自然语言处理——卷积神经网络
自然语言处理——卷积神经网络
- 概述
- 卷积
- 二维卷积
- 卷积神经网络
- 文本卷积神经网络
概述
由于词向量的平均无法考虑词序,会出现“猫吃鱼”和“鱼吃猫”这样子的不同句子但是嵌入到向量空间中却完全相同的例子,因此基于词向量的前向神经网络模型就应运而生了。
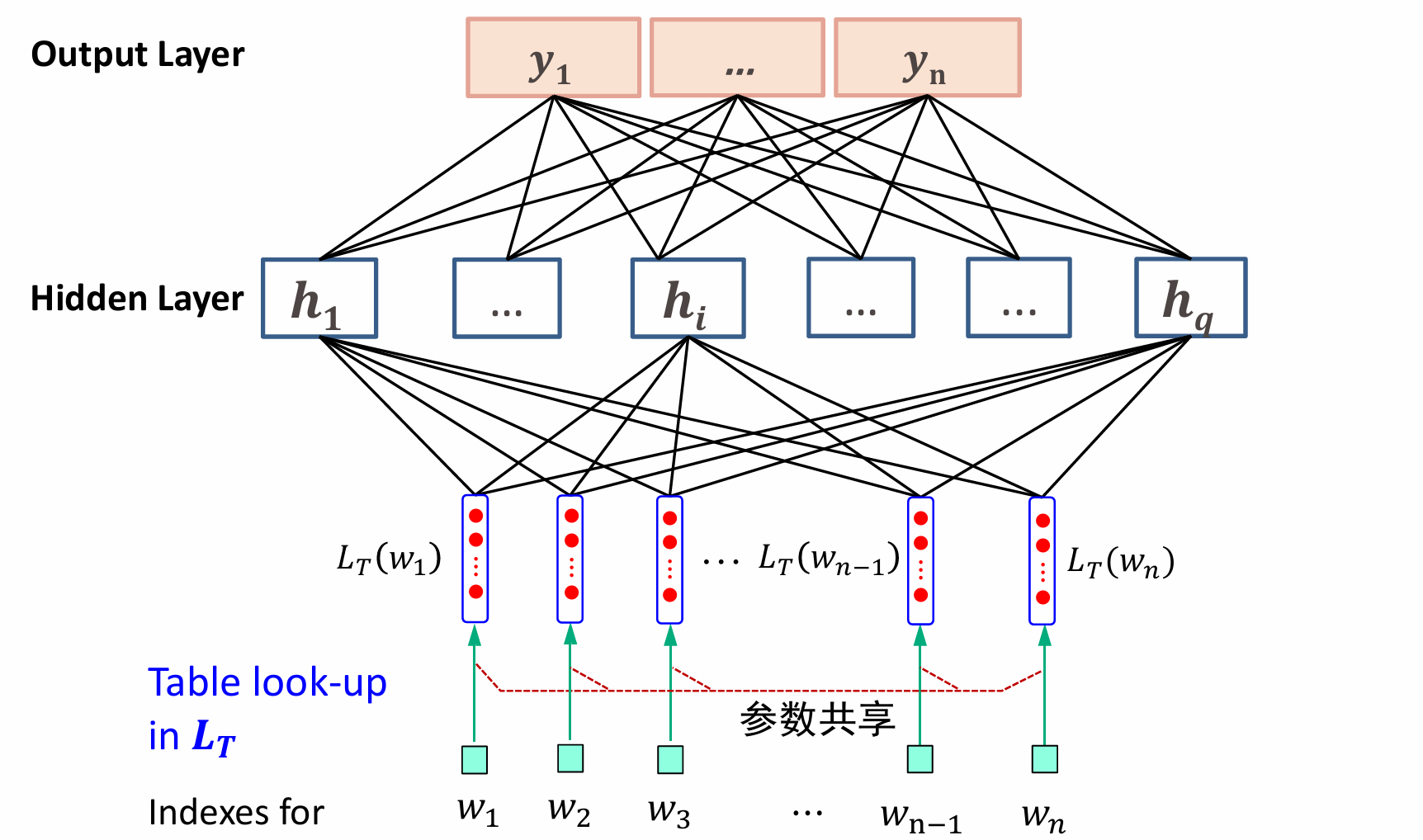
举一个简单的应用:情感分类应用:预测文本的情感倾向(正面vs中立vs负面)
- 使用词向量作为输入(300维)
- 文档最大长度512(长度不足时padding)
- 假设隐藏层神经元个数设为100个
H=f(Wx+b),H维度为100,W维度为15.36w*100=1536w,这导致了一个问题:权重矩阵的参数量很大。
