第三章 k近邻法
3.1 简介
3.1.1 直观理解
k近邻法(k-nearest neighbor,k-NN)顾名思义,就是k个相邻的邻居,这说明我们如果给定一个新的实例的时候,它是要根据最近的k个邻居来决定。
k近邻法是一种基本的分类与回归方法。主要思想是:假定给定一个训练数据集T,其中实例给定,当输入新的实例x时,可以根据其最近的k个训练实例的标签,预测新实例x对应的标注信息。
对于分类问题:对新的实例,根据与之相邻的k个训练实例的类别,通过多数表决等方式进行预测。也就是说,在这k个训练实例里面所属的哪一种类别占比最大,那么这个新的实例点就属于哪一个类别,这也可以称作是大概率事件。
对于回归问题:对新的实例,根据与之相邻的k哥训练实例的标签,通过均值计算进行预测。
下面我们通过一个图形进行简单直观的理解:
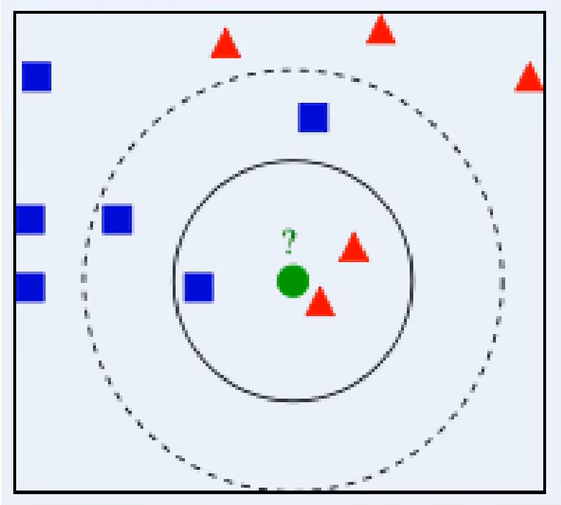
在这里,我们给定了11个训练样本,其中包括6个蓝色正方形,5个红色三角形。现在,假如给定一个新的实例,即绿色圆形,那么这个绿色点属于哪个类别呐?
如果这时候,k=3,那么在这个二维的图形里面,我们计算与这个绿色圆最近的三个点是一个蓝色的方框和两个红色的三角形。在这里,红色三角形所占的比例是2/3大于蓝色正方形所占比例的1/3。所以,可以认为这个绿色圆是属于红色三角形这个类别。
假如k=5,那么与绿色圆最近的5个点就是这三个蓝色正方形和两个红色三角形,这时候蓝色正方形所占比例是3/5,红色三角形所占比例是2/5,也就是多数是属于蓝色正方形类别的,所以根据多数表决规则,认为绿色圆点是属于蓝色正方形。
我们从这个例子可以看出,当k的值不一样时,绿色圆点所属的类别也有可能是不一样的;而且我们这里考虑的是一个二维平面,所以距离定义就是普通的一个欧式距离,如果我们换一种距离定义方式,这里绿色圆点所属的类别可能就会发生变化。
3.1.2 算法
假设我们输入一个训练集,其中
,类别
。如果给定实例x;希望输出:实例x所属类别y
具体算法包含三步:
(1)给出一种距离的度量方式,根据给定的距离度量方法,计算新的实例x与T中每个点的距离.
(2)找出与x最相近的k个点,这k个点都是位于训练集T中。我们将包含这k个点的x的邻域记作
(3)在中根据分类决策规则(如多数表决)决定x的类别y
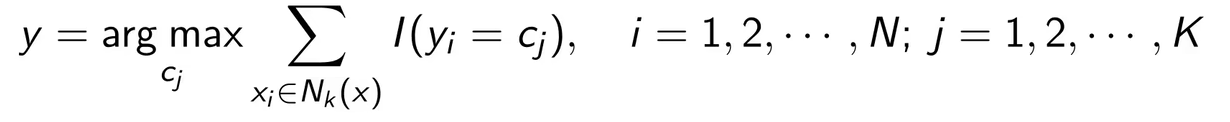
3.2.1 k近邻法模型
对于k近邻法,它的模型主要是由距离度量、k-值的选择以及分类决策规则决定的,这三个就是构成k近邻算法的三要素。
k近邻法的模型实际上是对训练数据集所对应的特征空间进行了一个划分,每当给定一个新的实例时候,它可以通过最相近的k个邻居决定它所属分类,那么k近邻法就不具有显性的学习过程,所以我们也称这种学习方法为Lazy Learning。下面我们通过一个例子具体看一下k近邻法的模型是什么样子的。
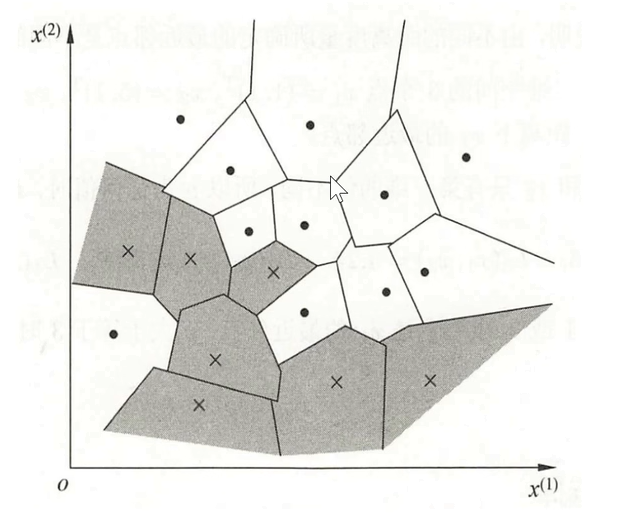
