Linux 文本比较与处理工具:comm、uniq、diff、patch、sort 全解析
在类 UNIX 操作系统,特别是 Linux 系统中,命令行提供了一整套强大的文本处理工具,这些工具对于文件差异对比、内容筛选、文本排序以及源代码管理尤为重要。今天,我们将结合真实示例,深入介绍并实战演示 comm、uniq、diff、patch 和 sort 五大命令的用法,深入探讨工具背后的原理和工具间的协作机制,帮助读者更高效地处理文本数据。
一、基础概念与环境准备
在 Linux 中,文本处理工具的设计哲学是“做一件事并做好”,这些工具通常专注于单一功能,但通过管道(|)和重定向(>、<)等机制组合使用,可以实现复杂的数据处理任务。以下是我们将使用的测试环境和文件准备步骤。
1.1 创建测试环境
为了便于演示,我们首先在用户主目录下创建一个实验目录并生成几个测试文件,分别代表不同的类 UNIX 系统类型:
mkdir -p ~/textcompare && cd ~/textcompare
创建四个测试文件:gnu、linux、bsd 和 unix,内容如下:
cat > gnu << EOF
Arch Hurd
Debian GNU/Hurd
Debian GNU/kFreeBSD
Debian GNU/Linux
Guix System
EOFcat > linux << EOF
Debian GNU/Linux
Gentoo
Android
Alpine Linux
OpenWRT
Ubuntu
EOFcat > bsd << EOF
FreeBSD
OpenBSD
GhostBSD
Debian GNU/kFreeBSD
NetBSD
DragonFly BSD
EOFcat > unix << EOF
macOS
AIX
Solaris
OpenBSD
FreeBSD
EOF
这些文件模拟了不同系统发行版的清单,我们将使用它们来演示 comm、uniq、diff、patch 和 sort 的功能。
1.2 工具概览
以下是本文将介绍的五个工具的核心功能概览:
| 工具 | 主要功能 | 典型应用场景 |
|---|---|---|
comm | 比较两个已排序文件的交集和差异 | 查找文件内容的共有和独有部分 |
uniq | 去重、统计重复行 | 日志分析、数据清洗 |
sort | 按指定规则排序文本行 | 数据预处理、字段排序 |
diff | 比较文件差异并生成补丁 | 版本控制、配置文件对比 |
patch | 应用补丁修改文件内容 | 软件更新、配置合并 |
这些工具的组合使用可以覆盖从简单文本处理到复杂版本控制的多种场景。
二、comm:高效比较两个有序文件的交集与差异
2.1 用法与原理
comm 命令用于比较两个已排序的文本文件,输出结果分为三列:
- 第一列:仅在第一个文件中出现的行
- 第二列:仅在第二个文件中出现的行
- 第三列:两个文件共有的行
comm 的基本语法如下:
comm [OPTION] FILE1 FILE2
注意:comm 要求输入文件已排序,因此通常需要配合 sort 命令使用。如果文件未排序,结果可能不准确。
常用选项包括:
-1:隐藏第一列(仅 FILE1 的行)-2:隐藏第二列(仅 FILE2 的行)-3:隐藏第三列(共有的行)--check-order:检查输入文件是否已排序--nocheck-order:忽略排序检查
2.2 示例演示
假设我们要比较 gnu 和 linux 文件的内容。首先确保文件已排序,这里使用进程替换将命令执行结果当作一个文件交给 comm:
comm <(sort gnu) <(sort linux)
输出结果(假设以制表符分隔):
Alpine LinuxAndroid
Arch Hurd
Debian GNU/HurdDebian GNU/Linux
Debian GNU/kFreeBSDGentoo
Guix SystemOpenWRTUbuntu
- 第一列:仅在
gnu中出现的内容 - 第二列:仅在
linux中出现的内容 - 第三列:共有的内容
如果只想查看 gnu 独有的内容:
comm -23 <(sort gnu) <(sort linux)
只查看交集:
