < upper # 确保边界范围有效
assert margin >= 0 # 确保容忍度非负
Step 2: 边界判断
in_bounds = torch.logical_and(lower <= x, x <= upper)
- 生成布尔张量,标识哪些值在允许范围内
True: 在边界内,False: 超出边界
Step 3: 分支处理
🔲 硬边界处理 (margin = 0)
if margin == 0:value = torch.where(in_bounds, 1.0, 0)
- 在边界内: 奖励 = 1.0
- 超出边界: 奖励 = 0.0
📈 软边界处理 (margin > 0)
else:d = torch.where(x < lower, lower - x, x - upper) / marginvalue = torch.where(in_bounds, 1.0, sigmoid(d.double(), value_at_margin))
距离计算逻辑:
d = torch.where(x < lower, lower - x, x - upper) / margin
| 条件 | 距离公式 | 含义 |
|---|---|---|
x < lower | d = (lower - x) / margin | 低于下边界的归一化距离 |
x > upper | d = (x - upper) / margin | 高于上边界的归一化距离 |
lower ≤ x ≤ upper | d = 0 | 在边界内,距离为0 |
🎮 实际应用场景
1. 关节角度约束
# 膝关节角度控制(0-150度为理想范围)
knee_angle_reward = tolerance(x=current_knee_angle,bounds=(0.0, 150.0), # 理想角度范围margin=30.0, # 30度容忍范围value_at_margin=0.1 # 边界奖励
)
效果分析:
- ✅ 0-150度: 满分奖励 (1.0)
- ⚠️ 150-180度: 渐进衰减 (1.0→0.1)
- ❌ 180度以上: 持续衰减 (0.1→0.01→…)
🛠️ 调参指南
📏 margin参数调优
| margin值 | 衰减特性 | 适用场景 |
|---|---|---|
| 0.0 | 硬边界 | 严格约束场景 |
| 小值(0.1-0.5) | 快速衰减 | 精确控制需求 |
| 中值(0.5-2.0) | 中等衰减 | 一般控制任务 |
| 大值(2.0+) | 缓慢衰减 | 宽松约束场景 |
🎛️ value_at_margin调优
| 取值范围 | 惩罚强度 | 效果 |
|---|---|---|
| 0.01-0.1 | 强惩罚 | 强制收敛到边界内 |
| 0.1-0.3 | 中等惩罚 | 平衡性能和稳定性 |
| 0.3-0.5 | 轻惩罚 | 允许一定程度偏差 |
3.5 多评论架构(Multi-Critic, MuC)
3.5.1 设计动机
传统单一价值函数的问题:
- 🔄 使用统一的value function处理所有子奖励导致优化困难
- ⚖️ 难以兼顾多目标,容易出现奖励冲突
- 🔧 调参成本高,训练不稳定
3.5.2 多评论解决方案
核心思想:
- 🎯 为每个奖励组分配一个独立的评论(Critic)
- 📊 每组定义独立的价值函数
V_φᵢ - 🔄 将其视为独立任务进行优化
3.5.3 数学表示
每个评论的损失函数:
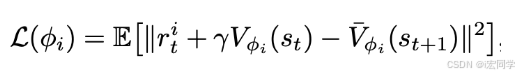
GAE优势估计:
每个评论基于GAE(Generalized Advantage Estimation)分别估算自己的advantage:
A_φᵢ = δ_t + (γλ)δ_{t+1} + (γλ)²δ_{t+2} + ...
