【Java】谈谈HashMap
一,概述
网上关于HashMap解析众多,笔者不妨再多添一篇,以更进一步加深此数据结构的理解。
所谓的HashMap,在Java中,是采用数组(散列表)+链表方式(hash冲突)实现,它是线程不安全的,并且具备自动扩容特性。在java8之后,满足一定条件的链表,会被转换为红黑树,以提高查询效率。那么,先给出几个问题,笔者将带着这这个问题阅读源码。
1,散列表下标如何确认?
2,什么时候会扩容散列表?
3,什么时候转换节点红黑树?
4,红黑树节点值的比较原则?
二,实现
1,散列表下标确认

首先,将key原本hash进行均匀分布,高位右移16位后,与原hash值做与或运算,这是经过均匀加工的hash,进一步确认下标是将散列表长度与计算的hash做与运算,保证不会越界。
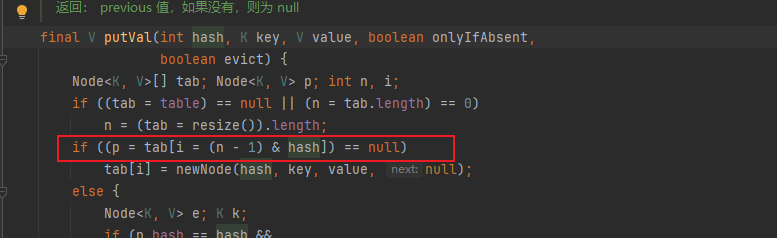
即index = (tab.length - 1)&( (obj.hashcode() >>> 16)^ obj.hashcode() );