解决方法:提出参数共享,相比于网络每个部分都拥有独立的权重集,共享参数可以显著减少参数的总量。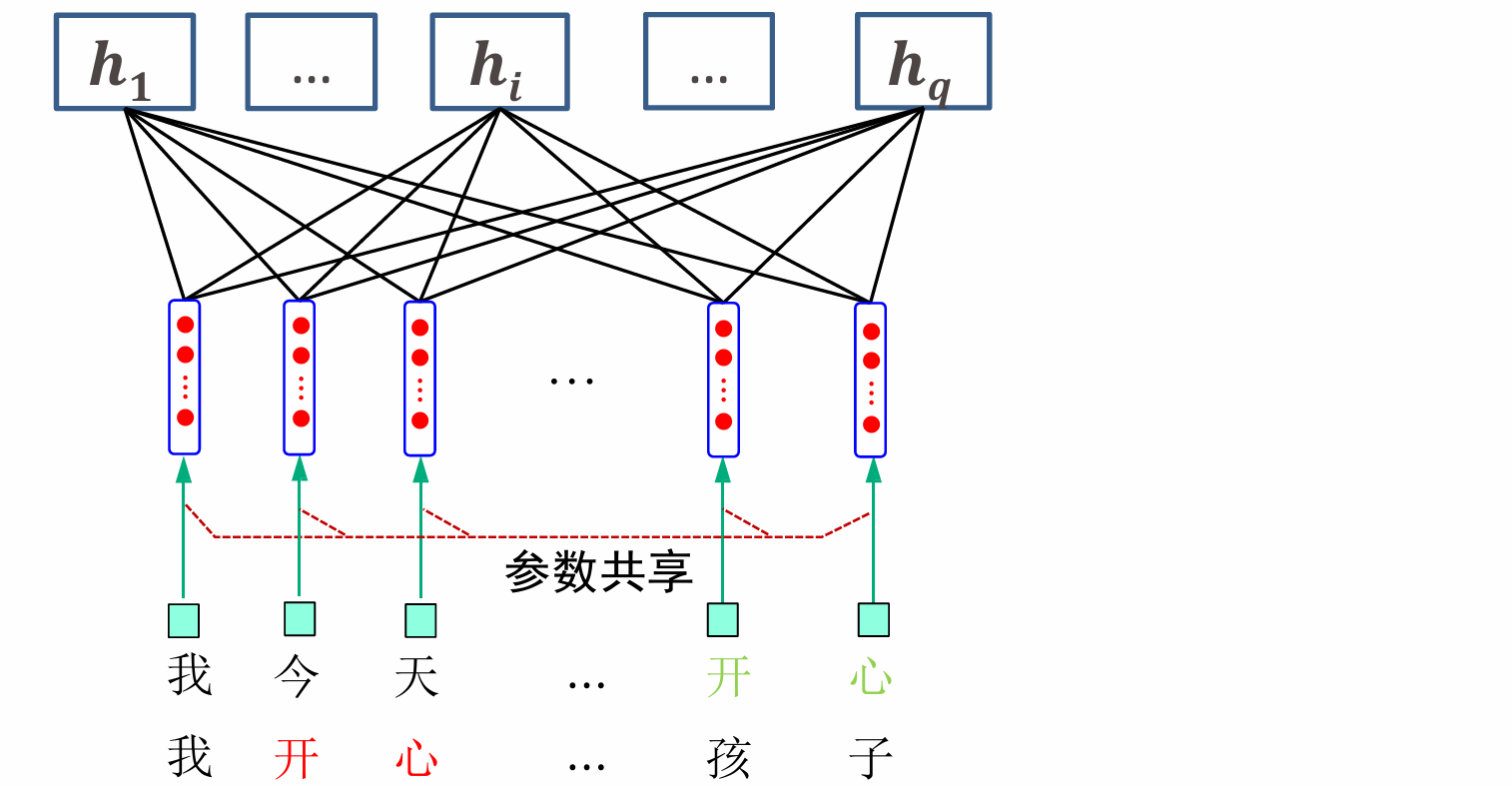
局部不变性特:自然语言中的短语一般而言具有局部不变性特征,即出现在句中不同位置一般不影响其语义信息,在上图中我们希望"开心"的位置映射到隐藏层之后是同样的位置,很明显在FNN中很难捕获局部不变性特征。
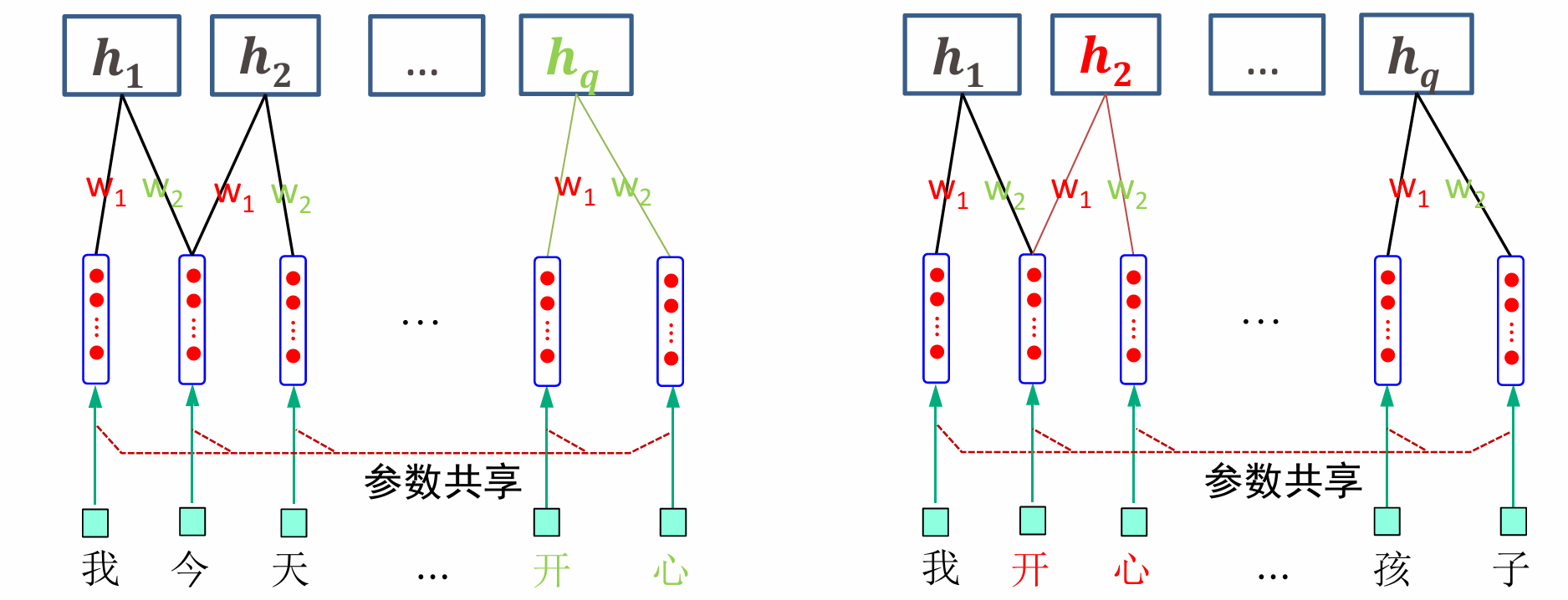
解决方案:局部连接,每个隐藏层神经元只与局部输入相连,同样的 w 1 、 w 2 w_1、w_2 w1、w2同样也是全局共享的,这样子不仅可以降低参数量还可以让 h q = h 2 h_q=h_2 hq=h2。
卷积