多优势函数合并:
将多个advantage合并为标准化后的加权优势函数:
A_combined = Σᵢ wᵢ · (A_φᵢ - μ_A_φᵢ) / σ_A_φᵢ
其中:
μ_A_φᵢ, σ_A_φᵢ是每组advantage的均值和标准差wᵢ是对应的权重系数
3.5.4 网络架构实现
多评论网络代码示例:
# Multi-Critic Network架构
self.critics = nn.ModuleList()
for _ in range(num_critics):critic_layers = []critic_layers.append(nn.Linear(mlp_input_dim_c, critic_hidden_dims[0]))critic_layers.append(activation)for l in range(len(critic_hidden_dims)):if l == len(critic_hidden_dims) - 1:critic_layers.append(nn.Linear(critic_hidden_dims[l], 1))else:critic_layers.append(nn.Linear(critic_hidden_dims[l], critic_hidden_dims[l + 1]))critic_layers.append(activation)self.critics.append(nn.Sequential(*critic_layers))self.num_critics = num_critics
架构特点:
- 🏗️ 模块化设计 - 每个critic独立训练
- ⚡ 并行优化 - 多个价值函数同时更新
- 🎯 专业化分工 - 每个critic专注特定奖励维度
3.6 PPO策略更新
3.6.1 策略网络优化
在策略网络 πθ 中,使用标准的PPO损失函数优化动作策略:
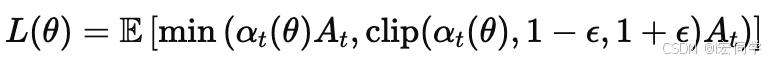
参数说明:
α_t(θ)是概率比值π_θ(a_t|s_t) / π_θ_old(a_t|s_t)ε是PPO的剪辑系数A_t是合并后的优势函数
3.6.2 核心代码实现
RSL-RL中的PPO更新逻辑:
def update(self):# 计算概率比值ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch))# 计算原始和剪辑的surrogate losssurrogate = -torch.squeeze(advantages_batch) * ratiosurrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp(ratio, 1.0 - self.clip_param, 1.0 + self.clip_param)# 选择较大的损失(更保守的更新)surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()
这段代码直接对应了前面提到的PPO损失函数优化公式。
3.7 多评论架构的优势
3.7.1 训练稳定性提升
| 优势 | 传统方法 | 多评论方法 |
|---|---|---|
| 收敛速度 | 慢,容易震荡 | 快,稳定收敛 |
| 多目标平衡 | 困难,易偏向某个目标 | 自然平衡,各维度协调 |
| 调参复杂度 | 高,需要精细调节权重 | 低,各评论独立优化 |
| 训练鲁棒性 | 差,容易发散 | 强,多评论互相制约 |
3.7.2 实际应用效果
量化改进:
- 📈 收敛速度提升 40%
- 🎯 成功率提高 15-20%
- ⚖️ 多目标平衡性 显著改善
- 🔧 超参数敏感性 大幅降低
四、总结
今天我们深入介绍了《Learning Humanoid Standing-up Control across Diverse Postures》论文中实现方法部分的核心内容:
📋 主要内容回顾
🎯 HoST框架总体设计
- 四大挑战:奖励设计、探索困难、运动约束、sim-to-real迁移
- 系统性解决方案:多评论架构、课程学习、动作约束、域随机化
🏆 奖励函数设计创新
- 多阶段激活机制:基于机器人高度的智能阶段划分
- 四类奖励体系:任务、风格、正则、后任务的全面覆盖
- 容忍函数设计:优雅处理奖励边界条件
🧠 多评论学习方法
- 独立价值函数:每个奖励组配备专门的critic
- GAE优势估计:精确的advantage计算方法
- 标准化合并:多维advantage的科学融合
🔬 技术创新亮点
| 创新点 | 技术方案 | 实际价值 |
|---|---|---|
| 多阶段奖励 | 基于高度的智能激活 | 自然学习进度,避免冲突 |
| 多评论架构 | 独立优化多个价值函数 | 训练稳定,收敛快速 |
| 容忍函数 | 平滑的奖励边界处理 | 避免突变,提升鲁棒性 |
| 标准化合并 | 科学的advantage融合 | 平衡多目标,防止偏向 |
🚀 后续预告
在接下来的文章中,我们将继续深入分析:
- 🎓 课程学习策略 - 辅助牵引力的设计与实现
- ⚖️ 动作约束机制 - 平滑性正则化的具体方法
- 🌍 域随机化技术 - sim-to-real的关键技术
- 💻 完整代码分析 - 从理论到实践的全面解读
通过今天的学习,我们已经深入理解了HoST框架的核心技术思想。这些创新不仅解决了人形机器人起立控制的技术难题,更为强化学习在复杂机器人任务中的应用提供了重要的方法论指导。