2,扩容散列表
核心实现是resize函数,
该函数两个作用,1是初始化散列表,2是扩容当前散列表(两倍扩容,最多到2^30),
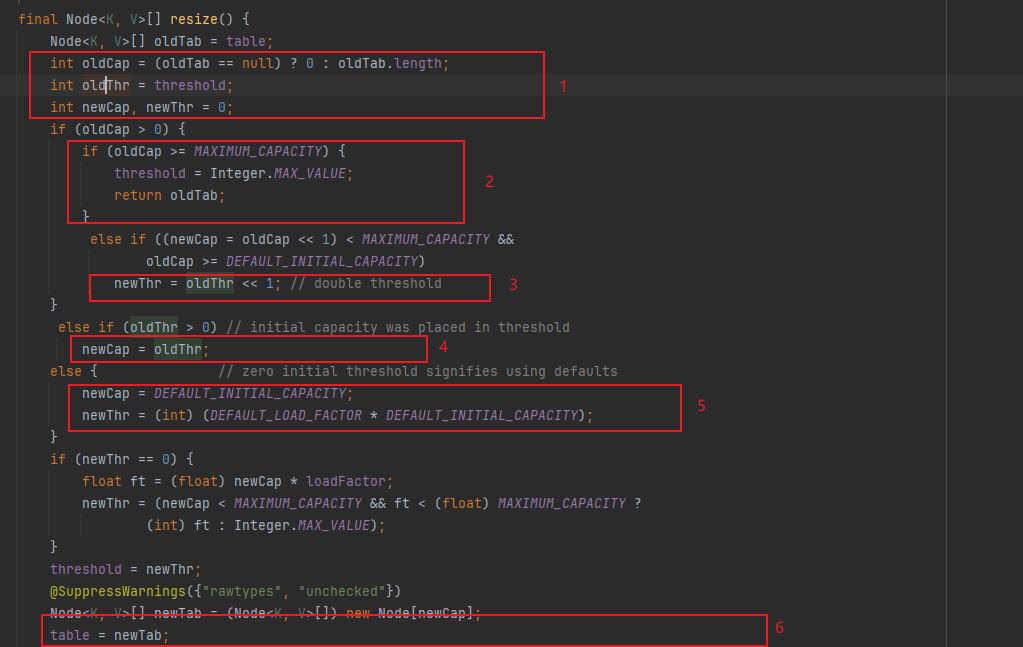
先看resize前半段,
1,保存当前散列表长度、阈值字段
2,如果存在已有散列表,且散列表长度已经到达1 << 30,即2^30,则不再进行扩容,将阈值赋为最大整数,
3,如果当前可以扩容,则将扩容阈值加倍,即x2,
4,如果是初始化散列表,且存在旧阈值,散列表长度直接取扩容阈值
5,默认初始化,默认长度16,默认扩容因子0.75


否则,按照给定的loadFactor和newCap进行初始化,

随后,通过计算出的newCap和newThr,保存成员threadhold和table,表示扩容阈值(散列表已占用数的最大值),散列表本身(一个Node<K,V> 数组)