comm -12 <(sort gnu) <(sort linux)
三、uniq:去重与重复行统计
3.1 用法与原理
uniq 命令用于处理文本中的重复行,通常与 sort 配合使用,因为它只检测连续的重复行。基本语法为:
uniq [OPTION] [INPUT [OUTPUT]]
常用选项:
-c:在每行前显示重复次数-d:只输出重复的行-u:只输出不重复的行-i:忽略大小写-f N:忽略每行前 N 个字段-s N:忽略每行前 N 个字符
3.2 示例演示
假设我们将所有测试文件合并为 all.txt:
cat gnu linux bsd unix > all.txt
统计每种系统出现的次数:
sort all.txt | uniq -c
输出:
1 AIX1 Alpine Linux1 Android1 Arch Hurd1 Debian GNU/Hurd2 Debian GNU/Linux2 Debian GNU/kFreeBSD1 DragonFly BSD2 FreeBSD1 Gentoo1 GhostBSD1 Guix System1 NetBSD2 OpenBSD1 OpenWRT1 Solaris1 Ubuntu1 macOS
其中,Debian GNU/kFreeBSD 出现了两次(在 gnu 和 bsd 中)。
只显示重复的行:
sort all.txt | uniq -d
输出:
Debian GNU/kFreeBSD
FreeBSD
OpenBSD
四、sort:文本排序的多面手
4.1 用法与原理
sort 命令用于对文本行进行排序,支持多种排序规则。基本语法为:
sort [OPTIONS] [FILE...]
常用选项:
-n:按数字排序-r:倒序排序-k:指定排序字段(例如-k2表示按第二列排序)-t:指定字段分隔符-f:忽略大小写-u:去重(等同于sort | uniq)-R:随机排序
4.2 示例演示
对 all.txt 按字典序排序:
sort all.txt
按行长度排序(结合 awk 预处理):
awk '{print length($0), $0}' all.txt | sort -n | awk '{$1=""; print $0}'
输出:
AIXmacOSGentooNetBSDUbuntuAndroidFreeBSDFreeBSDOpenBSDOpenBSDOpenWRTSolarisGhostBSDArch HurdGuix SystemAlpine LinuxDragonFly BSDDebian GNU/HurdDebian GNU/LinuxDebian GNU/LinuxDebian GNU/kFreeBSDDebian GNU/kFreeBSD
字段排序:对 /etc/passwd 按 UID(第 3 字段)排序:
sort -t: -k3,3n /etc/passwd
五、diff:文件差异分析的利器
5.1 用法与原理
diff 命令用于比较两个文件的差异,输出差异的行或生成补丁文件。基本语法为:
diff [OPTION] FILE1 FILE2
常用选项:
-u:生成统一格式(unified format)的补丁-c:生成上下文格式的补丁-y:并排显示差异(side-by-side)-r:递归比较目录--brief:仅报告是否有差异
5.2 示例演示
要比较 gnu 和 linux 文件并生成统一格式的补丁文件,我们可以使用以下命令:
diff -u gnu linux > gnu-linux.patch
输出补丁文件:
--- gnu 2025-06-06 17:25:23.430342856 +0800
+++ linux 2025-06-06 17:25:23.434342856 +0800
@@ -1,5 +1,6 @@
-Arch Hurd
-Debian GNU/Hurd
-Debian GNU/kFreeBSDDebian GNU/Linux
-Guix System
+Gentoo
+Android
+Alpine Linux
+OpenWRT
+Ubuntu
解读:
- 行首以
-开头的行(如Arch Hurd、Debian GNU/Hurd、Debian GNU/kFreeBSD、Guix System)表示仅存在于gnu文件中的内容。 - 行首以