给定一个输入信号序列: 𝑥 = [ 𝑥 1 , 𝑥 2 , 𝑥 3 , … , 𝑥 d ] 𝑥= [𝑥_1, 𝑥_2, 𝑥_3, …, 𝑥_d] x=[x1,x2,x3,…,xd]
滤波器filter(或者卷积核convolutional kernel): 𝑤 = [ w 1 , w 2 , … , w K ] 𝑤= [w_1, w_2, …, w_K] w=[w1,w2,…,wK]
在t时刻的卷积结果为第t个时刻以及前K-1个时刻信息的叠加 y t = ∑ u = 1 K w K − u + 1 x t − u + 1 y_{t}=\sum_{u=1}^{K} w_{K-u+1} x_{t-u+1} yt=u=1∑KwK−u+1xt−u+1
假设 𝑤 = [ w 1 , w 2 , w 3 ] 𝑤= [w_1, w_2, w_3] w=[w1,w2,w3],卷积的输出为: y t = w 1 x t − 2 + w 2 x t − 1 + w 3 x t y_{t}=w_{1} x_{t-2}+w_{2} x_{t-1}+w_{3} x_{t} yt=w1xt−2+w2xt−1+w3xt
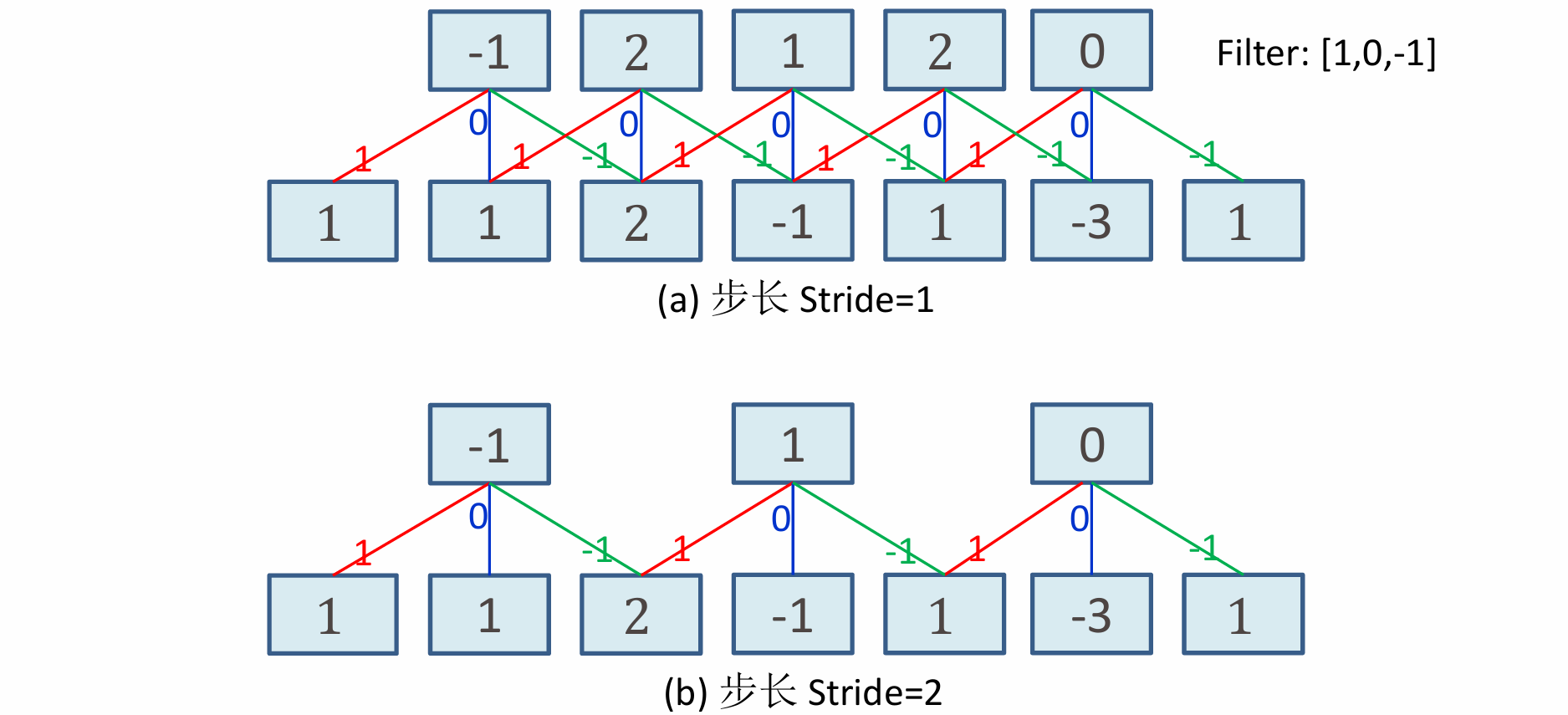
下图为步长=1和步长=2的情况下卷积的结果。
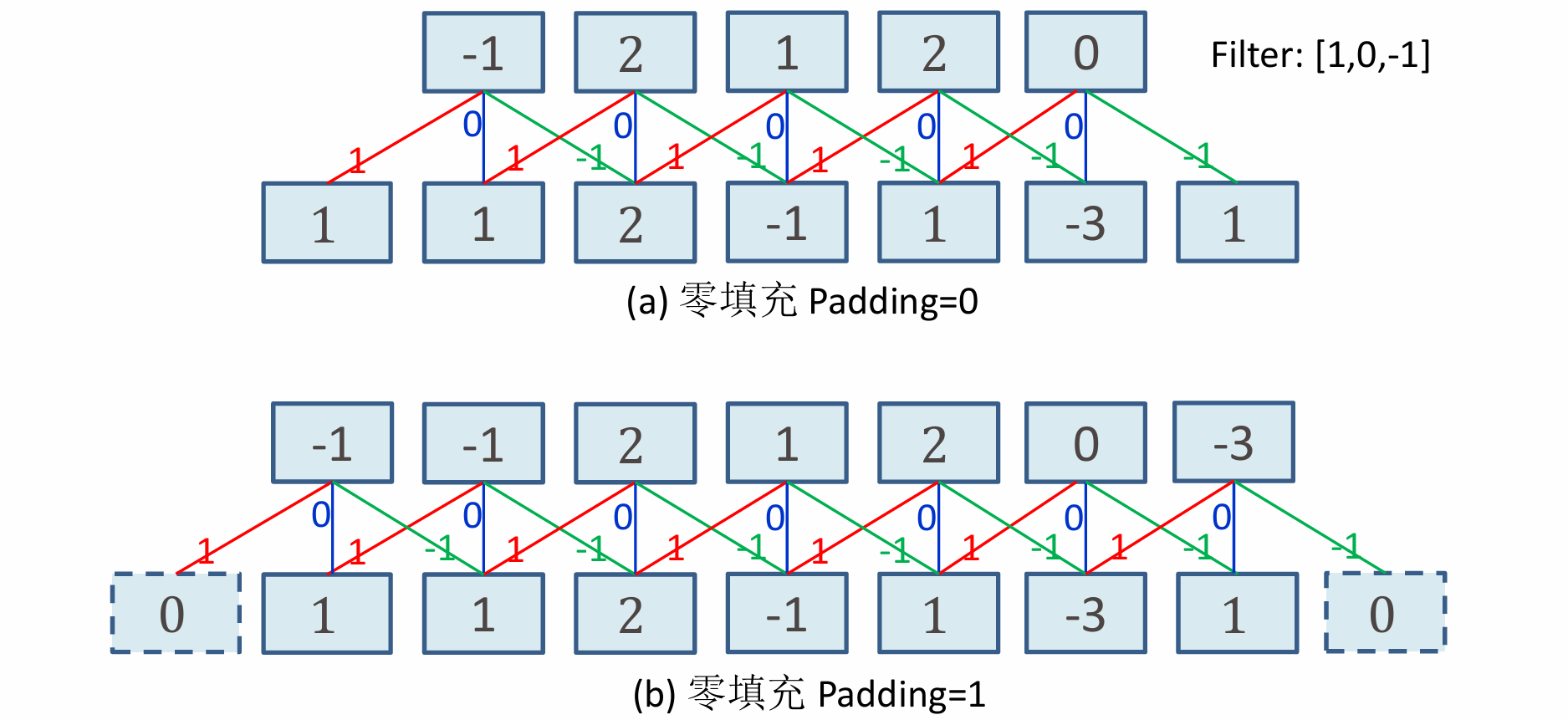
再卷积中,Padding也是一个常有的操作,Padding在神经网络中主要是为了保持输入数据的空间尺寸,防止信息损失,并使网络能够构建更深更复杂的结构。下图为Padding=0和Padding=1的情况下卷积的结果。