以上逻辑不管初始化还是扩容,均创建了一个table,而对于扩容,其oldTab不为null,则进行扩容操作,即resize后半段逻辑
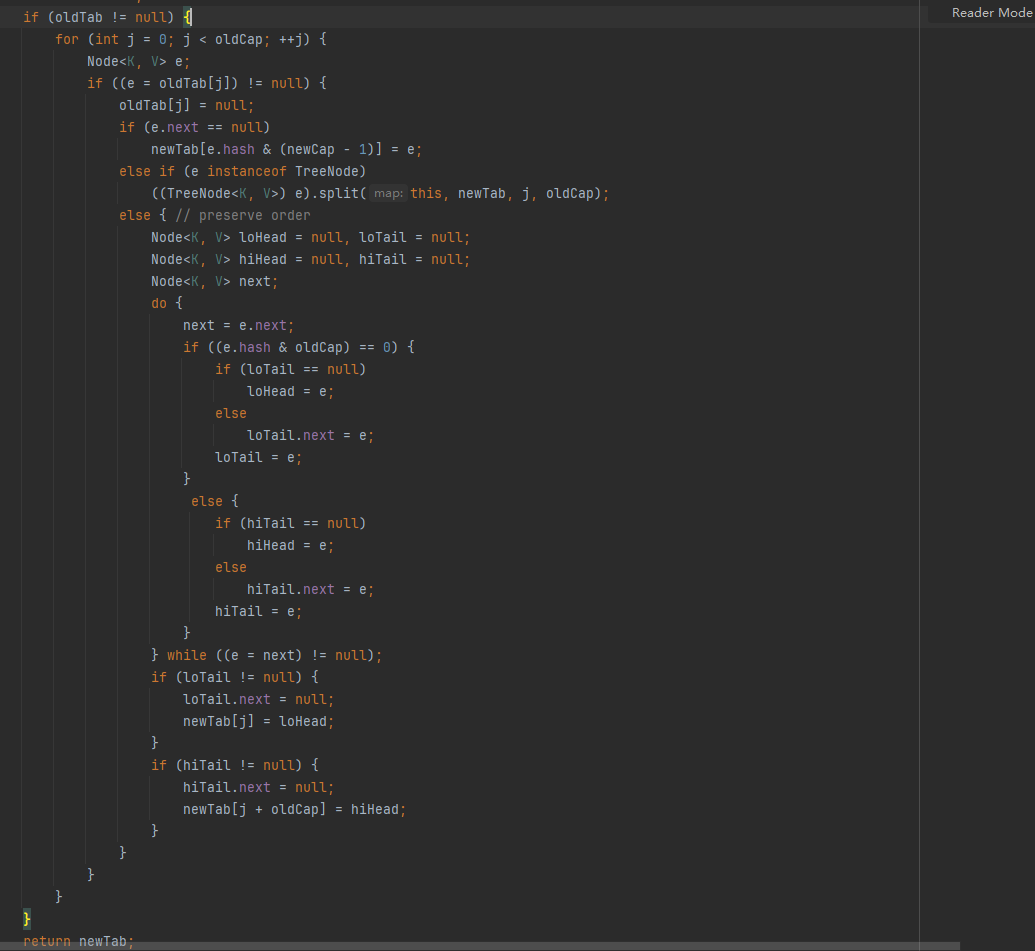
扩容后,各节点链表仍与扩容前一致,只是对新put的key,减小了hash冲突。
3,put
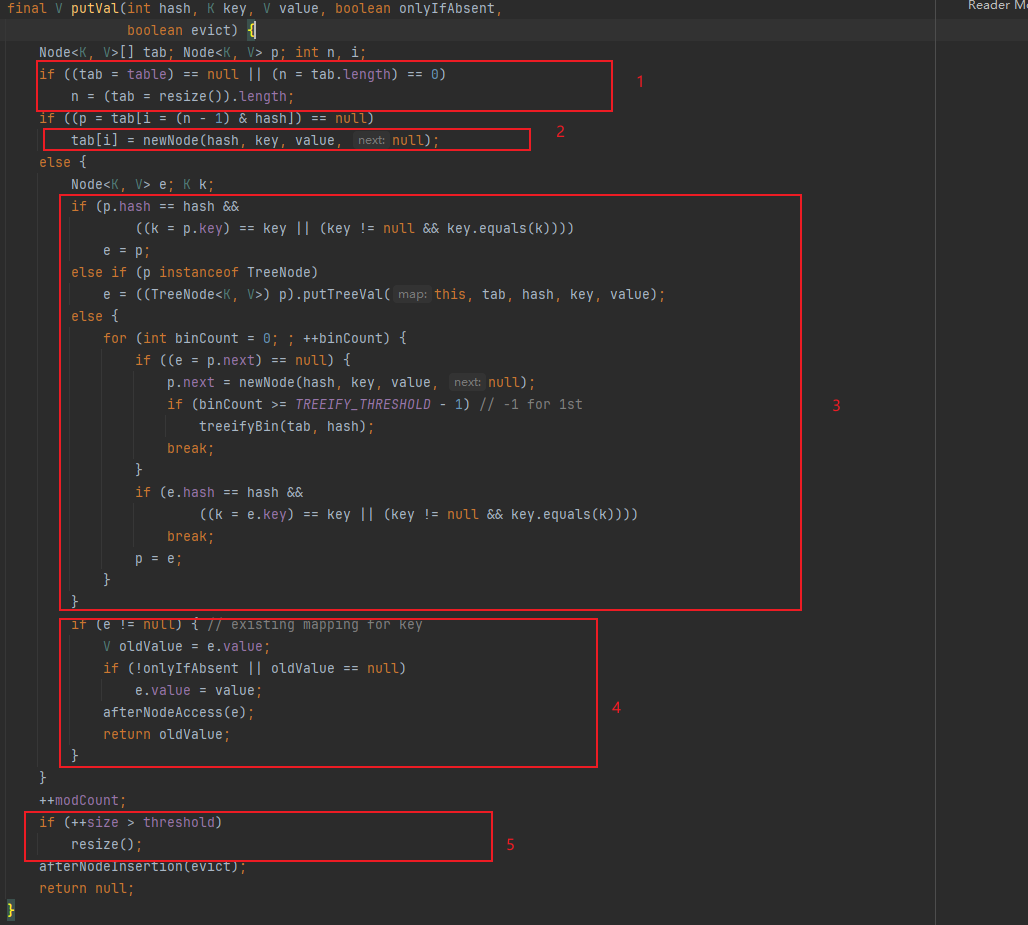
散列表下标及其resize逻辑确认后,直接看下put实现,
1,如果散列表不存在,初始化散列表
2,如果不存在节点值,直接new一个Node传入tab即可
3,主要逻辑是从节点链表或红黑树中找到节点e,为空则表示不存在key,并且附treely操作。
a,先对头节点判断,
b,如果当前节点已经是TreeNode,委托putTreeVal方法加入红黑树
c,遍历链表,直至找到一个e,并且记录链表长度,并通过TREEIFY_THRESHOLD判断是否触发treely操作,阈值是8