这里的特征空间是二维的,我们考虑k近邻法。训练数据集包含了两类,一个是点所代表的类,一个是叉所代表的类,对于每一个训练示例,我们都画出了它的邻域,也就是划分。当给定一个新的输入实例时,它的类别将由这些划分或者这些小的子空间决定。
那么这一个个小的子空间是怎么划分出来的呐?这就需要考虑k近邻法的三要素了,也就是我们之前说的距离度量、k-值的选择以及分类决策规则,我们具体看一下这三个要素。
3.2.2 三要素
3.2.2.1 距离度量
我们先给出一般的距离,假如特征空间位
,对于这个特征空间中的任意两个点
,
,
,则有
,
。
我们日常所说的距离其实就是欧氏距离,它所对应的就是p=2的情况。
当p=1时,就是曼哈顿距离。
当p=∞时,我们称之为切比雪夫距离。
下面我们通过一个例子来说明距离。假设我们考虑两点之间的距离,也就是点
到原点
的距离,我们来看看
所对应的图形是什么样的。
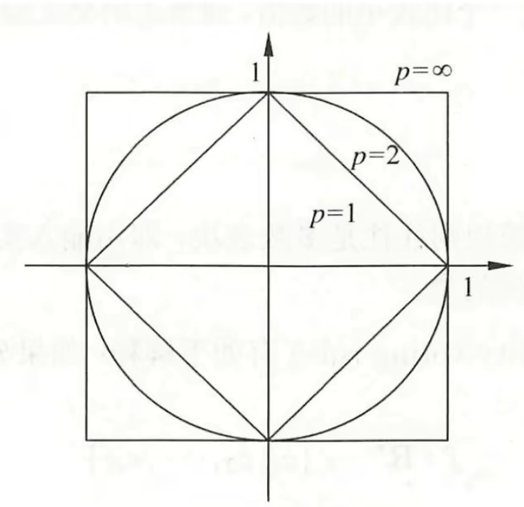
先看p=2的情况,代入可得。对于这个式子,恰好就是以原点为中心,半径为1的单位圆;而p=1时,
;当p=∞时,
。这说明不同的p对应着不同的距离的定义。
我们具体看一个例子:
已知二维空间中的三个点:,求p取不同的值时,
的最近邻点。
当p=1时,,
,此时:
是最近邻点。当p=2时,
,
,此时:
是最近邻点。当p=3时,
,
,此时:
是最近邻点;当p=4时,
,
,此时:
是最近邻点。当p>4时,
,
,此时:
是最近邻点。当p=∞,
,
,此时:
是最近邻点。
因此,p=1,2时,是最近邻点;p≥3时,
是最近邻点。这说明不同的距离度量,它所确定的最近邻点也是不同的。
3.2.2.2 k-值的选择
在之前这个例子中,我们知道当k=3时,绿色圆点是属于红色三角形类别;当p=5时,绿色圆点是属于蓝色正方形类别。
如果我们选择的k值比较小,相当于在一个比较小的邻域内,对于训练数据集中的实例进行预测,此时每一个点都由它最相近的极少的点决定类别,所以近似误差是比较小的,但是如果我们给定一个新的实例,它依然由附近比较少的k个点决定类别,有可能所属类别是错误的,这时候的估计误差其实是相对增大的,敏感性增强,而且模型复杂,容易过拟合。
如果我们选择的k值较大,那么就相当于在一个比较大的邻域里面对训练集的实例进行预测,这时候可以减少学习的估计误差,也就是当我们给定一个新的实例点的时候,这时候判断出差错的可能性会小一些,当然给定一个新的实例,它有可能受到距离它较远的一个训练实例点的影响,所以近似误差有可能增大,不过由于我们选择的k值比较大,这时候模型是比较简单的,如果考虑极端情况k=N(N代表训练数据集中样本的个数),那么这时候每给定一个新的实例点,它的类别都是由这个训练数据集中所包含最多样本的那个类别决定的,这时候的模型过于简单,完全不可行。
在这里,我们有两条建议:k的取值可以通过交叉验证的方法进行选取,k的取值是比较小的,一般低于训练数据集样本量的平方根。
3.2.2.3 分类决策规则
分类决策规则一般采取的是多数表决规则:由多个输入实例的k个邻近的训练实例中的多数类决定输入实例的类。