输入长度为M的序列卷积的结果长度为 L = ⌊ ( 𝑀 + 2 ∗ 𝑃 − 𝐾 ) / 𝑆 + 1 ⌋ L=⌊(𝑀+2∗𝑃−𝐾)/𝑆+1⌋ L=⌊(M+2∗P−K)/S+1⌋
卷积的结果按输出长度不同可以分为三类:
- 窄卷积:步长S= 1 ,两端不补零𝑃= 0 ,卷积后输出长度为𝑀− 𝐾+ 1
- 等宽卷积:步长S= 1 ,两端补零𝑃=(𝐾− 1)/2 ,卷积后输出长度𝑀
- 宽卷积:步长S = 1 ,两端补零𝑃= 𝐾− 1 ,卷积后输出长度𝑀+ 𝐾− 1
二维卷积
在图像处理中,图像是以二维矩阵的形式输入到神经网络中,因此我们需要二维卷积。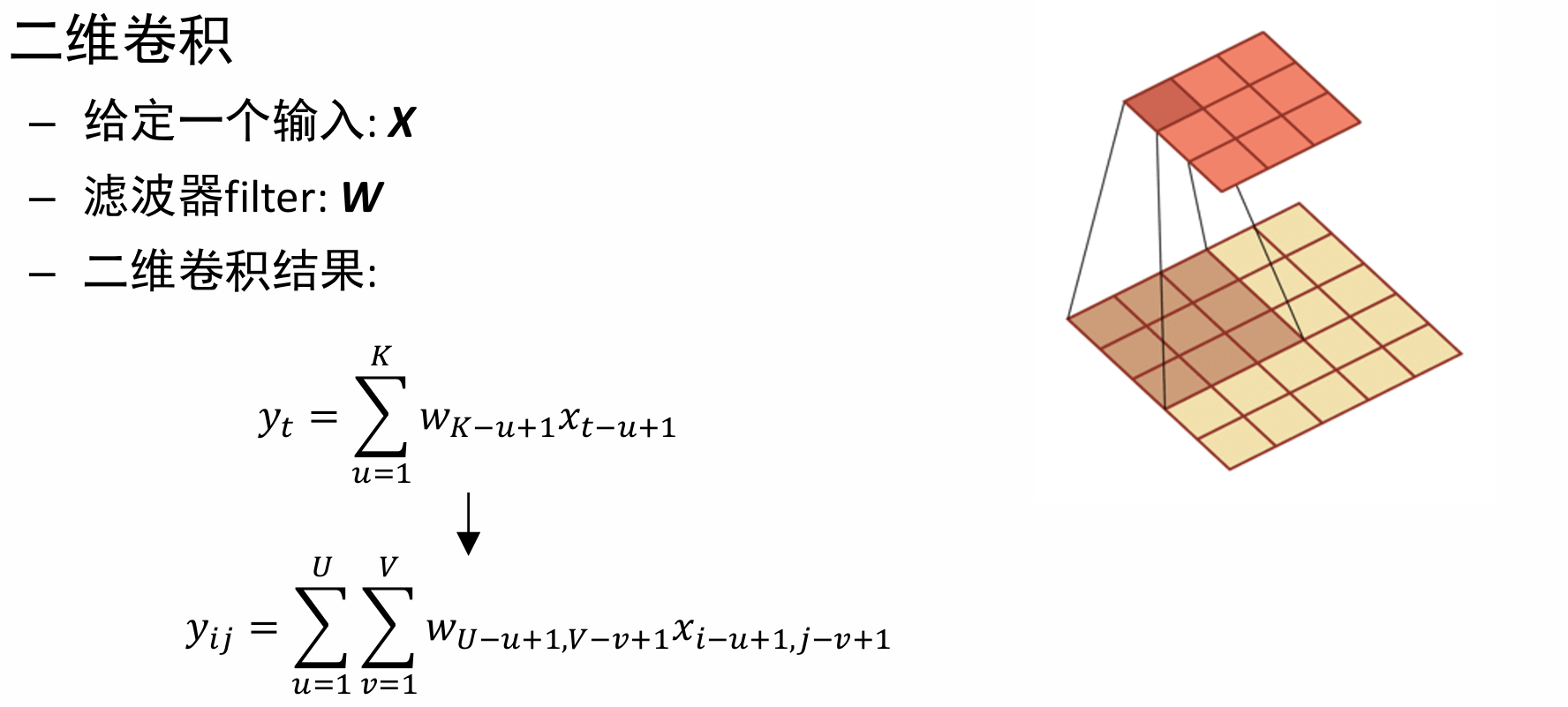