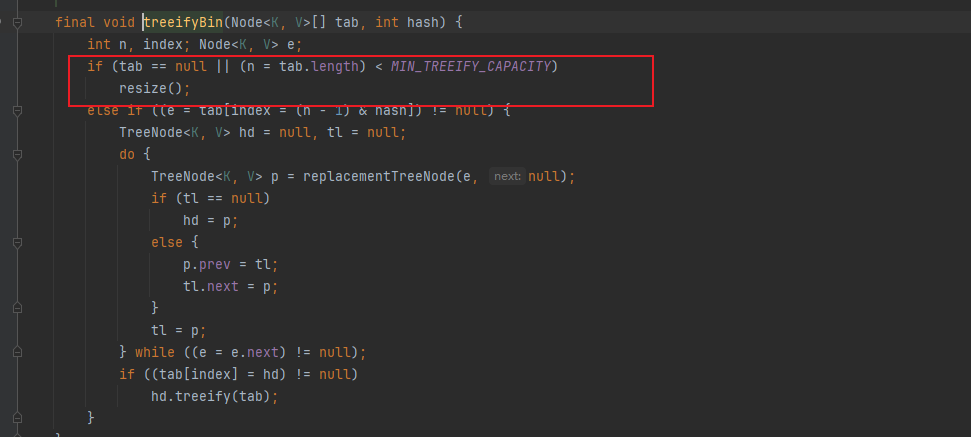
注意,并非一定会转化红黑树,也可能是resize,看下treeifBin实现,tab.length<MIN_TREEIFY_CAPACITY(64),只会走resize,
4,如果存在key,则根据onlyIfAbsent参数赋值,并且返回旧值(此处无需resize,毕竟size未+1)
5,e==null,根据扩容阈值判断是否resize,并且返回null,
4,get
写操作分析ok,读操作便简单多了

跟进getNode,
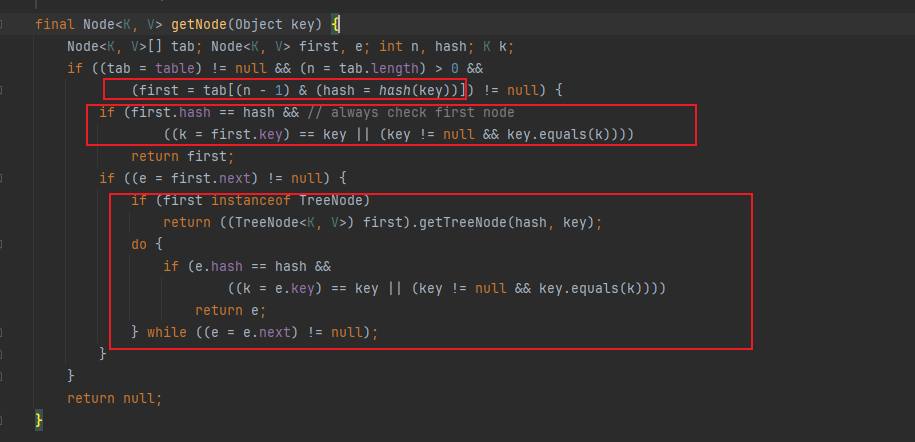
1,获得散列表第一个节点first,检查第一个节点是满足条件并返回
2,如果已是TreeNode,委托Tree查询
3,如果仍是Node,遍历链表查询即可,
5,treely