+开头的行(如Gentoo、Android、Alpine Linux、OpenWRT、Ubuntu)表示仅存在于linux文件中的内容。 - 无标记的行(如
Debian GNU/Linux)表示两个文件共有的内容。 @@ -1,5 +1,6 @@表示差异的行范围:gnu文件从第1行开始有5行,linux文件从第1行开始有6行。
为了更直观地比较两个文件的内容,可以使用并排(side-by-side)格式:
diff -y gnu linux
输出如下:
Arch Hurd <
Debian GNU/Hurd <
Debian GNU/kFreeBSD <
Debian GNU/Linux Debian GNU/Linux
Guix System | Gentoo> Android> Alpine Linux > OpenWRT > Ubuntu
解读:
- 左侧列显示
gnu文件的内容,右侧列显示linux文件的内容。 - 共有的行(如
Debian GNU/Linux)对齐显示。 - 独有的行以
<(仅在gnu中)或>(仅在linux中)标记。 - 空行表示对方文件中没有对应内容。
虽然命令行中的并排输出便于快速查看,但对于大型文件或复杂差异,终端显示可能显得不够直观。此时,可以借助图形化工具进一步增强体验。推荐使用图形化工具如 Meld 或 Vimdiff:
meld gnu linux
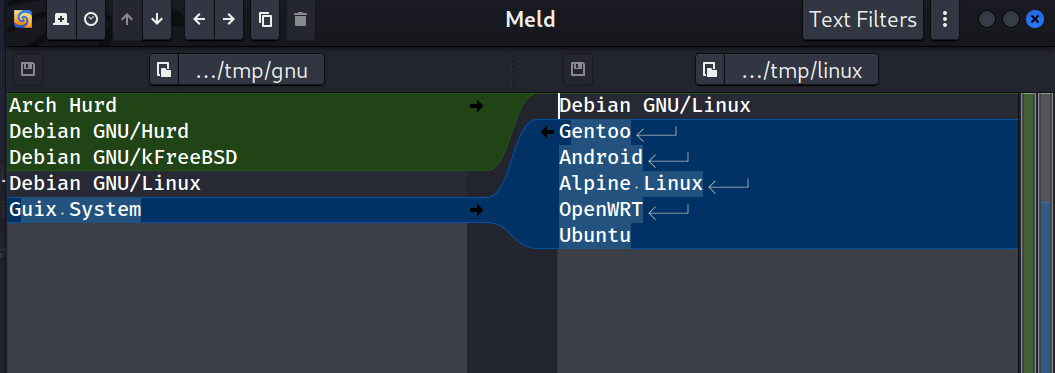
或者 Vimdiff,它是Vim 编辑器的内置差异模式:
vim -d gnu linux
六、patch:应用差异更新文件
6.1 用法与原理
patch 命令用于将 diff 生成的补丁应用到目标文件,实现内容的更新。基本语法为:
patch [OPTION] < PATCH_FILE
常用选项:
-pN:剥离 N 级路径前缀-R:反向应用补丁-i:指定补丁文件
6.2 示例演示
将 gnu-linux.patch 应用到 gnu 文件:
cp gnu gnu.bak
patch gnu < gnu-linux.patch
检查 gnu 文件内容,应与 linux 文件一致。
反向恢复:
patch -R gnu < gnu-linux.patch
patch 操作,即打补丁操作对于软件的开发是十分有用的,像对软件的源代码进行打补丁其实用的就是patch 这个命令,感兴趣的话可以自行深入学习。
七、工具间的协同工作
7.1 典型组合
这些工具的真正威力在于组合使用。以下是一些典型场景:
- 查找独有和共有内容:
comm -12 <(sort gnu) <(sort linux) > common.txt
comm -23 <(sort gnu) <(sort linux) > gnu-only.txt
comm -13 <(sort gnu) <(sort linux) > linux-only.txt
- 日志分析与去重:
cat access.log | sort | uniq -c | sort -nr > error-stats.txt
统计日志中重复错误并按次数倒序排列。
- 版本差异管理:
diff -u old.conf new.conf > config.patch
patch -p0 < config.patch
生成并应用配置文件补丁。
7.2 复杂实战:分析多文件交集与差异
假设我们需要找出所有文件中独有和共有的系统类型:
cat gnu linux bsd unix | sort | uniq -c > systems.txt
筛选出现多次的系统:
awk '$1 > 1' systems.txt
输出:
2 Debian GNU/kFreeBSD
进一步比较 bsd 和 unix 的差异:
diff -y bsd unix
输出:
FreeBSD | macOS
OpenBSD | AIX
GhostBSD | Solaris
Debian GNU/kFreeBSD <
7.3 工具间的依赖关系
sort是基础:comm和uniq依赖已排序的输入。diff和patch成对使用:diff生成补丁,patch应用补丁。- 管道连接:通过
|将工具串联,形成数据处理流水线。