Stride步长情况和Padding情况的处理与一维卷积相似,在此不多赘述。
卷积神经网络
将全连接层替换为卷积层:引入空间信息感知能力和参数共享,从而减少模型参数、增强特征提取的局部性和平移不变性,并允许输入尺寸的灵活性。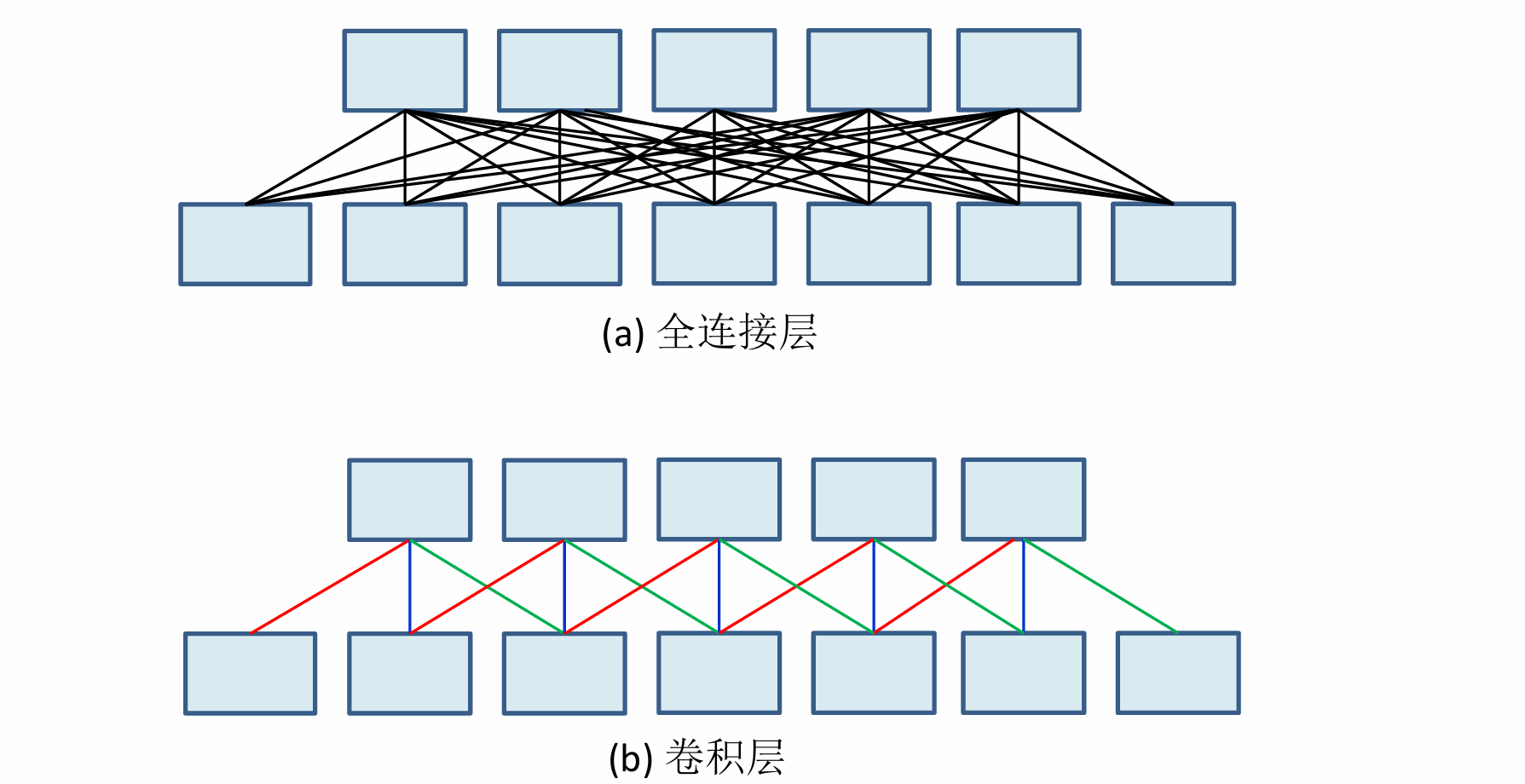
卷积过程中,我们可以把卷积核作为一个特征提取器,如何增强卷积层的能力?引入多个卷积核!每个卷积核提取到不同的特征,从而让卷卷积神经网络模型性能提升!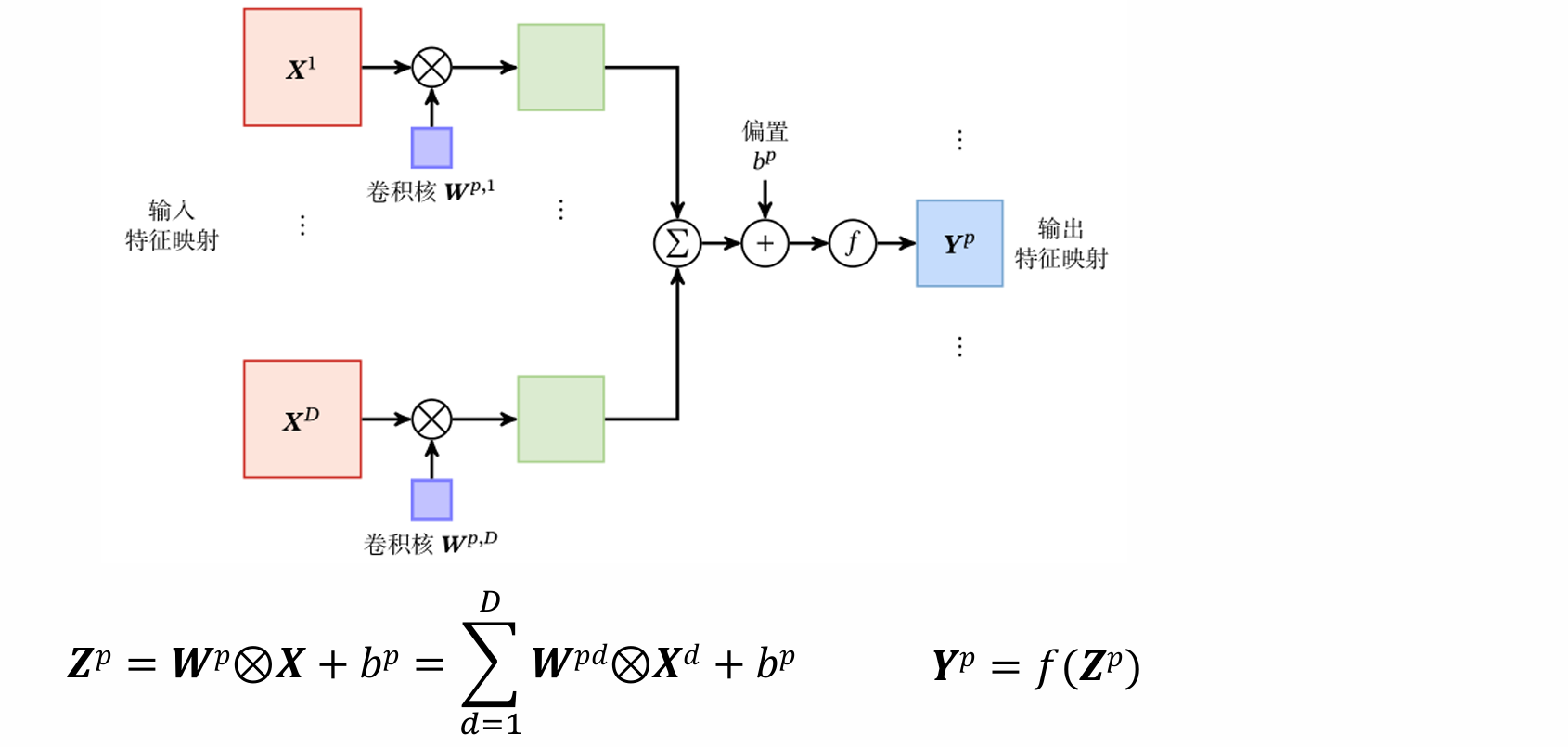
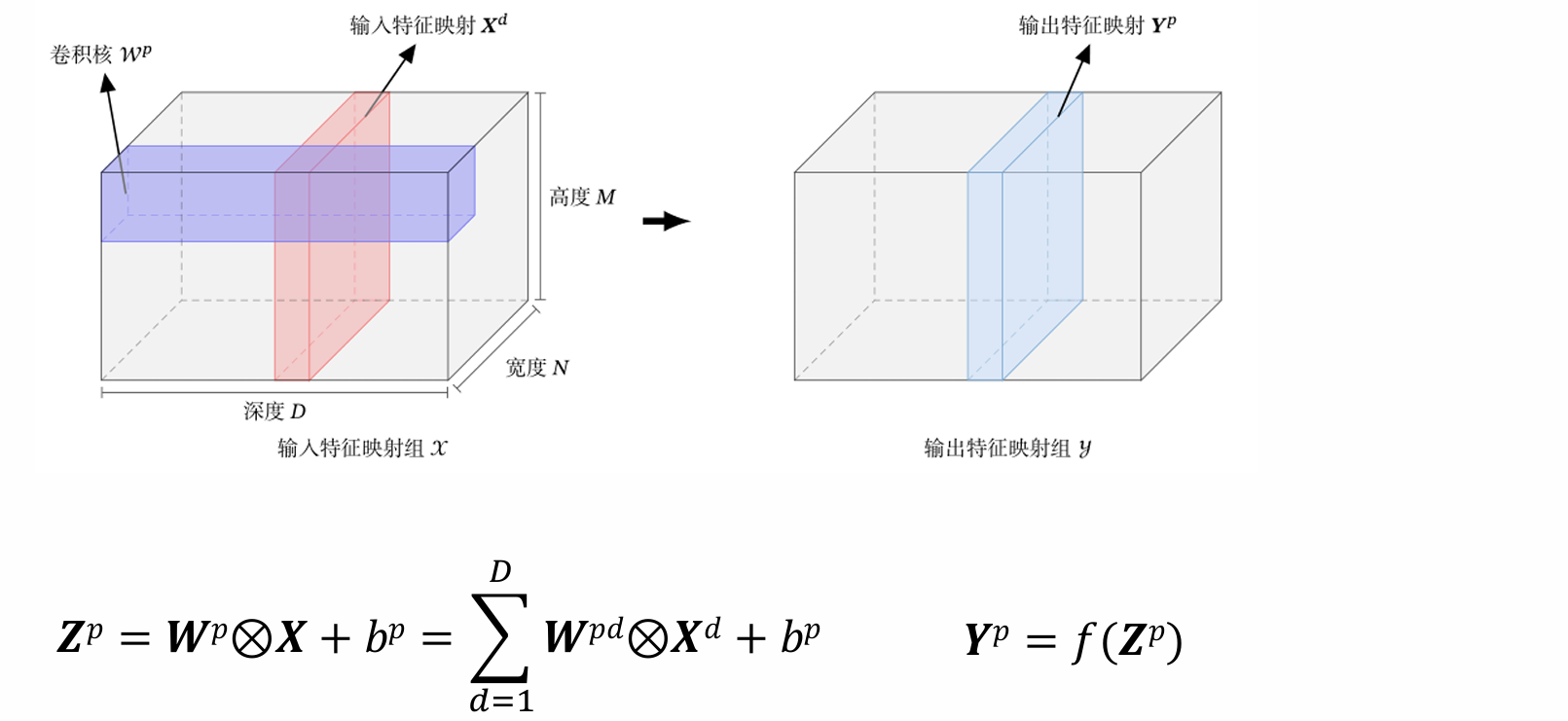
卷积层:典型的卷积层为3维结构。
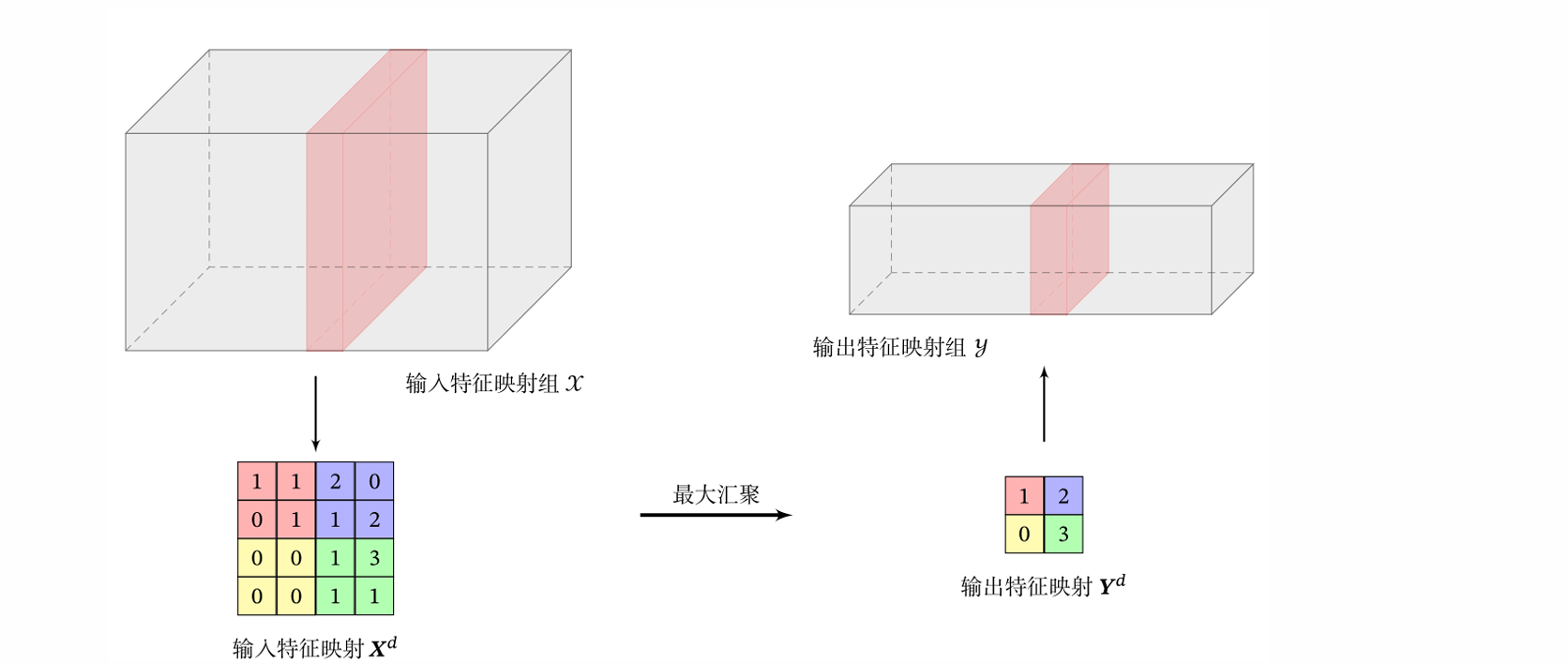