从put中可知,当满足链表长度>=8 && tab.length >= 64时,会触发链表转红黑树操作,读者思考一个问题,转红黑树必须对节点值进行比较,那么怎么比较?key签名可是一个Object呢,
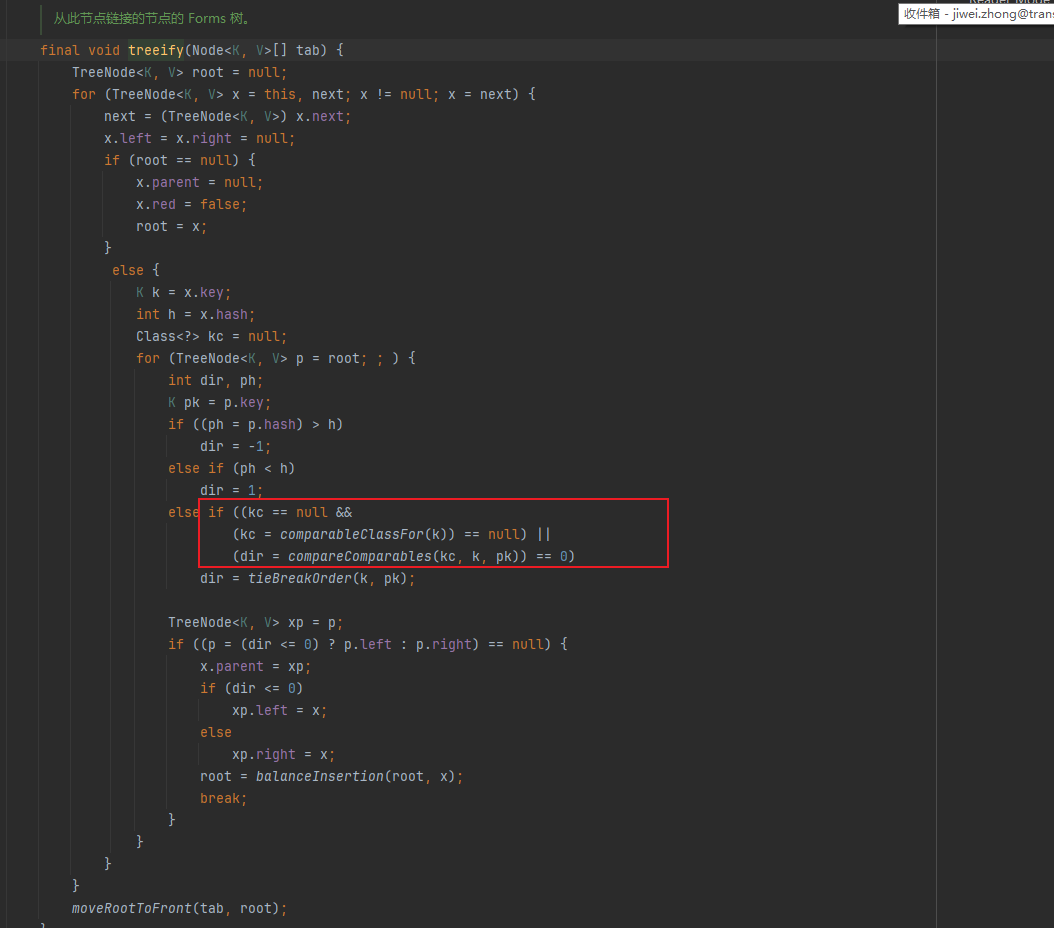
其实很简单,先尝试拿到key的compare,如果key没有实现compare接口,则直接通过原始hashcode比较大小即可,
1,判断是否实现了comparable接口,否则返回null
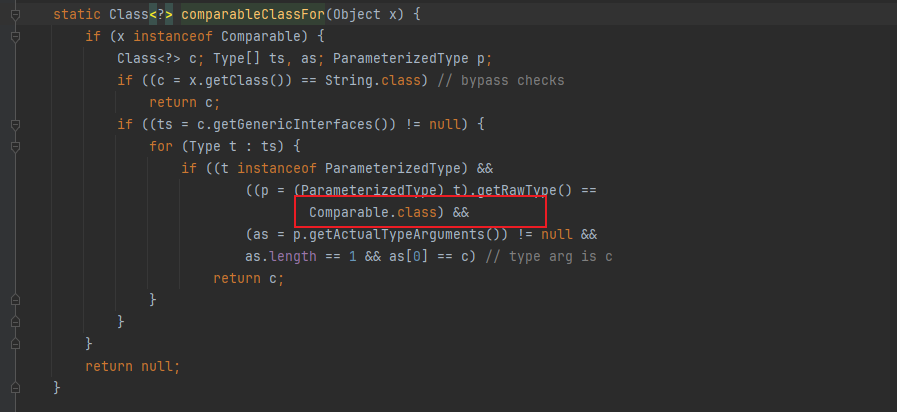
2,如果kc==null,调用tieBreakOrder方法,强行通过hashcode比较
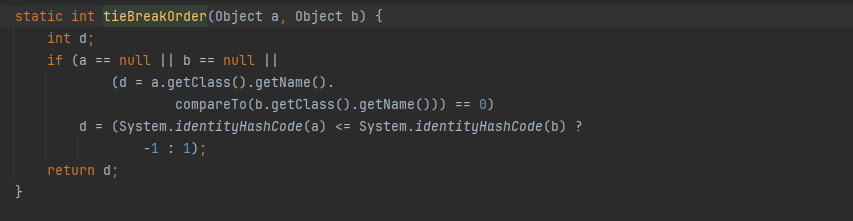 随后,通过balanceInsertion方法插入到红黑树中,内部实现即左旋右旋,不跟进了,纯粹红黑树算法。
随后,通过balanceInsertion方法插入到红黑树中,内部实现即左旋右旋,不跟进了,纯粹红黑树算法。
6,size