汇聚层(也叫池化层,Pooling Layer):卷积层虽然可以显著减少连接的个数,但是每一个特征映射的神经元个数并没有显著减少。池化层通过对特征图(Feature Map)进行下采样(downsampling),显著减少了数据的空间尺寸(宽度和高度),从而降低了模型的计算复杂度和所需参数数量。这有助于提高训练效率和推理速度。池化主要分为两种,一种是最大池化,另一种是平均池化。
卷积网络是由卷积层、汇聚层、全连接层交叉堆叠而成,汇聚层可以视作特殊的卷积层。
一个卷积块为连续M 个卷积层和b个汇聚层(M通常设置为2 ∼ 5,b为0或1)。一个卷积网络中可以堆叠N 个连续的卷积块,然后在接着K 个全连接层(N 的取值区间比较大,比如1 ∼ 100或者更大;K一般为0 ∼ 2)
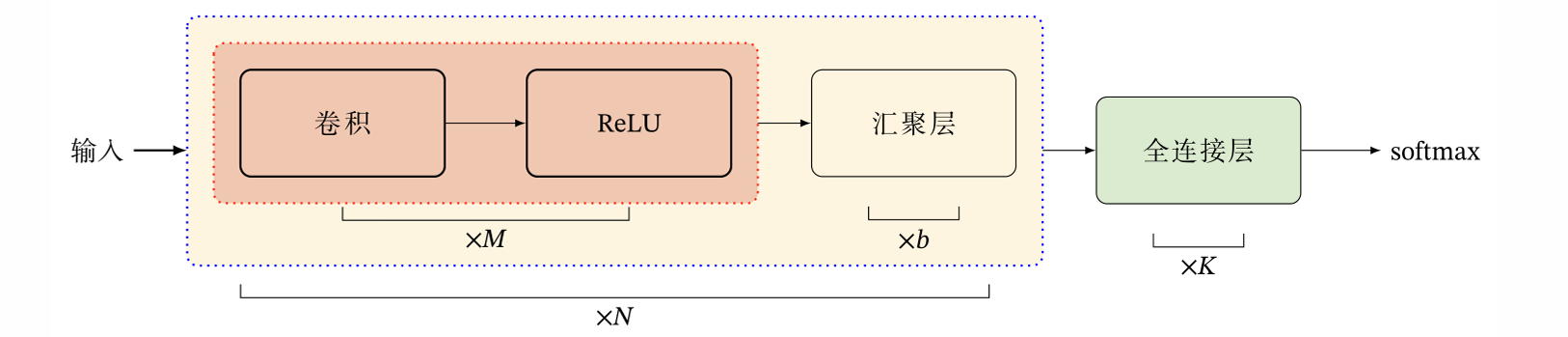
现如今的卷积典型结构趋向于小卷积、大深度,并且还趋向于全卷积。
文本卷积神经网络
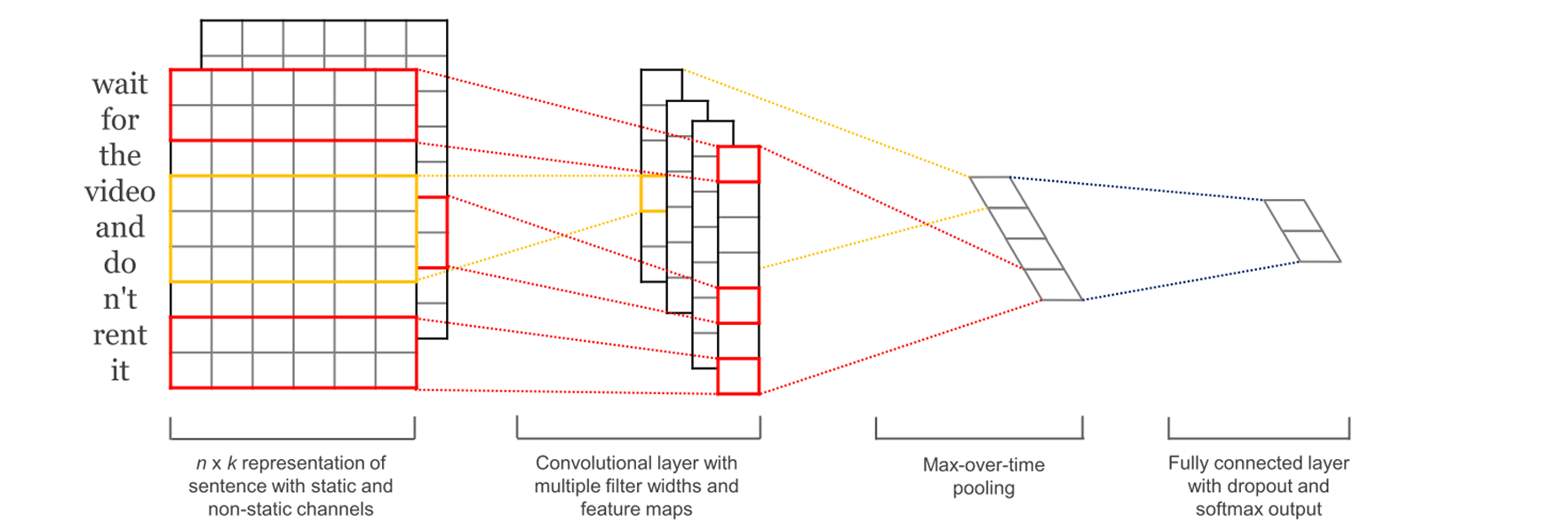
文本卷积中仍然通过一个数字组成的d维向量来表示一个单词,即词向量,下图是一个简单的例子。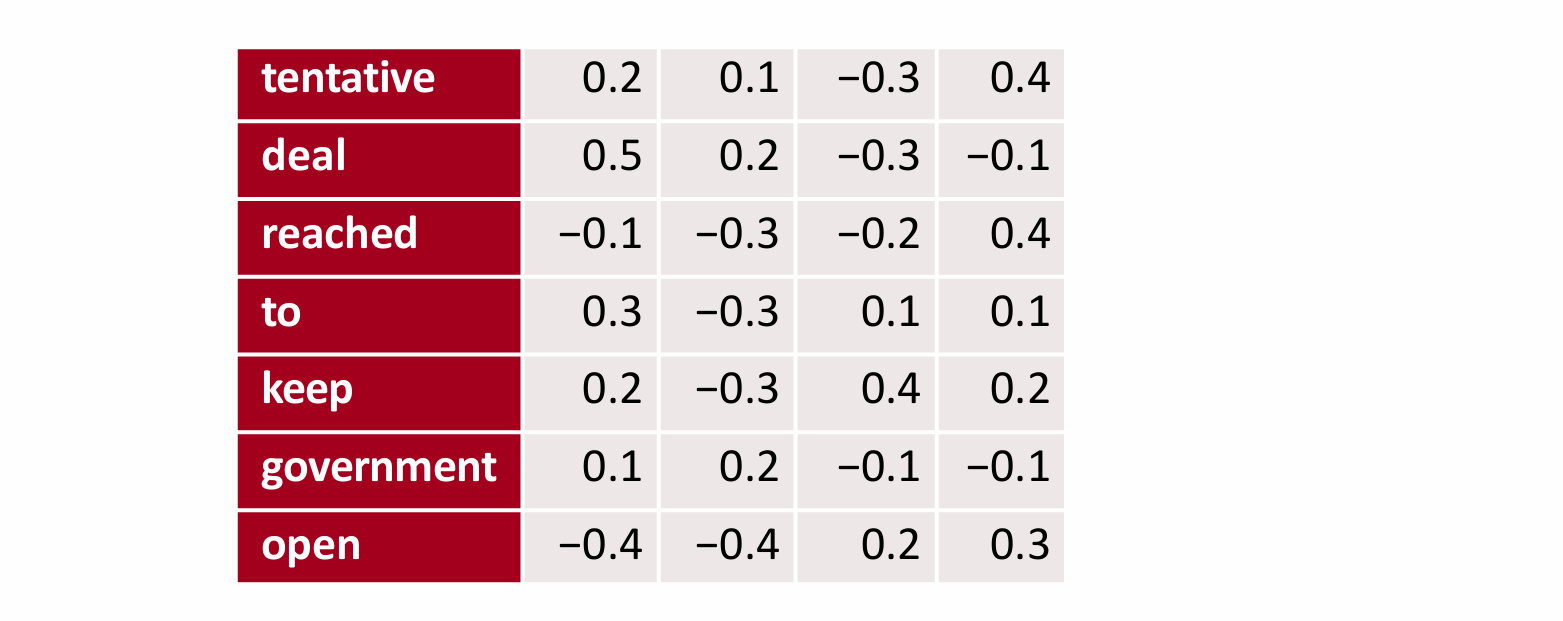
在卷积的过程要注意:不可以用3*3的卷积核来卷积,这样子会拆开单词。所以在文本卷积的过程中,有一维需要固定,从上往下进行卷积即可,本例中的卷积核可以设置为3*4的矩阵,这样子就可以不用把单词拆开了。
一般来说文本处理中stride一般会设置为1,因为句子长度一般会比较短(不超过50)